







阅读总结
Google的TPU是AI_ASIC芯片的鼻祖,从论文的作者数量之庞大,及论文少有的出现了致谢,就可以看出一定是历经了一番磨砺才创造出来。该论文发表在 2017 年,让我们回到那个年代,一同看看是什么样的背景诞生了如此伟大的艺术品~

《In-Datacenter Performance Analysis of a Tensor Processing Unit》
To appear at the 44th International Symposium on Computer Architecture (ISCA), Toronto, Canada, June 26, 2017.
1. 通往TPU之路
早在2006年,Google就在考虑为神经网络构建一个专用集成电路(ASIC)。2013年这个需求变得更加紧迫,当时Google意识到快速增长的计算需求,可能意味着数据中心的数量需要翻番才能满足。
通常而言,ASIC的开发需要耗时数年。但具体到TPU而言,从设计到验证、构建和部署到数据中心里,只需要15个月。
TPU ASIC采用了28nm工艺制造,主频700MHz,功耗40W。为了尽快把TPU部署到现有的服务器中,Google选择把这个芯片打包成外部扩展加速器,然后插到SATA硬盘插槽里使用。所以TPU通过PCIe Gen3 x16总线与主机相连,也就是说12.5GB/s的有效带宽。
Abstract
 > 1.Deployed in datacenters.
> 1.Deployed in datacenters.
2.Accelerates the inference phase of neural networks (NN).
3.The heart of the TPU is a 65,536 8-bit MAC matrix multiply unit that offers a peak throughput of 92 TeraOps/second (TOPS) and a large (28 MiB) software-managed on-chip memory.
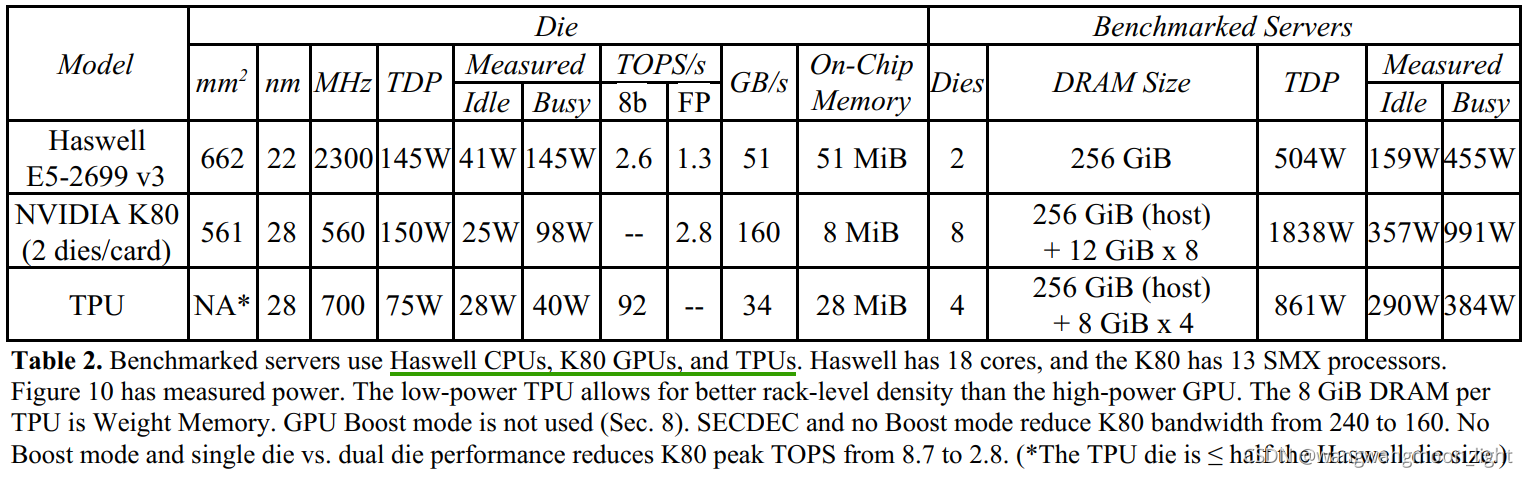
4.We compare the TPU to a server-class Intel Haswell CPU and an Nvidia K80 GPU, which are contemporaries deployed in the same datacenters
摘要:
– Many architects believe that major improvements in cost-energy-performance must now come from domain-specific hardware.
本文评估了自2015年以来部署在数据中心的定制专用集成电路——称为张量处理单元(Tensor processing Unit, TPU),该集成电路可加速神经网络(NN)的推理阶段。TPU的核心是一个65,536个8位MAC矩阵相乘单元,提供了92 TeraOps/秒(TOPS)的峰值吞吐量和一个大(28 MiB)的软件管理片上存储器。
TPU的确定性执行模型比cpu和gpu的时变优化更符合我们的NN应用程序的99%响应时间要求 (缓存、乱序执行、多线程、多处理、预取……) 这些都有助于提高平均吞吐量,而不是保证延迟。
缺乏这样的功能有助于解释为什么尽管拥有无数的mac和大内存,TPU却相对较小和低功耗。我们将TPU与服务器级的Intel Haswell CPU和 Nvidia K80 GPU,部署在相同的数据中心。
我们的工作量,写在高层TensorFlow框架,使用生产NN应用(MLPs, CNNs和LSTMs),代表95%的数据中心的NN推断需求。尽管某些应用程序的利用率很低,但TPU的平均利用率约为15倍比现在的GPU或CPU快30倍,TOPS/Watt大约高出30 - 80倍。此外,使用GPU的TPU中的GDDR5内存将会三倍于TOPS,并将TOPS/Watt提高到GPU的近70倍和GPU的200倍CPU。
结论:Despite low utilization for some applications, the TPU is on average about 15X -
30X faster than its contemporary GPU or CPU, with TOPS/Watt about 30X - 80X higher. Moreover, using the GPU’s GDDR5 memory in the TPU would triple achieved TOPS and raise TOPS/Watt to nearly 70X the GPU and 200X the CPU.
算力 92TeraOps/Second(TOPS)and 28MiB software-managed on chip memory
Introduction to Neural Networks
A step called quantization transforms floating-point numbers into narrow integers—often just 8 bits—which are usually good enough for inference.
Eight-bit integer multiplies can be 6X less energy and 6X less area than IEEE 754 16-bit floating-point multiplies, and the 1advantage for integer addition is 13X in energy and 38X in area [Dal16]
介绍INT8,为什么需要INT8,以及量化(quantization)的概念
作为优化的第一步,Google应用了一种称为量化的技术进行整数运算,而不是在CPU或者GPU上对所有数学工作进行32位或者16位浮点运算。这能减少所需的内存容量和计算资源。
— 分割线 —
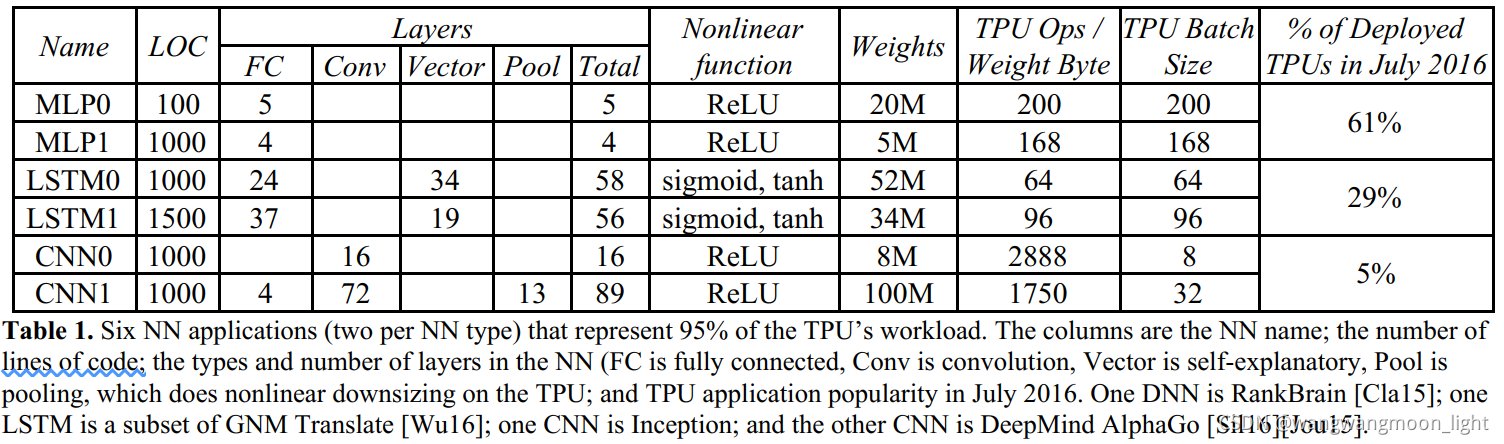
实际业务中需要多少次乘法运算?2016年7月,Google团队调查了实际业务中,六个有代表性的神经网络应用,结果如下表所示:
NN – Neural Networks ,当前主要有三类,多层感知器(MLP),CNN,RNN.
Thus, we started a high-priority project to quickly produce a custom ASIC for inference (and bought off-the-shelf GPUs for training).


为了减少延迟部署的机会,TPU没有与CPU紧密集成,而是被设计为PCIe I/O总线上的协处理器,允许它像GPU那样插入现有的服务器。此外,为了简化硬件设计和调试,主机服务器发送TPU指令让它执行,而不是自己获取指令。
我们的目标是在TPU中运行整个推理模型,以减少与主机CPU的交互,并保持足够的灵活性,以满足2015年及以后的NN需求,而不是仅仅满足2013年NN的需求。图1显示了TPU的框图
2. TPU 的起源、架构和实现
缘由:
这个话题在2013年发生了变化,当时人们每天使用语音识别dnn进行3分钟的语音搜索,这需要我们的数据中心翻倍才能满足计算需求,而传统cpu满足这一需求的成本非常昂贵。
我们的目标是比 GPU 提高10倍的性价比。考虑到这一任务,TPU的设计、验证、建造和部署在数据中心只用了15个月。
设计:
为了减少延迟部署的机会,TPU没有与CPU紧密集成,而是被设计为PCIe I/O总线上的协处理器,允许它像GPU那样插入现有的服务器,为了简化硬件设计和调试,主机服务器发送TPU指令让它执行,而不是自己获取指令

- TPU指令从主机通过PCIe Gen3 x16总线发送到指令缓冲区。
- MACs包括 256256的 8-bit 乘加,产生的 16bit 结果存放在 4MiB 做32bit的累加,4MiB 的含义是 4096, 256个元素的32bit累加(4K256*32b == 4MiB)
本单元是为稠密矩阵设计的。由于部署时间的原因,省略了稀疏的体系结构支持。在未来的设计中,稀疏性将是优先考虑的问题
它每个时钟周期读写256个值,可以执行矩阵乘法或卷积
中间结果保存在24 MiB片上统一缓冲区中, 选择24 MiB大小,一方面是为了匹配模具上Matrix Unit的间距,另一方面是为了简化编译器
一个可编程的DMA控制器传输数据到或从CPU主机内存和统一缓冲区 – M*E
Control is just 2%.
ISA
由于指令通过相对较慢的PCIe总线发送,TPU指令遵循CISC传统,包括一个重复字段。这些CISC指令的每条指令的平均时钟周期(CPI)通常是10到20。它总共有十几条指令,但这五条是关键的
为了控制MUX、UB和AU进行计算,Google定义了十几个专门为神经网络推理而设计的高级指令。以下是五个例子。
PIngPang : The philosophy of the TPU microarchitecture is to keep the matrix unit busy. The plan was to hide the execution of the other instructions by overlapping their execution with the MatrixMultiply instruction.


由于读取一个大的SRAM比算术消耗更多的能量,矩阵单元使用收缩执行,通过减少统一缓冲区的读写来节省能量
与CPU和GPU相比,TPU的控制单元更小,更容易设计,面积只占了整个Floor Plan的2%,给片上存储器和运算单元留下了更大的空间。而且,TPU的大小只有其他芯片的一半。硅片越小,成本越低,良品率也越高。

脉动矩阵
TPU采用了与传统CPU和GPU截然不同的脉动阵列(systolic array)结构来加速AI运算,脉动阵列能够在一个时钟周期内处理数十万次矩阵运算,在每次运算过程中,TPU能够将多个运算逻辑单元(ALU)串联在一起,并复用从一个寄存器中取得的结果。这种设计,不仅能够将数据复用实现最大化,减少芯片在运算过程中的内存访问次数,提高AI计算效率,同时也降低了内存带宽压力,进而降低内存访问的能耗。
MXU的脉动阵列包含256 × 256 = 65,536个ALU,也就是说TPU每个周期可以处理65,536次8位整数的乘法和加法。
算力计算:TPU以 700MHz 的功率运行,也就是说,它每秒可以运行 65,536 × 700,000,000 = 46 × 1012次乘法和加法运算,或每秒92万亿(92 × 1012), 92Tops 次矩阵单元中的运算。

4. Performance: Rooflines, Response-Time, and Throughput
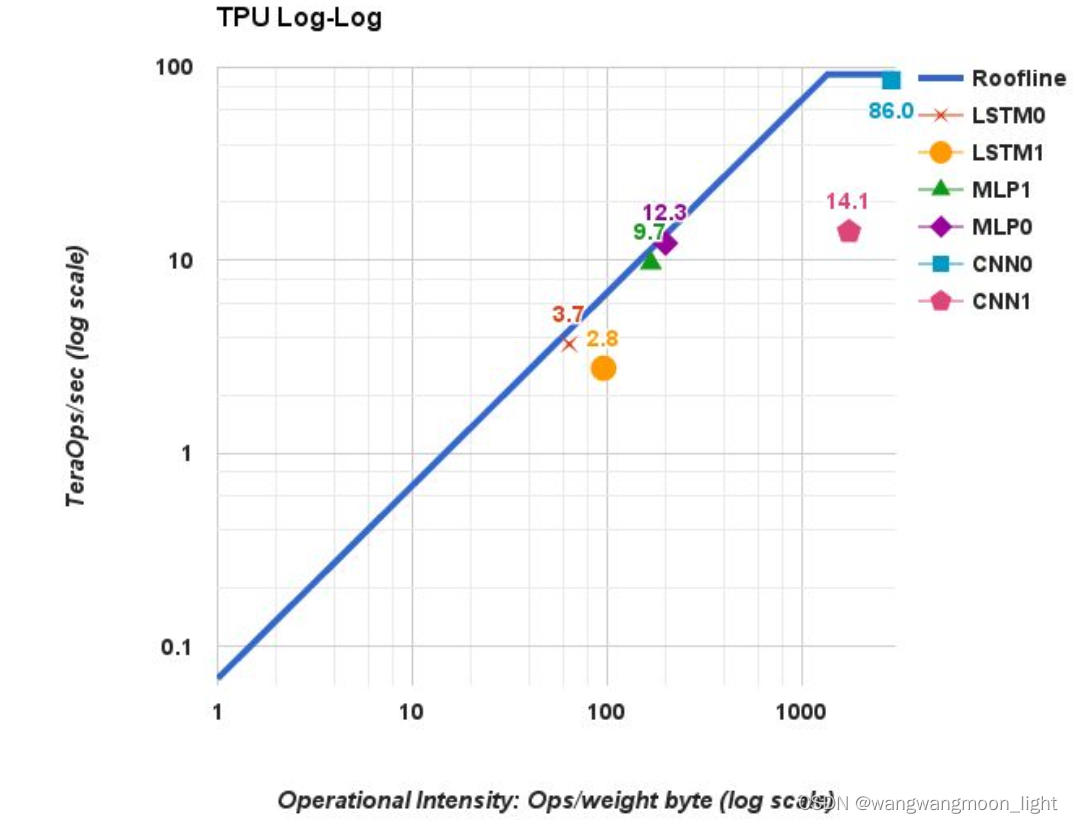
TPU Log-Log
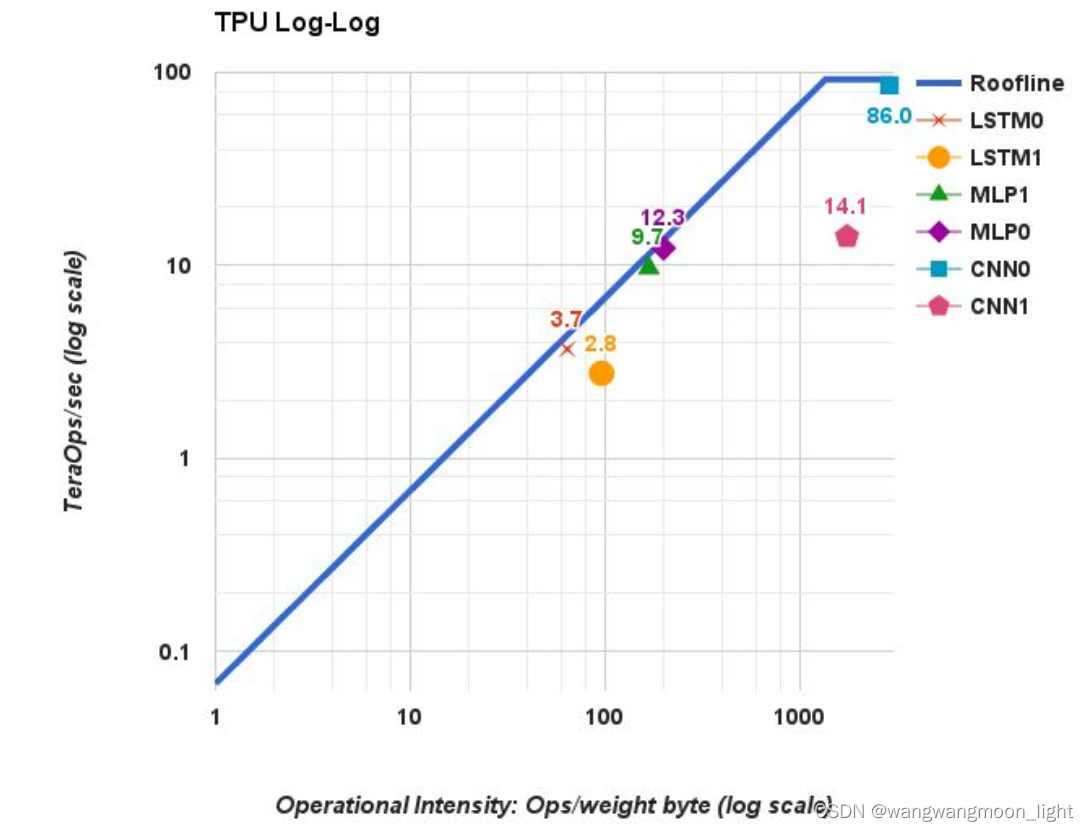
TPU的脊点出现在 1350 Oper/s. TPU的屋顶线有一个很长的“倾斜”部分,其中的操作强度意味着性能受到内存带宽的限制,而不是峰值计算
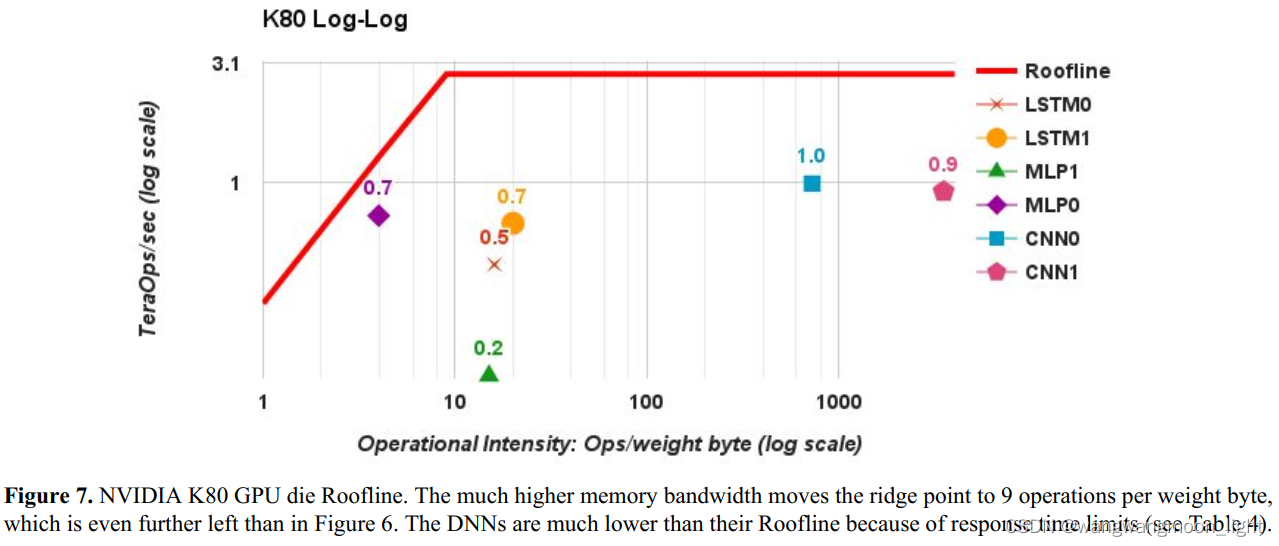
the MLPs and LSTMs are memory bound and CNNs are computation bound.
因为 MLPs 和 LSTMs 在脊点之前,CNNs在脊点之后。在脊点之前,则X轴访存能力提升,Y轴计算能力提升,说明瓶颈在访存能力,在脊点之后,X轴访存能力提升,Y轴计算能力也不变,说明瓶颈在计算能力。
尽管CNN1的操作强度非常高,但其TOPS仅为14.1; CNN0在86 TOPS;
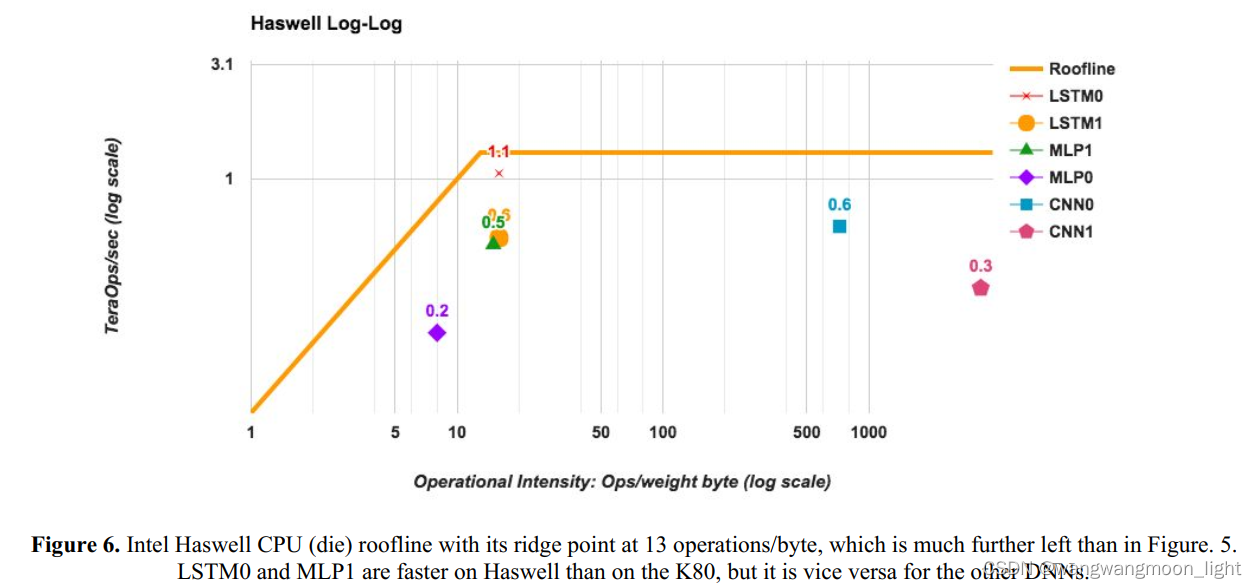
Haswell Log-Log
K80 Log-Log
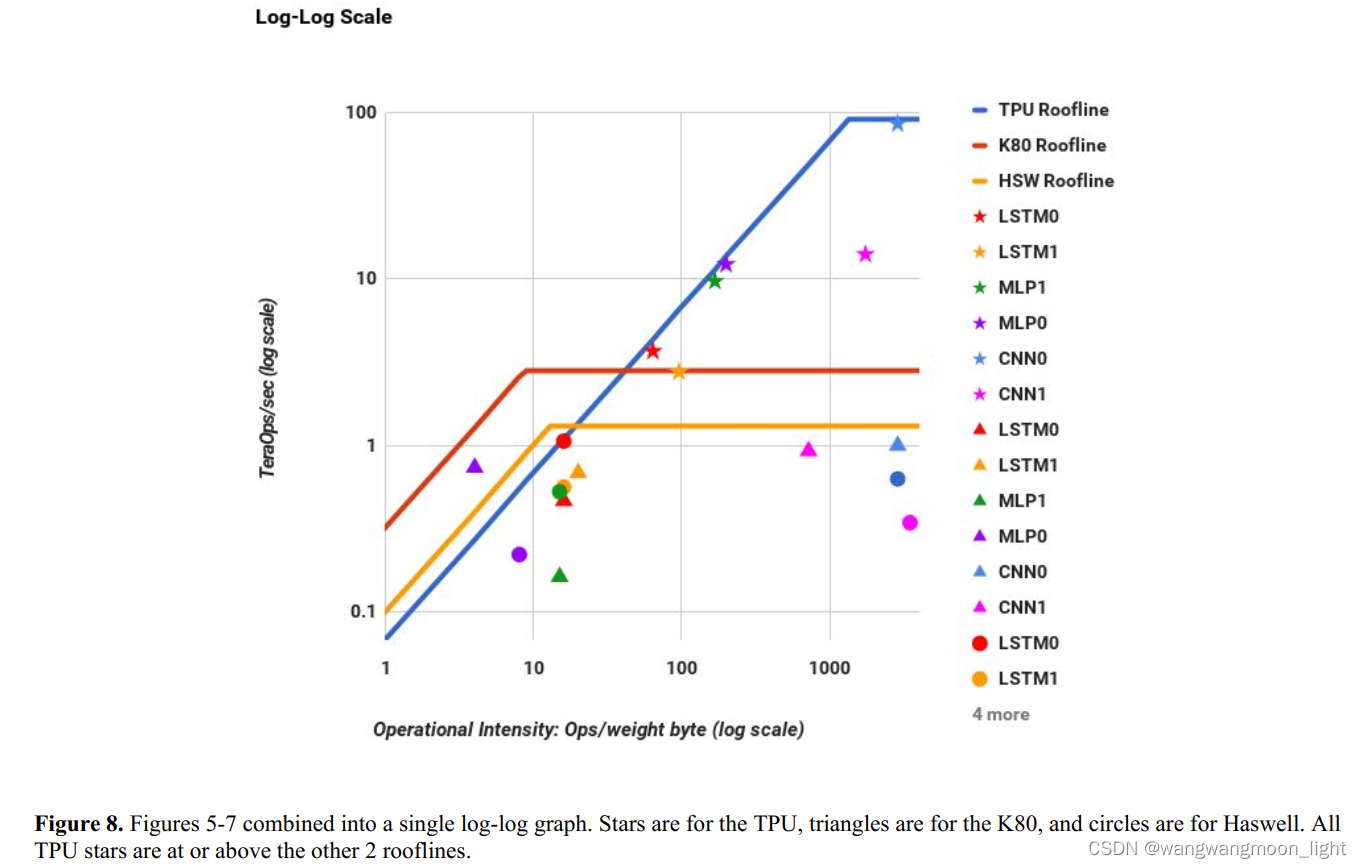
下面,是TPU、CPU、GPU在六种神经网络上的性能对比。在CNN1上,TPU性能最为惊人,达到了CPU的71倍。

这个简单的可视化模型并不完美,但它提供了性能瓶颈的原因
5. Cost-Performance, TCO, and Performance/Watt
6. Energy Proportionality
7. Evaluation of Alternative TPU Designs
8. 软件栈
TPU设计封装了神经网络计算的本质,可以针对各种神经网络模型进行编程。为了编程,Google还创建了一个编译器和软件栈,将来自TensorFlow图的API调用,转化成TPU指令。
















 1408
1408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









