








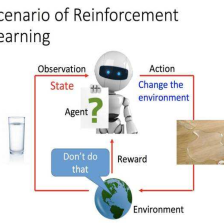

李宏毅机器学习系列-强化学习之近端策略优化
策略梯度的另一个问题
上一篇深度强化学习介绍到,我们的奖励梯度是这个样子:
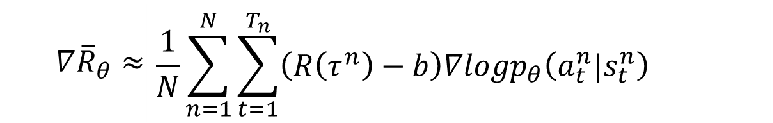
这个就意味着,在同一场游戏里不同的
s
t
s_t
st下,采取某个
a
t
a_t
at的权重有一个相同的
R
(
τ
n
)
R(\tau^n)
R(τn),这显然是有问题的。比如如果某个
R
(
τ
n
)
R(\tau^n)
R(τn)好,并不意味着他里面的a都好,要提高出现的概率,相反
R
(
τ
n
)
R(\tau^n)
R(τn)不好,也不意味着里面的a都不好,要降低出现的概率,所以每个a的对奖励的影响或者说贡献,也就是权重应该是不一样的。
比如下面的例子,左边的一场游戏中,奖励是3,但是里面的a并不都是好的,是因为
a
1
a_1
a1的共享太大,所以最后奖励是正的,
a
2
a_2
a2的行为可能也是不好的,他可能会简介导致
a
3
a_3
a3获得了不好的分数,这就说明了总的奖励大,并不一定每个a都是好的,都要提高概率。或许如果我们采样的够多,或许我们只知道
a
2
a_2
a2对后面的影响,但是问题是我们可能采样不到那么多,所以我们要不同的a合理的权重:

其实我们可以认为某个a对奖励的影响只会影响到他后面的奖励,不会影响前面的,所以每一个a都可能会有不同的权重,这个权重应该是从a的时刻开始到最后的奖励的和也就是:
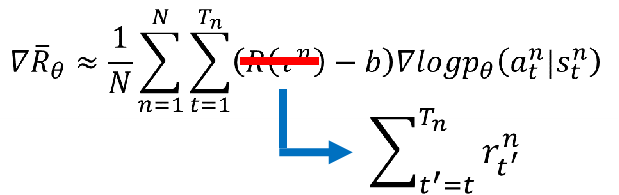
但是因为玩的越多,最开始的行为对游戏的奖励的影响是会越来越小的,所以我们要再给一个衰减系数
γ
\gamma
γ。然后我们可以把
R
(
τ
n
)
−
b
R(\tau^n)-b
R(τn)−b叫做优势函数,也就是在一个s下,采取a之后致的结果相对于其他行为有多好,是个相对的,这个优势函数跟
θ
\theta
θ有关,因为奖励是某一个模型采取的行为得来的,而这个模型的参数就是
θ
\theta
θ,所以是相关的:

从现在学习到离线学习(From on-policy to off-policy)
在线学习就是说智能体是一直在跟环境做互动的,离线学习就是智能体没有在跟环境做互动,而是看这别人做互动,简单来说学习和环境交互的是同一个智能体,比如下面棋魂里的阿光和佐为下棋,边下边学就是在线学习,佐为下棋,阿光在旁边看,边看边学习,就是离线学习:

为什么我们要从在线学习转到离线学习呢,根据我们前面的梯度公式,梯度是跟
θ
\theta
θ相关的,因为我们会采样很多局游戏进行学习,然后会更新参数
θ
\theta
θ,更新完了就要重新去采样,不能用上次根据旧的模型采样来的数据再来训练,所以这样效率就不高,所以就提出了离线学习,也就是能不能找一个固定为参数
θ
′
\theta '
θ′的模型
π
θ
′
\pi _\theta'
πθ′,只要采集一次数据,可以重复使用多次,从这个固定模型生成的数据上去学习我们的模型参数
θ
\theta
θ,可以简单比喻理解成在线学习就是充电5分钟,通话5分钟,离线学习是充电5分钟,通话两小时:

重要性采样(importance sampling)
所以我们提出了一种新的采样方式,重要性采样,我们去找有个分布
q
(
x
)
q(x)
q(x),从他里面采样,我们知道随机变量函数
f
(
x
)
f(x)
f(x)的期望是
∫
f
(
x
)
p
(
x
)
d
x
\int f(x)p(x)dx
∫f(x)p(x)dx,其中
f
(
x
)
f(x)
f(x)是另一个随机变量,也可以认为是随机变量函数,
p
(
x
)
p(x)
p(x)是随机变量的概率密度函数,然后我们进行恒等变换,最后将
q
(
x
)
q(x)
q(x)作为概率密度函数,
f
(
x
)
p
(
x
)
q
(
x
)
f(x)\frac{p(x)}{q(x)}
f(x)q(x)p(x)作为随机变量,其实就是多一个权重,这个权重叫做重要性权重:

重要性采样的问题
那这个重要性权重存在什么问题呢,虽然我们知道左边的式子等于右边的式子,也只能期望值相等:
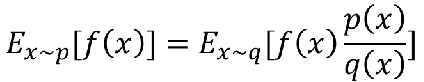
但是如果是方差,其实是不一样的:
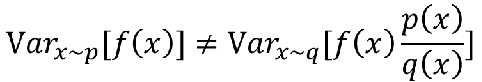
我们来看下方差公式:
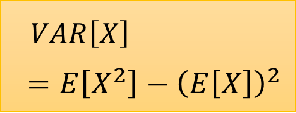
所以我们来算一下: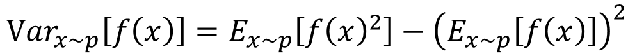
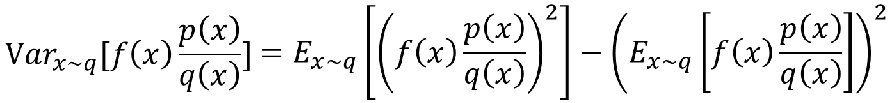
然后中间还一步变换我手写了:

最后就等于这个式子:
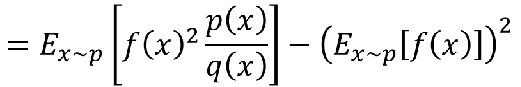
可以看到方差之间也是相差了一个系数
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x),如果p,q相差很大的话,方差就很大,虽然说理论上期望是一样的,但是实际上做不到采样那么数据,方差是不一样的,所以可能得到的差距比较大了。
如果说公式比较难理解,那举个直观点的例子。蓝色的是p的分布,绿色的是q的分布,红色的是随机变量
f
(
x
)
f(x)
f(x),如果要计算p的期望,因为p在左边几率很高,所以期望应该是负的,如果计算q的期望,右边q的几率高,虽然权重系数
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x)小,但是基本都是正的,期望也会是正的。那不是和p不一样啦,但是如果你采样的足够多的,q还是会采样到左边的点,因为左边p几率很大,所以
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x)这项权重可能非常大,
f
(
x
)
f(x)
f(x)又是负的,所以可能抵消掉右边采样的正项,期望就可能是负的,也就会和p一样了:

所以我们现在可以从在线学习转到离线学习了,前面定义的跟
θ
\theta
θ相关的奖励梯度可以转换为跟
θ
′
\theta'
θ′相关的,我们只要让
θ
′
\theta'
θ′的模型去做采样,然后可以重复使用很多次进行训练:

因为上次最后讲了基线和优势函数,所以我们可以一起代入,得到:
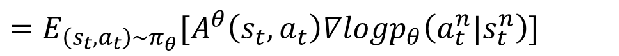
然后转乘离线学习就是:
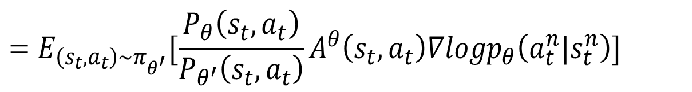
但是你会发现A是跟
θ
\theta
θ相关的,其实应该是跟
θ
′
\theta'
θ′相关的,因为我们的数据都是根据
θ
′
\theta'
θ′模型采样出来的,我们暂时认为相等好了。然后我们用乘法公式变换得到:
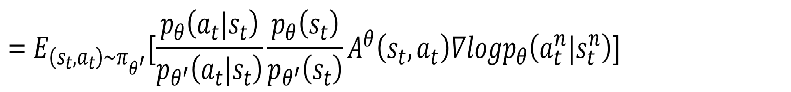
我们假设
p
θ
(
s
t
)
,
p
θ
′
(
s
t
)
p_\theta(s_t),p_\theta'(s_t)
pθ(st),pθ′(st)相等,因为貌似我们没办法算,另外一个理解可以是说大多情况下,我们看到的环境不会改变太多,所以可以认为是一样的:
因为我们知道:
所以我们可以还原上面那个式子,这里的
f
(
x
)
f(x)
f(x)就是
p
θ
(
a
t
∣
s
t
)
p_\theta(a_t|s_t)
pθ(at∣st),也就是找原函数,得到目标函数是:
大括号里面的都是可以计算的。所以现在的问题就是变成怎么样让q,p不要差太多,否则这个效果就不会太好。因此我们可以加一些限制,使得他们不要差太多,这个就是PPO。
近端策略优化(PPO)
PPO就是加了一个限制,加了
θ
,
θ
′
\theta,\theta'
θ,θ′的KL散度,其实衡量的不是
θ
,
θ
′
\theta,\theta'
θ,θ′的差异,而是他们所产生的action分布的差异,因为
θ
,
θ
′
\theta,\theta'
θ,θ′的变化可能和action是不一样的,所以缩小
θ
,
θ
′
\theta,\theta'
θ,θ′的差异不一定能缩小action的差异:

另外一个是PPO的前身,把加的限制分离出来了,比较难处理:

接下来来看下PPO的算法流程,其实就是每次采集一次数据,可以训练多次,然后继续迭代循环,参数
β
\beta
β是动态调整的,如果发现差距大于一个设定的值,就进行惩罚,加大
β
\beta
β。如果差距过小,就减少,不然就一样了,那就没什么进步了:

我们再来看下PPO2的算法:

看起来有点复杂,我们先来看看clip这个函数,他的意思就是如果比值小于
1
−
ϵ
1-\epsilon
1−ϵ的话就等于
1
−
ϵ
1-\epsilon
1−ϵ,同样大于
1
+
ϵ
1+\epsilon
1+ϵ的话就等于
1
+
ϵ
1+\epsilon
1+ϵ,就是给了上下限,不能让他们的比值离1太远,看下面的图,横轴就是比值,其实就是被限定在一个范围里了:

再来看看为什么前面取最小值,因为A是有正负的,看下面的图,绿色的是第一项,蓝色的是第二项,取消就是红色的线。当A是正的时候,我们希望
p
θ
(
a
t
∣
s
t
)
p_\theta(a_t|s_t)
pθ(at∣st)越大越好,但是不能一直大,大到
1
+
ϵ
1+\epsilon
1+ϵ就可以了,不然差距就大了,同理A小于0的时候,我们希望
p
θ
(
a
t
∣
s
t
)
p_\theta(a_t|s_t)
pθ(at∣st)越小越好,但是不要太小,不能小于
1
−
ϵ
1-\epsilon
1−ϵ,否则差距也大了:

可以看下PPO和其他的算法的一些实验数据,紫色的就是PPO,看上去都不错:

总结
本篇主要介绍PPO算法,是一种提高训练效率的方法,可以采集一次样本训练多次,其中很重要的就是重要性采样,要使得采样的模型参数的分布和训练的不要差太多。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件,侵删。















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









