









文章大纲
1. 简介与背景
一直比较关注LLM 相关内容的业界进展,所以特定来参加这个训练营《书生·浦语大模型实战营》,动手学习LLM,看看大模型生态链中具体的最佳实践(Best Practice),很早的时候GPT3.5 时代,我只是注意到了他的发布,之前的聊天机器人还是这么个架构
智能聊天机器人与大语言模型
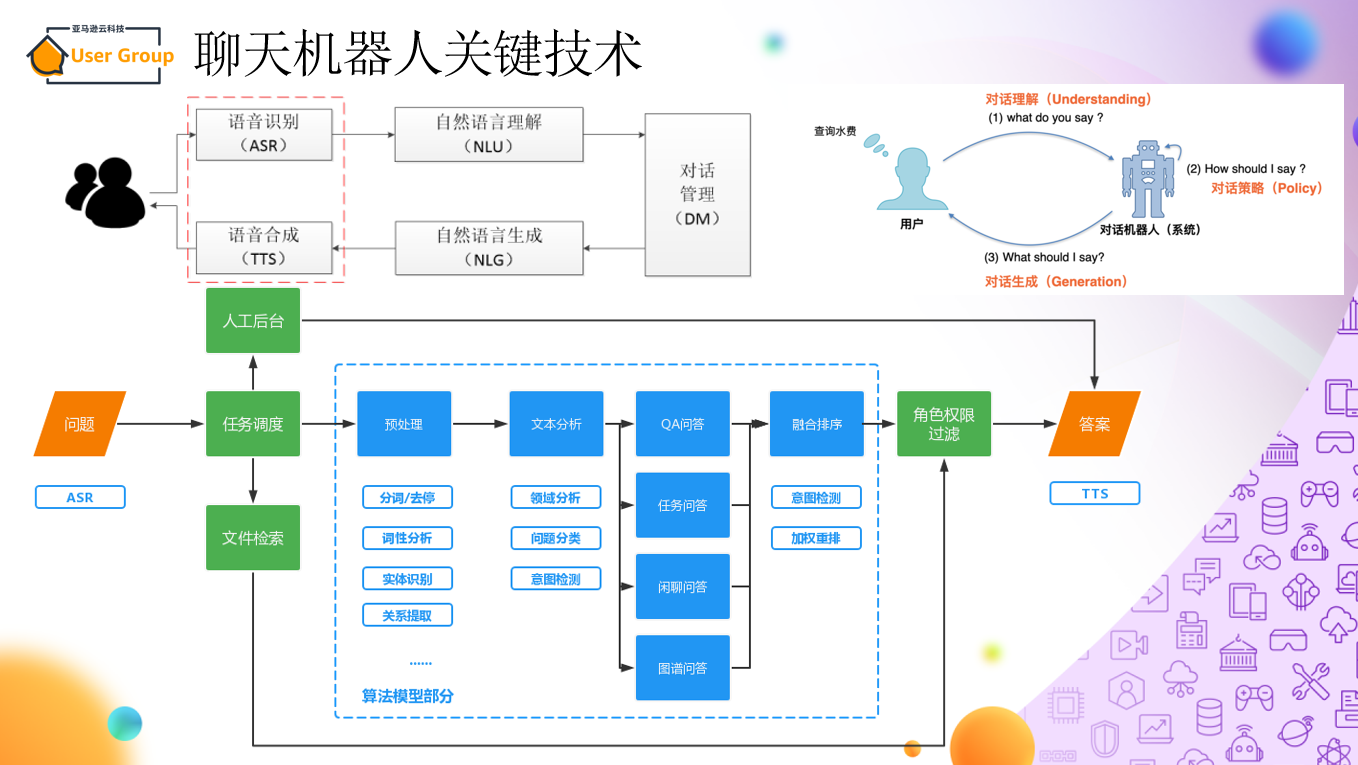
ChatGPT在效果强大的GPT 3.5大规模语言模型(LLM,Large Language Model)基础上,引入“人工标注数据+强化学习”(RLHF,Reinforcement Learning from Human Feedback ,这里的人工反馈其实就是人工标注数据)来不断Fine-tune预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义(比如给我写一段小作文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
ChatGPT 使用来自人类反馈的强化学习进行训练,这种方法通过人类干预来增强机器学习以获得更好的效果。在训练过程中,人类训练者扮演着用户和人工智能助手的角色,并通过近端策略优化算法进行微调。
目前的开源智能聊天机器人与云上运行模式
在人工智能飞速发展的时代,大模型已经成为引领创新和突破的大力推动者。但开发和应用大模型可不是一件容易的事情,需要我们掌握一堆技巧和方法。所以,这次实战营的目标就是让大家能够高效地学习,玩转大模型的微调、部署和评测全套工具。
2. InternLM2 大模型 简介
官网:https://internlm.intern-ai.org.cn/
GitHub: https://github.com/InternLM
InternLM2 技术报告【英文版】:https://arxiv.org/pdf/2403.17297.pdf
3. 视频笔记:书生·浦语大模型全链路开源体系
内容要点
- 大模型成为发展通用人工智能的重要途径
- 从2023年七月InternLM全面开源到,2024年1月17日开源InternLM2,半年版本一更新
书生浦语 2.0 (InternLM2) 的主要亮点
- 超长上下文200k
- 综合性能全面提升
- 优秀的对话和创作体验
- 工具调用能力整体升级
- 突出的数理能力和实用的数据分析能力
从模型到应用典型流程
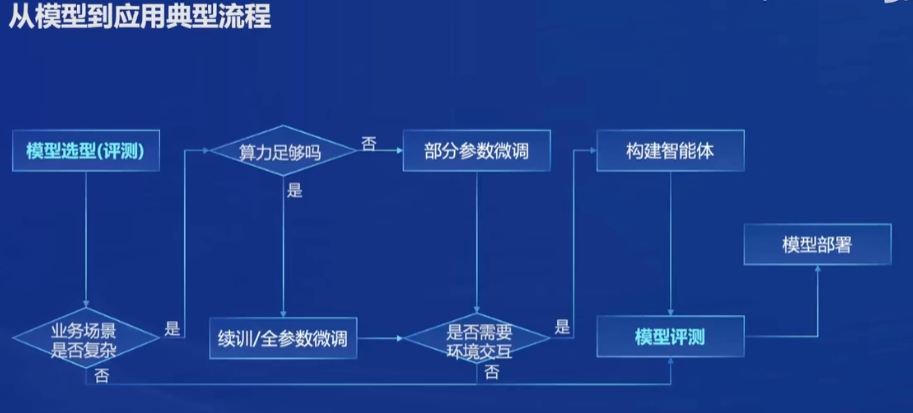
全链路开源体系
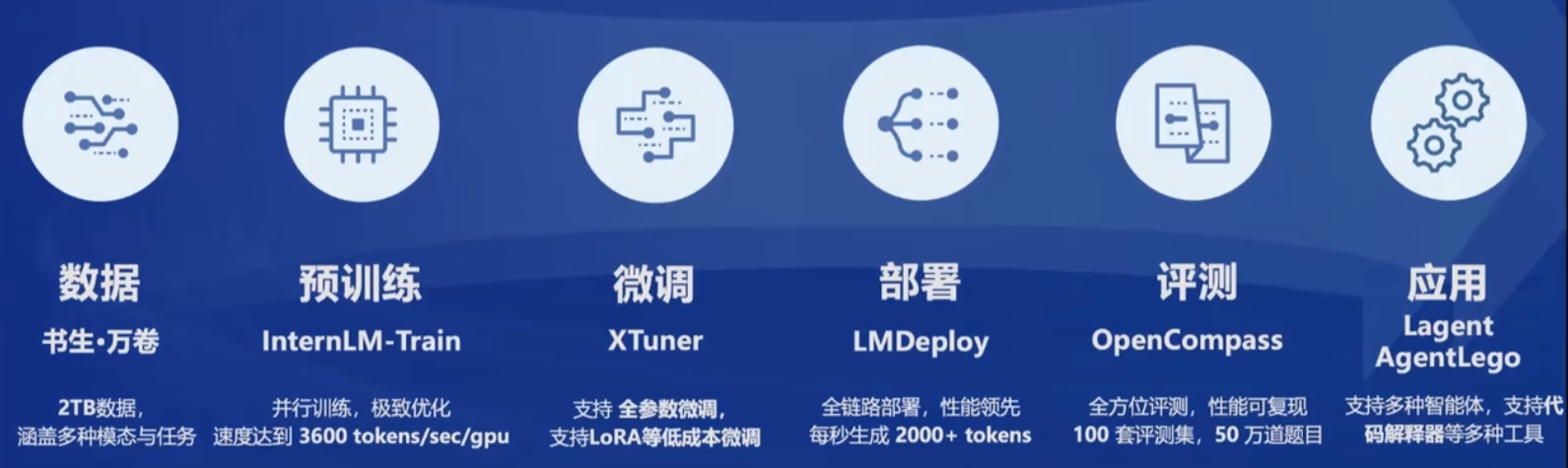
从实际商业项目的调研来看
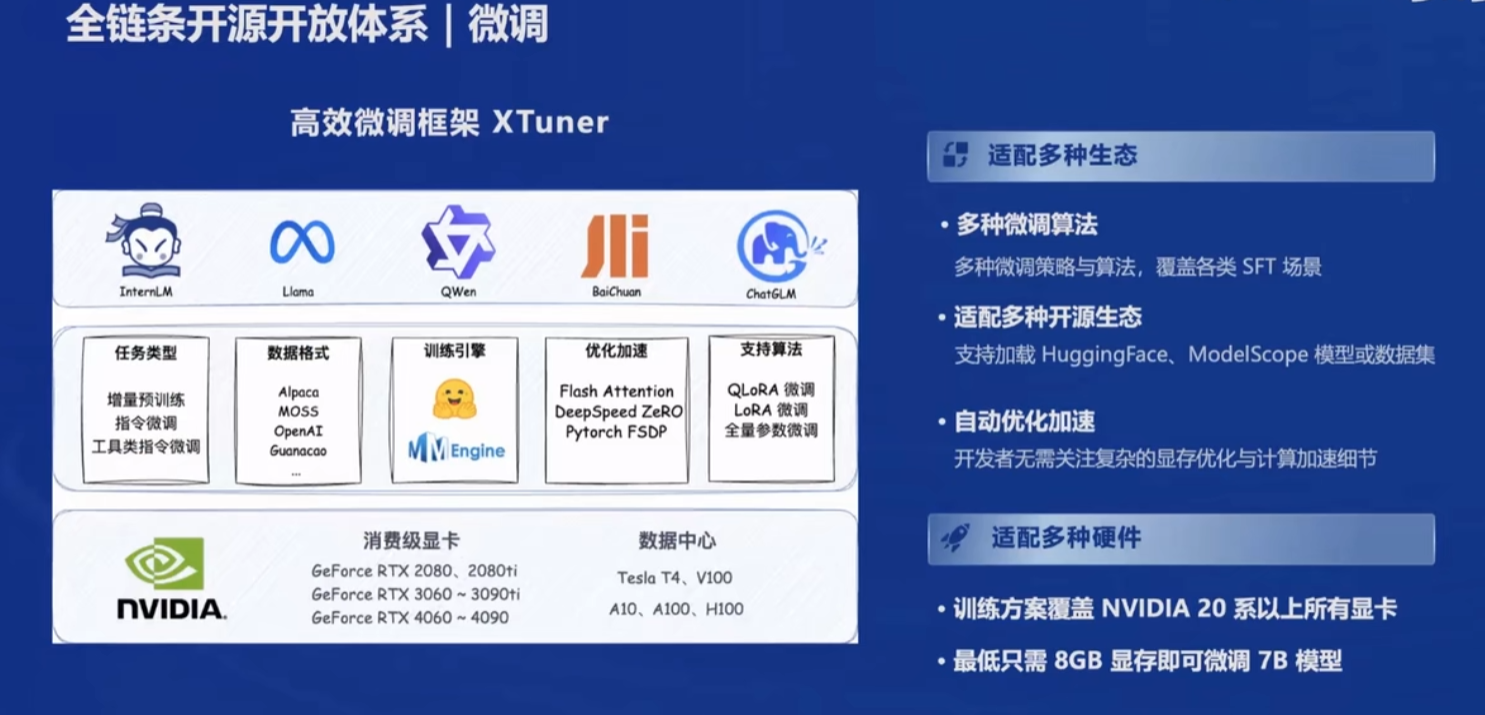
- XTuner微调是刚需,特别是LoRA这种低成本微调,能和RAG连续覆盖场景和成本,在一定范围内,预计避免随着数据规模增加出现成本激增的情况
- LMDeploy部署是刚需,从过去二十多年的商业项目经验来看,客户对于部署这类非直接需求的费用比较敏感
- OpenCompass评测是刚需,实际商业项目不需要全方位评测,更多的可能是针对商业项目的需求编写评测集,保障微调达到预期效果
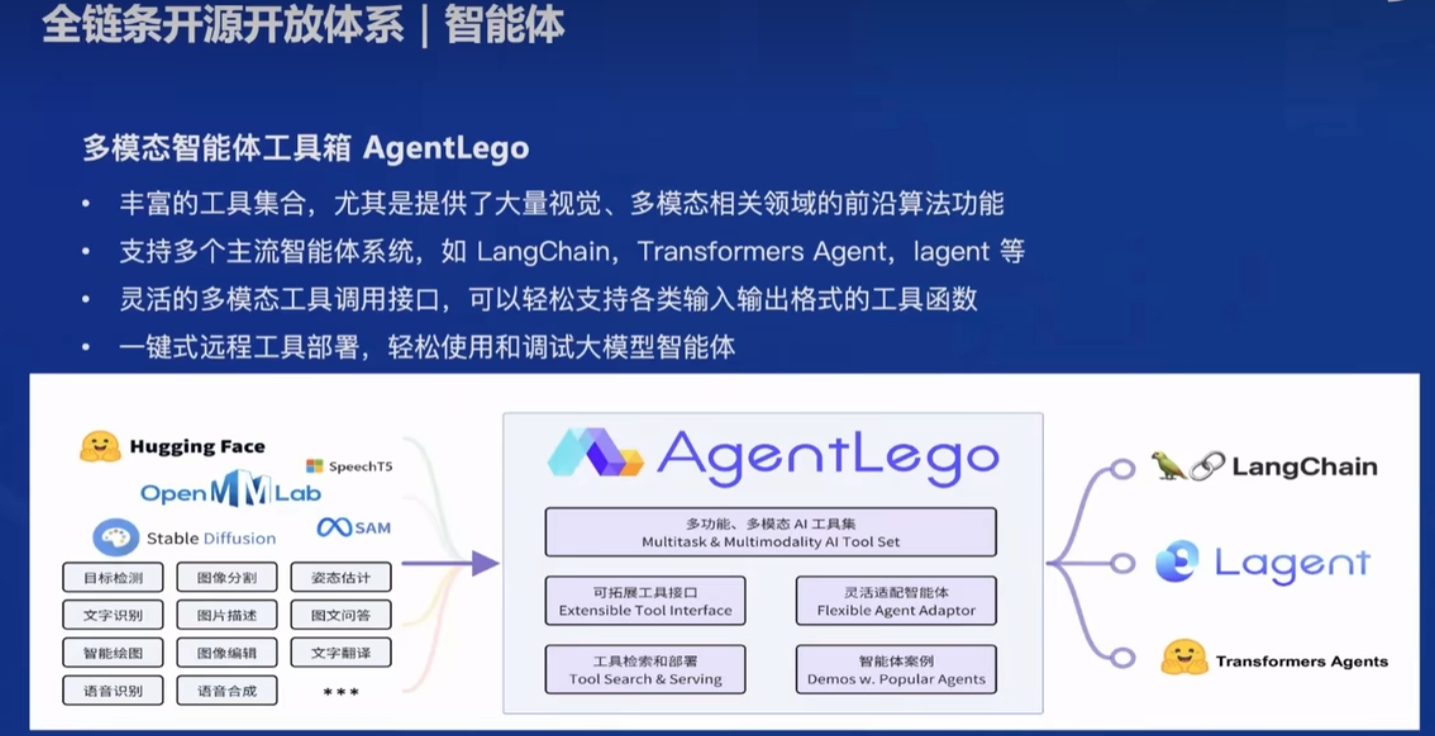
- Lagent和AgentLego是刚需,实际商业项目中需要针对存量数据进行定制开发
4. 论文笔记:InternLM2 Technical Report
论文地址
- https://arxiv.org/pdf/2403.17297.pdf
官方翻译
- https://mp.weixin.qq.com/s/IUUj_CWUJPdrhLq1XAR-KA
中文翻译参考
- https://hub.baai.ac.cn/view/36639
简介
软硬件基础设施 Infrastructure
在预训练、SFT 和 RLHF 中使用的训练框架 InternEvo
预训练方法 Pre-train
Transformer由于其出色的并行化能力,已经成为过去大语言模型(LLMs)的主流选择,这充分利用了GPU的威力; 。LLaMA在Transformer架构基础上进行了改进,将LayerNorm替换为RMSNorm,并采用SwiGLU作为激活函数,从而提高了训练效率和性能。
自从LLaMA发布以来,社区积极地扩展了基于LLaMA架构的生态系统,包括高效推理的提升和运算符优化等。为了确保我们的模型InternLM2能无缝融入这个成熟的生态系统,与Falcon、Qwen、Baichuan、Mistral等知名LLMs保持一致,我们选择遵循LLaMA的结构设计原则。
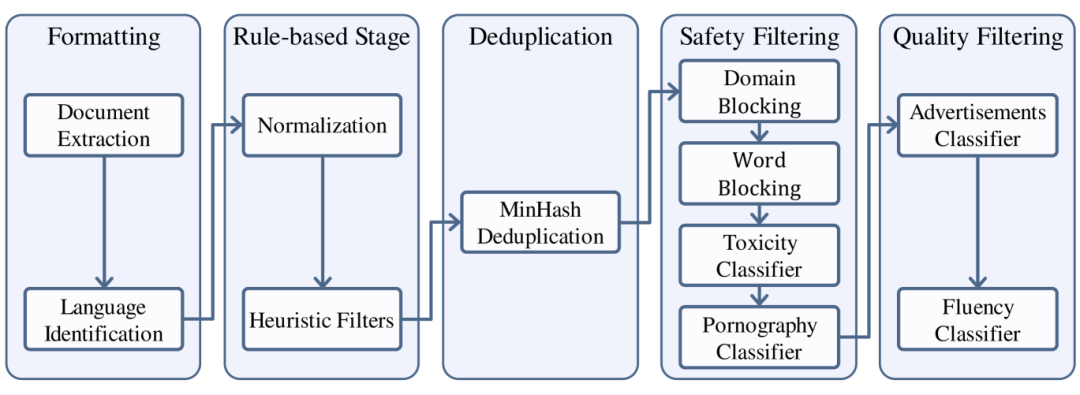
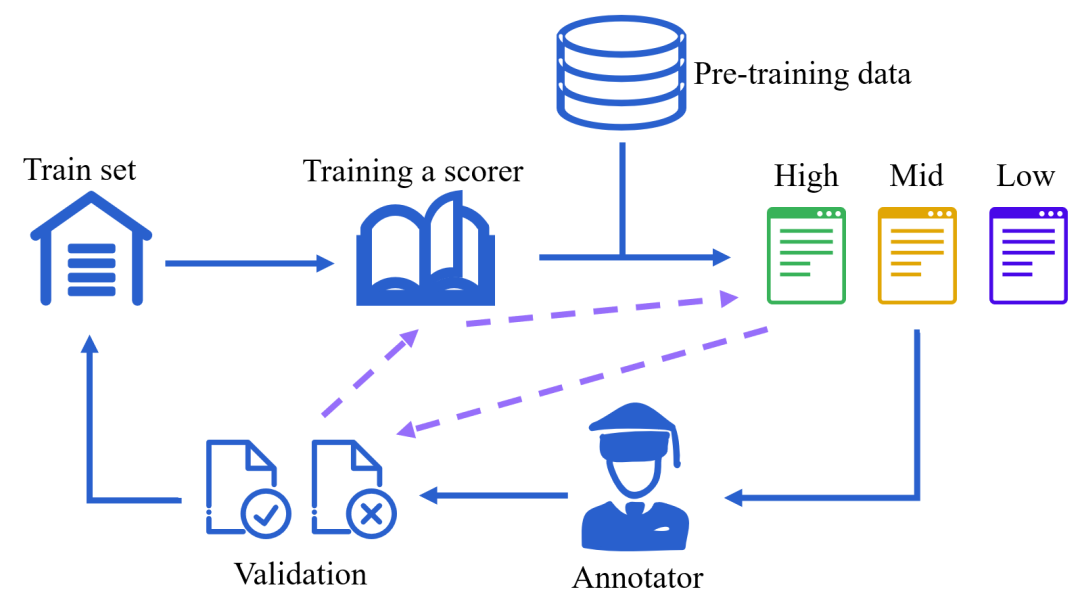
预训练数据、预训练设置以及三个预训练阶段
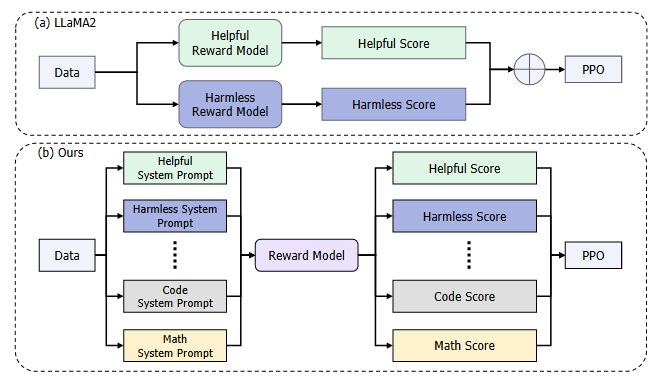
对齐 Alignment
预训练阶段为大型语言模型(LLMs)赋予了解决各种任务所需的基础能力和知识。我们进一步微调LLMs,以充分激发其能力,并指导LLMs作为有益和无害的AI助手。
这一阶段,也常被称为“对齐”(Alignment),通常包含两个阶段:
- 监督微调(SFT)
- 基于人类反馈的强化学习(RLHF)。
在SFT阶段,我们通过高质量指令数据微调模型,使其遵循多种人类指令。然后我们提出了带人类反馈的条件在线强化学习(COnditionalOnLine Reinforcement Learning with Human Feedback,COOL RLHF),它应用了一种新颖的条件奖励模型,可以调和不同的人类偏好(例如,多步推理准确性、有益性、无害性),并进行三轮在线RLHF以减少奖励黑客攻击。
在对齐阶段,我们通过在SFT和RLHF阶段利用长上下文预训练数据来保持LLMs的长上下文能力
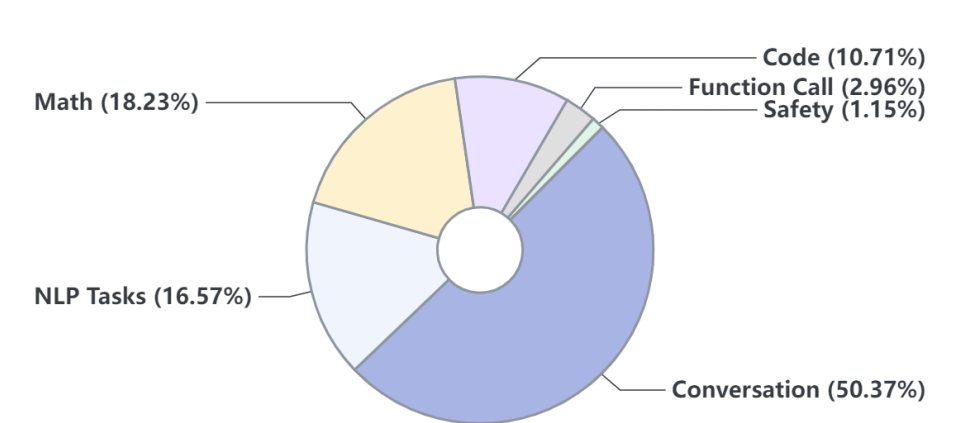
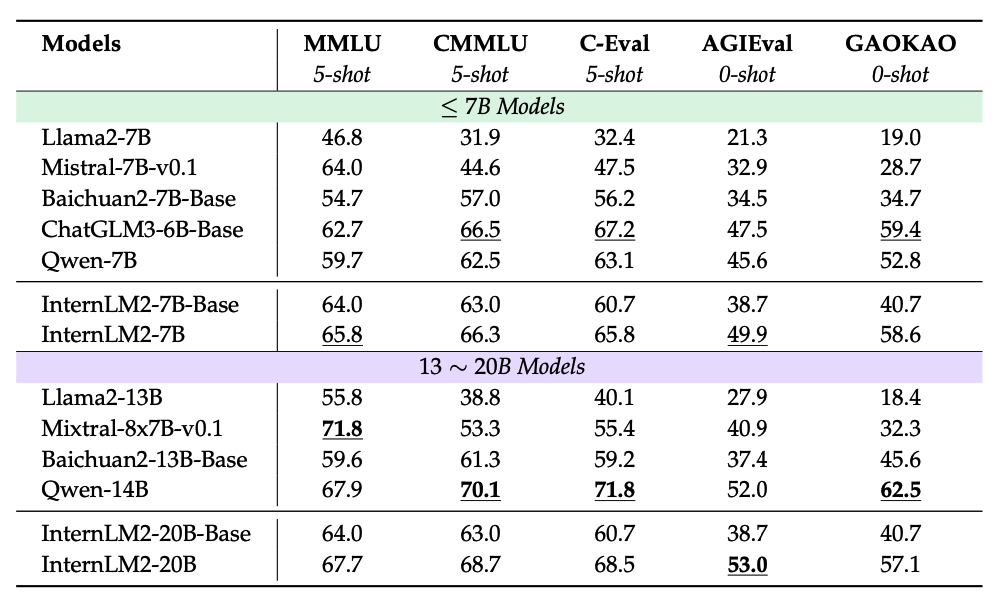
评价与分析 Evaluation and analysis
评测主要分为两种类别:
(a)下游任务
(b)对齐性。
对于每个类别,我们进一步将评测任务细分为具体的子任务,以详细了解模型的优点和缺点。
最后,我们讨论了语言模型中潜在的数据污染问题及其对模型性能和可靠性的影响。除非另有明确说明,所有评测都使用OpenCompass进行。
我们首先详细介绍了多个自然语言处理任务的评估标准和性能指标。
我们引入了数据集,解释了实验设置,然后展示了实验结果并进行深入分析,并将我们的模型与最先进(SOTA)的方法进行了比较,以展示我们模型的有效性。语言模型在下游任务上的表现评测将通过六个关键维度进行深入剖析:
(1) 综合考试
(2) 语言和知识
(3) 推理和数学
(4) 多编程语言编程
(5) 长文本建模
(6) 工具使用
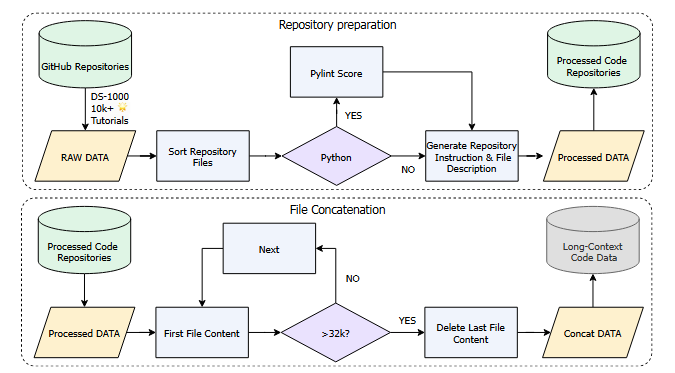
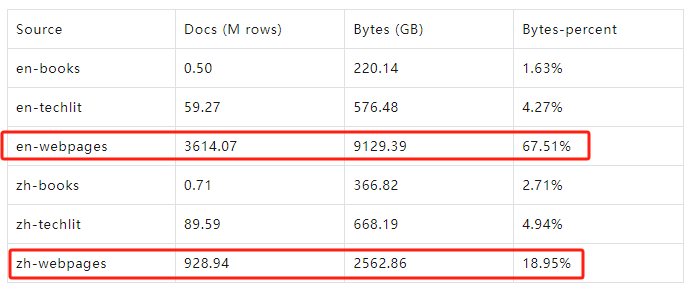
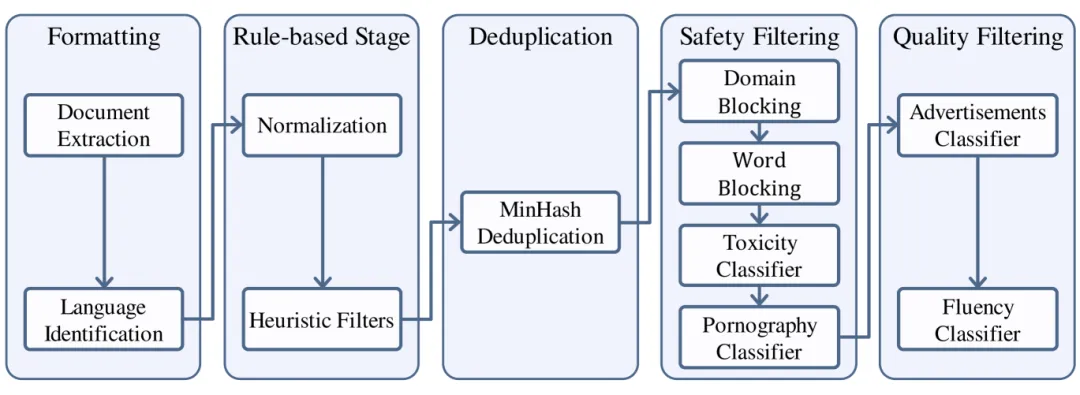
数据收集与整理
典型网页内容获取工具:https://trafilatura.readthedocs.io/en/latest/
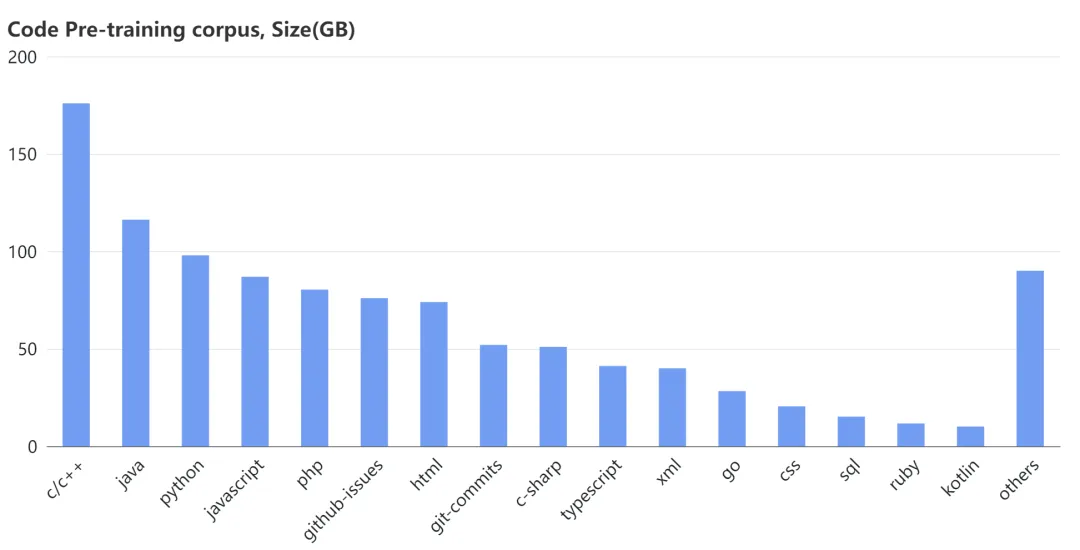
网上的c++ 代码确实太多了,所以你应该多利用AI帮忙写c++代码
其他学习内容
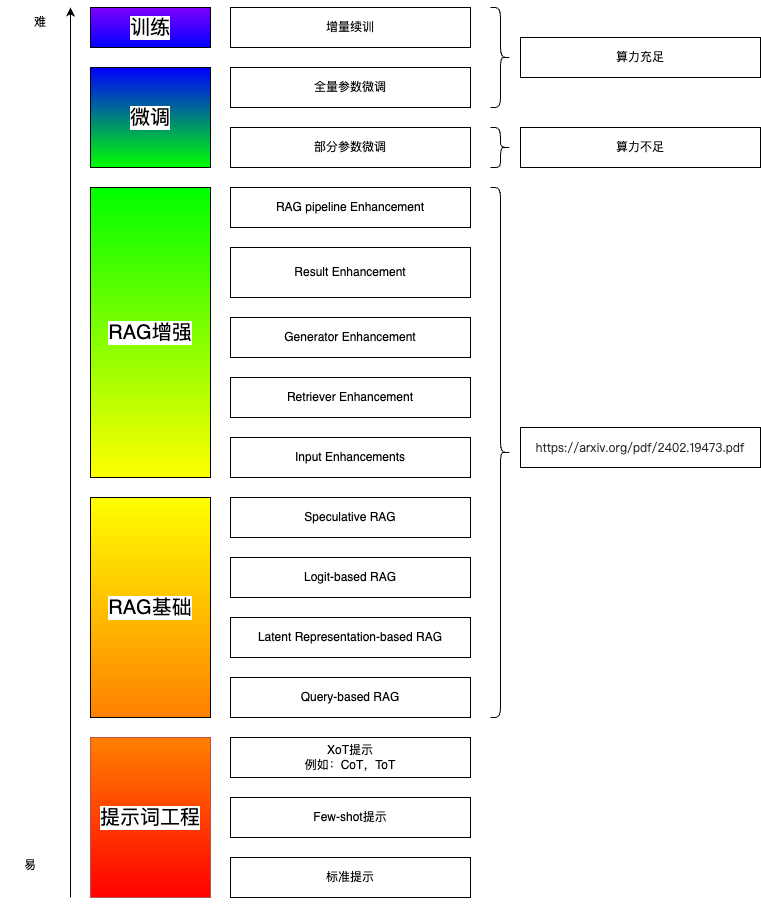
RAG综述
https://arxiv.org/pdf/2402.19473.pdf
Retrieval-Augmented Generation for AI-Generated Content A Survey
LLM 带给世界的改变!
以下观点来源于 《动手学自然语言处理》书籍首发直播
- 通过NLP 任务统一了大部分AI 任务
- 定义问题,解决问题的周期加快
- 未来能与AI 协作的能力是最重要的能力!
参考文献
本人学习系列笔记
- 《书生·浦语大模型实战营》第1课 学习笔记:书生·浦语大模型全链路开源体系
- 《书生·浦语大模型实战营》第2课 学习笔记:轻松玩转书生·浦语大模型趣味 Demo
- 《书生·浦语大模型实战营》第3课 学习笔记:搭建你的 RAG 智能助理(茴香豆)
- 《书生·浦语大模型实战营》第4课 学习笔记:XTuner 微调 LLM:1.8B、多模态、Agent
- 《书生·浦语大模型实战营》第5课 学习笔记:LMDeploy 量化部署 LLM 实践
- 《书生·浦语大模型实战营》第6课 学习笔记:Lagent & AgentLego 智能体应用搭建
- 《书生·浦语大模型实战营》第7课 学习笔记:OpenCompass 大模型评测实战
课程资源
学员手册
- https://aicarrier.feishu.cn/wiki/KamPwGy0SiArQbklScZcSpVNnTb
算力平台
- https://studio.intern-ai.org.cn/
课程文档
- https://github.com/InternLM/Tutorial/tree/camp2
课程视频
- https://www.bilibili.com/video/BV1Vx421X72D/
代码仓库
- https://github.com/InternLM/Tutorial/tree/camp2
论文
RAG综述
https://arxiv.org/pdf/2402.19473.pdf
Retrieval-Augmented Generation for AI-Generated Content A Survey
其他参考
胡老师博客:
- 第一课
- https://blog.csdn.net/hu_zhenghui/article/details/138811450
















 1297
1297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











