







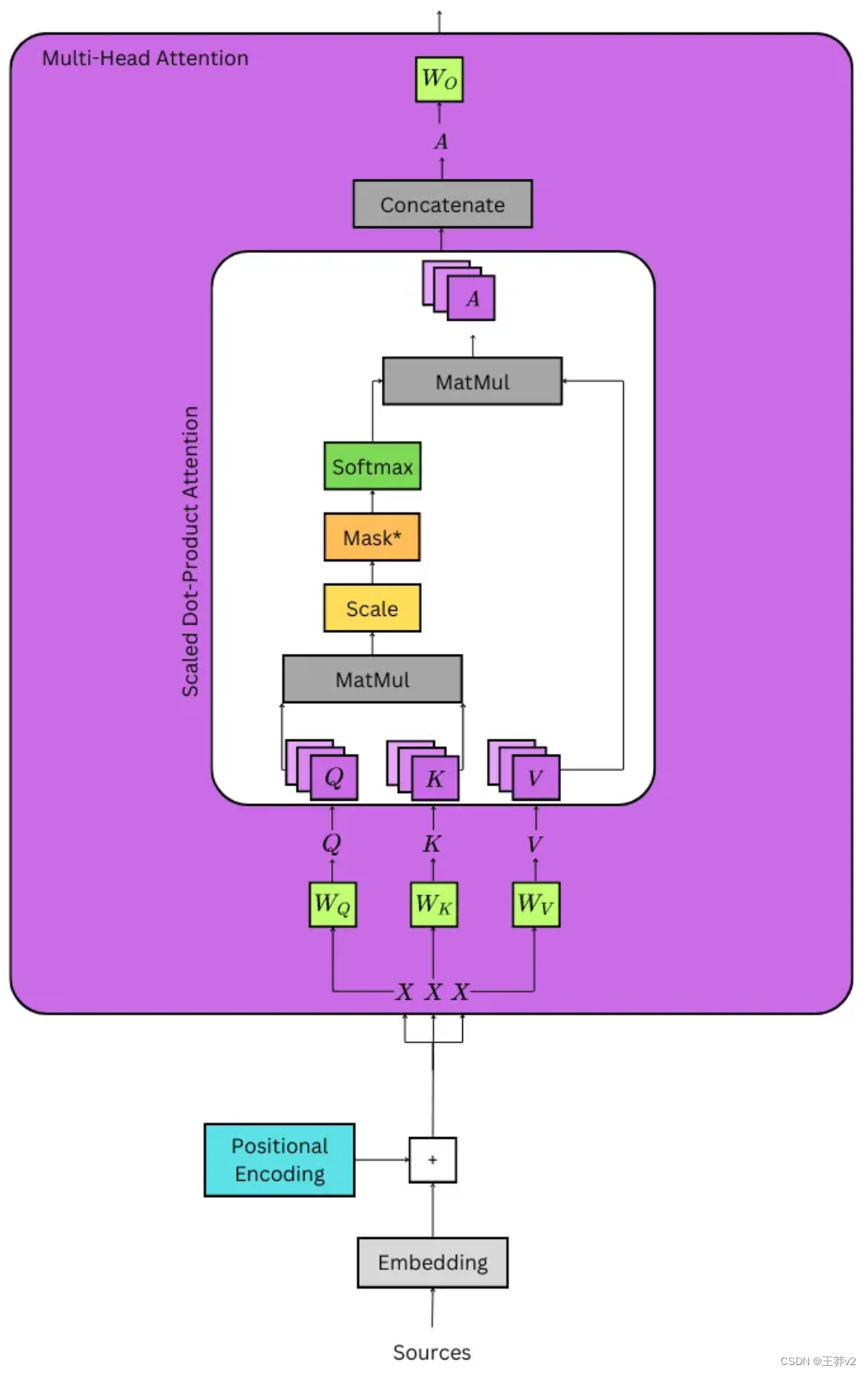
文中大部分内容以及图片来自:https://medium.com/@hunter-j-phillips/multi-head-attention-7924371d477a
当使用 multi-head attention 时,通常d_key = d_value =(d_model / n_heads),其中n_heads是头的数量。研究人员称,通常使用平行注意层代替全尺寸性,因为该模型能够“关注来自不同位置的不同表示子空间的信息”。
通过线性层传递输入
计算注意力的第一步是获得Q、K和V张量;它们分别是查询张量、键张量和值张量。它们是通过采用位置编码的嵌入来计算的,它将被记为X,同时将张量传递给三个线性层,它们被记为Wq, Wk和Wv。这可以从上面的详细图像中看到。
- Q = XWq
- K = XWk
- V = XWv
为了理解乘法是如何发生的,最好将每个组件分解成这个形状: - X的大小为(batch_size, seq_length, d_model)。例如,一批32个序列的长度为10,嵌入为512,其形状为(32,10,512)。
- Wq,Wk和Wv的大小为(d_model,d_model)。按照上面的示例,它们的形状为(512,512)。
因此,可以更好地理解乘法的输出。每个重量矩阵同时在批处理中 broadcast 每个序列,以创建Q,K和V张量。
- Q = XWq | (batch_size, seq_length, d_model) x (d_model, d_model) = (batch_size, seq_length, d_model)
- K = XWk | (batch_size, seq_length, d_model) x (d_model, d_model) = (batch_size, seq_length, d_model)
- V = XWv | (batch_size, seq_length, d_model) x (d_model, d_model) = (batch_size, seq_length, d_model)
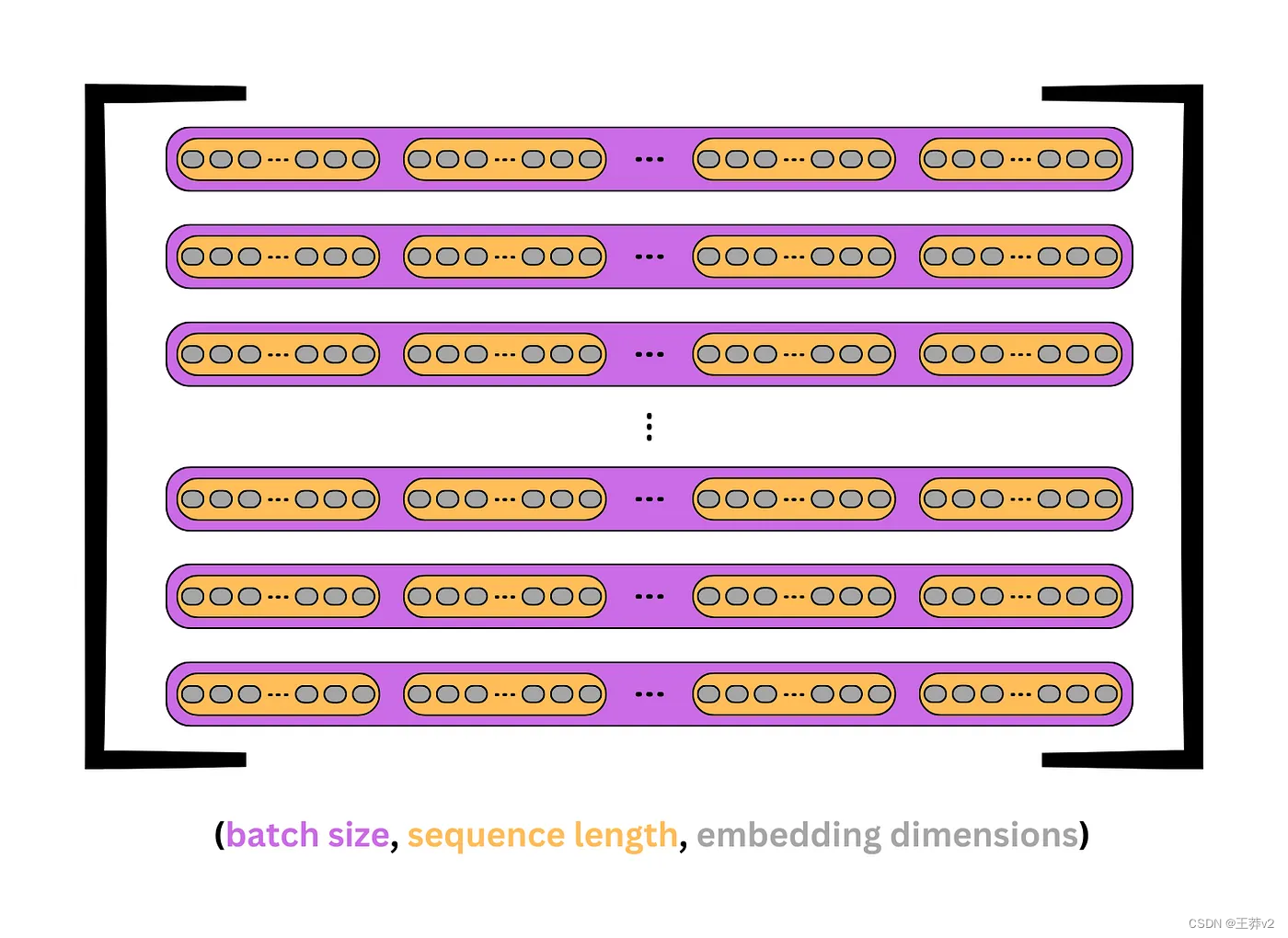
下面的图片显示了Q, K和V是如何出现的。每个紫色盒子代表一个序列,每个橙色盒子是序列中的一个 token 或单词。灰色椭圆表示每个token 的嵌入。
下面的代码加载了Positional Encoding和Embeddings类。
# convert the sequences to integers
sequences = ["I wonder what will come next!",
"This is a basic example paragraph.",
"Hello, what is a basic split?"]
# tokenize the sequences
tokenized_sequences = [tokenize(seq) for seq in sequences]
# index the sequences
indexed_sequences = [[stoi[word] for word in seq] for seq in tokenized_sequences]
# convert the sequences to a tensor
tensor_sequences = torch.tensor(indexed_sequences).long()
# vocab size
vocab_size = len(stoi)
# embedding dimensions
d_model = 8
# create the embeddings
lut = Embeddings(vocab_size, d_model) # look-up table (lut)
# create the positional encodings
pe = PositionalEncoding(d_model=d_model, dropout=0.1, max_length=10)
# embed the sequence
embeddings = lut(tensor_sequences)
# positionally encode the sequences
X = pe(embeddings)
tensor([[[-3.45, -1.34, 4.12, -3.33, -0.81, -1.93, -0.28, 8.25],
[ 7.36, -1.09, 2.32, 1.52, 3.50, 1.42, 0.46, -0.95],
[-2.26, 0.53, -1.02, 1.49, -3.97, -2.19, 2.86, -0.59],
[-3.87, -2.02, 1.46, 6.78, 0.88, 1.08, -2.97, 1.45],
[ 1.12, -2.09, 1.19, 3.87, -0.00, 3.73, -0.88, 1.12],
[-0.35, -0.02, 3.98, -0.20, 7.05, 1.55, 0.00, -0.83]],
[[-4.27, 0.17, -2.08, 0.94, -6.35, 1.99, 5.23, 5.18],
[-0.00, -5.05, -7.19, 3.27, 1.49, -7.11, -0.59, 0.52],
[ 0.54, -2.33, -1.10, -2.02, -0.88, -3.15, 0.38, 5.26],
[ 0.87, -2.98, 2.67, 3.32, 1.16, 0.00, 1.74, 5.28],
[-5.58, -2.09, 0.96, -2.05, -4.23, 2.11, -0.00, 0.61],
[ 6.39, 2.15, -2.78, 2.45, 0.30, 1.58, 2.12, 3.20]],
[[ 4.51, -1.22, 2.04, 3.48, 1.63, 3.42, 1.21, 2.33],
[-2.34, 0.00, -1.13, 1.51, -3.99, -2.19, 2.86, -0.59],
[-4.65, -6.12, -7.08, 3.26, 1.50, -7.11, -0.59, 0.52],
[-0.32, -2.97, -0.99, -2.05, -0.87, -0.00, 0.39, 5.26],
[-0.12, -2.61, 2.77, 3.28, 1.17, 0.00, 1.74, 5.28],
[-5.64, 0.49, 2.32, -0.00, -0.44, 4.06, 3.33, 3.11]]],
grad_fn=<MulBackward0>)
此时,嵌入序列X的形状为(3,6,8)。有3个序列,包含6个标记,具有8维嵌入。
Wq、Wk和Wv的线性层可以使用nn.Linear(d_model, d_model)来创建。这将创建一个(8,8)矩阵,该矩阵将在跨每个序列的乘法期间广播。
Wq = nn.Linear(d_model, d_model) # query weights (8,8)
Wk = nn.Linear(d_model, d_model) # key weights (8,8)
Wv = nn.Linear(d_model, d_model) # value weights (8,8)
Wq.state_dict()['weight']
tensor([[ 0.19, 0.34, -0.12, -0.22, 0.26, -0.06, 0.12, -0.28],
[ 0.09, 0.22, 0.32, 0.11, 0.21, 0.03, -0.35, 0.31],
[-0.34, -0.21, -0.11, 0.34, -0.28, 0.03, 0.26, -0.22],
[-0.35, 0.11, 0.17, 0.21, -0.19, -0.29, 0.22, 0.20],
[ 0.19, 0.04, -0.07, -0.02, 0.01, -0.20, 0.30, -0.19],
[ 0.23, 0.15, 0.22, 0.26, 0.17, 0.16, 0.23, 0.18],
[ 0.01, 0.06, -0.31, 0.19, 0.22, 0.08, 0.15, -0.04],
[-0.11, 0.24, -0.20, 0.26, -0.01, -0.14, 0.29, -0.32]])
Wq的权重如上图所示。Wk和Wv形状相同,但权重不同。当X穿过每一个线性层时,它保持它的形状,但是现在Q, K和V已经被权值转换成唯一的张量。
Q = Wq(X) # (3,6,8)x(broadcast 8,8) = (3,6,8)
K = Wk(X) # (3,6,8)x(broadcast 8,8) = (3,6,8)
V = Wv(X) # (3,6,8)x(broadcast 8,8) = (3,6,8)
Q
tensor([
# sequence 0
[[-3.13, 2.71, -2.07, 3.54, -2.25, -0.26, -2.80, -4.31],
[ 1.70, 1.63, -2.90, -2.90, 1.15, 3.01, 0.49, -1.14],
[-0.69, -2.38, 3.00, 3.09, 0.97, -0.98, -0.10, 2.16],
[-3.52, 2.08, 2.36, 2.16, -2.48, 0.58, 0.33, -0.26],
[-1.99, 1.18, 0.64, -0.45, -1.32, 1.61, 0.28, -1.18],
[ 1.66, 2.46, -2.39, -0.97, -0.47, 1.83, 0.36, -1.06]],
# sequence 1
[[-3.13, -2.43, 3.85, 4.34, -0.60, -0.03, 0.04, 0.62],
[-0.82, -2.67, 1.82, 0.89, 1.30, -2.65, 2.01, 1.56],
[-1.42, 0.11, -1.40, 1.36, -0.21, -0.87, -0.88, -2.24],
[-2.70, 1.88, -0.10, 1.95, -0.75, 2.54, -0.14, -1.91],
[-2.67, -1.58, 2.46, 1.93, -1.78, -2.44, -1.76, -1.23],
[ 1.23, 0.78, -1.93, -1.12, 1.07, 2.98, 1.82, 0.18]],
# sequence 2
[[-0.71, 1.90, -1.12, -0.97, -0.23, 3.54, 0.65, -1.39],
[-0.87, -2.54, 3.16, 3.04, 0.94, -1.10, -0.10, 2.07],
[-2.06, -3.30, 3.63, 2.39, 0.38, -3.87, 1.86, 1.79],
[-2.00, 0.02, -0.90, 0.68, -1.03, -0.63, -0.70, -2.77],
[-2.76, 1.90, 0.14, 2.34, -0.93, 2.38, -0.17, -1.75],
[-1.82, 0.15, 1.79, 2.87, -1.65, 0.97, -0.21, -0.54]]],
grad_fn=<ViewBackward0>)
Q K和V都是这个形状。和前面一样,每个矩阵是一个序列,每一行都是由嵌入表示的 token。
把Q, K, V分成多头
通过创建Q,K和V张量,现在可以通过将D_Model的视图更改为 (n_heads, d_key) 将它们分为各自的头部。N_heads可以是任意数字,但是使用较大的嵌入时,通常要执行8、10或12。请记住,d_key = (d_model / n_heads)。
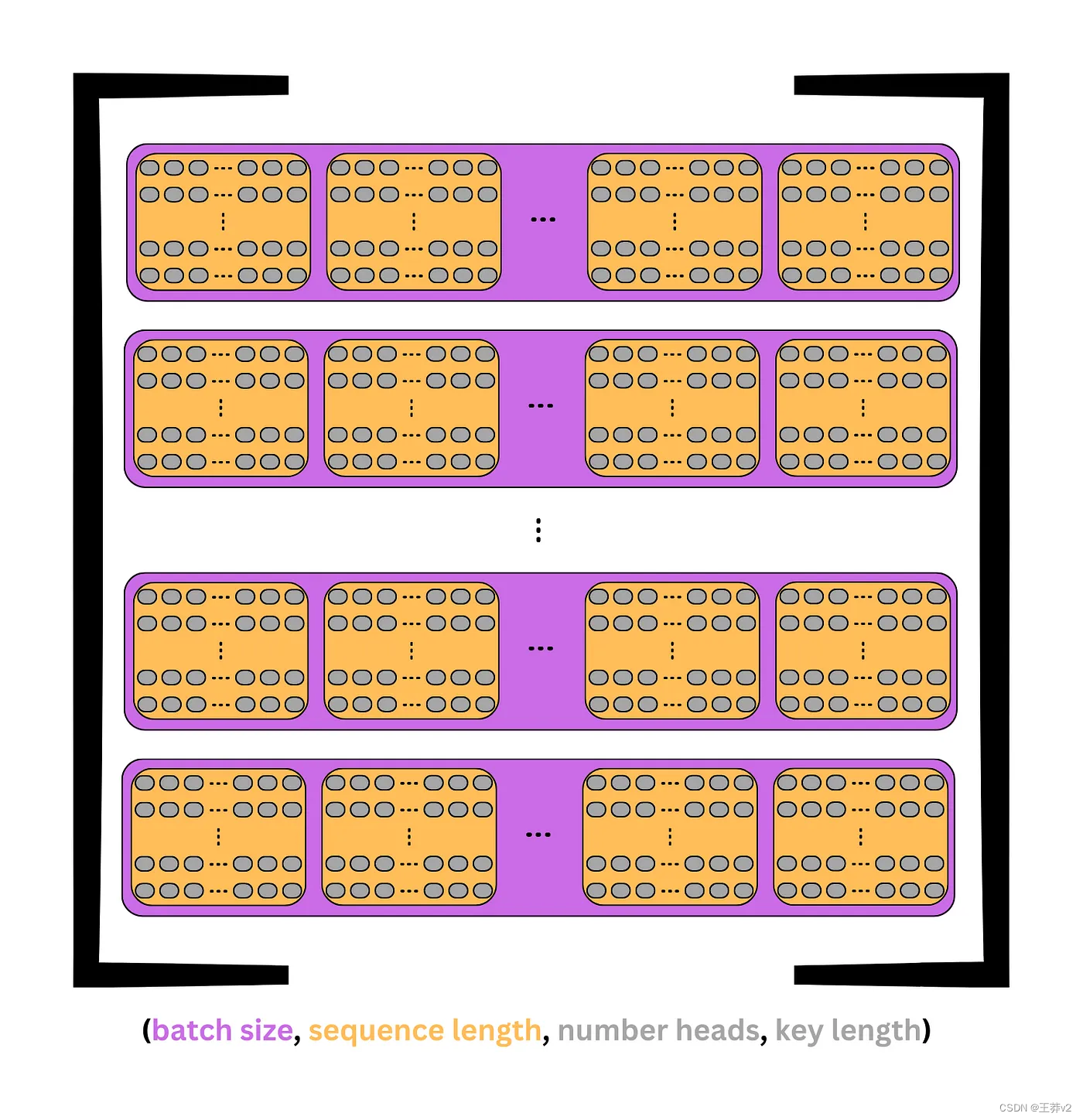
在前面的图像中,每个 token 在单个维度中包含d_model嵌入。现在,这个维度被分成行和列来创建一个矩阵;每行是一个包含键的头。这可以从上面的图片中看到。
每个张量的形状变成:
- (batch_size, seq_length, d_model) → (batch_size, seq_length, n_heads, d_key)
假设示例中选择了四个heads,则(3,6,8)张量将被分成(3,6,4,2)张量,其中有3个序列,每个序列中有6个tokens,每个标记中有4个heads,每个正面中有2个元素。
这可以通过view来实现,它可以用来添加和设置每个维度的大小。由于每个示例的批大小或序列数量是相同的,因此可以设置批大小。同样,在每个张量中,头的数量和键的数量应该是恒定的。-1可用于表示剩余值,即序列长度。
batch_size = Q.size(0)
n_heads = 4
d_key = d_model//n_heads # 8/4 = 2
# query tensor | -1 = query_length | (3, 6, 8) -> (3, 6, 4, 2)
Q = Q.view(batch_size, -1, n_heads, d_key)
# value tensor | -1 = key_length | (3, 6, 8) -> (3, 6, 4, 2)
K = K.view(batch_size, -1, n_heads, d_key)
# value tensor | -1 = value_length | (3, 6, 8) -> (3, 6, 4, 2)
V = V.view(batch_size, -1, n_heads, d_key)
Q
下面是Q张量的例子。这3个序列中的每一个都有6个tokens,每个标记是一个tokens,每个标记有4个head(行)和2个keys。
tensor([
# sequence 0
[[[-3.13, 2.71],
[-2.07, 3.54],
[-2.25, -0.26],
[-2.80, -4.31]],
[[ 1.70, 1.63],
[-2.90, -2.90],
[ 1.15, 3.01],
[ 0.49, -1.14]],
[[-0.69, -2.38],
[ 3.00, 3.09],
[ 0.97, -0.98],
[-0.10, 2.16]],
[[-3.52, 2.08],
[ 2.36, 2.16],
[-2.48, 0.58],
[ 0.33, -0.26]],
[[-1.99, 1.18],
[ 0.64, -0.45],
[-1.32, 1.61],
[ 0.28, -1.18]],
[[ 1.66, 2.46],
[-2.39, -0.97],
[-0.47, 1.83],
[ 0.36, -1.06]]],
# sequence 1
[[[-3.13, -2.43],
[ 3.85, 4.34],
[-0.60, -0.03],
[ 0.04, 0.62]],
[[-0.82, -2.67],
[ 1.82, 0.89],
[ 1.30, -2.65],
[ 2.01, 1.56]],
[[-1.42, 0.11],
[-1.40, 1.36],
[-0.21, -0.87],
[-0.88, -2.24]],
[[-2.70, 1.88],
[-0.10, 1.95],
[-0.75, 2.54],
[-0.14, -1.91]],
[[-2.67, -1.58],
[ 2.46, 1.93],
[-1.78, -2.44],
[-1.76, -1.23]],
[[ 1.23, 0.78],
[-1.93, -1.12],
[ 1.07, 2.98],
[ 1.82, 0.18]]],
# sequence 2
[[[-0.71, 1.90],
[-1.12, -0.97],
[-0.23, 3.54],
[ 0.65, -1.39]],
[[-0.87, -2.54],
[ 3.16, 3.04],
[ 0.94, -1.10],
[-0.10, 2.07]],
[[-2.06, -3.30],
[ 3.63, 2.39],
[ 0.38, -3.87],
[ 1.86, 1.79]],
[[-2.00, 0.02],
[-0.90, 0.68],
[-1.03, -0.63],
[-0.70, -2.77]],
[[-2.76, 1.90],
[ 0.14, 2.34],
[-0.93, 2.38],
[-0.17, -1.75]],
[[-1.82, 0.15],
[ 1.79, 2.87],
[-1.65, 0.97],
[-0.21, -0.54]]]], grad_fn=<ViewBackward0>)
为了继续,最好将序列长度和n个头(第二次和第三次)调换成以下形状
- (batch_size, seq_length, n_heads, d_key) → (batch_size, n_heads, seq_length, d_key)
现在,每个序列被分成n_heads,每个头接收seq_length长度token中的d_key个元素,而不是d_model个。这达到了研究人员在不同位置关注来自不同表示子空间的信息的目的。
这个张量的可视化如下图所示。每个序列是紫色的,每个头是灰色的。在头部中,每个标记是一行d_key元素。
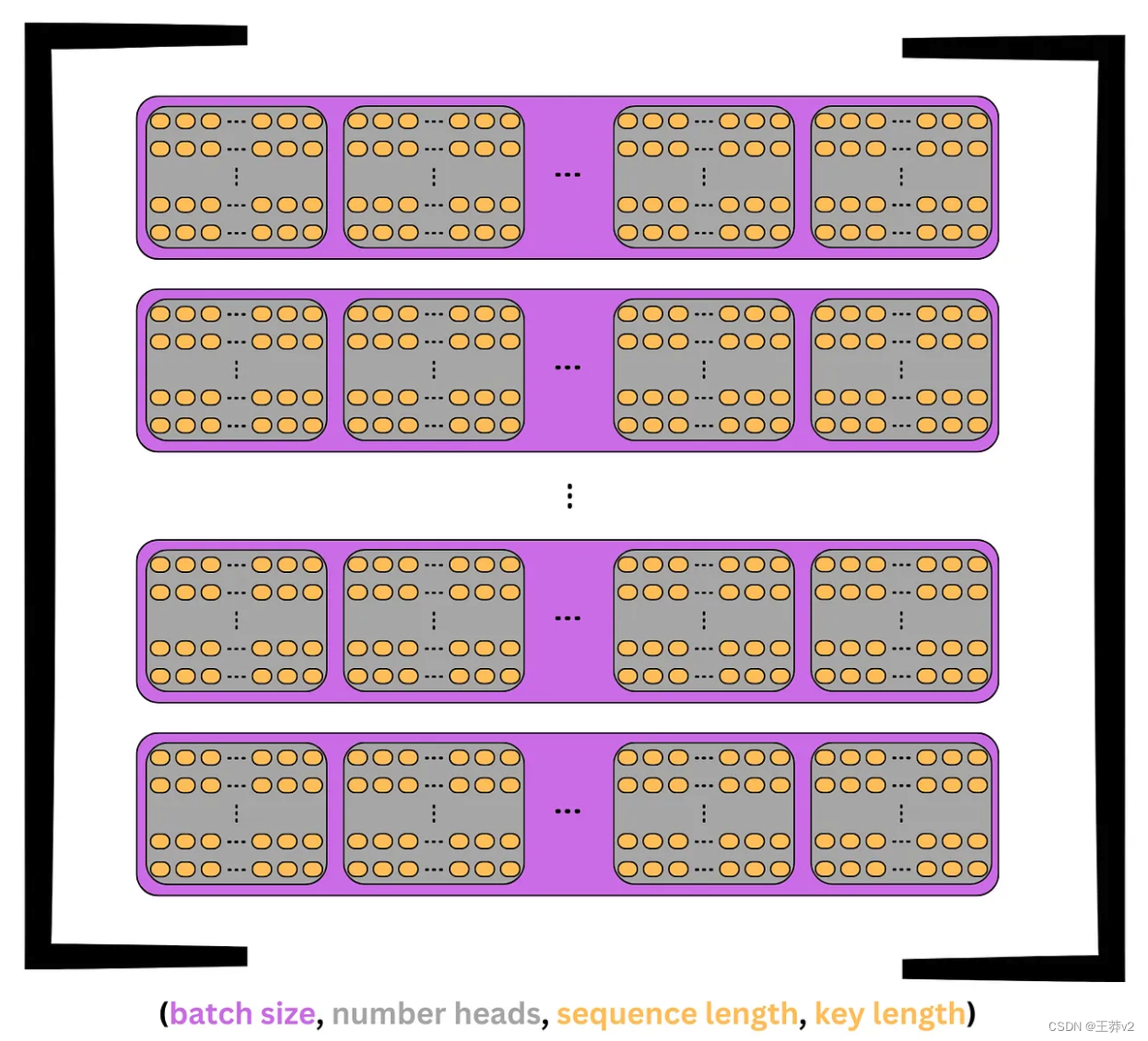
回到前面的例子,Q张量将从(3,6,4,2)转置到(3,4,6,2)。这个张量现在将表示3个序列,每个序列分为n_heads= 4,每个头包含 seq_length= 6个tokens,每个tokens有一个 d_key = 2元素键。
本质上,每个头部都包含每个序列 tokens 的副本,但它只有一个 d_key= 2的元素表示,而不是完整的d_model= 8的元素表示。这意味着每个序列同时在n_head= 4个不同的子空间中表示。
下面的代码使用permute来切换每个张量的第二轴和第三轴。
# query tensor | (3, 6, 4, 2) -> (3, 4, 6, 2)
Q = Q.permute(0, 2, 1, 3)
# key tensor | (3, 6, 4, 2) -> (3, 4, 6, 2)
K = K.permute(0, 2, 1, 3)
# value tensor | (3, 6, 4, 2) -> (3, 4, 6, 2)
V = V.permute(0, 2, 1, 3)
Q
tensor([
# sequence 0
[[[-3.13, 2.71],
[ 1.70, 1.63],
[-0.69, -2.38],
[-3.52, 2.08],
[-1.99, 1.18],
[ 1.66, 2.46]],
[[-2.07, 3.54],
[-2.90, -2.90],
[ 3.00, 3.09],
[ 2.36, 2.16],
[ 0.64, -0.45],
[-2.39, -0.97]],
[[-2.25, -0.26],
[ 1.15, 3.01],
[ 0.97, -0.98],
[-2.48, 0.58],
[-1.32, 1.61],
[-0.47, 1.83]],
[[-2.80, -4.31],
[ 0.49, -1.14],
[-0.10, 2.16],
[ 0.33, -0.26],
[ 0.28, -1.18],
[ 0.36, -1.06]]],
# sequence 1
[[[-3.13, -2.43],
[-0.82, -2.67],
[-1.42, 0.11],
[-2.70, 1.88],
[-2.67, -1.58],
[ 1.23, 0.78]],
[[ 3.85, 4.34],
[ 1.82, 0.89],
[-1.40, 1.36],
[-0.10, 1.95],
[ 2.46, 1.93],
[-1.93, -1.12]],
[[-0.60, -0.03],
[ 1.30, -2.65],
[-0.21, -0.87],
[-0.75, 2.54],
[-1.78, -2.44],
[ 1.07, 2.98]],
[[ 0.04, 0.62],
[ 2.01, 1.56],
[-0.88, -2.24],
[-0.14, -1.91],
[-1.76, -1.23],
[ 1.82, 0.18]]],
# sequence 2
[[[-0.71, 1.90],
[-0.87, -2.54],
[-2.06, -3.30],
[-2.00, 0.02],
[-2.76, 1.90],
[-1.82, 0.15]],
[[-1.12, -0.97],
[ 3.16, 3.04],
[ 3.63, 2.39],
[-0.90, 0.68],
[ 0.14, 2.34],
[ 1.79, 2.87]],
[[-0.23, 3.54],
[ 0.94, -1.10],
[ 0.38, -3.87],
[-1.03, -0.63],
[-0.93, 2.38],
[-1.65, 0.97]],
[[ 0.65, -1.39],
[-0.10, 2.07],
[ 1.86, 1.79],
[-0.70, -2.77],
[-0.17, -1.75],
[-0.21, -0.54]]]], grad_fn=<PermuteBackward0>)
虽然拥有完整的视图很好,但通过检查单个序列更容易理解。
很容易在这个序列中看到四个heads。每个头包含六行,这是 tokens,每行有两个元素,这是键。这显示了如何将序列拆分为四个子空间,以创建同一序列的不同表示。
# select the first sequence from the Query tensor
Q[0]
tensor([
# head 0
[[-3.13, 2.71],
[ 1.70, 1.63],
[-0.69, -2.38],
[-3.52, 2.08],
[-1.99, 1.18],
[ 1.66, 2.46]],
# head 1
[[-2.07, 3.54],
[-2.90, -2.90],
[ 3.00, 3.09],
[ 2.36, 2.16],
[ 0.64, -0.45],
[-2.39, -0.97]],
# head 2
[[-2.25, -0.26],
[ 1.15, 3.01],
[ 0.97, -0.98],
[-2.48, 0.58],
[-1.32, 1.61],
[-0.47, 1.83]],
# head 3
[[-2.80, -4.31],
[ 0.49, -1.14],
[-0.10, 2.16],
[ 0.33, -0.26],
[ 0.28, -1.18],
[ 0.36, -1.06]]], grad_fn=<SelectBackward0>)
计算注意力
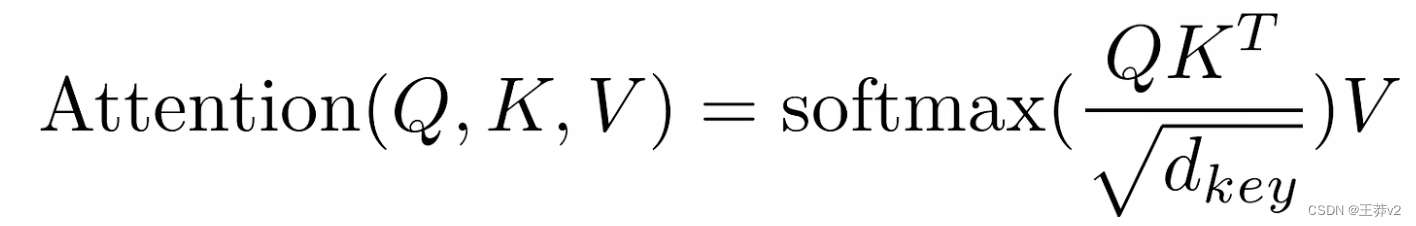
将Q, K和V分成多个头,现在可以计算Q和K的标量点积。上面的等式表明,第一步是执行张量乘法。然而,K必须先转置。
接下来,为了清晰起见,每个张量的seq长度形状将通过其各自的张量,Q_length,K_length 或 V_length 来知道
- Q has a shape of (batch_size, n_heads, Q_length, d_key)
- K has a shape of (batch_size, n_heads, K_length, d_key)
- V has a shape of (batch_size, n_heads, V_length, d_key)
K最右边的两个维度必须调换,以改变形状为(batch_size, n_heads, d_key, K_length)。
现在, Q K T QK^T QKT的输出是
- (batch_size, n_heads, Q_length, d_key) x (batch_size, n_heads, d_key, K_length) = (batch_size, n_heads, Q_length, K_length)
每个张量中的相应序列将相互乘法。Q中的第一个序列将乘以K中的第一个序列,Q中的第二个序列与K中的第二个序列相乘。当这些序列相互相乘时,每个头将在相反的张量中与相应的头相乘。Q的第一个序列的第一个头将与K的第一个序列的第一个头相乘,Q的第一个序列的第二个头与K的第一个序列的第二个头相乘。在乘以这些头时,Q头中每个形状为(Q_length,d_key)的token与K头中的每个token相乘,形状为(d_key,K_length)。结果是一个(Q-length,K_length)矩阵,显示每个单词与包括自身在内的所有其他单词的强度。这就是“self-attention”这个名字的来源,因为模型通过将单词乘以另一个自身表示来发现哪些单词与序列最相关。
Q K T QK^T QKT由 d_key 缩放,以帮助使softmax函数在下一步的输出不那么集中在0和1附近。在未缩放分布中,接近0和1的值更接近分布的中间。
继续这个例子,缩放后的点积的输出形状为(3, 4, 6, 2) x (3, 4, 2, 6) = (3, 4, 6, 6)。
# calculate scaled dot product
scaled_dot_prod = torch.matmul(Q, K.permute(0, 1, 3, 2)) / math.sqrt(d_key) # (batch_size, n_heads, Q_length, K_length)
这个张量然后通过softmax函数来创建一个概率分布。请注意softmax是如何应用于每个头部中每个矩阵的每一行的。softmax维度可以设置为-1或3,因为两者都表示形状中最右边的维度,即键。
# apply softmax to get context for each token and others
attn_probs = torch.softmax(scaled_dot_prod, dim=-1) # (batch_size, n_heads, Q_length, K_length)
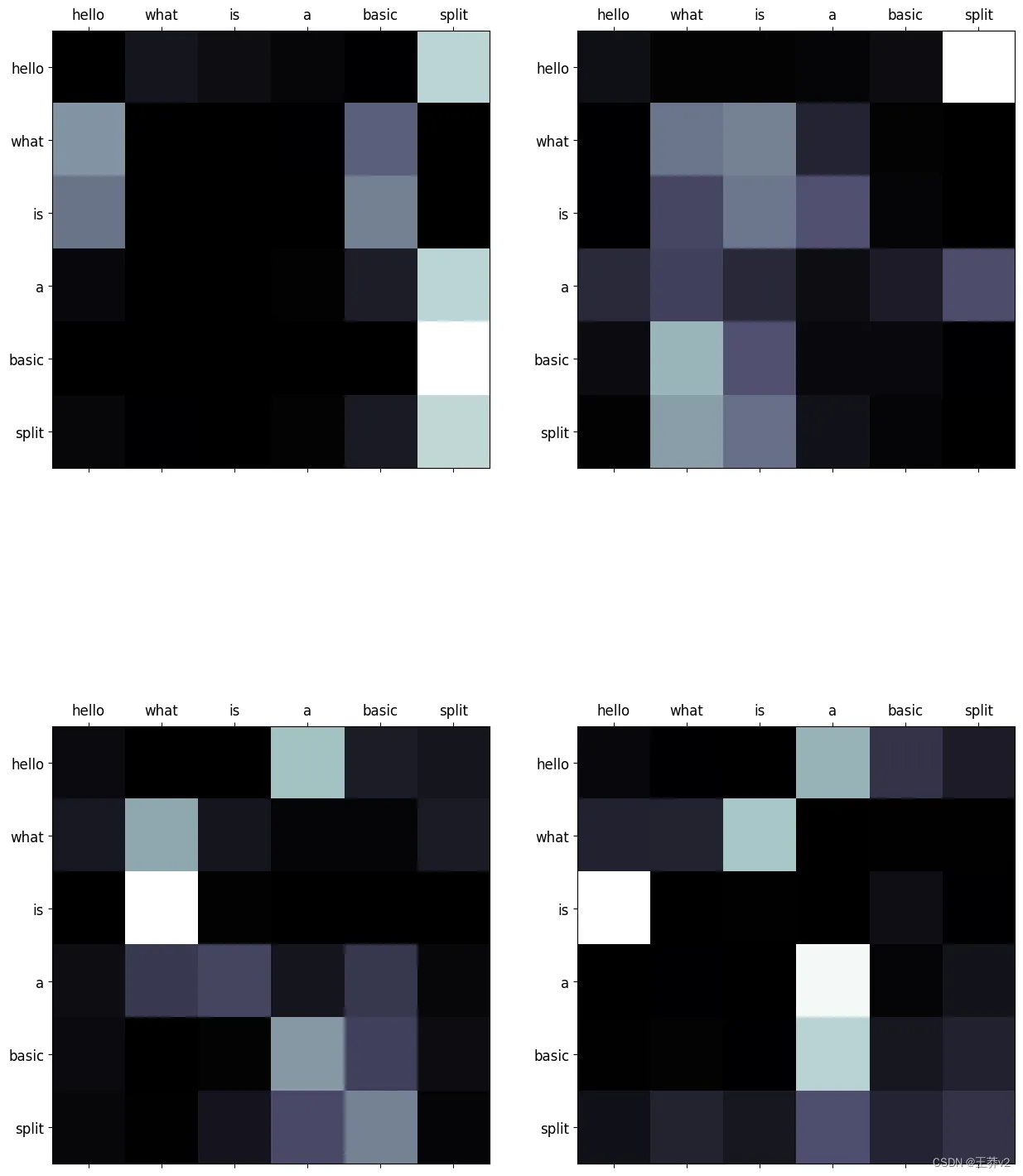
这些注意概率可以使用来自matplotlib的imshow可视化。可以在附录中找到同时显示序列的所有头部的函数,称为display_attention。白色更接近于1,黑色更接近于0。
# sequence 0
display_attention(["i", "wonder", "what", "will", "come", "next"],
["i", "wonder", "what", "will", "come", "next"],
attn_probs[0], 4, 2, 2)

# sequence 1
display_attention(["this", "is", "a", "basic", "example", "paragraph"],
["this", "is", "a", "basic", "example", "paragraph"],
attn_probs[1], 4, 2, 2)
# sequence 2
display_attention(["hello", "what", "is", "a", "basic", "split"],
["hello", "what", "is", "a", "basic", "split"],
attn_probs[2], 4, 2, 2)
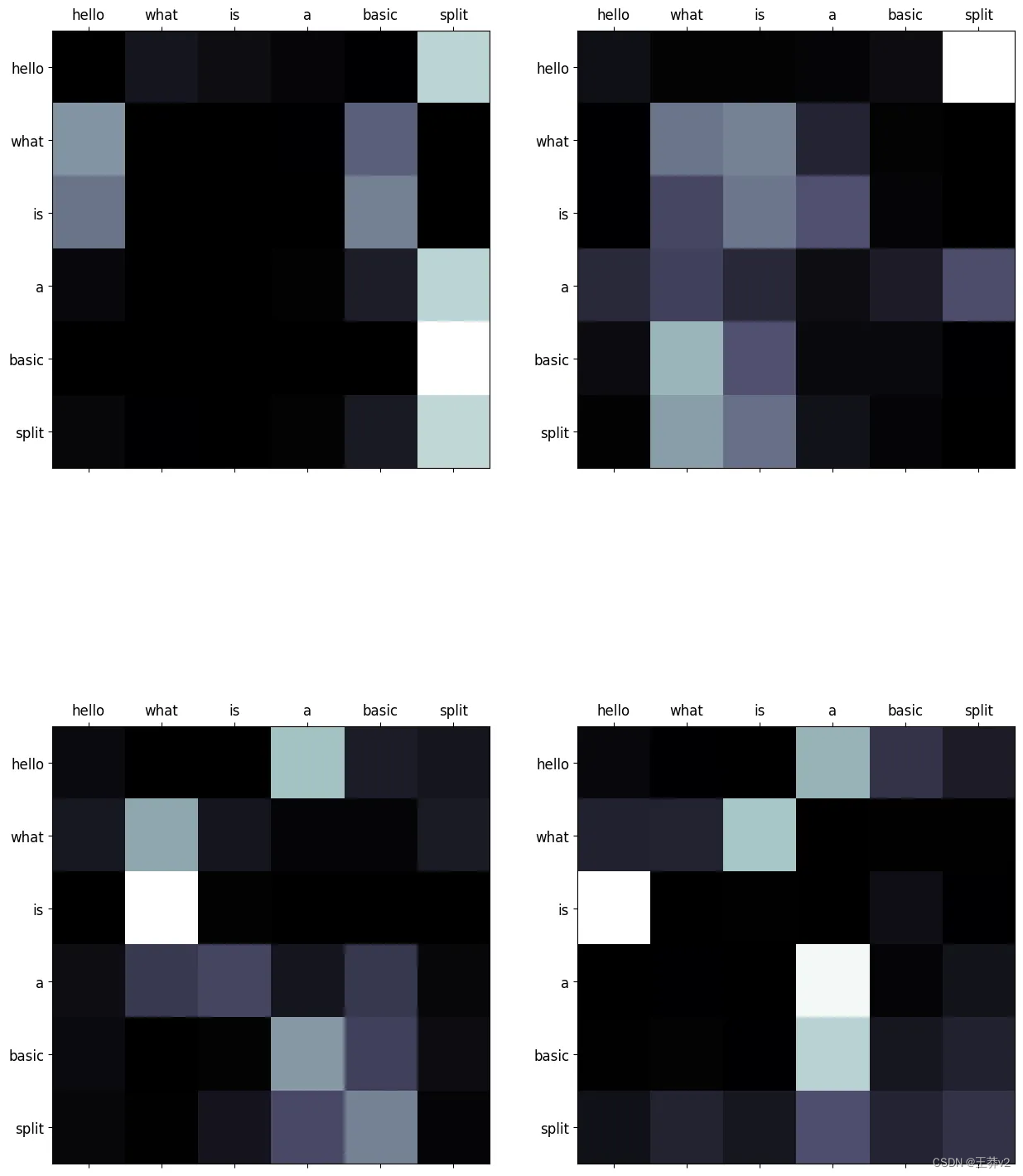
它们演示了每个query(row)和key(column)之间的关系。序列中单词之间的每个交集都代表了关系的强度。由于这些值是从随机权重生成的,因此它们目前没有显示任何有效的关系。下图展示了编码器经过训练后这些矩阵的样子。

计算出这些概率后,下一步是将它们与V张量相乘,以创建这些分布的总结。每个单词的上下文本质上是聚合的。

# multiply attention and values to get reweighted values
A = torch.matmul(attn_probs, V) # (batch_size, n_heads, Q_length, d_key)
下面是这个示例的每个步骤的图表。
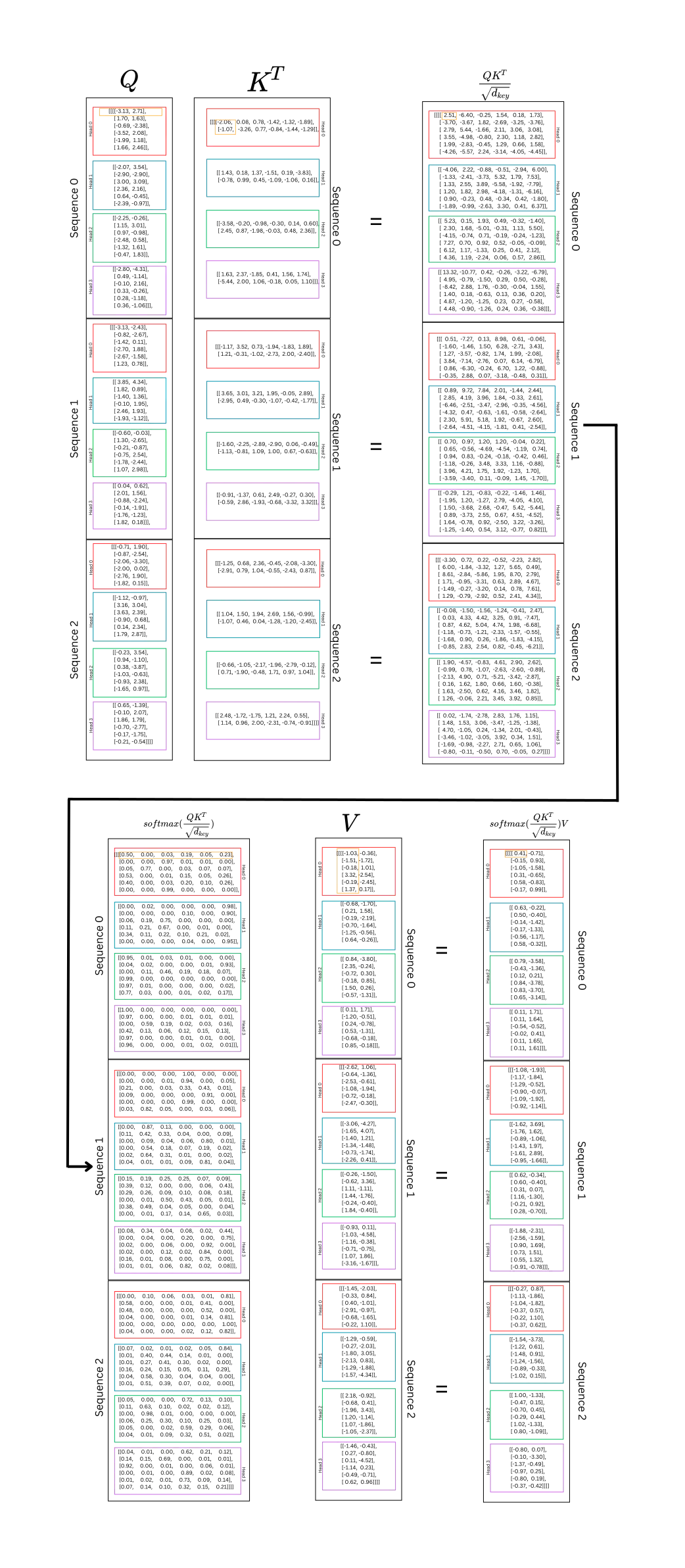
这里到底发生了什么:好吧,Q和K都是同一序列的表示,分为不同头部的query和key组件。这计算了序列中每个单词与序列中所有其他单词之间的关系。这发生在 n_heads 子空间中。计算每个单词的query表示和每个单词的key表示之间的点积。这表示每个单词和其他单词之间的“强度”或“重量”。通过训练,这种力量将帮助模型理解哪些单词之间应该有更高的“权重”;这将表明哪些单词对上下文和预测最重要。再次强调,query与key相乘,以在每个token和序列中的所有其他token之间生成权重。
softmax张量中的每一行都表示一个token与同一序列中的其他token之间的关系。在V中,每一列是序列的一个表示。将两个张量相乘以重新加权值,并计算每个头或子空间中每个token的最重要上下文的摘要。
下面的图表显示了序列中单个头部的 self-attention。

Passing It Through the Output Layer
此时,在通过最后的线性层(即多头注意机制中的最后一层)之前,这些头部可以重新连接在一起。
串联将反转最初执行的分割。第一步是n_heads和Q_length的转置。第二步是将 n_heads 和 d_key 连接起来,得到 d_model。
一旦完成,A将具有 (batch_size, Q_length, d_model) 的形状。
# transpose from (3, 4, 6, 2) -> (3, 6, 4, 2)
A = A.permute(0, 2, 1, 3).contiguous()
# reshape from (3, 6, 4, 2) -> (3, 6, 8) = (batch_size, Q_length, d_model)
A = A.view(batch_size, -1, n_heads*d_key)
A
tensor([[[ 0.41, -0.71, 0.63, -0.22, 0.79, -3.58, 0.11, 1.71],
[-0.15, 0.93, 0.50, -0.40, -0.43, -1.36, 0.11, 1.64],
[-1.05, -1.58, -0.14, -1.42, 0.12, 0.21, -0.54, -0.52],
[ 0.31, -0.65, -0.17, -1.33, 0.84, -3.78, -0.02, 0.41],
[ 0.58, -0.83, -0.56, -1.17, 0.83, -3.70, 0.11, 1.65],
[-0.17, 0.99, 0.58, -0.32, 0.65, -3.14, 0.11, 1.61]],
[[-1.08, -1.93, -1.62, 3.69, 0.62, -0.34, -1.88, -2.31],
[-1.17, -1.84, -1.76, 1.62, 0.60, -0.40, -2.56, -1.59],
[-1.29, -0.52, -0.89, -1.06, 0.31, 0.07, 0.90, 1.69],
[-0.90, -0.07, -1.43, 1.97, 1.16, -1.30, 0.73, 1.51],
[-1.09, -1.92, -1.61, 2.89, -0.21, 0.92, 0.55, 1.32],
[-0.92, -1.14, -0.95, -1.66, 0.28, -0.70, -0.91, -0.78]],
[[-0.27, 0.87, -1.54, -3.73, 1.00, -1.33, -0.80, 0.07],
[-1.13, -1.86, -1.22, 0.61, -0.47, 0.15, -0.10, -3.30],
[-1.04, -1.82, -1.48, 0.91, -0.70, 0.45, -1.37, -0.49],
[-0.37, 0.57, -1.24, -1.56, -0.29, 0.44, -0.97, 0.25],
[-0.22, 1.10, -0.89, -0.33, 1.02, -1.33, -0.80, 0.19],
[-0.37, 0.62, -1.02, 0.15, 0.80, -1.09, -0.37, -0.42]]],
grad_fn=<ViewBackward0>)
最后一步是让A通过Wo,它的形状为 (d_model, d_model)。同样,权重张量在批处理中的每个序列中广播。最后的输出保持其形状

Wo = nn.Linear(d_model, d_model)
# (3, 6, 8) x (broadcast 8, 8) = (3, 6, 8)
output = Wo(A)
tensor([[[-0.39, -0.45, -0.17, 0.18, -0.24, -1.68, -0.35, -0.56],
[ 0.38, 0.02, 0.28, -0.42, -0.70, -0.81, 0.05, 0.03],
[ 1.01, -0.72, 0.12, 0.18, 1.20, -0.29, 1.10, -0.59],
[-0.50, -0.84, -0.07, 0.22, 0.49, -1.58, 0.13, -0.90],
[-0.15, -0.95, -0.35, 0.17, 0.15, -1.65, -0.27, -0.79],
[-0.47, -0.04, 0.15, 0.03, -0.83, -1.24, -0.04, -0.15]],
[[-1.29, -0.85, -1.02, 1.56, 0.32, -0.08, -0.14, 0.40],
[-0.45, -1.19, -0.70, 1.23, 0.75, -0.42, 0.46, -0.38],
[ 1.33, -0.58, -0.34, 0.10, -0.13, 0.15, 0.44, 0.38],
[-0.42, -0.32, -0.97, 0.89, -1.19, 0.01, -0.66, 1.11],
[ 0.66, -0.75, -1.36, 0.73, -0.69, 0.47, -0.79, 1.29],
[ 0.60, -1.03, 0.01, 0.29, 1.20, -0.50, 1.07, -0.78]],
[[ 0.61, -0.66, 0.54, -0.06, 0.97, -0.68, 1.30, -1.08],
[-0.22, -1.02, -0.38, 0.62, 1.46, 0.30, 0.74, 0.10],
[ 0.67, -1.23, -0.65, 0.47, 0.58, -0.18, 0.31, -0.09],
[ 0.94, -0.43, 0.30, -0.22, 0.40, -0.23, 0.78, -0.36],
[-0.46, -0.03, 0.16, 0.37, -0.23, -0.55, 0.34, -0.11],
[-0.54, -0.15, -0.03, 0.46, -0.06, -0.29, 0.26, 0.13]]],
grad_fn=<ViewBackward0>)
该输出将传递到下一层,其中包括残差加法和layer normalization。这些将在后面的文章中讨论。
Multi-Head Attention in Transformers
在解释了多头注意力的每个组件之后,实现就很简单了,并且使用了前面列出的相同组件。唯一增加的是一个dropout层。
代码中有一个掩码的实现,但现在可以忽略它。它不会对实现之后的示例产生影响。当描述编码器和解码器时,将对此进行解释。
请注意,在这个实现中,Q、K和V张量是同时分割和排列的,这与上面的实现不同。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int = 512, n_heads: int = 8, dropout: float = 0.1):
"""
Args:
d_model: dimension of embeddings
n_heads: number of self attention heads
dropout: probability of dropout occurring
"""
super().__init__()
assert d_model % n_heads == 0 # ensure an even num of heads
self.d_model = d_model # 512 dim
self.n_heads = n_heads # 8 heads
self.d_key = d_model // n_heads # assume d_value equals d_key | 512/8=64
self.Wq = nn.Linear(d_model, d_model) # query weights
self.Wk = nn.Linear(d_model, d_model) # key weights
self.Wv = nn.Linear(d_model, d_model) # value weights
self.Wo = nn.Linear(d_model, d_model) # output weights
self.dropout = nn.Dropout(p=dropout) # initialize dropout layer
def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Tensor = None):
"""
Args:
query: query vector (batch_size, q_length, d_model)
key: key vector (batch_size, k_length, d_model)
value: value vector (batch_size, s_length, d_model)
mask: mask for decoder
Returns:
output: attention values (batch_size, q_length, d_model)
attn_probs: softmax scores (batch_size, n_heads, q_length, k_length)
"""
batch_size = key.size(0)
# calculate query, key, and value tensors
Q = self.Wq(query) # (32, 10, 512) x (512, 512) = (32, 10, 512)
K = self.Wk(key) # (32, 10, 512) x (512, 512) = (32, 10, 512)
V = self.Wv(value) # (32, 10, 512) x (512, 512) = (32, 10, 512)
# split each tensor into n-heads to compute attention
# query tensor
Q = Q.view(batch_size, # (32, 10, 512) -> (32, 10, 8, 64)
-1, # -1 = q_length
self.n_heads,
self.d_key
).permute(0, 2, 1, 3) # (32, 10, 8, 64) -> (32, 8, 10, 64) = (batch_size, n_heads, q_length, d_key)
# key tensor
K = K.view(batch_size, # (32, 10, 512) -> (32, 10, 8, 64)
-1, # -1 = k_length
self.n_heads,
self.d_key
).permute(0, 2, 1, 3) # (32, 10, 8, 64) -> (32, 8, 10, 64) = (batch_size, n_heads, k_length, d_key)
# value tensor
V = V.view(batch_size, # (32, 10, 512) -> (32, 10, 8, 64)
-1, # -1 = v_length
self.n_heads,
self.d_key
).permute(0, 2, 1, 3) # (32, 10, 8, 64) -> (32, 8, 10, 64) = (batch_size, n_heads, v_length, d_key)
# computes attention
# scaled dot product -> QK^{T}
scaled_dot_prod = torch.matmul(Q, # (32, 8, 10, 64) x (32, 8, 64, 10) -> (32, 8, 10, 10) = (batch_size, n_heads, q_length, k_length)
K.permute(0, 1, 3, 2)
) / math.sqrt(self.d_key) # sqrt(64)
# fill those positions of product as (-1e10) where mask positions are 0
if mask is not None:
scaled_dot_prod = scaled_dot_prod.masked_fill(mask == 0, -1e10)
# apply softmax
attn_probs = torch.softmax(scaled_dot_prod, dim=-1)
# multiply by values to get attention
A = torch.matmul(self.dropout(attn_probs), V) # (32, 8, 10, 10) x (32, 8, 10, 64) -> (32, 8, 10, 64)
# (batch_size, n_heads, q_length, k_length) x (batch_size, n_heads, v_length, d_key) -> (batch_size, n_heads, q_length, d_key)
# reshape attention back to (32, 10, 512)
A = A.permute(0, 2, 1, 3).contiguous() # (32, 8, 10, 64) -> (32, 10, 8, 64)
A = A.view(batch_size, -1, self.n_heads*self.d_key) # (32, 10, 8, 64) -> (32, 10, 8*64) -> (32, 10, 512) = (batch_size, q_length, d_model)
# push through the final weight layer
output = self.Wo(A) # (32, 10, 512) x (512, 512) = (32, 10, 512)
return output, attn_probs # return attn_probs for visualization of the scores
现在,可以将它与嵌入层和位置编码层一起使用,以生成与本文类似的输出。将使用相同的示例,但将使用该类生成不同的输出。记住,这假设Embeddings和PositionalEncoding模块与MultiHeadAttention模块一起加载。
torch.set_printoptions(precision=2, sci_mode=False)
# convert the sequences to integers
sequences = ["I wonder what will come next!",
"This is a basic example paragraph.",
"Hello, what is a basic split?"]
# tokenize the sequences
tokenized_sequences = [tokenize(seq) for seq in sequences]
# index the sequences
indexed_sequences = [[stoi[word] for word in seq] for seq in tokenized_sequences]
# convert the sequences to a tensor
tensor_sequences = torch.tensor(indexed_sequences).long()
# vocab size
vocab_size = len(stoi)
# embedding dimensions
d_model = 8
# create the embeddings
lut = Embeddings(vocab_size, d_model) # look-up table (lut)
# create the positional encodings
pe = PositionalEncoding(d_model=d_model, dropout=0.1, max_length=10)
# embed the sequence
embeddings = lut(tensor_sequences)
# positionally encode the sequences
X = pe(embeddings)
# set the n_heads
n_heads = 4
# create the attention layer
attention = MultiHeadAttention(d_model, n_heads, dropout=0.1)
# pass X through the attention layer three times to create Q, K, and V
output, attn_probs = attention(X, X, X, mask=None)
output
正如预期的那样,输出的形状与输入的形状相同,即(3,6,8)。
tensor([[[-0.54, 0.58, -0.86, 0.72, 0.73, 0.26, 0.22, -1.31],
[-0.88, -0.50, 0.06, -1.04, 0.79, 0.05, 0.78, -1.34],
[-2.34, 0.46, 0.84, 0.15, 1.22, 1.25, 1.99, -1.55],
[-2.69, 0.17, 0.57, 0.20, 1.44, 1.89, 1.99, -1.95],
[-0.00, -1.09, 0.21, -0.90, 1.34, -0.32, -0.30, -0.81],
[-1.25, -0.88, 0.85, -0.05, 1.54, 0.11, 0.77, -1.59]],
[[-0.36, -0.52, -0.66, -0.71, -0.46, 0.83, 0.68, 0.19],
[-0.45, -0.04, -0.76, -0.12, 0.21, 1.05, 0.54, -0.12],
[-0.97, 0.15, -0.32, -0.14, -0.07, 0.96, 1.07, -0.42],
[ 0.06, -0.69, -0.71, -0.72, 0.04, 0.32, 0.20, 0.13],
[-0.40, 0.14, -0.48, 0.36, -0.85, 0.72, 0.77, 0.45],
[-0.17, -0.69, -0.45, -0.98, -0.15, 0.14, 0.52, -0.04]],
[[ 0.57, 0.26, -0.24, 0.44, 0.08, -0.66, -0.37, -0.23],
[-0.33, 0.75, 0.58, 0.06, 0.32, -0.63, 0.55, -0.10],
[-0.50, 0.46, -0.64, 0.87, 0.65, 0.85, 0.29, -0.60],
[ 1.54, 0.43, 1.51, 0.09, -0.19, -2.58, -0.84, 1.40],
[ 1.46, -0.38, -0.51, -0.06, 0.04, -0.83, -1.10, 1.08],
[-0.28, 1.85, 0.19, 1.38, -0.69, -0.01, 0.55, -0.11]]],
grad_fn=<ViewBackward0>)
来自注意力的概率也可以使用注意力问题来预览。下面是第一个序列的heads的注意力分布。
display_attention(["i", "wonder", "what", "will", "come", "next"],
["i", "wonder", "what", "will", "come", "next"],
attn_probs[0], 4, 2, 2)

Supplementary Images of Attention
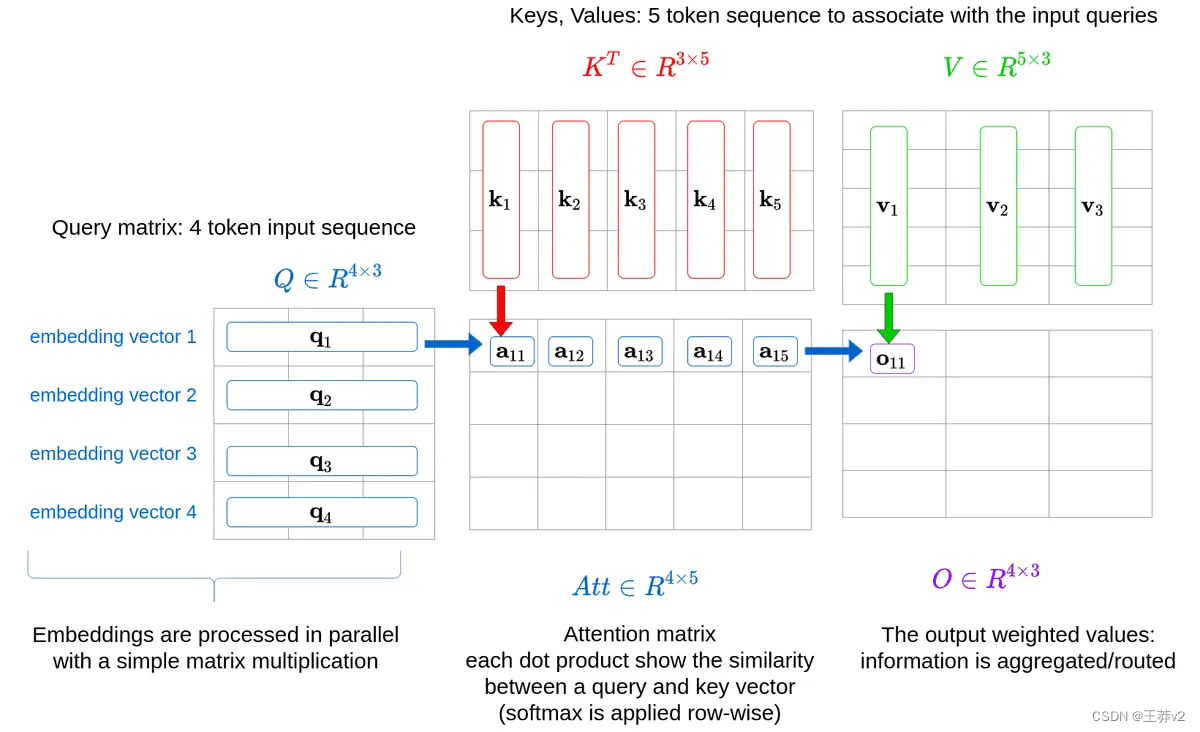
这是多头注意力计算的另一种view。下图是如何在同一序列的不同表示之间计算softmax的示例。
















 5093
5093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









