







ACL 2020
概要
由于标签具有结构信息,层次文本分类一直是多标签分类下的一个挑战。目前存在的方法对全局标签的结构进行建模都有一定的困难,并且不能充分利用文本特征空间与标签空间的交互信息。本文将层次结构视为一个有向图,使用层次敏感的结构编码器(structure encoders)来对标签间的依赖关系进行建模。并基于该编码器,提出了一个端到端的分层感知全局模型(HiAGM),及其两个变体:HiAGM-LA和HiAGM-TP。HiAGM-LA通过层次结构编码器学习层次敏感的label embedding,并对label-aware的文本特征进行归纳融合,而HiAGM-TP则直接将文本特征送入到层次编码器。
介绍
问题:
目前对于层次文本分类主要存在两种方法:基于局部和基于全局。基于局部的方法就是为每一层都构建一个分类器,但此类方法会导致参数过多和由于缺少全局层次结构信息带来的曝光偏差问题。基于全局的方法就是对所有类别都使用同一个分类器,该类方法提出了各种各样的策略来从上到下的利用结构信息,但目前为止没有一种全局性的方法能够将整体标签结构视为标签的相关特征的编码方式,而且以往的方法忽略了细粒度的标签相关信息。
IDEA :
本文将层次结构视为有向图,将标签依赖关系的先验概率汇总到节点信息,提出HiAGM使用标签的结构特征来增强层次信息。该模型包括一个传统的text encoder(用于提取层次信息)和一个层次敏感的structure encoder(用于对层次标签的关系进行建模)。其中structure encoder是一个集成了先验知识的TreeLSTM或者hierarchy-GCN(GCN 图卷积神经网络 跟GNN相似 只是在聚合信息方式上不同 引入了一些新的方法 如注意力等)。
为了结合文本特征和标签的结构特征,作者提出了HiAGM的两个变体,HiAGM-LA(提取标签文本特征)和HiAGM-TP(将文本信息传播到整个层次结构中。整个层次结构中每个节点的隐藏状态代表了特定类别的文本信息)。前者更新整个层次的标签结构并使用节点的输出作为层次意识的标签表征。
方法
该模型的整体结构如下图所示:
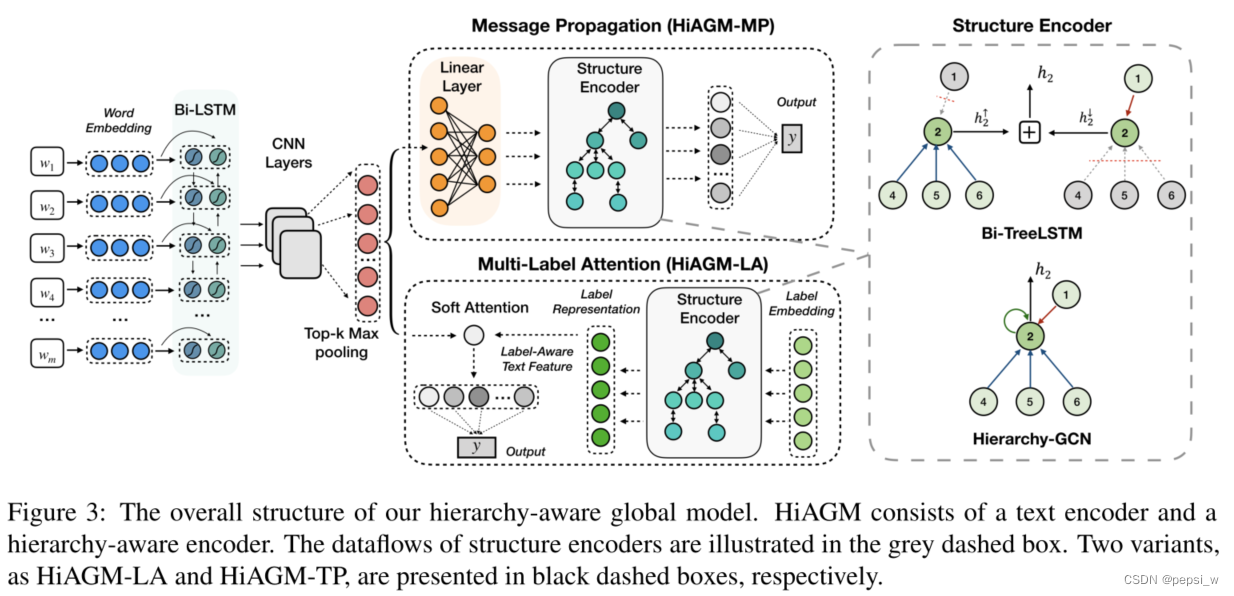
先验层次信息
HiAGM利用关于预先定义的层次结构和语料库中标签相关性的先验知识,即将标签之间依赖关系的先验概率作为先验层次结构信息,如下图所示:
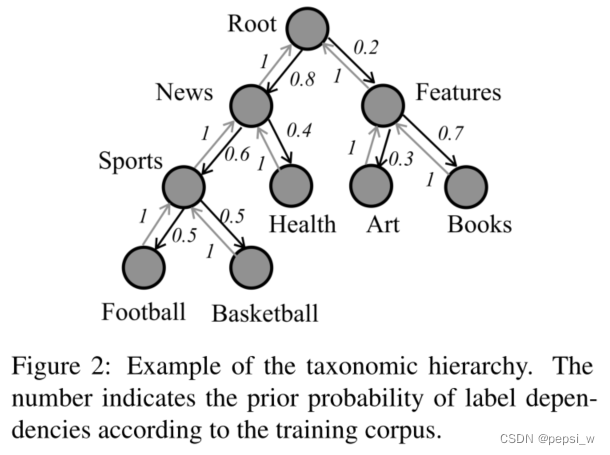
假设节点vj是节点vi的子节点,则节点之间的先验概率计算公式如下,即父节点到子节点的先验概率为在先验知识中,父节点发生的情况下子节点出现的概率。相应地,子节点到其父节点的概率为子节点发生的情况下其父节点出现的概率,很明显每个子节点到其父节点的概率都为1。
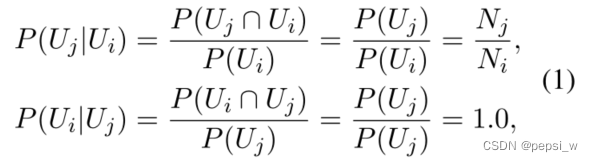
层次敏感的结构编码器(Hierarchy-Aware Structure Encoder)
该模块基于不同的结构编码器来对细粒度的层次信息进行建模,本文中使用两个structure encoder:Bidirectional Tree-LSTM和Hierarchy-GCN。
Bidirectional Tree-LSTM
这里与语法树(syntax encoders)相似,对所有样本,预定义的层次结构都是相同的,这使得这个递归计算模块的小型批次训练方法成为可能。
在该结构编码器中,节点更新公式如下,其中和
分别表示节点k的隐藏状态和记忆元状态:
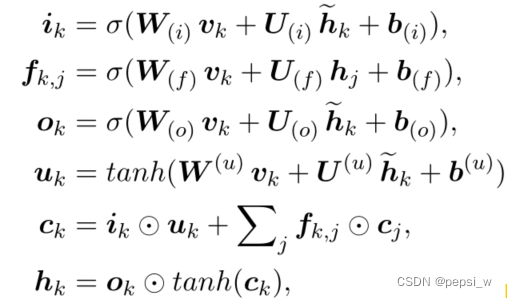
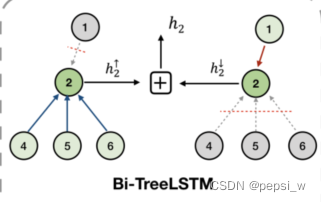
为了得到标签的相关性,HiAGM采用了一个双向的Tree-LSTM(感觉这里和LSTM网络差不多,只是会从两个方向来进行计算,表示潜在候选隐藏状态,
表示节点k的最终隐藏状态),由一个childsum和一个top-down模块融合而成,如下图所示:

Hierarchy-GCN
使用一个简单的层次GCN来获得细粒度层次结构信息,如图所示:
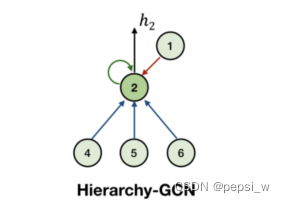
GCN汇集从上到下、从下到上和自循环这三个边数数据流。由于在层次图中,每条有向边表示一对标签的相关特征,因此这三个数据流应该用边的线性变换进行节点变换(这里不是很懂 什么是用边的线性变换进行节点变换?这里应该是在structure encoder中 对边进行更新的时候会用边的一个信息 就是图神经网络里面的东西 用边来对点的信息进行聚合)。但这种变换会导致过度参数化边权重矩阵,本文用一个加权的相邻矩阵(即其先验概率)对这种转换进行简化。
Hierarchy-GCN根据节点k的相邻节点(节点k,k的父节点以及k的子节点)对其隐藏状态进行编码,其中d(j,k)表示从节点j到节点k的层次方向(包括三个方向),表示节点k和节点j之间的层次概率(自环的边为1,子节点到父节点的边为1,父节点到子节点的边为Nk/Nj)。最后节点k的隐藏状态hk表示其对应于层次结构信息的标签表征。
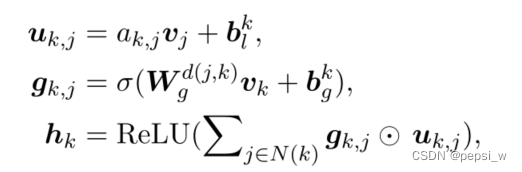
Hybrid Information Aggregation
给定一个文档序列x,使用一个双向GRU层对该序列的token embedding提取文本上下文特征,再经过多个CNN提取n元特征,经过最大池化层提取关键信息。最后通过reshape得到一个连续的文本表征S。
Hierarchy-Aware Multi-Label Attention
HiAGM-LA,是HiAGM基于多标签注意力的一个变种。标签表征通过双向层次信息得到增强,这种局部的结构信息使得能在一个模型中学习不同层次的标签特征。
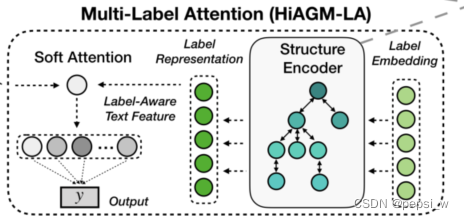
节点k的label embedding进行随机初始化为Lk,然后作为结构编码器的输入,输出的隐藏状态h代表层次敏感的标签特征。对于文本表征S,Hi-AGM使用以下公式计算其标签注意力值。
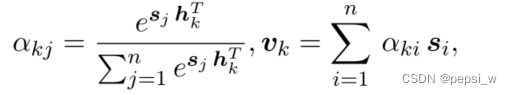
其中表示第i个文本特征向量对第k个标签的相关性,基于多标签注意力,就能得到与标签对齐的文本特征V,将该文本特征用于预测。另外可以直接使用结构编码器的隐藏状态作为预训练的标签表征,这样该模块在推理阶段能更轻量级。
Hierarchical text feature propagation
第二个变体(HiAGM-TP)基于演绎法获得获得label-wise的文本特征,主要进行文本特征的传播。直接将文本特征S作为节点输入并通过结构编码器对文本信息进行更新。
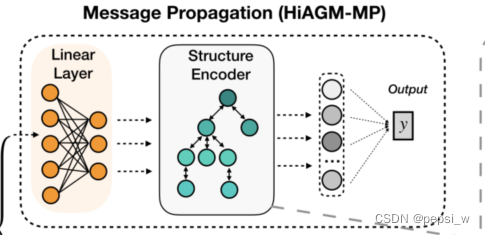
节点输入V由文本特征S通过一个线性变换得到,在给定的结构下,每个样本在同一个整体的分类层次中更新它的文本信息。一个小批量中,将初始节点表征V送到结构编码器中,输出的隐藏状态h表示层次敏感的文本特征,作为分类器的最终输入。
和HiAGM-LA相比,该变体的转换是在文本信息上进行的,没有进行标签embedding的融合。因此结构编码器在训练和推理阶段都会被激活,以便在层次结构中传递文本信息。该变体也比HiAGM-LA更容易收敛,但复杂度略高。
分类
作者将所有节点都作为多标签分类的叶子节点,使其结构扁平化。最终的层次敏感的特征输入到全连接层用于预测。损失函数由L2正则和多标签分类的交叉熵损失函数构成:Lm = Lc + λ · Lr
实验
将该模型与之前的模型进行比较,实验结果如下:
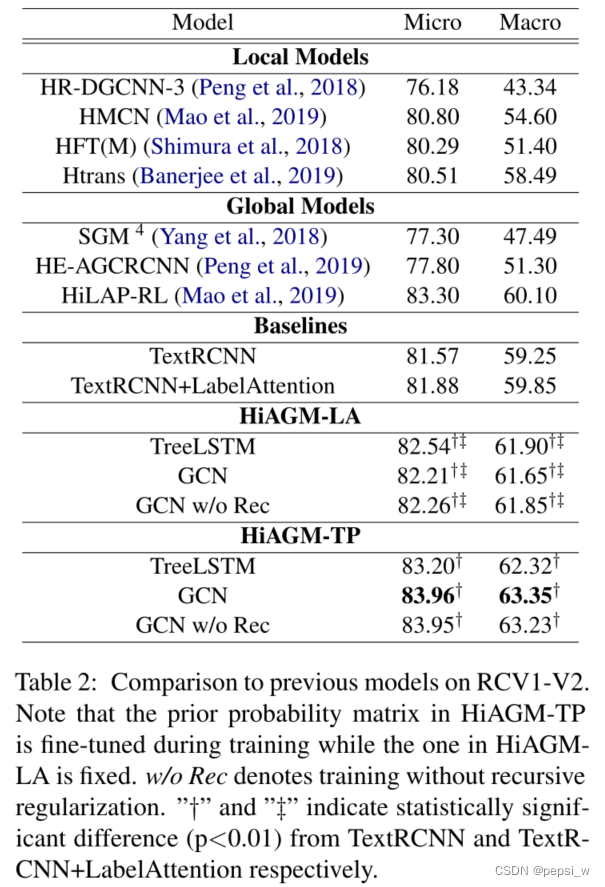
在Macro-F1上,我们提出的两个模型都比全局和局部的方法表现得更好,表明我们的结构编码器在HTC上的提升。
对两种变体和机构编码器进行消融实验,结果如下:
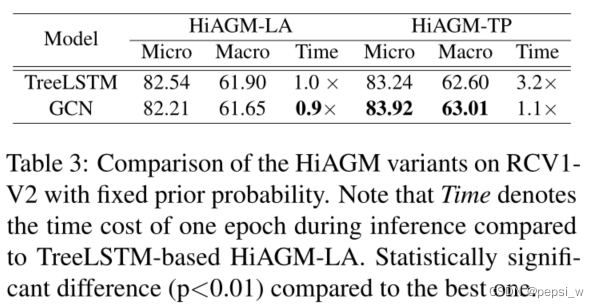
可以看出双向Tree-LSTM在学习层次敏感的label embedding上表现更好,但与GCN相比,其计算效率会低一点。在HiAGM-TP中,层次GCN比双向Tree-LSTM表现更好并且效率更高。即这两种变体有不同优势,HiAGM-TP都会比HiAGM-LA表现更好一点,但LA的计算速度更快一点。
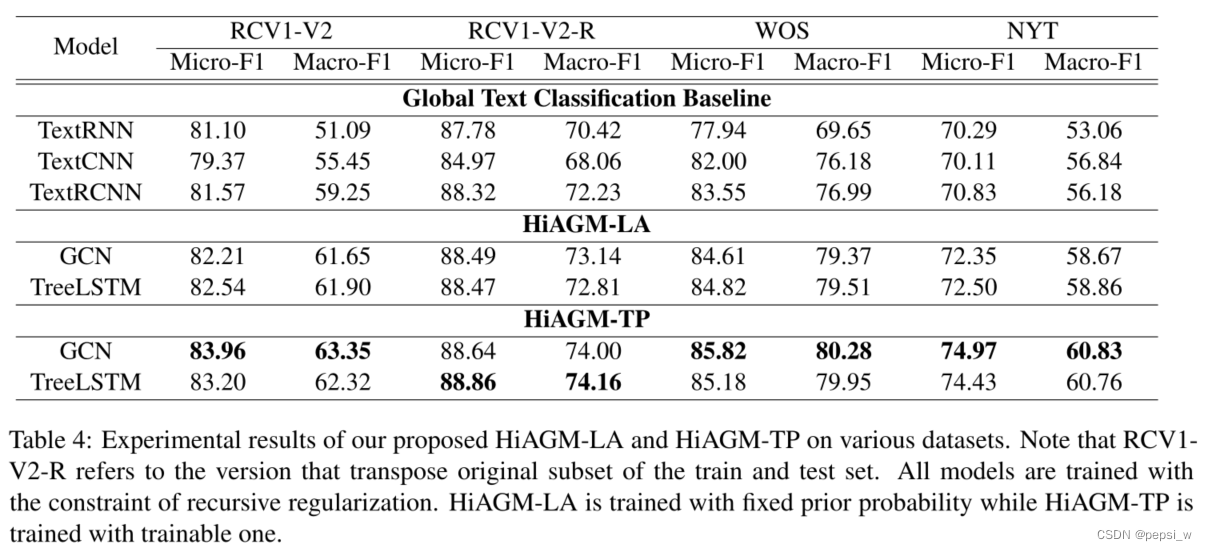
GCN深度的消融实验,可以看出在两个变体中,GCN为一层的时候效果最好,表示非相邻节点之间的相关性对于HTC任务来说不重要,但对分层信息聚合来说有一定的噪音。
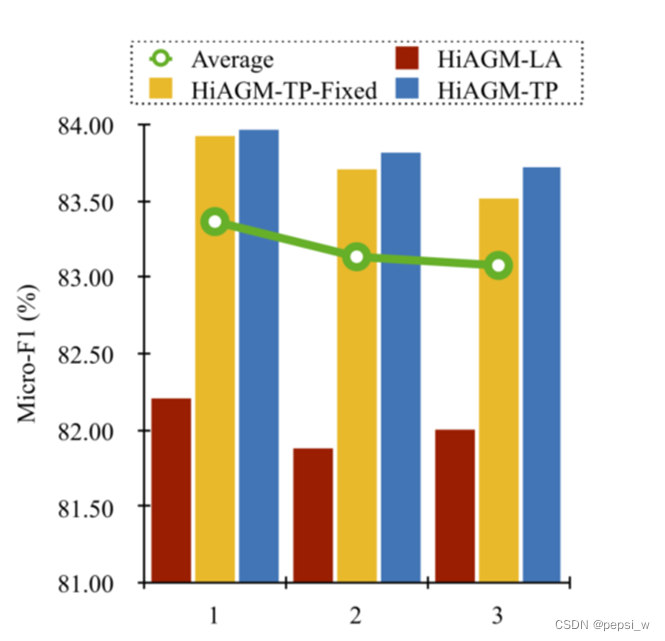
作者对GCN编码器中的先验概率选择进行了实验,
简单的加权相邻矩阵比复杂的边缘加权矩阵在节点转换中表现得更好。固定的加权矩阵比随机初始化可训练的矩阵表现更好,表明层次的先验概率能够代表层次标签的依赖关系。并且加权相邻矩阵进行微调可以获得更高的灵活性和更好的性能。
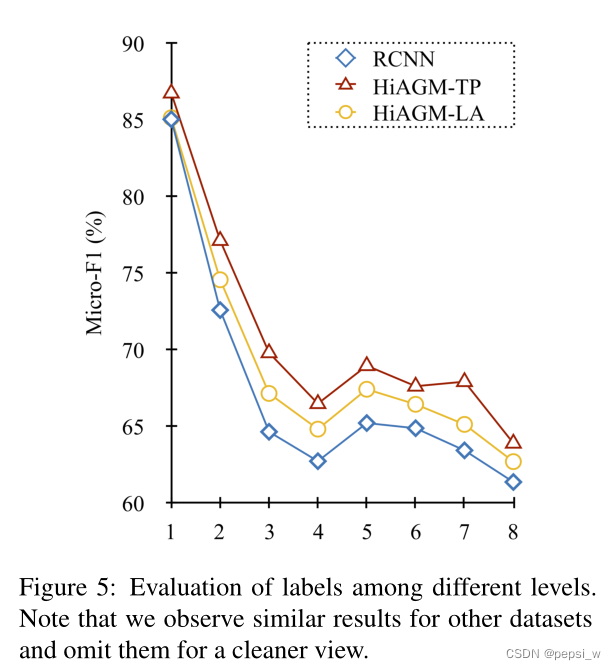
对不同层标签的划分结果进行实验,可以看出本文提出的模型在所有层中,特别是高层次中比baseline的表现更好。
总结
作者提出了一个新颖的端到端分层感知的全局模型,该模型提取标签的结构信息用于聚合标签方面的文本特征。并基于多标签注意和文本特征传播得到两个对于变体。
疑惑
先验层级信息
感觉这个点挺有意思的,结合之前有篇引入对抗学习的层次文本分类,提到文中使用的Graphormer没有使用edge encoding这个信息,因为层次结构中的边不携带任何信息,是不是就可以考虑将这种先验层级信息作为edge encoding去参与计算?(后面去看了这个论文,好像这个论文就是一种方法,实验中也使用HiAGM作为baseline进行了实验)
但是这种先验层级信息是根据训练数据得到的,是不是就代表这种信息其实对于其他的数据就没啥用,甚至会起到反作用?感觉这样会影响模型的泛化性?
预先定义的层次结构
文中提到structure encoder是预先定义好的结构,但是没有指出到底是怎么定义的,这一块看不懂。
HiAGM-TP中虽然文本表征最后通过top-k得到的都是同样长度的表征,可以在同一个结构种进行更新文本信息。但是这里把文本表征(通过一个线性层后)作为structure encoder的节点输入,那怎么得到标签的层次信息呢?难道得到的文本表征的层次信息吗?而且文本表征之间也没有那个先验概率啊,那怎么更新?(不知道是不是没认真看这个地方的公式表达)















 3144
3144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









