








简单有效的文本匹配,具有更丰富的对齐功能
github: https://github.com/daiyizheng/shortTextMatch/blob/master/src/DL_model/classic_models/models/RE2.py
本文作者提出了一种快速、强神经网络的通用文本匹配方法。保持序列间对齐可用的三个关键特征:原始点方向特征、先前对齐特征和上下文特征,同时简化所有其余组件。在自然语言推理、意译识别和答案选择任务上达到了很好的性能。
RE2架构如下图所示。embedding层首先映射离散token。然后由encoder层、alignment层和fusion层组成的多个相同结构的块对序列进行连续处理。这些块由增强的残差来连接。pooling层将顺序表示聚合成向量,最后由prediction层处理这些向量以给出最终的预测。

Augmented Residual Connections
为了提供更丰富的对齐功能,RE2采用了增强残差连接来连接连续的block。对于长度为
l
l
l的序列,我们将第n个bloc的输入和输出表示为
x
(
n
)
=
(
x
1
(
n
)
,
x
2
(
n
)
,
.
.
.
,
x
l
(
n
)
)
x^{(n)} = (x^{(n)}_1 , x^{(n)}_2 , ... , x^{(n)}_l)
x(n)=(x1(n),x2(n),...,xl(n))和
o
(
n
)
=
(
o
1
(
n
)
,
o
2
(
n
)
,
.
.
.
,
o
l
(
n
)
)
o^{(n)} = (o^{(n)}_1 , o^{(n)}_2 , ... , o^{(n)}_l)
o(n)=(o1(n),o2(n),...,ol(n)),其中,设
o
(
0
)
o^{(0)}
o(0)是零向量的序列。第
n
b
l
o
c
k
x
(
n
)
n block x^{(n)}
nblockx(n)(n≥2)的输入是第
1
b
l
o
c
k
x
(
1
)
1 block x^{(1)}
1blockx(1)的输入的串联,以及前两个block的输出的求和。
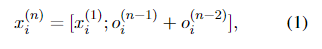
其中
;
;
;表示连接操作
Alignment Layer
对齐层将两个序列的特性作为输入,并计算对齐后的表示作为输出。长度为
l
a
l_a
la的第一个序列的输入表示为
a
=
(
a
1
,
a
2
,
…
,
a
l
a
)
a = (a_1, a_2,…, a_{l_a})
a=(a1,a2,…,ala),长度为lb的第二个序列的输入记为
b
=
(
b
1
,
b
2
,
…
(
b
l
b
)
b = (b_1, b_2,…(b_{l_b})
b=(b1,b2,…(blb)。
a
i
a_i
ai和
b
j
b_j
bj之间的相似度
e
i
j
e_{ij}
eij被计算为投影向量的点积:
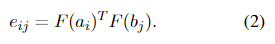
F
F
F是一个恒等函数或单层前馈网络。这个选择被视为一个超参数。
输出向量
a
′
a'
a′和
b
′
b'
b′是由其他序列表示的加权和计算出来的。该总和由当前位置与其他序列中相应位置之间的相似度评分进行加权。
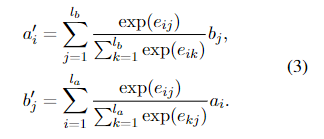
Fusion Layer
融合层从三个角度比较局部和对齐的表示,然后将它们融合在一起。第一个序列
a
‾
\overline{a}
a的融合层输出由
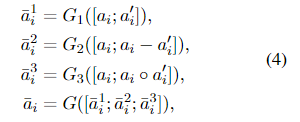
式中,G1、G2、G3、G为参数独立的单层前馈网络,
⋅
\cdot
⋅为逐元乘法。减法运算符强调两个向量之间的差异,而乘法则强调相似性。
b
‾
\overline{b}
b的公式类似,此处省略。
Prediction Layer
预测层将来自池化层的两个序列
v
1
v1
v1和
v
2
v2
v2的向量表示作为输入,并根据Mou et al.(2016)预测最终目标。
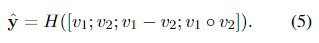
H
H
H是一种多层前馈神经网络。在一个分类任务中,
y
^
∈
R
C
\hat{y} \in R^C
y^∈RC表示所有类的非归一化预测得分,其中
C
C
C为类的数量。预测的类是
y
^
=
a
r
g
m
a
x
i
y
i
\hat{y} = argmax_i y_i
y^=argmaxiyi。在回归任务中,
y
^
\hat{y}
y^是预测的scala值。
在像意译识别这样的对称任务中,预测层的对称版本被用于更好的泛化
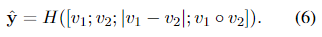
简化的预测层可以表示为

自然语言推理的结果

释义识别的结果

结论
提出了一种高效的通用文本匹配方法RE2。经过充分研究的数据集上实现了SOAT,三个不同的文本匹配任务,得到只有少量的参数和非常高的推理速度。突出了三个关键特征,即先前的对齐特征、原始的点方向特征和序列间对齐的上下文特征,并简化了大多数其他组件。该模型速度快,性能强,适用于广泛的相关应用。
















 3158
3158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











