







原文链接:
https://aclanthology.org/2022.coling-1.224.pdf
ACL 2022
介绍
问题:
目前few-shot NER方法侧重于使用目标领域的其他数据集进行充分训练后,迁移到同领域下目标数据集,但当目标领域中没有可用数据时,这种方法就会失效。
IDEA:
因此作者提出了一个新型的多任务学习框架SEE-Few(seed、expand、entail),用于解决源域没有数据的情况。其中seed和expand模块负责提供准确的spans给entail模块,entail模块将sapn分类任务视为文本蕴含任务对spans进行分类。
方法
模型的整体结构如下所示:

模型主要方法如下:
1)首先使用文本中质量较高的单字或双字词作为seed,然后对其进行expand作为候选span;
2)将span的分类问题视为文本蕴含任务,从而自然地纳入实体类型的信息。例如:“J. K. Rowling is a British author.”中的“J. K. Rowling”可能时一个person类的实体或者是一个非实体,将原句作为一个前提,“J. K. Rowling is a person” “J. K.Rowling is not an entity”作为假设,如此一来实体分类问题就转换为了哪个假设为真的问题,作者认为将分类任务转化为文本蕴含任务增加了训练数据,有利于低资源的ner;
Seeding
给定一个输入文本,单词和词组的集合表示为
。该模块主要是为了找到与实体重叠并可能扩展为命名实体的单词或双词,因此对于每个
都要计算seed score(其为种子的分数)
,将分数高于阈值
的
进行expand。
计算公式如下所示,其中表示第i个token经过bert得到的表征:

为了训练seeding model,作者构建了词组与其seed socre的数据集,seed socre的分数基于IoF来进行计算,A表示某个词组,B表示一个真实的实体span。
![]()
Expanding
expand是学习seed与其最近实体之间边界偏移的回归任务,seed的左右边界最多可偏移,即最大实体长度为2+2r,比如seed
最大可扩展为:
![]()
但如果直接使用作为
的窗口大小,就没办法获取到最长span的边界信息,即
的窗口大小
应该大于
:

通过窗口内的上下文信息和本身来得到偏移
,并基于该偏移得到新的span边界
:


最后生成用于分类的所有候选span。
Entailing
对于第i个候选sapn ,通过以下规则构建entailment pair
:
![]()
送入同一个encoder来获取[cls] token的表征,进行分类:
![]()
另外,在训练时,为了保证所有ground-truth实体都能被学习到,作者在span候选集C中都加入了ground-truth。
Training Objective
seed、expand模块的损失如下:

在entail 模块中,由于负样本的数量远多于正样本,作者使用了focal loss来解决样本不均衡问题(是focal loss 的focus参数):

最终的loss为:
![]()
实验
对比实验
在不同数量样本(K表示每一类别的样本个数)下进行实验(对比模型的结果是作者在同一设置下结果,即只在目标数据集上进行训练),结果如下所示:

消融实验
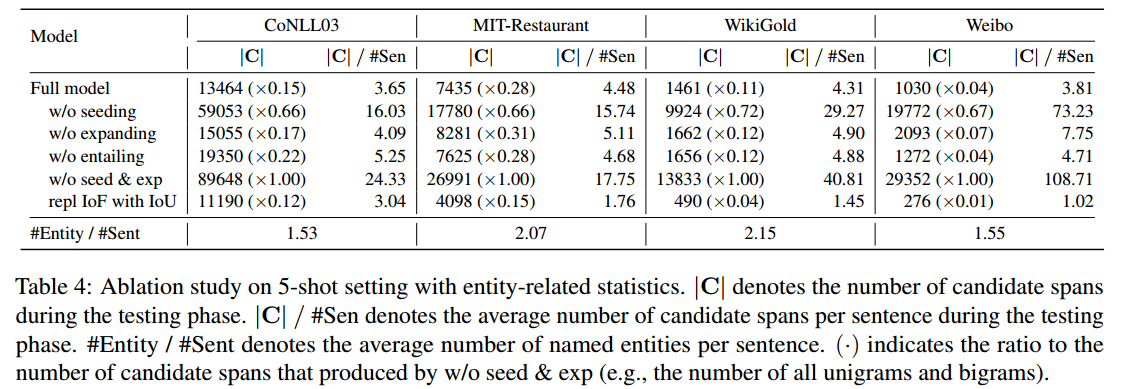
作者对模型的主要模块进行了实验,结果如下所示:

w/o seeding:表示移除了seeding模块,直接枚举所有的单字词和词组作为seed;
w/o expanding:直接将seed作为候选span,不再进行expand;
w/o entailing:将候选span使用一个多类别分类器进行分类;这个模块的消融实验时对模型效果影响最大的,因此可以看出在低资源ner上,使用entail任务来代替分类能够带来较好的效果。
作者对生成候选span的数量也进行了消融实验:
结论
第一次看论文看得胆战心惊的!这跟我之前的想法有点撞了,很悲伤!
整体框架还比较简单,作者通过一个在手动构建的数据集上训练好的MLP来生成span seed有点麻烦,不太优雅。不过从实验结果可以看出这种方式生成的seed效果也还不错;将span分类任务视为文本蕴含来做,也算是比较新的一个点,实验也可以看出这种方法比直接将span进行多类别分类要好很多,但是也不知道是不是few-shot的原因。














 6090
6090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









