






tushare ID:505144
按照【时间序列分析】ARMA预测GDP的python实现 - 知乎实现
基于ARMA模型对国内生产总值进行预测研究,首先对数据进行平稳化处理,然后识别与建立模型,根据模型预测未来年份的数据并与真实数据进行比对,证明模型能够准确地预测GDP数值,说明模型设计的合理性。本文以1952年—2021年的中国GDP为实验数据,利用python软件建立了ARMA算法的中国GDP预测模型,并验证了其有效性;成功地预测了2021年的GDP,并与实际值进行对比,验证了其准确性;说明本模型设计得比较合理。该模型可以预测未来年份的GDP数值,从而能够对中国外贸出口等经济策略进行调整并给予中国经济结构调整一定的启示。
1. 数据获取
由Tushare金融大数据社区得到数据,本文以1952-2021年中国GDP为样本数据,为研究模型实验研究对象。用本文提到的基于ARMA算法的预测模型,实现中国GDP的预测。
免费提供各类数据 , 助力行业和量化研究。拥有丰富的数据内容,如股票、基金、期货、数字货币等行情数据,公司财务、基金经理等基本面数据。SDK开发包支持语言,同时提供HTTP Restful接口,最大程度方便不同人群的使用。提供多种数据储存方式,如Oracle、MySQL、MongoDB、HDF5、CSV等,为数据获取提供了性能保证。
2.数据预处理
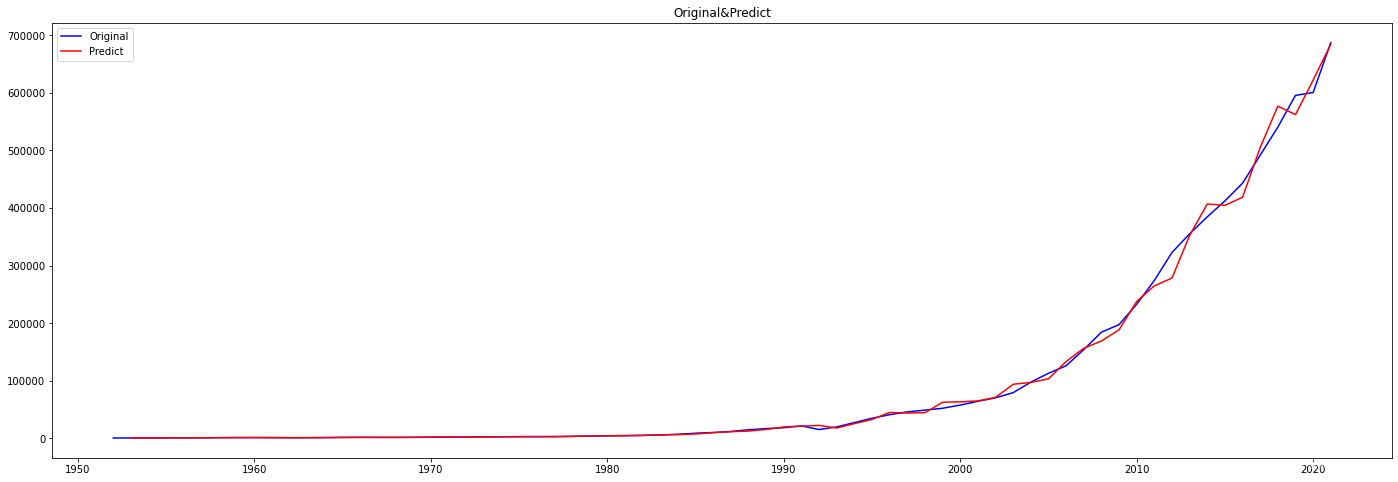
本文以1952-2021年为样本数据绘制成时序图如图1,X年份,Y为GDP,显示出历年GDP呈指数增长。应用ARMA算法对2021年的数据进行预测,并与真实值对比。
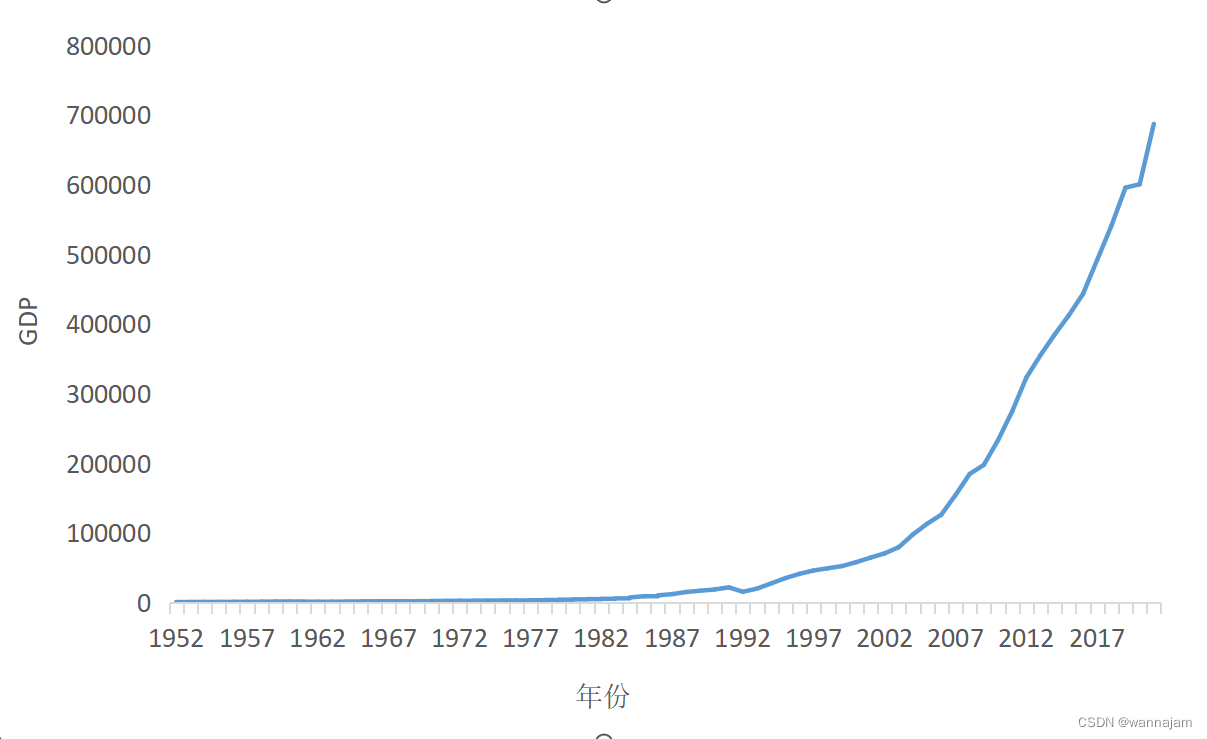
首先,对变量采取对数化处理,将时间序列的指数趋势变成线性趋势;后采用差分来消除线性趋势。将序列ln(y)进行二阶差分得到d2,发现观测值绕着均值上下波动,且该均值和时间无关,振幅变化不大,基本平稳,数据符合要求。
根据时间序列模型的特性可知,符合AR,MA,ARMA模型描述的对象应该是均值为零的平稳随机序列,然而实际中建模对象经常既包括平稳的随机部分,又含有确定的非随机分量。因此,在对时间序列进行建模时,应该首先对数据序列采取平稳化检验,并将非平稳的数据序列转成均值为零的平稳随机序列。而对处理过的序列检验其ADF,以进一步检测序列的平稳性,如表1。
表 1 单位根检验表
| 检验方法 | 水平 | t - Statistic | Prob.* |
| Augmented Dickey - Fuller test statistic | -6.710499 | 0.000000 | |
| Test critical values | 1% level | -3.530399 | |
| 5% level | -2.905087 | ||
| 10% level | -2.590001 |
3.ARMA模型建立与预测
由表1发现,ADF=-6.710499,比1%、5%、10%3个水平的临界值都小,拒绝非平稳的原假设,说明该序列不存在单位根,序列平稳。
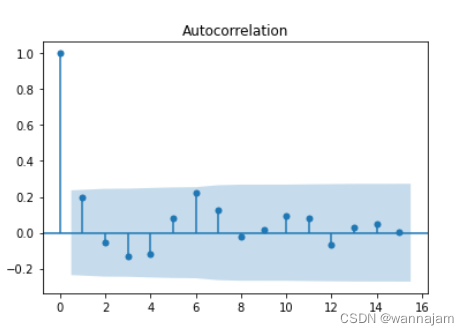
图 2 自相关图
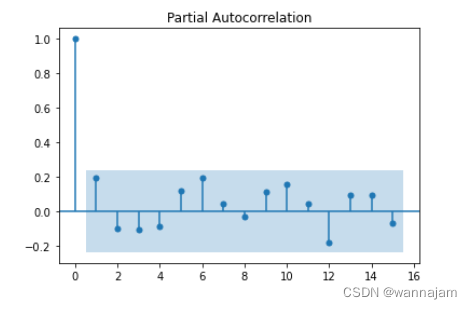
图 3 偏自相关图
通过Q-Q图可以看出,残差序列可以认为是正态分布。
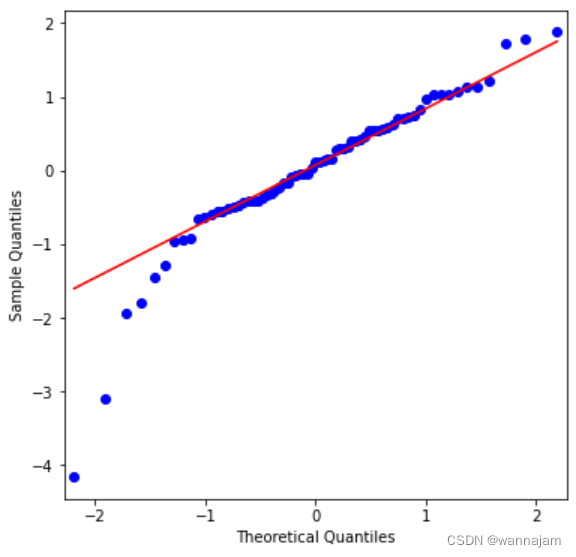
图 4 Q-Q图
本文用的是检验自相关常用的Durbin-Watson检验(D-W检验)。通过检验可知,DW=1.86,接近2,因此可以认为序列不存在一阶相关性。
从上边两步可以看出,残差序列是正态分布,且相互独立。因此可以认为是高斯白噪声,通过白噪声检验,建模可以终止。
本文提出的基于ARMA算法的GDP预测模型,预测GDP数值,事实上是通过研究分析社会经济的发展变化,找出其发展的量变规律,以预测经济现象的将来。在预测时,不需要考虑其他因素的影响,仅根据序列本身来建立相应的模型来进行预测,这就在根本上避免了寻找主要因素以及识别主次要因素的困难,在一定程度上确保了预测的准确性。
4.模型检验


















 6747
6747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









