







Paper Reading Note
URL:
TL;DR
17年初提出的针对于原始GAN问题本质上的改进,现在已经成为主流GAN的base-model。
作者花了两篇文章的篇幅,从证明到改进论述了原始GAN的两个重要问题:
- 【梯度消失】,即不需要再小心地平衡生成器和判别器之间的gap。
- 【模型崩塌】,原始模型优化KL散度导致的不对称会让生成器倾向于生成单一而安全的样本而放弃多样性。
Algorithm
作者在这里给出了详细的论述:
原始GAN的损失函数:
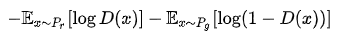
实际上这种损失函数经过变形等价为:
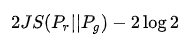
实际上就是原始数据的分布和生成数据的分布的js散度。而由于在大部分情况下二者在高维空间里几乎不可能有不可忽略的重叠,导致js散度的梯度几乎都等于常数。这也是原始的GAN在训练过程中常常会出现梯度消失最本质的问题。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4396
4396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









