










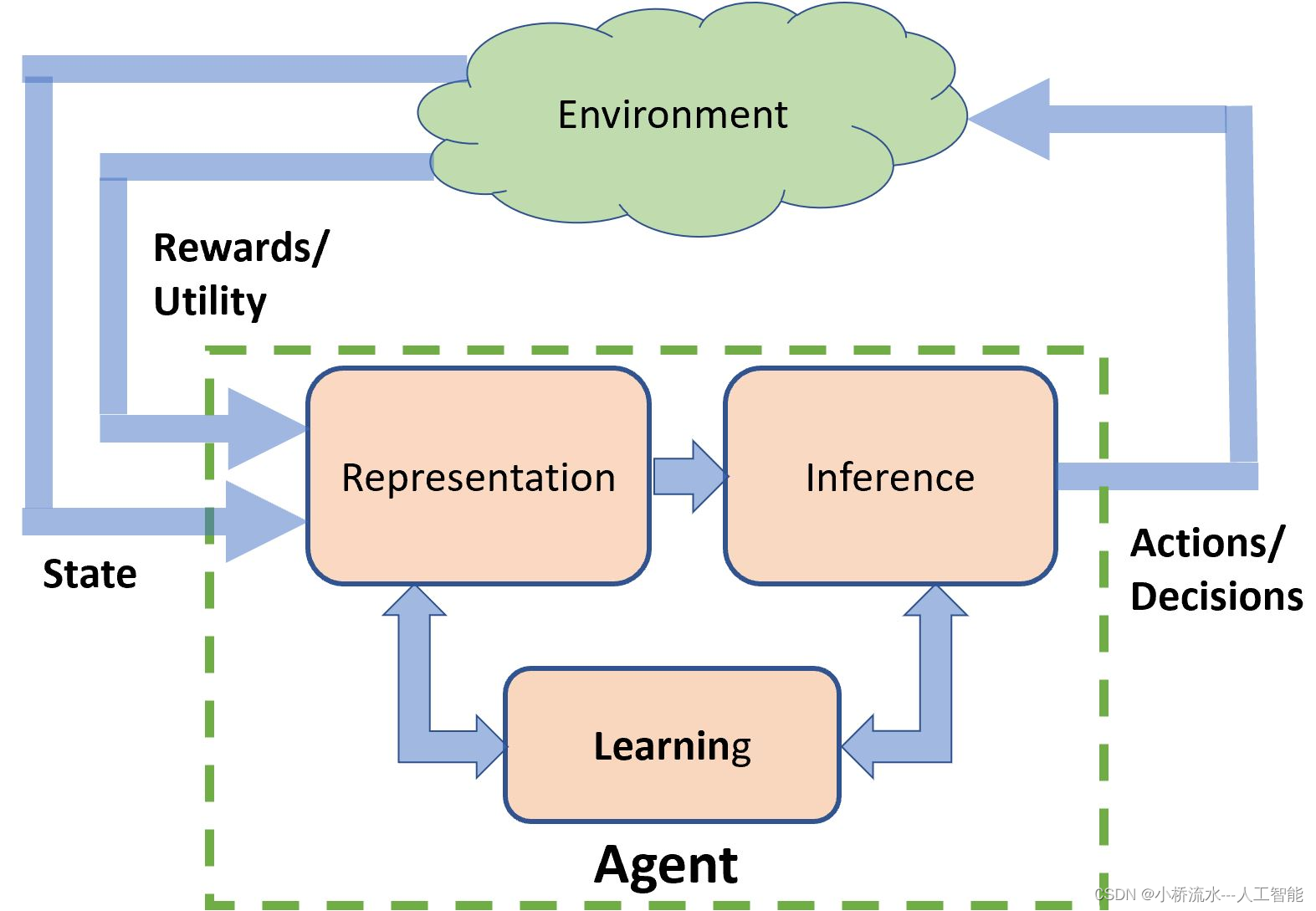
在强化学习中,Q值是一个非常核心的概念,用来表示在给定的状态下,采取某个特定动作所期望获得的总回报。Q值基本上是一种衡量“动作价值”的方式,即在当前状态采取一个动作能带来多大价值。
定义和计算
Q值通常表示为 (Q(s, a)),其中 (s) 表示环境的状态,(a) 表示在该状态下可能采取的动作。Q值的计算涉及到当前动作的即时奖励以及因该动作导致的状态转移而获得的未来奖励的预期值。
具体来说,Q值可以通过以下公式计算:
Q
(
s
,
a
)
=
r
+
γ
max
a
′
Q
(
s
′
,
a
′
)
Q(s, a) = r + \gamma \max_{a'} Q(s', a')
Q(s,a)=r+γa′maxQ(s′,a′)
其中:
- ( r ) 是采取动作 ( a ) 时获得的即时奖励。
- γ \gamma γ 是折扣因子,用于调节未来奖励的当前价值,通常取值在 0 到 1 之间。
- max a ′ Q ( s ′ , a ′ ) \max_{a'} Q(s', a') maxa′Q(s′,a′) 表示在下一个状态 ( s’ ) 可能采取的所有动作中,选择使得Q值最大化的动作的Q值。这部分代表了未来奖励的预期值。
Q值的作用
Q值的主要作用是帮助智能体(比如一个机器学习模型)在给定状态下做出最优决策。通过比较在某状态下所有可能动作的Q值,智能体可以选择Q值最高的动作,因为这个动作预期能带来最大的总回报。
Q学习算法
Q值的更新通常通过一种叫做Q学习的算法实现,该算法是一种无模型的强化学习算法,可以估计策略的好坏。Q学习的目标是找到使Q值最大化的策略,这样的策略可以指导智能体在任何状态下都能做出最佳决策。
通过不断地与环境交互,收集奖励信息,智能体可以不断更新其Q值表或Q值函数(在深度强化学习中使用神经网络来近似Q值函数),以此逐步优化其决策过程,最终学习到一个能在给定任务中表现最佳的策略。















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









