







《Focal Loss for Dense Object Detection》是Facebook AI 2017年提出的论文,这篇文章的贡献我觉得主要有两点:
- 提出了one-stage 目标检测模型RetinaNet
- 探究了one-state目标检测的类别失衡问题,并针对该问题提出了Focal Loss
类别失衡
为什么two-stage目标检测强于one-stage
In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause.
文章认为,在one-stage网络中,前景和背景的比例失衡问题,是造成one-stage精确度瓶颈的主要原因。而two-stage目标检测方法能很好的规避这个问题,主要原因有两点:
- two-stage cascade
- biased minibatch sampling
two-stage cascade
在目标检测中,前景目标是我们关心的主要区域,其中包含了用于物体检测的有用信息。而背景区域相比于前景而言:
1.无法提供用于提取目标特征的有用信息
2.背景区域过多,比例远远高于前景,从而使得最终的loss被背景区域所支配,loss无法达到预期的知道作用。
在stage one候选区域提取网络(rpn)中,能够抛弃大部分背景框而提取出候选前景框,达到了滤除绝大多数背景信息,rpn之后的区域多数都是我们关心的目标区域以及hard example,为模型训练提供更多有用的信息。
biased minibatch sampling
在stage two中,对正负样本进行抽样来控制比例,比如采用1:3的正负样本比例,正负样本的比例不至于失衡。
通过loss解决类别失衡问题
Cross Entropy Loss存在的问题
Binary Cross Entropy Losss的形式如下:
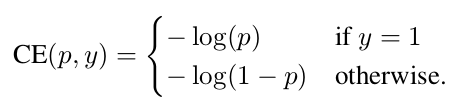
其中y是真实标签值,p为网络输出的类别概率。假设当前目标的类别标签为1,在输出概率p为横坐标,loss为纵坐标的图像如下面的这条蓝色曲线:

可以看到,当类别标签为1,即使检测输出概率为0.6~1的范围内,对应的纵坐标值也依旧有着不小的loss,而通常输出概率大于0.6这部分预测结果,我们通常认为是得到了正确分类的well-classified examples。这部分example已经得到了很好的分类,理论上我们应该更加关注那些输出概率和标签值相差非常大的样本,而对于well-classified的部分减小对其的关注度。
另一方面考虑,由于图像中存在着大量的背景区域,远远超过了前景区域的面积,而背景区域由于和前景区域有较大的区分度,通常为well-classified examples,而又因为背景区域的数量众多,在这样的情况下,如果背景的example经过分类计算后还有着一定的loss,乘上数量这将是一个很可怕的数字。所以目标是很明确的:更加关注于那些不好分类的hard example,惩罚well-classified examples的loss值。
Focal Loss
为了解决类别失衡问题,文章中提出了Focal Loss,其形式为:
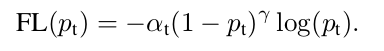
其中:
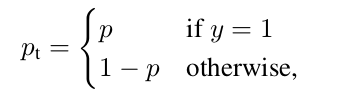
p 是分类输出的概率。
不考虑系数,当目标类别标签y=1的情况下,对于well-classified examples,
,值会非常接近于1,而
的值则更加接近于0,如果
的取值范围大于1,可以想象
的值将会更加的接近于0,从而达到了惩罚目的;而如果这个样本没有被很好的分类,输出概率值p远小于1,
的值则更加接近于1,不受到影响。说白了也就是通过指数来增加对well-classified examples计算的loss增加惩罚,使其loss变得更小。对应上面的图中红色到绿色曲线为
取值0.5~5的对应曲线,可以看到在
接近于1的情况下,将会比cross entropy得到更低的loss。
而系数则是起到了类似于minibatch sampling的一样的,平衡正负样本的作用。

当的时候,为传统的的binary cross entropy,可以观察到当
的时候,AP得到了明显提升。

在的基础上引入参数
,可以看到在
,
的情况下AP最高。
RetinaNet
网络结构
网络结构上RetinaNet没有提出新的东西,就是FPN和PCN的结合,骨干网络选择ResNet,是一个较为典型的one-stage目标检测方法。值得一提的是,backbone后,RetinaNet将目标分类和目标框回归分解成了两个子网络,如下图:

这里要说明一下,RetinaNet中作者提取了FPN中的P3~P7层(
代表相较于input大小除以
)作为feature map,而没有采用具有更高分辨率的P2往上层,这样 是出于计算量考量,毕竟更高层虽然有更加丰富的特征但是也有更大分分辨率,会增加计算量。
且P3~P5和传统FPN相同,通过top-down和相加得到对应的层;而P6层是通过C5直接通过3*3的步长为2的卷积计算而来,P7则是通过P63*3的步长为2的卷积计算而来,作者说这样是兼顾计算量和准确性考虑。
参数初始化
对于分类网络classification subnet,对于最终的卷积层的bias参数,作者初始化成了,π经过实验测试当π取值为0.01的时候效果最好(我本人认为这就很玄学了)。
效果
















 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









