









内容来自小象学院皱博老师。
一、前向分步算法
最终模型可以分为若干个基函数及其系数的加和。

只要通过最小化损失函数来确定基函数的系数βm和基函数的参数γm就可以确定最终模型f(x)。

但是想要一次性确定所有的系数和参数显然很困难,前向分步算法对求解系数和参数进行了化简:给当前模型fm-1(x)加上βmb(x;γm)然后求使得损失函数最小化的βm和γm,得到新的模型fm(x)=fm-1(x)+βmb(x;γm)。也就是不用求最终模型的损失函数极小化问题,每次只对当前模型加上一个基函数来求损失函数极小化问题,重复M次就会得到最终的模型。
前向分步算法步骤:

二、AdaBoost
1、前向分步算法和AdaBoost的关系

2、AdaBoost算法如何更新参数和系数
(1)初始化数据集和初始化权值分布

(2)给当前模型加上新的基函数Gm(x),求其损失函数极小化问题,得到新的系数αm。


新的基函数Gm(x)如何来求:

系数αm如何来求:
注:将上面求得的Gm(x)带入进来
令
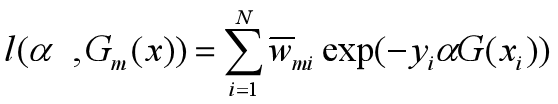
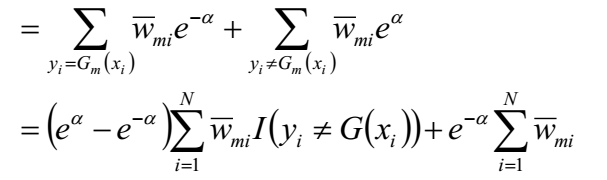
约定所有样本的权值之和为1,即:
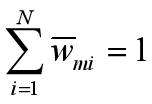
新的基函数(本质是一个弱分类器)分类错误的样本的权值之和就是错误率,这也就是为啥规定wmi的期望为1的原因。

所以l(α, Gm(x))化简为:
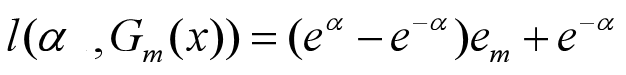
上式对α求导并令导数等于0得到使得上式取最小值的αm:
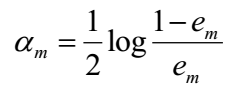
4、总结一下Adaboost的算法流程
(1)初始化数据集权值分布

(2)训练多个弱分类器,选择误差率最小的那个弱分类器作为Gm(x),然后用它的错误率em来计算αm。

(3)更新训练数据集的权值分布

(4)整合Gm(x)得到 fm(x) = fm-1(x) + αmGm(x)
(5)重复步骤(2)(3)(4)直到m等于M结束,得到最终的模型fm(x)。















 2257
2257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









