






NLP是人工智能(AI)的一个方向,大白话来说就是让机器理解人类的语言,并且能够与人进行自然地交流。当然,这个语言包括口头语言,也包括书面语言(文字)。就像人一样,一天学没上过,他也可以日常交流,但是读不懂书,认不了字。我们称之为文盲。那么机器呢,是由电子元器件组成的一个物品,它最容易识别的是0和1信号。当然,让机器达到理解和说出人类语言的目标,难度还是很高的。就算智力最高的动物,学说几个字都很困难,不管是大猩猩还是鹦鹉,也都做不到与人语言交流。目前的技术水准,机器距离理解语言和自然的使用语言这个目标还差得很远。
但,我们研究AI技术也好,研究NLP技术也好,主要还是为了应用,落地到现实场景中,解决现实中的一些问题,改善人类的生活。NLP落地场景也有很多,传统的如搜索、推荐、翻译等相对成熟的应用领域,也有最近比较热的应用领域,比如对话机器人、智能客服、虚拟数字人等。
NLP落地难,是目前的现状,当然也有一些简单的任务,比如文本分类聚类、命名实体识别等,已经落地并普遍应用。但随着Transformer 和 BERT 等这些新的模型出来,目前看来已经看到了NLP普遍落地的一些曙光。当然,这些模型参数量巨大,需要高效的分布式大规模训练以及快速的在线推理服务,可能是目前影响大规模应用落地的短期障碍,但相信只要它的效果是足够好的,这些短期的障碍很快就会被行业所攻克,就像视频领域的深度学习模型一样,所以这只是短期障碍,并不是长期问题。
在仔细说Transformer之前,我们先说说语言模型。语言模型可以说是一个无条件的文本生成模型,一般是指单向的(更狭义的只是指正向的)语言模型。已经知道了X1,预测X2,已经知道了X2预测X3,比如:X1=清华,那么预测X2最可能是"大学",X1X2="清华大学",来预测X3,比如X3最可能是“计算机”,依次类推,已经知道了“清华大学计算机”继续预测X4。单向语言模型预测一个词,只依赖于前面的词。RNN 模型是天然适合来做语言模型的,因为它本身就是递归的运算。如果需要记住更多的前期信息,那么RNN模型就要有更多的层,但是随着RNN层数的增加,就会出现梯度消失(vanishing gradients) 的问题。
直到2017年6月一篇论文《Attention is all you need》,它提出了解决序列到序列(sequence to sequence)问题的transformer模型,该文章使用全Attention的结构代替了LSTM,抛弃了之前传统的编解码(encoder-decoder)模型必须结合CNN或者RNN的固有模式。在减少计算量和提高并行效率的同时还取得了更好的结果,也被评为2017年 NLP 领域的年度最佳论文。
Self-Attention是Transformer中很关键的一个概念。像上面说到的单向语言模型,对于远距离的相互依赖的特征,要经过若干时间步的信息累积才能将两者联系起来,而距离越远,有效信息也就越难提取,比如X12的预测,可能X1、X2、X3等这些信息已经被遗忘了,对于预测X12不再发挥作用。而Self-Attention更容易捕获句子中长距离的相互依赖的特征,在计算过程中直接将句子中任意两个单词之间的联系通过一个计算结果直接表示,远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
Transformer思想
- 原来的模型只学习输入——输出之间的关系;而Transformer提出了Self-Attention的概念,学习输入——输入之间,输出——输出之间,输入——输出之间这三种关系。
- Transformer提出了multi-head attention的机制,分别学习对应的三种关系,使用了全Attention的结构。
- 对于词语的位置,Transformer使用positional encoding机制进行数据预处理,增大了模型的并行性。
Transformer结构
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
第一步:获取输入句子的每一个单词(token)的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 两部分相加得到。
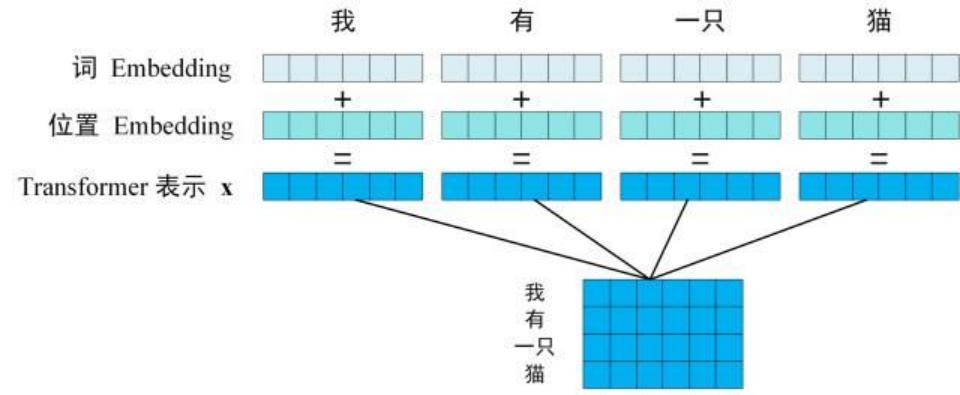
Transformer 的输入表示
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C。单词向量矩阵用 Xn*d表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
Transformer总结
- Transformer 与 RNN 不同,可以比较好地并行训练,并且一定程度解决了梯度消失(vanishing gradients) 的问题。
- Transformer 在输入中添加位置 Embedding,可以同时利用单词的内容特征和位置特征。
- Transformer 的重点是 自注意力(Self-Attention )结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
全球最大规模的中文Transformer单体模型
自谷歌提出Transformer结构后,预训练的超大规模参数的模型蓬勃发展,国内外形成了“大炼大模型”的热潮。更大的参数规模为模型性能带来质的飞跃。对十亿、百亿乃至千亿级超大模型的探索成为产学研界的热门话题,引发国内外著名互联网企业和研究机构的竞相跟进,将模型规模和性能不断推向新的高度。
在“大模型时代”,因为大模型巨大的参数量和算力需求,在大范围内应用大模型仍然存在着较大的挑战。如何让更多开发者方便享用大模型,如何让更多企业广泛应用大模型,让大模型不再“大”不可及,是实现大模型可持续发展的关键。
基于此,浪潮源1.0大模型开源了向人工智能应用开发者群体进行开放,开放内容包含开放模型API,开放高质量中文数据集,开源模型训练代码、推理代码和应用代码等。
开放平台:https://air.inspur.com/,可进行模型API、中文数据集的申请使用。
开发者社区:https://github.com/Shawn-Inspur/Yuan-1.0,可浏览训练代码、推理代码和应用示例代码。
作为人工智能应用开发者,你可以去申请试用一下全球最大规模的单体transformer模型,开发有趣的应用或者改进目前的产品性能。














 880
880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









