









我是分2类 我的训练和测试集在http://blog.csdn.net/wd1603926823/article/details/51732849已经转化为leveldb格式
首先,我的Imagenet_solver.prototxt文件:
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "E:/Keras_Code/examples/imagenet/meanforme.binaryproto"
}
data_param {
source: "E:/Keras_Code/examples/imagenet/train_leveldb"
batch_size: 8
backend: LEVELDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "E:/Keras_Code/examples/imagenet/meanforme_test.binaryproto"
}
data_param {
source: "E:/Keras_Code/examples/imagenet/test_leveldb"
batch_size: 1
backend: LEVELDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}
net: "E:/Keras_Code/examples/imagenet/Imagenet_train_test.prototxt"
test_iter: 24
test_interval: 200
base_lr: 0.001
momentum: 0.9
weight_decay: 0.0005
lr_policy: "inv"
gamma: 0.001
power: 0.75
display:20
max_iter: 2000
snapshot: 400
snapshot_prefix: "E:/Keras_Code/examples/imagenet/mine"
solver_mode: GPU
然后在python接口下:accuracy_loss_img.py 训练并画出accuracy
from pylab import *
import matplotlib.pyplot as plt
import caffe
caffe.set_device(0)
caffe.set_mode_gpu()
solver = caffe.SGDSolver('E:\Keras_Code\examples\imagenet\Imagenet_solver.prototxt')
niter = 2000
display_iter = 400
test_iter = 24
test_interval = 200
# train loss
train_loss = zeros(ceil(niter * 1.0 / display_iter))
# test loss
test_loss = zeros(ceil(niter * 1.0 / test_interval))
# test accuracy
test_acc = zeros(ceil(niter * 1.0 / test_interval))
# iteration 0
solver.step(1)
_train_loss = 0; _test_loss = 0; _accuracy = 0
for it in range(niter):
solver.step(1)
_train_loss += solver.net.blobs['loss'].data
if it % display_iter == 0:
train_loss[it // display_iter] = _train_loss / display_iter
_train_loss = 0
if it % test_interval == 0:
for test_it in range(test_iter):
solver.test_nets[0].forward()
_test_loss += solver.test_nets[0].blobs['loss'].data
#_accuracy += solver.test_nets[0].blobs['accuracy'].data
test_loss[it / test_interval] = _test_loss / test_iter
test_acc[it / test_interval] = _accuracy / test_iter
_test_loss = 0
_accuracy = 0
print '\nplot the train loss and test accuracy\n'
_, ax1 = plt.subplots()
ax2 = ax1.twinx()
ax1.plot(display_iter * arange(len(train_loss)), train_loss, 'g')
ax1.plot(test_interval * arange(len(test_loss)), test_loss, 'y')
ax2.plot(test_interval * arange(len(test_acc)), test_acc, 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('loss')
ax2.set_ylabel('accuracy')
plt.show()

可是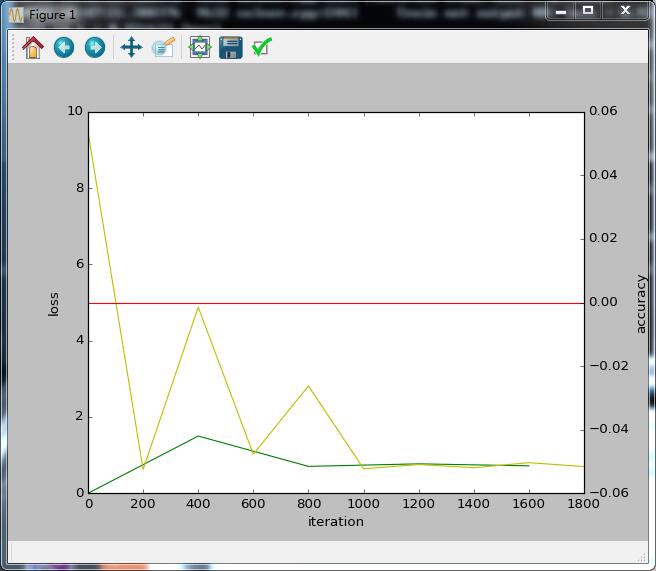
_accuracy += solver.test_nets[0].blobs['accuracy'].data
即使把这句不注释掉 运行出来也是一直为0的红线 好奇怪的。。。???为什么 这是第一个问题?!
然后就是对新图片进行预测分类:
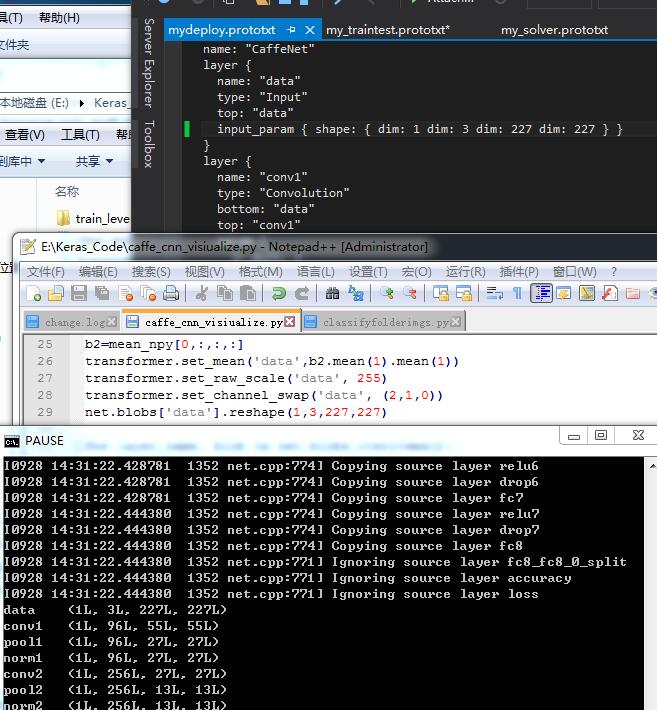
那么首先要有自己的deploy.prototxt文件:我的是mydeploy.prototxt:我不知道我这个deploy根据我的Imagenet_train_test.prototxt改写的对不对在dim:10这里:
name: "CaffeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } } #话说这第一个dim为什么是10啊 10代表的是什么??第二个问题
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}

然后就是预测分类的脚本:
#coding=utf-8
#http://www.cnblogs.com/denny402/p/5685909.html
#http://www.cnblogs.com/NanShan2016/p/5532589.html
import caffe
import numpy as np
deploy='E:/Keras_Code/examples/imagenet/mydeploy.prototxt'
caffe_model='E:/Keras_Code/examples/imagenet/mine_iter_800.caffemodel'
img='E:/Keras_Code/examples/imagenet/test13.bmp'
labels_filename = 'E:/Keras_Code/examples/imagenet/mylabel.txt'
mean_file='E:/pyCaffe_GPU/python/caffe/imagenet/ilsvrc_2012_mean.npy'
net = caffe.Net(deploy,caffe_model,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
im=caffe.io.load_image(img)
net.blobs['data'].data[...] = transformer.preprocess('data',im)
out = net.forward()
labels = np.loadtxt(labels_filename, str, delimiter='\t')
#print net.blobs
prob= net.blobs['prob'].data[0].flatten()
print 'frequency belong to 2 classes:', prob
order=prob.argsort()[0]
print order
#print labels
#print 'the class is:',labels[order]
###########################################################
#http://www.cnblogs.com/denny402/category/759199.html
#http://www.bubuko.com/infodetail-1019584.html
#http://www.docin.com/p-871820922.html
#http://blog.csdn.net/hjimce/article/details/48972877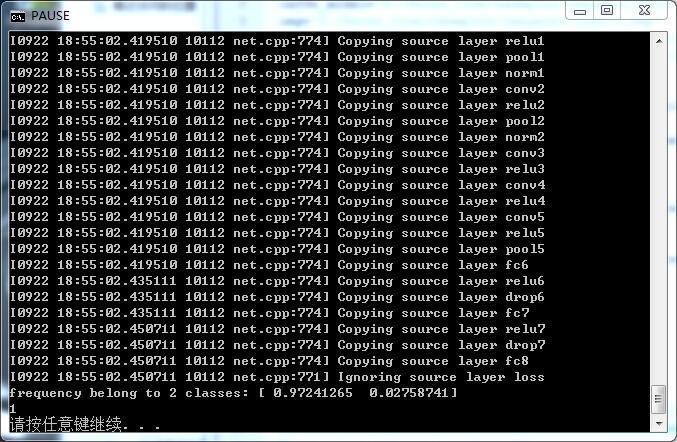
的确 如@风翼冰舟 所说 标号对应的是【1 0】:
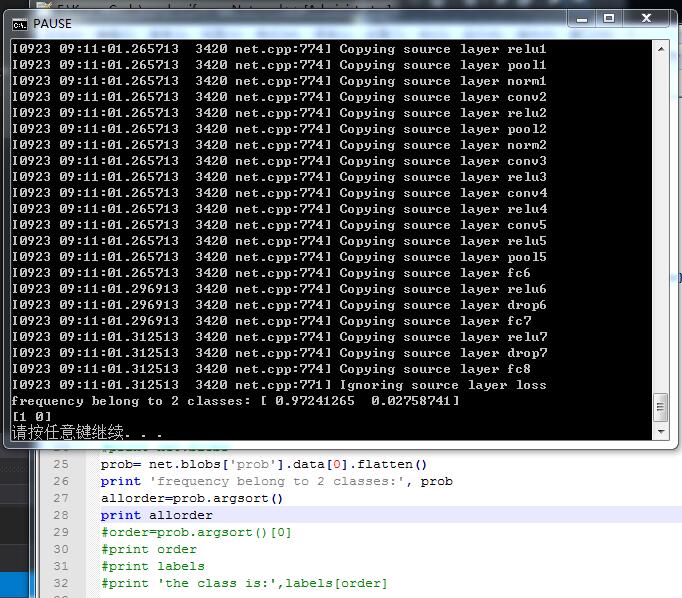
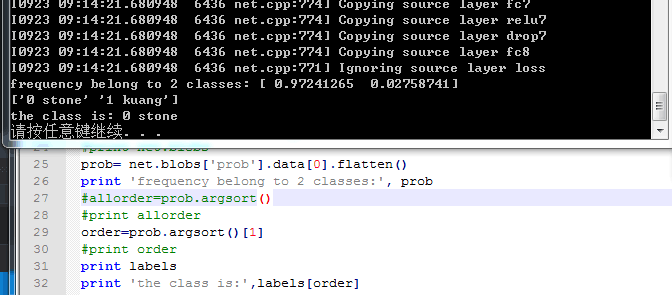
但我还是疑惑 allorder中为什么存储的是[1 0]而不是[0 1]呢????
哦 我懂了 刚刚我也去查了argsort这个函数:如果x表示属于每个类别的概率 labelss表示我的标签 如果三类 那么labelss=[0 1 2] 然后:
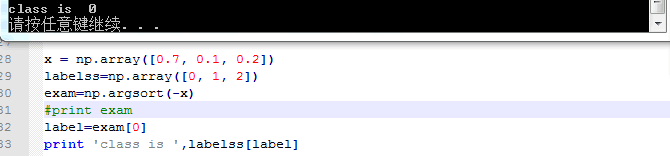
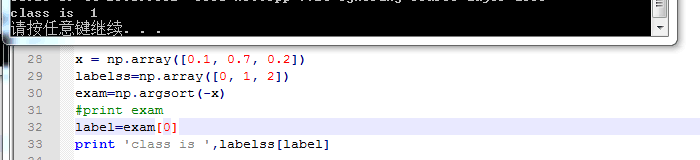
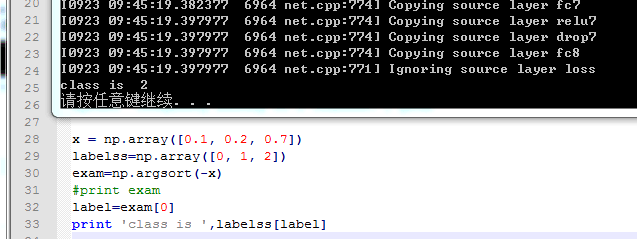
再比如:
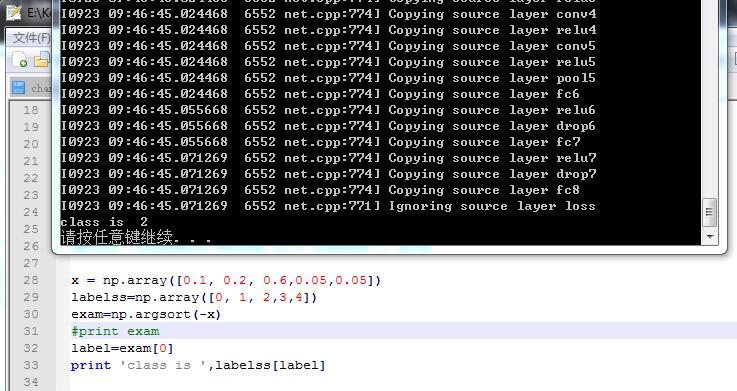
不管几类都是正确的 根据概率来的:

读取一个文件夹下的一些图片:

预测这个文件夹下所有图片的分类结果:并写进一个class_result.txt的文件中:

其中这有2个脚本文件:
第一个是myclassify1img.py:
import caffe
import numpy as np
def classify1img(caffe_model,deploy,mean_file,labels_filename,img):
net = caffe.Net(deploy,caffe_model,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
im=caffe.io.load_image(img)
net.blobs['data'].data[...] = transformer.preprocess('data',im)
out = net.forward()
labels = np.loadtxt(labels_filename, str, delimiter='\t')
prob= net.blobs['prob'].data[0].flatten()
order=np.argsort(-prob)[0]
#print 'class is:',labels[order]
myclass=labels[order]
return myclass#http://www.111cn.net/phper/python/47504.htm
import os,glob
from myclassify1img import classify1img
import caffe
dir_path='E:/Keras_Code/examples/imagenet/forclassify/'
imgsextension=['bmp']
os.chdir(dir_path)
imglist=[]
for extension in imgsextension:
extension='*.'+extension
imglist+=[os.path.realpath(e) for e in glob.glob(extension)]
caffe_model='E:/Keras_Code/examples/imagenet/mine_iter_800.caffemodel'
deploy='E:/Keras_Code/examples/imagenet/mydeploy.prototxt'
mean_file='E:/pyCaffe_GPU/python/caffe/imagenet/ilsvrc_2012_mean.npy'
labels_filename = 'E:/Keras_Code/examples/imagenet/mylabel.txt'
class_file='E:/Keras_Code/examples/imagenet/class_result.txt'
f=open(class_file,'w')
for file in imglist:
img=file
myclass=classify1img(caffe_model,deploy,mean_file,labels_filename,img)
#print myclass
f.write(myclass+'\n')
f.close()///
遇到一个问题 我想把图片显示出来:
import numpy as np
import matplotlib.pyplot as plt
image='E:/Keras_Code/examples/imagenet/test00.bmp'
plt.imshow(image)
plt.axis('off')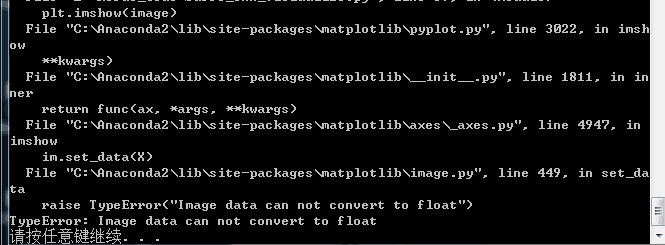
就剩下第一个和这个问题待解决了。。。
///
/
刚刚看到对新图片预测分类时 要用自己的mean文件 据说是要用新图片减去训练集的mean.binaryproto :之前我是用的pycaffe自带的ilsvrc_2012_mean.npy 而做自己的图片还是不能用它的 因为我看到它是[3,256,256]而我自己的图片不是这样 所以用它的均值不对的:
比如上面我的待预测的新图片都放在forclassify文件夹下面 比如有10张 只是我不知道这上面预测时到底是用训练集计算得到的那个meanforme.binaryproto还是应该首先对这些新图片也就是forclassify文件夹下的图片计算出一个新mean_new.binaryproto 然后用这个mean_new.binaryproto??这两个mean到底应该用哪个 有人说用第一个也就是训练集的mean文件 对吗???这是第三个问题。
///马上要十一了 七天假 哈哈///
按照http://www.07net01.com/2016/05/1502443.html 用自己训练好的模型提取全连接层的特征并保存:
#http://www.cnblogs.com/louyihang-loves-baiyan/p/5078746.html
#http://www.cnblogs.com/louyihang-loves-baiyan/p/5134671.html
import numpy as np
import matplotlib.pyplot as plt
import caffe
from useless_test import vis_square
from PIL import Image
import scipy.io as sio
caffe.set_mode_gpu()
caffe.set_device(0)
deployPrototxt ='E:/Keras_Code/examples/imagenet/mydeploy.prototxt'
modelFile ='E:/Keras_Code/examples/imagenet/mine_iter_800.caffemodel'
mean_file='E:/Keras_Code/examples/imagenet/meanforme.binaryproto'
net = caffe.Net(deployPrototxt, modelFile,caffe.TEST)
dir_path='E:/Keras_Code/examples/imagenet/forclassify/'
#myimglist=readImageList(dir_path)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
mean_blob = caffe.proto.caffe_pb2.BlobProto()
mean_blob.ParseFromString(open(mean_file, 'rb').read())
mean_npy = caffe.io.blobproto_to_array(mean_blob)
b2=mean_npy[0,:,:,:]
transformer.set_mean('data',b2.mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
net.blobs['data'].reshape(1,3,227,227)
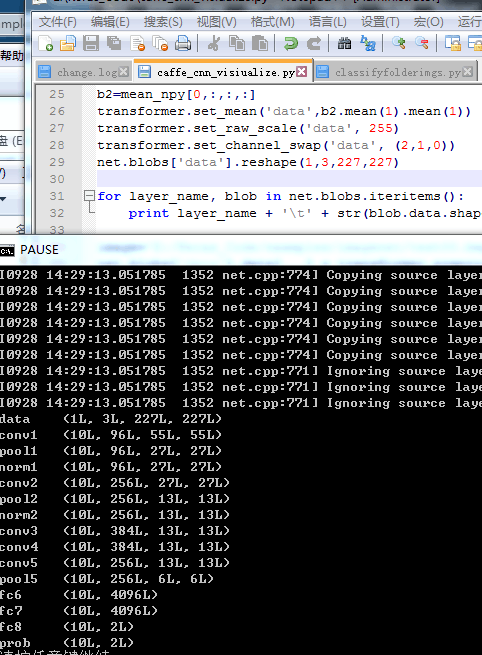
for layer_name, blob in net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
image='E:/Keras_Code/examples/imagenet/test00.bmp'
net.blobs['data'].data[...] = transformer.preprocess('data',caffe.io.load_image(image))
net.forward()
plt.subplot(4, 1, 1)
plt.imshow(Image.open(image))
plt.axis('off')
#conv1
plt.subplot(4, 1, 2)
feat_conv= net.blobs['conv1'].data[0, :36]
vis_square(feat_conv)
feat_fc= net.blobs['fc6'].data[0]
print feat_fc.shape
#print 'full connect feature:',type(feat_fc)
plt.subplot(4, 1, 3)
plt.plot(feat_fc.flat)
plt.subplot(4, 1, 4)
_ = plt.hist(feat_fc.flat[feat_fc.flat > 0], bins=100)
feat_fc.shape=(4096,1)
row_feat_fc=np.transpose(feat_fc)
#print row_feat_fc.shape
#np.savetxt("E:/Keras_Code/examples/imagenet/savefeatures.txt",row_feat_fc)
sio.savemat("E:/Keras_Code/examples/imagenet/savefeatures.mat", {'feature':row_feat_fc})
#http://www.07net01.com/2016/05/1502443.html
#filters = net.params['conv1'][0].data
#with open('FirstLayerFilter.pickle','wb') as f:
# pickle.dump(filters,f)
#vis_square(filters.transpose(0, 2, 3, 1))
#http://blog.csdn.net/thy_2014/article/details/51659300
#with open('FirstLayerOutput.pickle','wb') as f:
# pickle.dump(feat,f)
#pool = net.blobs['pool1'].data[0,:36]
#with open('pool1.pickle','wb') as f:
# pickle.dump(pool,f)
#vis_square(pool,padval=1)
#vis_square(pool)
#http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/00-classification.ipynb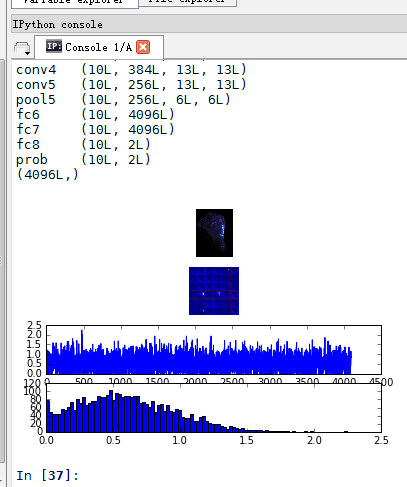 第一张是我要提取特征的原图 第二张是36个小图 即卷积层的输出 第三个是fc6层特征
第一张是我要提取特征的原图 第二张是36个小图 即卷积层的输出 第三个是fc6层特征
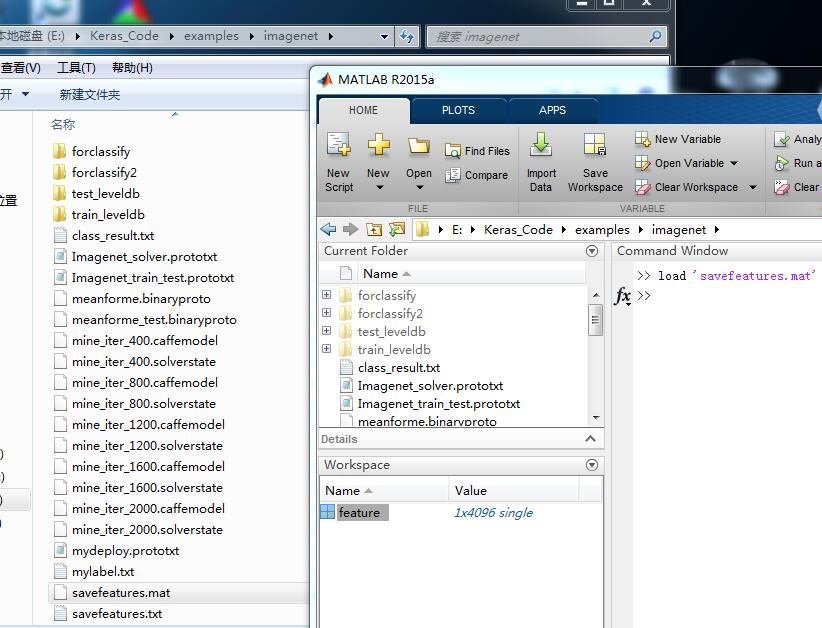 保存为mat !
保存为mat !
//
上面是提取一张图片特征并保存 现在是提取一个文件夹下的所有图片并保存:
#extract many images in one folder
import os
import numpy as np
import matplotlib.pyplot as plt
import caffe
from useless_test import vis_square
from PIL import Image
import scipy.io as sio
caffe.set_mode_gpu()
caffe.set_device(0)
deployPrototxt ='E:/Keras_Code/examples/imagenet/mydeploy.prototxt'
modelFile ='E:/Keras_Code/examples/imagenet/mine_iter_800.caffemodel'
mean_file='E:/Keras_Code/examples/imagenet/meanforme.binaryproto'
net = caffe.Net(deployPrototxt, modelFile,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
mean_blob = caffe.proto.caffe_pb2.BlobProto()
mean_blob.ParseFromString(open(mean_file, 'rb').read())
mean_npy = caffe.io.blobproto_to_array(mean_blob)
b2=mean_npy[0,:,:,:]
transformer.set_mean('data',b2.mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
net.blobs['data'].reshape(1,3,227,227)
dir_path='E:/Keras_Code/examples/imagenet/forclassify'
filelists=os.listdir(dir_path)
#print filelists
#dim=4096 changed by you
features = np.empty((len(filelists),4096),dtype="float32")
for ind,everyimg in enumerate(filelists):
theimg='E:/Keras_Code/examples/imagenet/forclassify/'+everyimg
net.blobs['data'].data[...] = transformer.preprocess('data',caffe.io.load_image(theimg))
net.forward()
feat_fc= net.blobs['fc6'].data[0]
feat_fc.shape=(4096,1)
row_feat_fc=np.transpose(feat_fc)
features[ind,:]=row_feat_fc
#np.savetxt("E:/Keras_Code/examples/imagenet/savefeatures.txt",row_feat_fc)
sio.savemat("E:/Keras_Code/examples/imagenet/imgsfeatures.mat", {'feature':features})
 OK!我的那个文件夹下只有8张图片!
OK!我的那个文件夹下只有8张图片!
///
我想设计自己的层,不用自带model里面的层,设计自己的层就得会计算每层的输入输出:
http://www.myexception.cn/other/1828071.html 按照这个:
我要学着计算这个 就以上面那个模型为例好了 它的层设置是这样子:
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "examples/imagenet/meanforme.binaryproto"
}
data_param {
source: "examples/imagenet/train_leveldb"
batch_size: 8
backend: LEVELDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "examples/imagenet/meanforme.binaryproto"
}
data_param {
source: "examples/imagenet/test_leveldb"
batch_size: 1
backend: LEVELDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TRAIN
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}
data的1L是不是batchsize?为什么是1呢?是指测试集的batchsize吗?为什么不是训练集的batchsize:8呢? 输入是3X227X227的 ......经过计算conv1后http://www.myexception.cn/other/1828071.html 可以得到96(num_output: 96)和55X55 但是 这个10?是怎么来的 ?默认的吗?.......计算经过pool1后,我按照公式计算出来是96X27X27......再经过norm1(不变),依旧是96X27X27.......然后是经过conv2,num_output: 256 默认步长stride是1哦 所以又计算出来是 256X27X27.....再经过pool2后,又计算出来的确是256X13X13.....后面的几层我都会按照这样计算了。
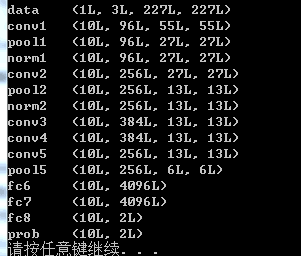
那么问题是 那个data的1是train还是test的batchsize或者什么? 为什么会在conv1变成10?是不是train和test不能写在同一个prototxt中????
哦 我明白了 后面的10是这个文件中设置的:

data中的1是 在预测分类和提取特征时设置的:
和别人讨论后,我觉得应该这样理解 :因为自己的deploy.prototxt文件主要用在2个地方:提取每层的特征和对新图片预测分类
提取特征时.py中:net.blobs['data'].reshape(1,3,227,227) 这句中的1的确代表batchsize 但代表的是要提取多少张图片一次性 的batchsize
预测分类时deploy中:input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } } 这个10也的确是代表batchsize 但代表的是一次性预测多少张图片的类别 的batchsize
个人觉得和我们训练集测试集训练模型的那个测试集的batchsize没太大关系 是这样吗????????????
/
别人给了我猫的图片12000张 狗的图片12000张 我试试这个二分类 :我拿98张猫和94张狗做测试集 剩余的都是训练集 :
一、首先对训练集生成标签、测试集生成对应标签:
#include<iostream>
#include<string>
int main()
{
FILE *fid1;
fid1 = fopen("test_labels9.27.txt", "w");
int label0 = 0, label1 = 1;
char name[15], label[2], black[] = "\r\n";
memset(name, 0, sizeof(name));
for (int i = 0; i < 98; ++i)
{
itoa(i, name, 10);
strcat(name, ".jpg ");
itoa(label0, label, 10);
strcat(name, label);
printf("%s", name);
fwrite(name, sizeof(name), 1, fid1);
fwrite(black, strlen(black), 1, fid1);
memset(name, 0, sizeof(name));
memset(label, 0, sizeof(label));
}
for (int i =98; i < 192; ++i)
{
itoa(i, name, 10);
strcat(name, ".jpg ");
itoa(label1, label, 10);
strcat(name, label);
printf("%s", name);
fwrite(name, sizeof(name), 1, fid1);
fwrite(black, strlen(black), 1, fid1);
memset(name, 0, sizeof(name));
memset(label, 0, sizeof(label));
}
fclose(fid1);
return 0;
}二、将训练测试集转为lmdb格式
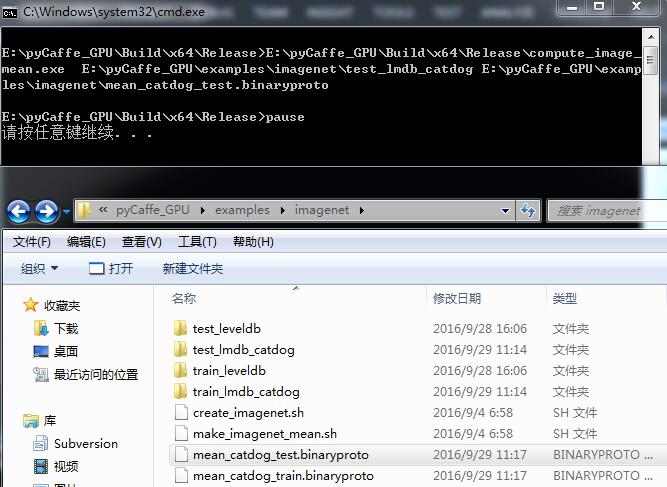
E:\pyCaffe_GPU\Build\x64\Release\convert_imageset.exe E:\pyCaffe_GPU\Build\x64\Release\mytest\ E:\pyCaffe_GPU\Build\x64\Release\mytest\test_labels9.27.txt E:\pyCaffe_GPU\examples\imagenet\test_lmdb_catdog -backend=lmdb
pause<img src="https://img-blog.csdn.net/20160929103509301" alt="" />
训练集也是这样:
三、生成训练测试集的mean文件:
E:\pyCaffe_GPU\Build\x64\Release\compute_image_mean.exe E:\pyCaffe_GPU\examples\imagenet\train_lmdb_catdog E:\pyCaffe_GPU\examples\imagenet\mean_catdog_train.binaryproto
pause 测试集也是这样
四、写那两个prototxt文件:
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 300
mean_file: "examples/imagenet/mean_catdog_train.binaryproto"
}
data_param {
source: "examples/imagenet/train_lmdb_catdog"
batch_size: 20
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 300
mean_file: "examples/imagenet/mean_catdog_test.binaryproto"
}
data_param {
source: "examples/imagenet/test_lmdb_catdog"
batch_size: 5
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 102
kernel_size: 3
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 204
kernel_size: 5
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 5
stride: 1
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 300
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 5
stride: 3
}
}
layer {
name: "fc4"
type: "InnerProduct"
bottom: "pool3"
top: "fc4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2050
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "fc4"
top: "fc4"
}
layer {
name: "drop4"
type: "Dropout"
bottom: "fc4"
top: "fc4"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc5"
type: "InnerProduct"
bottom: "fc4"
top: "fc5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc5"
bottom: "label"
top: "accuracy"
include {
phase: TRAIN
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc5"
bottom: "label"
top: "loss"
}
net: "examples/imagenet/my_traintest.prototxt"
test_iter: 40
test_interval: 50
base_lr: 0.001
momentum: 0.9
weight_decay: 0.0005
lr_policy: "inv"
gamma: 0.001
power: 0.75
display: 10
max_iter: 20000
snapshot: 1000
snapshot_prefix: "examples/imagenet/catdog"
solver_mode: GPU五、写train.bat进行训练:
.\Build\x64\Release\caffe.exe train --solver=.\examples\imagenet\my_solver.prototxt
pause
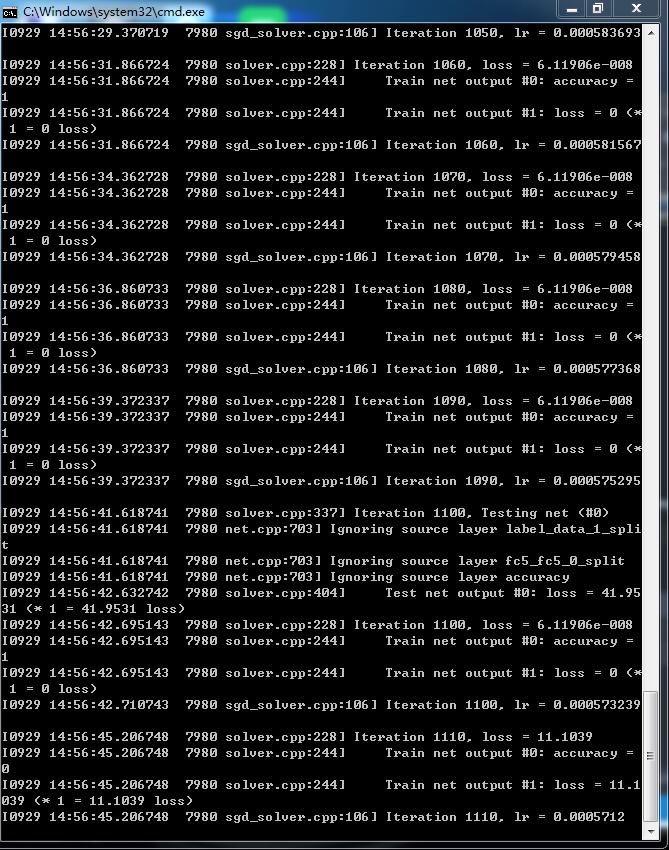
等。。。。。。。。。。。。。。。。
六、结果:

2万多图片 这个准确率 可以了!
/分界线/
用第一个模型 就是caffe自带的一个较复杂的模型 预测1016张图片的类别:

结果需要时间: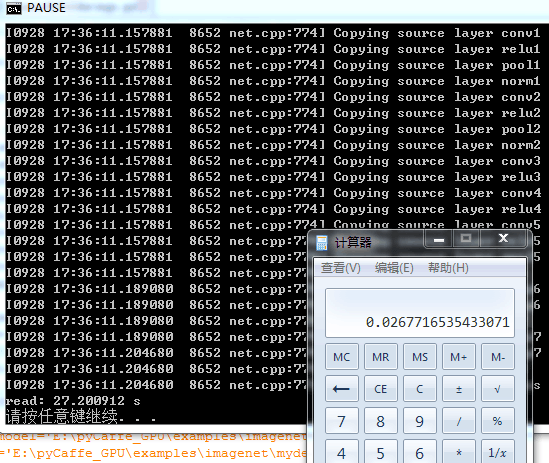
我乱编了一个较简短的模型 如下:
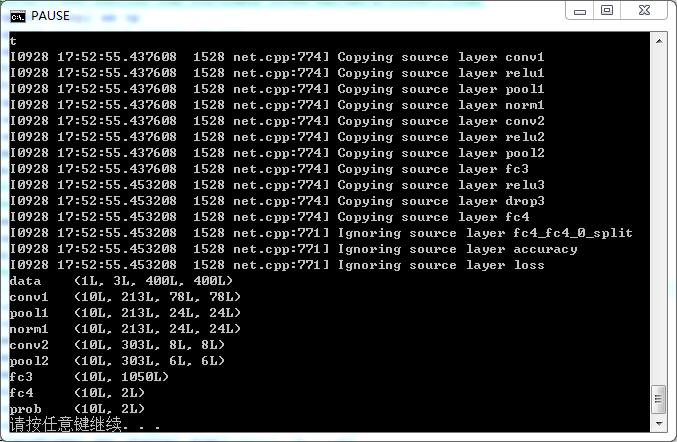

/今天下班就可以去嗨了哈哈
七天假哈哈/嘴巴都笑烂了哈哈
对我自己的图片重新来训练:
一、转换lmdb:
E:\pyCaffe_GPU\Build\x64\Release\convert_imageset.exe E:\pyCaffe_GPU\Build\x64\Release\test_mine\ E:\pyCaffe_GPU\Build\x64\Release\test_mine\test_labels.txt E:\pyCaffe_GPU\examples\imagenet\test_lmdb_mine --shuffle -backend=lmdb
pause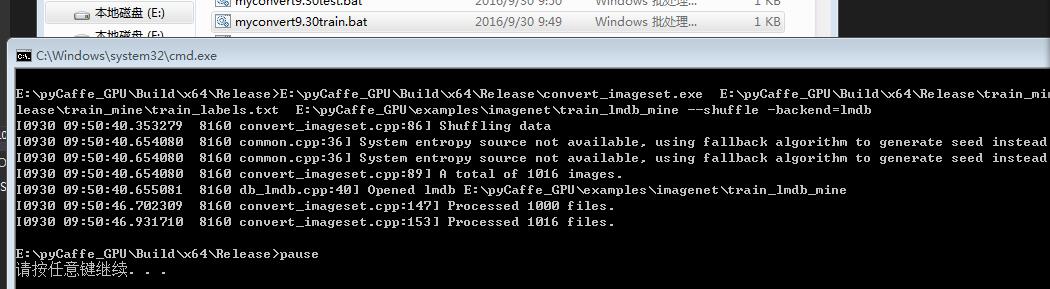
二、算mean
E:\pyCaffe_GPU\Build\x64\Release\compute_image_mean.exe E:\pyCaffe_GPU\examples\imagenet\train_lmdb_mine E:\pyCaffe_GPU\examples\imagenet\mean_mine_train.binaryproto
pause 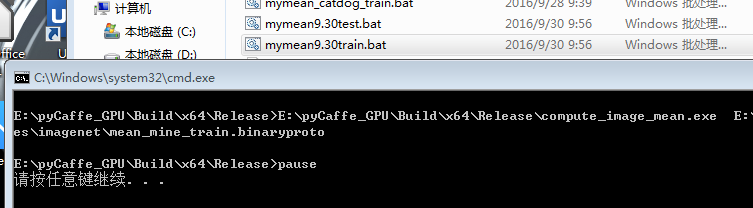
三、prototxt文件:
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 300
mean_file: "E:/pyCaffe_GPU/examples/imagenet/mean_mine_train.binaryproto"
}
data_param {
source: "E:/pyCaffe_GPU/examples/imagenet/train_lmdb_mine/"
batch_size: 10
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 300
mean_file: "E:/pyCaffe_GPU/examples/imagenet/mean_mine_test.binaryproto"
}
data_param {
source: "E:/pyCaffe_GPU/examples/imagenet/test_lmdb_mine/"
batch_size: 1
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 102
kernel_size: 3
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 204
kernel_size: 5
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 5
stride: 1
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 300
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 5
stride: 3
}
}
layer {
name: "fc4"
type: "InnerProduct"
bottom: "pool3"
top: "fc4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2050
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "fc4"
top: "fc4"
}
layer {
name: "drop4"
type: "Dropout"
bottom: "fc4"
top: "fc4"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc5"
type: "InnerProduct"
bottom: "fc4"
top: "fc5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc5"
bottom: "label"
top: "accuracy"
include {
phase: TRAIN
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc5"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc5"
bottom: "label"
top: "loss"
}
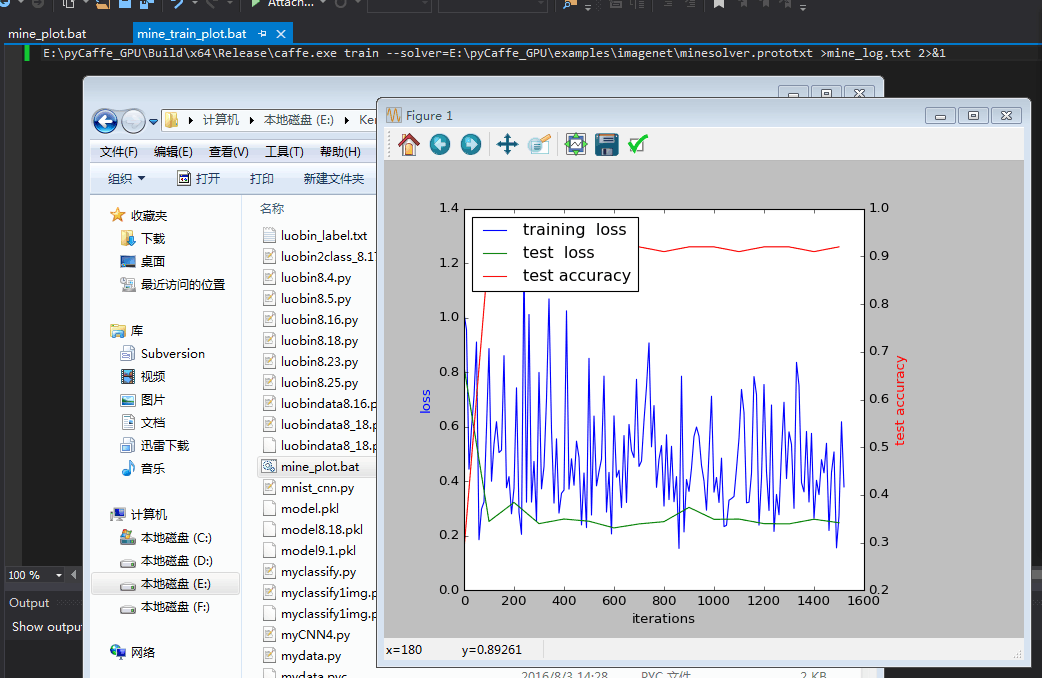
http://download.csdn.net/detail/wd1603926823/9671251 plot.py
这是1600次的图 等它执行完20000次我再看。。。
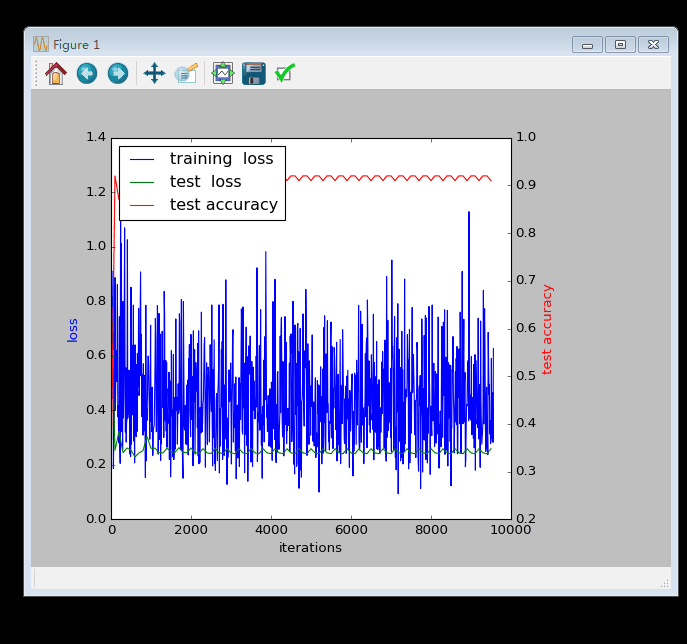

大功告成!
五、用最后一次的模型提取特征:

六、用最后一次的模型预测类别:

七、将类别结果保存:
#http://www.111cn.net/phper/python/47504.htm
import time
start=time.clock()
import os
from myclassify1img import classify1img
import caffe
caffe.set_mode_gpu()
caffe.set_device(0)
dir_path='E:/Keras_Code/examples/imagenet/forclassify/'
'''
imgsextension=['bmp']
os.chdir(dir_path)
imglist2=[]
for extension in imgsextension:
extension='*.'+extension
imglist2+=[os.path.realpath(e) for e in glob.glob(extension)]
print imglist2
'''
imglist=[]
for path,d,filelist in os.walk(dir_path):
filelist.sort(key= lambda x:int(x[:-4]))
for filename in filelist:
mypath =dir_path + filename
#print filename
#print mypath
#imglist+=[mypath]
imglist.append(mypath)
#print imglist
net_file='E:\pyCaffe_GPU\examples\imagenet\mydeploy_mine.prototxt'
caffe_model='E:\pyCaffe_GPU\examples\imagenet\mine_iter_20000.caffemodel'
mean_file='E:\pyCaffe_GPU\examples\imagenet\mean_mine_train.binaryproto'
class_result='E:\Keras_Code\examples\imagenet\class_result.txt'
net = caffe.Net(net_file,caffe_model,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
#transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
mean_blob = caffe.proto.caffe_pb2.BlobProto()
mean_blob.ParseFromString(open(mean_file, 'rb').read())
mean_npy = caffe.io.blobproto_to_array(mean_blob)
b2=mean_npy[0,:,:,:]
transformer.set_mean('data',b2.mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0)) # if using RGB instead if BGR
#img=caffe.io.load_image('E:/Keras_Code/examples/imagenet/forclassify/test13.bmp')
imagenet_labels_filename = 'E:/Keras_Code/examples/imagenet/mylabel.txt'
allclass=[]
for file in imglist:
img=file
myclass=classify1img(imagenet_labels_filename,net,transformer,img)
#f.write(myclass+'\n')
allclass.append(myclass)
f=open(class_result,'w')
for ind in range(len(filelist)):
f.write(filelist[ind]+' '+allclass[ind]+'\n')
f.close()
finish=time.clock()
print "read: %f s"%(finish - start) 可以了!
可以了!
还有一个小时就要放七天假了 内心澎湃/
caffe整个流程终于全部完了 而且准确了 哈哈
训练模型、预测分类、提取特征
终于都搞完了
谢谢很多人的帮助
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











