






文章基本信息:
论文一:《Multimodal Transformer for Unaligned Multimodal Language Sequences》 ACL 2019
论文二:《MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis》 ACM MM 2020
论文三:《Disentangled Representation Learning for Multimodal Emotion Recognition》ACM MM 2022
论文四:《Attention is not Enough: Mitigating the Distribution Discrepancy in Asynchronous Multimodal Sequence Fusion》ICCV 2021
论文资源:链接:Baidu Netdisk 提取码:Zs3T
《Multimodal Transformer for Unaligned Multimodal Language Sequences》
该论文是多模态情感识别领域中最早采用跨模态融合技术的文献,提出了基于Transformer框架跨模态交互的MuIT模型,为后续文章模态融合部分奠定基础。
1. 研究问题
1)多模态融合中存在由于每种模态序列的采样率不同,导致固有的数据不对齐的问题。
2)不同模态的元素之间存在着长依赖关系现象。
2. 解决方案
针对以上的问题,该文章引入Multimodal Transformer(MuIT)模型。巧妙地设计Transformer框架中的多头注意力模块,使其实现定向成对的跨模态注意力。进一步关注不同时间步长的多模态序列之间的交互,并潜移默化地将序列从一种模态调整到另一种模态,达到跨模态学习的目的。在经过手动模态对齐的数据集上,MuIT能够达到更好的效果,与此同时,在未经对齐的数据集中,MuIT也同样有着不错的表现,超过了一些在对齐数据集上训练的模型。
3. 技术路线
下图为MuIT的整体架构图:
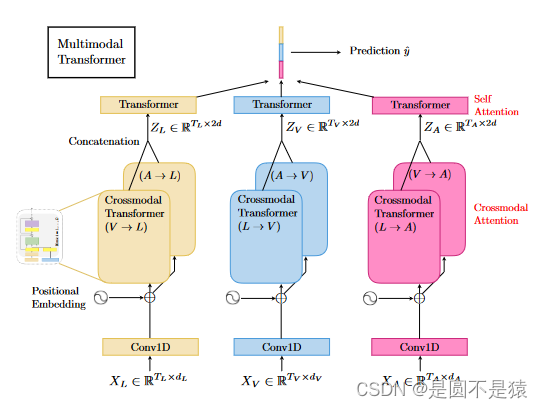
模型的大致流程是从多模态情感数据集中提取的视觉、语音、文本模态的低级特征先经过一维的时空卷积层,即让序列拥有“潜在的上下文认知”。接着加上位置编码序列(此时位置编码和Transformer模型中的位置编码构造方式一致)。然后进入跨模态融合模块(核心部分)使各个模态之间实现交互。最后通过自注意力方式完成交互后的序列拼接、融合工作,这样每个模态序列当中都结合了其他模态的相关信息,使得情感识别效果得到提升。
核心部分:Crossmodal Transformers
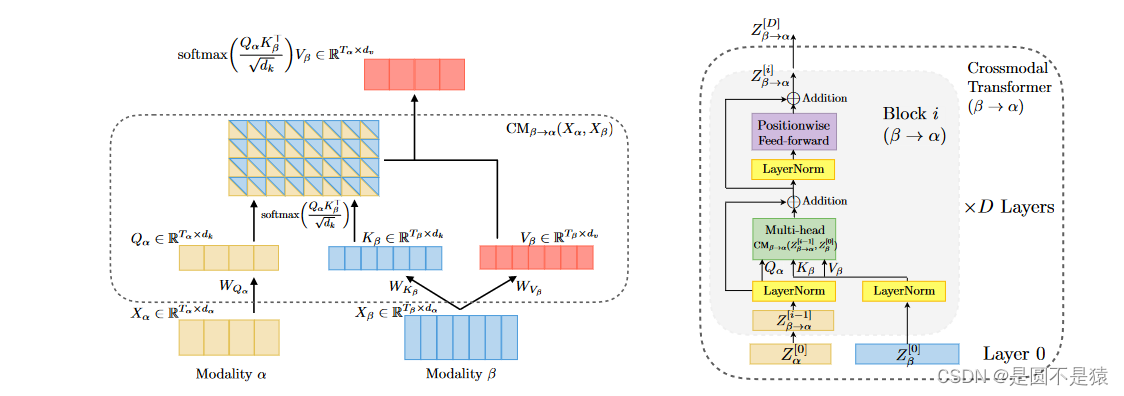
该模块为本文的核心内容,通过利用Transformer框架多头注意力中K、Q、V之间的运算关系实现情感状态的跨模态关注。与Transformer多头自注意力不同,Q为当前模态的序列,K、V为另外两种模态序列,矩阵相乘巧妙地将他们融合在一起,配合着叠加运算,最后拼接、Self-Attention融合完成跨模态学习。详细的运算过程可进一步分析本文的公式,或者结合Attention Is All You Need理解。
4. 实验结果
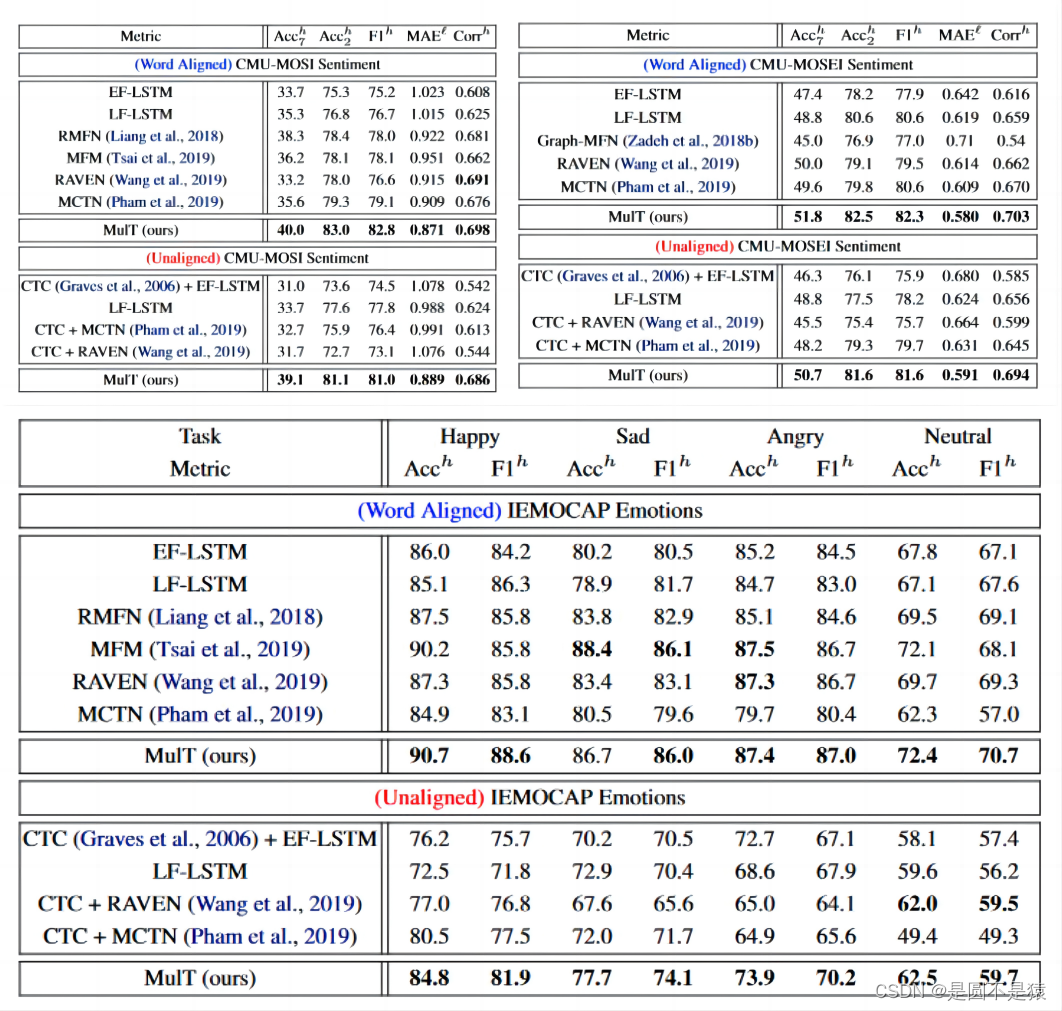
本文重点讨论在未进行模态对齐的数据集中模型测试的效果,分别在CMU-MOSI、CMU-MOSEI情感识别数据集和IEMOCAP情绪识别数据集上进行实验,给出对齐模态和未对齐模态的实验结果。
《MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis》
该文章着重探讨如何在特征空间中采取领域自适应的方案实现增强模态表征效果,研究模态不变子空间和特定模态子空间的关系,利用领域自适应方法构建适用于多模态特征空间交互的方案,学习不同模态之间的共性并缩小模态差距,能够有效增强模态融合的效果。本文在融合部分并未使用复杂的融合机制,这一遗憾将被后一文章弥补。
1. 研究问题
1)多模态信号的异质性造成了模态在特征空间分布上的差距。
2)不同模态之间的独特特征会影响多模态的全面表征。
2. 解决方案
本文提出MISA框架,其将三种模态投影到两个不同的子空间。第一个子空间是模态不变的(构建Similarity Loss),不同模态的表征在这里学习它们的共性并缩小模态差距,达到更好的对齐效果。第二个子空间是模态特定的(构建Difference Loss),是每种模态的私有空间,在面对模态各自的特点时能够更好的利用并弥补模态不变的特征。除此之外,本文还采用基于重构的领域自适应方案,使表征学习后的序列经Decoder尽可能的还原之前的样本(构建mean squared error loss),进一步约束模态表征。融合模块中将表征空间的序列采用多头自注意力机制进行融合,实现下游情感识别的任务。
3. 技术路线
MISA的整体网络框架图:
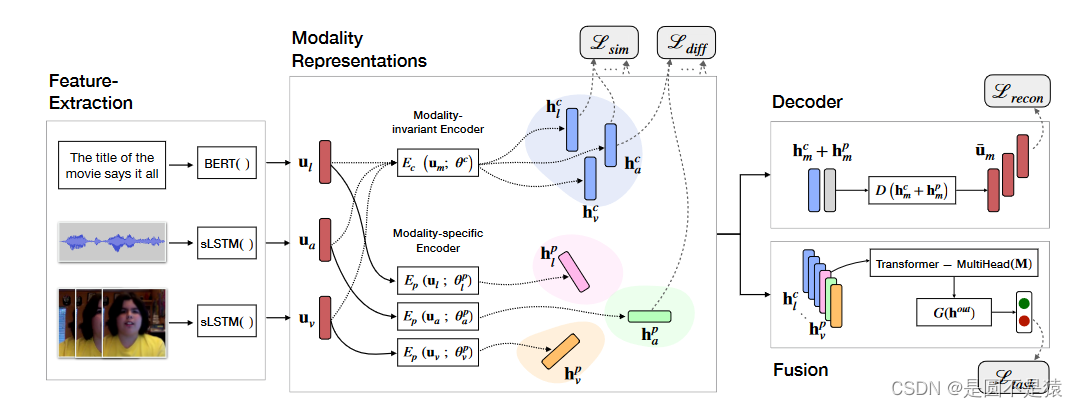
该模型分为特征提取、模态表征、模态融合三部分,在特征提取阶段与上一文献的最大区别是在文本模态中采用BERT模型优化特征序列,使文本信号蕴含“常识”信息,其他两种模态经LSTM模型学习“前后文”关系。模态表征学习为模型的核心部分,不同模态被分别投射到模态不变和模态特定子空间内。模态不变子空间内通过构建相似性损失衡量模态之间的相关性,同时达到模态对齐的效果;模态特定子空间内通过构建差异损失捕获相同模态信息不同方面的特性,缩小不同模态信号之间的异质性和冗余性;为了降低特定模态编码器存在学习琐碎表征的风险,采用构建重构损失策略,进一步约束多模态表征学习。最后的融合模块将来自模态表征学习的六种序列利用多头自注意力机制拼接、融合在一起。
模态不变子空间的相似性损失:Central Moment Discrepancy (CMD)—中心距差异
模态特定子空间的差异损失:Soft Orthogonality Constraint—软正交约束
重构损失:序列经解码后构建mean squared error loss—均方误差
本文的核心是构建多种损失函数共同约束模态表征学习,深入内容需进一步分析文章的公式。
4. 实验结果
该论文重点研究提升多模态表征学习的策略,在模态融合之前追求不同模态之间相似性、差异性学习,达到模态对齐的效果,在模态融合阶段未给出创新的策略。最终分别在CMU-MOSI、CMU-MOSEI情感识别数据集和UR_FUNNY幽默检测数据集上进行实验,展示了消融各部分损失对结果的影响情况。
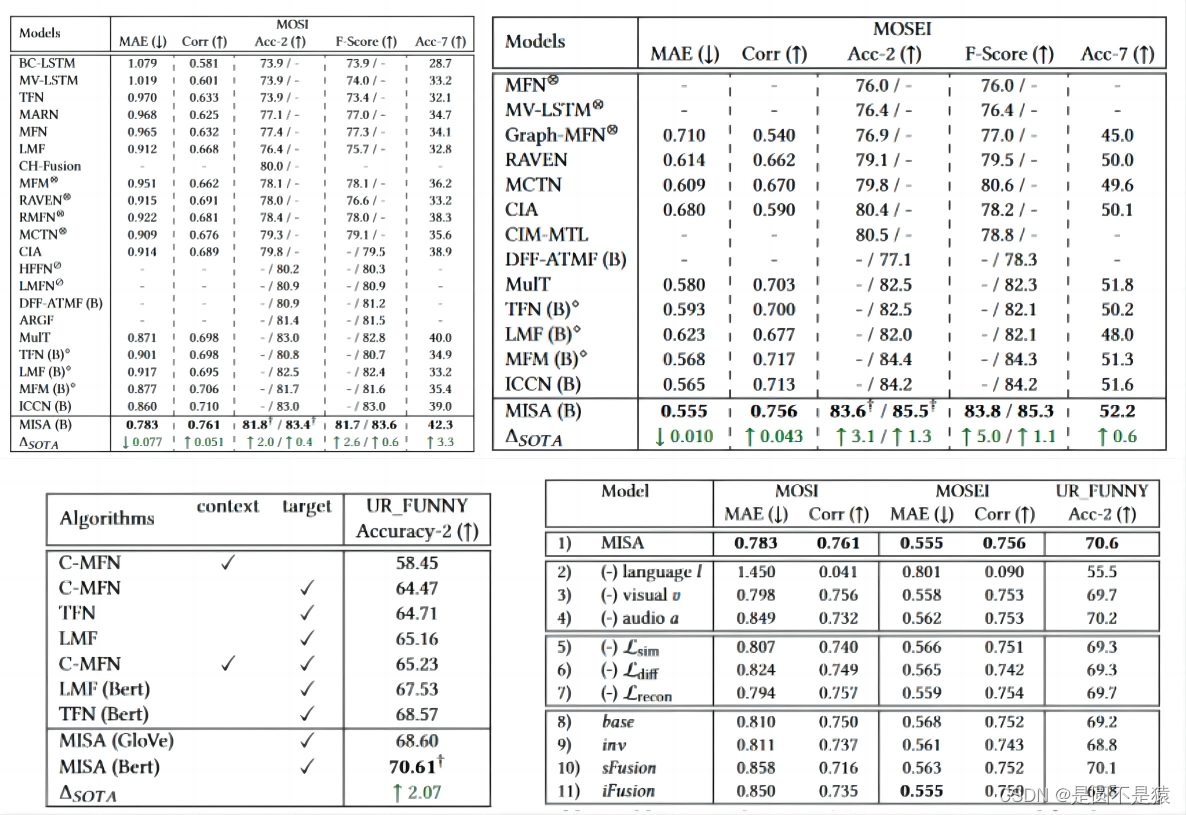
《Disentangled Representation Learning for Multimodal Emotion Recognition》
该文章直观来看是文献一和文献二的结合,提出特征离散多模态情感识别(FDMER)模型将多模态领域自适应方法和跨模态融合相结合,实现“1+1>2”的效果。与第二篇文献类似,本文在模态分离表征学习阶段分析模态不变和特定模态子空间特征的关系,探索模态之间的相关性,并解决不同模态之间的分布差距和信息冗余问题。在多模态融合部分采用类似文献一的跨模态融合方案,使其更好的融合经表征学习后的模态特征。相当于两文献的分别结合。
1. 研究问题
1)以往的方法要么探索不同模态之间的相关性,要么设计复杂的融合策略,没有很好的将他们结合。
2)异构模态之间往往存在分布差距和信息冗余,导致学习到的多模态表征可能不够精细。
2. 解决方案
本文提出FDMER模型框架,在特征离散表征学习部分与文献二的MISA模型相似,它采用新的领域自适应函数对投影到模态不变子空间和特定模态子空间的特征分别构建Consistency Constraint(一致性约束)损失和Disparity Constraint(差异性约束)损失。除了使用不同方式设计损失函数,该模型为优化模态投影与模态表征的效果,提出一种模态判别器来识别模态标签,并以对抗学习的方式指导共用和私有编码器的参数学习(对MISA问题的解决)。模态融合使用跨模态交互和自适应注意力实现。
3. 技术路线
下图为FDMER的整体架构图:
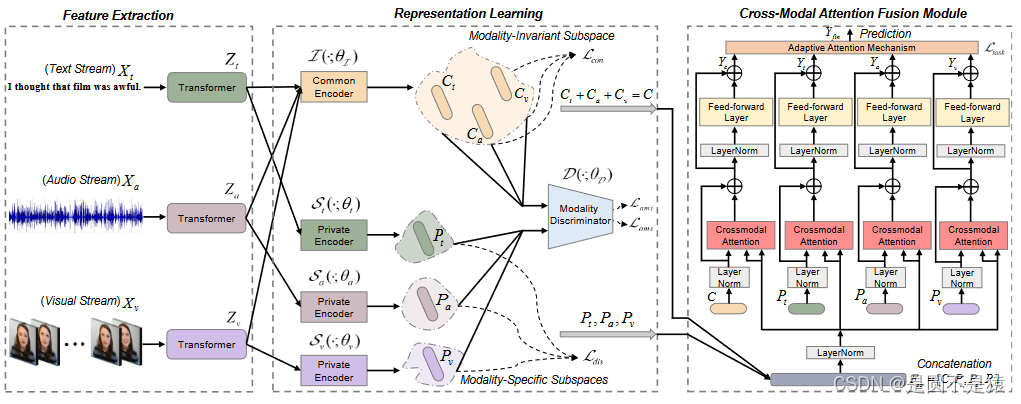
该模型分为特征提取、表示学习、跨模态注意力融合三个部分。三个模态信号均通过Transformer进行初始的“上下文学习”。文本模态给出两种特征提取方式,进一步验证了在文本模态使用BERT提取特征的有效性。核心部分是通过将每种模态投射到模态不变子空间和模态特定子空间来学习共同和私有特征表征。在表征学习部分,设计了一致性约束和差异约束,以分别增强共用表征之间的共性和减少私有表征之间的冗余。分析MISA其是一种次优解决方案,仅利用简单的约束条件无法保证学习到的表征完美地投射到所需的子空间,该文引入了一个模态判别器来明确监督共用表征和私有表征的学习,即在模态不变子空间中缩小模态之间的分布差距,同时在特定模态子空间中学习每种模态的独特特征。在模态融合部分,提出了一个跨模态注意力融合模块,以实现不同表征之间的信息交互和融合,自适应注意力机制可根据每个强化表征的重要性为其分配动态权重。最终,融合后的多模态表征将用于执行下游任务。模型相对更加复杂,有着更大的训练代价(All models are built on the Pytorch toolbox with four Nvidia Tesla V100 GPUs)。
模态不变子空间的一致性约束损失:𝐿2-normalization和Squared Frobenius Norm结合构造一致性约束。
模态特定子空间的差异性约束损失:Hilbert-Schmidt Independence Criterion (HSIC)—希尔伯特-施密特独立性准则
生成对抗策略:modality discriminator—模态判别器(监督和优化模态表征学习)
本文的核心是构建多种损失函数共同约束模态表征学习,深入内容需进一步分析文章的公式。跨模态注意力融合模块的跨模态交互阶段和MuIT模型原理基本一致,自适应注意力机制通过分配动态权重获取强化表征的重要程度。
4. 实验结果
该论文重点研究多模态表征学习的策略并设计完善的多模态融合方案。与MISA相同的是都在模态不变子空间和特定模态子空间上操作,不同之处是,其研究一致性约束和差异性约束对投射的特征的影响,并将MISA的重构策略改成生成对抗策略优化特征空间投射和模态表征学习的效果,最终要达到的目的两者是相似的。在模态融合阶段给出了跨模态注意力的策略,弥补了MISA的不足。同样,最终分别在CMU-MOSI、CMU-MOSEI情感识别数据集和UR_FUNNY幽默检测数据集上进行实验,展示了消融各部分损失对结果的影响情况。
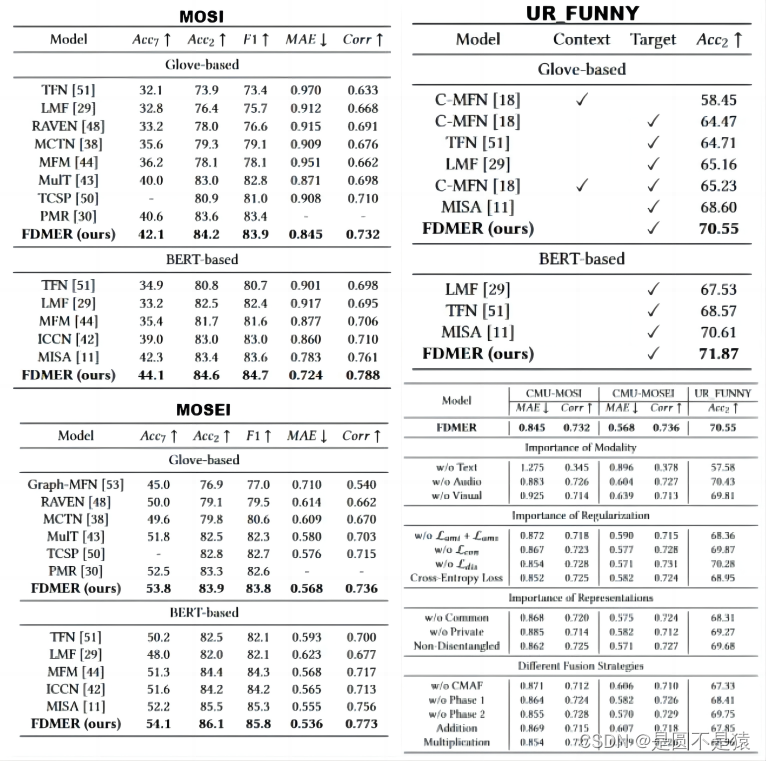
《Attention is not Enough: Mitigating the Distribution Discrepancy in Asynchronous Multimodal Sequence Fusion》
本文以MuIT模型为基准,学习该模型扩展Transforner网络的自注意力机制,以捕获元素之间的跨模态依赖关系。同时,将模态不变子空间中的领域自适应方法应用在跨模态融合网络内,减轻不同模态特征分布不匹配的影响,获取可靠的跨模态依赖关系。与文献三的区别是领域自适应与模态融合是在一起的,并未分成两部分。
1. 研究问题
1)每种模态的序列接收频率不同,收集到的多模态信号通常存在固有的不同步性。
2)直接应用跨模态注意力会受到不同模态特征分布不匹配的影响,学习到的跨模态依赖关系可能并不可靠。
2. 解决方案
针对上述问题并结合MuIT模型在未对齐模态中的良好表现,本文提出从异步多模态序列进行模态融合的 MICA 方法。该模型框架与MuIT基本一致,主要从跨模态注意力机制中的K、Q向量入手,探索是否可以通过其调整跨模态分布差异来建立更好的跨模态相关性模型。本文将跨模态相关性信息沿网络层传播,即在前一层中具有高置信度相关性的元素也将参与后续层的元素级对齐损失(如 L2 loss)。这种传播策略可以加强网络各层之间的一致性,并引导 Transformer 网络逐步获得更好的元素间跨模态相关性。与原始的 MulT 模型相比,该模型可以克服不同模态之间的分布差异,并为异步多模态序列的多模态融合建立更可靠的跨模态关系。
3. 技术路线
下图为MICA的整体架构图:
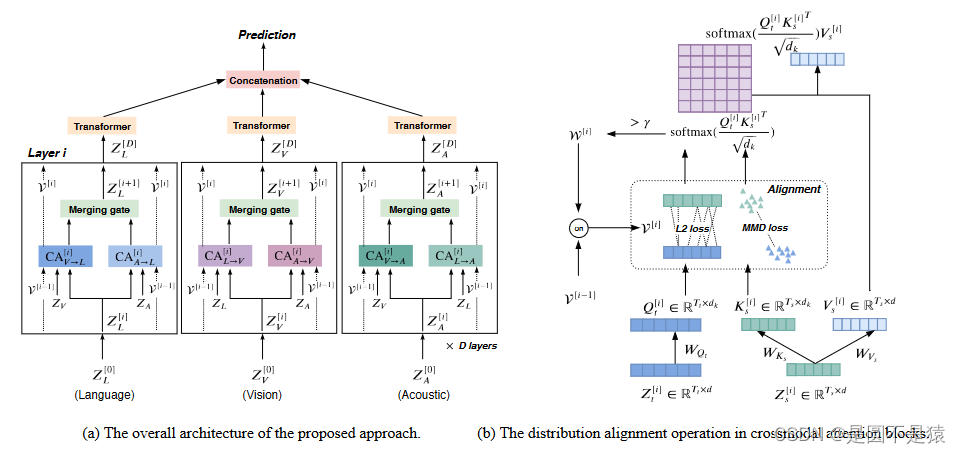
该模型与MulT 模型流程大致相同,不同的地方是MulT模型计算完D层结果后再进行完整的融合,而本文的模型是每一层都通过Merging gate进行一次融合(详细可阅读文章3.4节)。模型的核心部分是在每层的跨模态注意力运算中加入匹配特征分配策略,通过边际分布调整和传播元素级对齐减少跨模态的分布差异(均从跨模态注意力中代表不同模态的Q、V入手)。
Marginal distribution alignment:将K、Q向量映射到公共空间,构建MMD alignment解决边际分配不匹配问题。
Propagated element-level alignment:研究K、Q向量的关系,分析L2 distance,探索不同层元素的相关性,构建元素级对齐损耗。
4. 实验结果
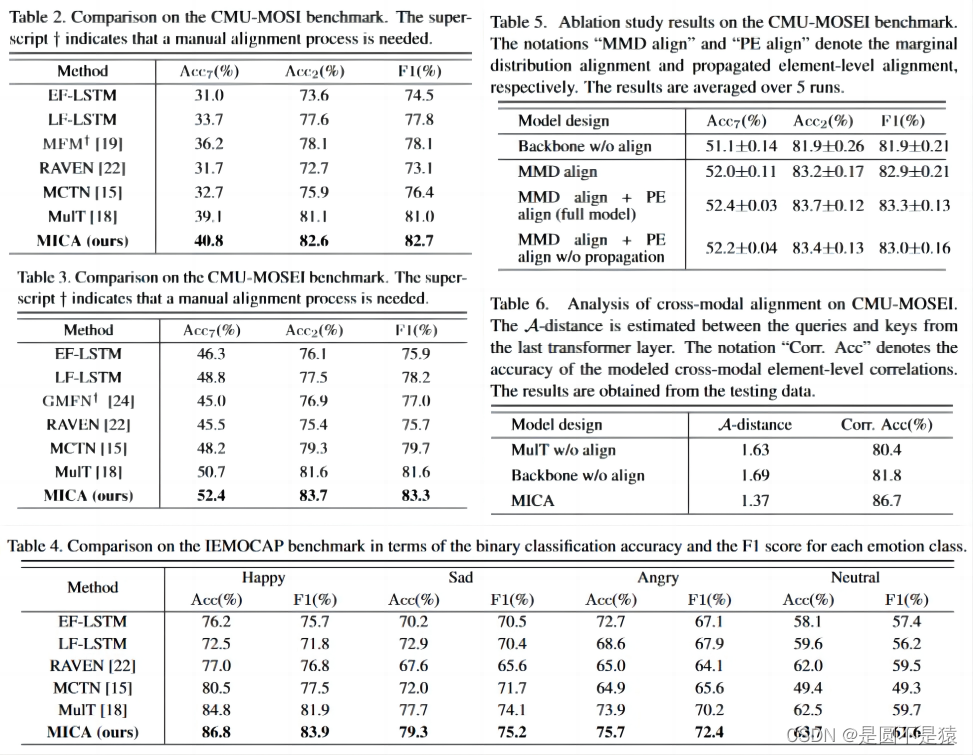
该论文在MuIT的基础上在模态不变空间上进行跨模态注意力,弥合了跨模态的分布差距。同时对边缘分布失配和元素级失配进行对齐,以减小分布差异。分别在CMU-MOSI、CMU-MOSEI情感识别数据集和IEMOCAP情绪识别数据集上进行实验,展示了消融各部分损失对结果的影响情况。

















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









