一 从感知机到深度学习
第一个正式的神经元模型是由沃伦·麦卡洛克(Warren Maculloach)和沃尔特·皮茨(Walter Pitts)于1943.年提出的。这个模型看起来很像组成计算机的逻辑门。麦克洛克-皮茨神经元做不了的事情就是学习。为此我们需要对神经元之间的连接给予不同的权重,这就是所谓的“感知机”。感知机于20世纪50年代由康奈尔大学的心理学家弗兰克·罗森布拉特(Frank Rosenblatt)发明。
在感知机中,一个正权值代表一个兴奋性连接,一个负权值代表一个抑制性连接。如果其输入量的加权和高于界限值,那么会输出1;如果加权和小于界限值,那么输入0。通过改变权值和界限值,我们可以改变感知器计算的函数。当然,这种做法忽略了神经元发挥作用的很多细节,但我们想让这个过程尽可能简单点。单个感知机的局限是无法解决XOR这类非线性不可分问题。
二 多层感知机的原理
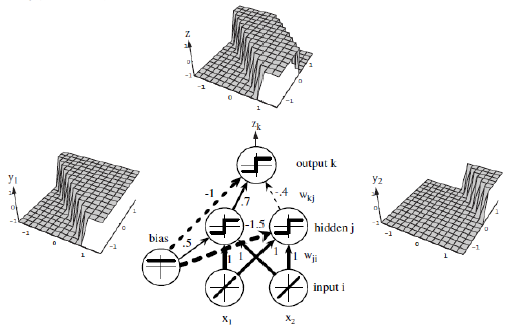
单个感知器虽然无法解决异或问题,但却可以通过将多个感知器组合,实现复杂空间的分割。如下图:
多个感知器组合成多层网络可解决XOR问题,但不能解决所有非线性可分问题。我们用非线性激活函数,可以拟合任意函数。求导用误差反向传播方法,求极值用梯度下降法。具体求导用Theano或TensorFlow封装的方法。
梯度下降法的步子大小是个很重要的技巧。在离极值点远的时候步子可以大一些,离极值点近的时候步子要小一些。可以动态调整学习率。如下图:
三 从贝叶斯角度看正则化
1. 正则化的目的:防止过拟合!2. 正则化的本质:约束(限制)要优化的参数。
从贝叶斯角度
看正则化就是最大后验概率估计(Maximum A Posteriori Estimation, MAP)
,正则项等价于引入参数的先验概率分布。常见的L1/L2正则,分别等价于引入先验信息:参数符合拉普拉斯分布/高斯分布。













 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 391
391





