







 本文详细介绍了视频抠图问题的数学模型,创新点在于使用背景图、分割结果和连续帧作为先验信息,并提出ContextSwitchingBlock模块。通过半监督学习提升模型泛化能力,网络结构包含Encoder-Decoder、ResBlock和Decoder组件,分别处理图像、背景、分割和视频帧信息。此外,文章还分析了网络的编码器、选择器和解码器结构,以及对抗训练过程。损失函数包括Alpha的L1Loss、gradientLoss、前景L1Loss和整体合成Loss。训练过程结合有监督和无监督学习,优化模型在不同数据集上的表现。
本文详细介绍了视频抠图问题的数学模型,创新点在于使用背景图、分割结果和连续帧作为先验信息,并提出ContextSwitchingBlock模块。通过半监督学习提升模型泛化能力,网络结构包含Encoder-Decoder、ResBlock和Decoder组件,分别处理图像、背景、分割和视频帧信息。此外,文章还分析了网络的编码器、选择器和解码器结构,以及对抗训练过程。损失函数包括Alpha的L1Loss、gradientLoss、前景L1Loss和整体合成Loss。训练过程结合有监督和无监督学习,优化模型在不同数据集上的表现。
一、要解决的问题
抠图问题可以概括为:
I = α ∗ F + ( 1 − α ) B I=\alpha *F+(1-\alpha)B I=α∗F+(1−α)B
其中, I I I表示输入图像(待扣图像),F表示前景图,B表示背景图。 α \alpha α表示输入点像素属于前景点像素的概率。
二、创新点
- 输入使用了背景图,分割结果(自动抠图),连续帧(视频)作为先验信息
- 提出了Context Switching Block模块用于整合上面的数据
- 提出了半监督的学习方式来提升模型的泛化能力
三、具体细节
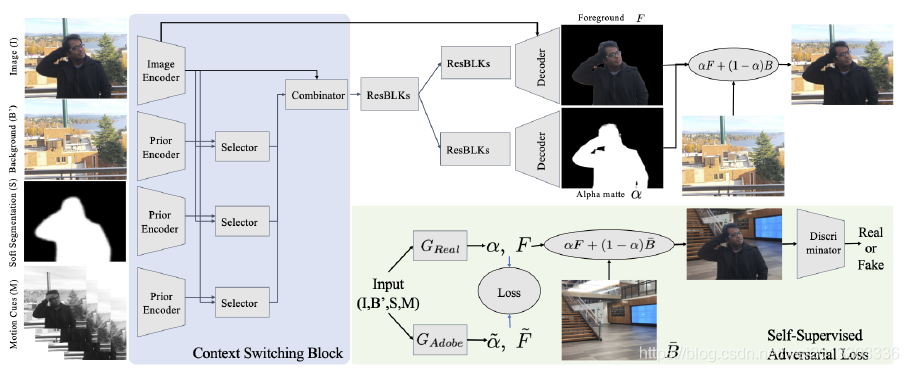
BG-v1的网络结构为经典的Encoder-Decoder结构。
Encoder部分包括四个输入:图像、背景图、Deeplab-v3分割结构图、视频帧序列(如果是视频抠图,转灰度)。
每个输入对应一个特征Encoder网络。然后,将四个Encoder网络的输出组合后输入三个相同的Selector网络,进一步进行特征融合与提取。
最后将Selector的输出与Image Encoder的输出combain后,融入Resblock进行特征抽取。
最后网络特征送入Decoder网络进行解码,解码结果包括了网络预测的前景图和alpha图。
BG-v1为了提高模型的泛化能力,使得模型能够在不同分布的数据集上进行抠图(不同的人解释成“跨域迁移”或者“知识蒸馏”),又添加了后续的无监督对抗训练过程。
该过程以前面的Encoder-Decoder网络作为生成器G,作为待训练的目标域知识学习网络(或称学生网络)。并使用在Adobe抠图数据集上训练好的 G a d o b e G_{adobe} Gadobe作为源域知识提取网络(或称教师网络),用 G a d o b e G_{adobe} Gadobe作为部分监督信号。生成器G和后面的判别网络D构成生成对抗网络,用于提高网络抠图的准确性,增强G在目标域上的拟合能力。
后续结合代码对上述网络以及关键损失函数进行说明。
四、代码分析
4.1 网络结构在network.py文件中。
- 输入图像的Encoder网络为:
#main encoder output 256xW/4xH/4
model_enc1 = [nn.ReflectionPad2d(3),nn.Conv2d(input_nc[0], ngf, kernel_size=7, padding=0,bias=use_bias),norm_layer(ngf),nn.ReLU(True)]
model_enc1 += [nn.Conv2d(ngf , ngf * 2, kernel_size=3,stride=2, padding=1, bias=use_bias),norm_layer(ngf * 2),nn.ReLU(True)]
model_enc2 = [nn.Conv2d(ngf*2 , ngf * 4, kernel_size=3,stride=2, padding=1, bias=use_bias),norm_layer(ngf * 4),nn.ReLU(True)]
输入图像首先进行镜像Padding,提高边缘的平滑度。然后接3个卷积层+BN+ReLU套装,其中第1个卷积层卷积核kerner_size=7,stride=1,使用大卷积核保持低维度信息的完整性,后两个卷积核的kerner_size=3,stride=2,用于进一步丰富特征信息,降低分辨率。输出的特征维度为: 256 ∗ H 4 ∗ W 4 256*\frac{H}{4}*\frac{W}{4} 256∗4H∗4W
- 后续Backgroun、Segmation、frames的Encoder的网络结构类似,以background为例:
#back encoder output 256xW/4xH/4
model_enc_back = [nn.ReflectionPad2d(3),nn.Conv2d(input_nc[1], ngf, kernel_size=7, padding=0,bias=use_bias),norm_layer(ngf),nn.ReLU(True)]
n_downsampling = 2
for i in range(n_downsampling):
mult = 2**i
model_enc_back += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3,stride=2, padding=1, bias=use_bias),norm_layer(ngf * mult * 2),nn.ReLU(True)]
同样是,输入经过镜像Padding后接3个套装。尺寸与Image输入保持一致。
- 在输入Selector之前,需要对4个Encoder的输出进行组合。图中箭头比较多,所以从代码中看其组合的策略则是十分清晰且简单了:
首先是Selector的结构:
self.comb_back=nn.Sequential(nn.Conv2d(ngf * mult*2,nf_part,kernel_size=1,stride=1,padding=0,bias=False),norm_layer(ngf),nn.ReLU(True))
self.comb_seg=nn.Sequential(nn.Conv2d(ngf * mult*2,nf_part,kernel_size=1,stride=1,padding=0,bias=False),norm_layer(ngf),nn.ReLU(True))
self.comb_multi=nn.Sequential(nn.Conv2d(ngf * mult*2,nf_part,kernel_size=1,stride=1,padding=0,bias=False),norm_layer(ngf),nn.ReLU(True))
3个Selector的结构一致,但是是三个不同小网络,并不是同一个小网络的三次复用。
- 三个Selector的输出与Image encoder的输出再次Cat起来后,送入由ResBlock构成的特征提取网络:
model_res_dec=[nn.Conv2d(ngf * mult +3*nf_part,ngf*mult,kernel_size=1,stride=1,padding=0,bias=False),norm_layer(ngf*mult),nn.ReLU(True)]
for i in range(n_blocks1):
model_res_dec += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
- Decoder网络则是由两个平行的由ResBlock构成的解码网络,但是用于解码F和alpha的细节则有所不同。
对于前景F:在这个分支中,它首先将共享残差的解码经过一组3个残差块的解码器进行继续解码,得到名为out_dec_fg的Feature Map。解码的第一部分使用out_dec_fg作为输入,经过一组双线性差值上采样,卷积,BN,ReLU操作后得到out_dec_fg1。解码的第二部分使用out_dec_fg1和img_feat拼接之后的结果,依次经过双线性差值上采样,卷积,BN,ReLU,镜面Padding,卷积后得到model_dec_fg2。这一部分的核心代码如下:
model_res_dec_fg=[]
for i in range(n_blocks2):
model_res_dec_fg += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
...
model_dec_fg1=[nn.Upsample(scale_factor=2,mode='bilinear',align_corners = True),nn.Conv2d(ngf * 4, int(ngf * 2), 3, stride=1,padding=1),norm_layer(int(ngf * 2)),nn.ReLU(True)]
model_dec_fg2=[nn.Upsample(scale_factor=2,mode='bilinear',align_corners = True),nn.Conv2d(ngf * 4, ngf, 3, stride=1,padding=1),norm_layer(ngf),nn.ReLU(True),nn.ReflectionPad2d(3),nn.Conv2d(ngf, output_nc-1, kernel_size=7, padding=0)]
...
self.model_res_dec_fg=nn.Sequential(*model_res_dec_fg)
self.model_dec_fg1=nn.Sequential(*model_dec_fg1)
self.model_fg_out = nn.Sequential(*model_dec_fg2)
...
def forward(self, image,back,seg,multi):
out_dec_fg=self.model_res_dec_fg(out_dec)
out_dec_fg1=self.model_dec_fg1(out_dec_fg)
fg_out=self.model_fg_out(torch.cat([out_dec_fg1,img_feat1],dim=1))
对于alpha:和前景预测分支类似,它首先经过一组3个残差块的解码器进行继续解码,然后经过两组双线性差值,卷积,BN,ReLU操作进行解码,最后经过一组镜面Padding,卷积以及Tanh之后得到最终预测的alpha matte,使用Tanh的原因是因为alpha matte的每个像素的值需要介于0和1之间。这一部分的核心代码如下:
model_res_dec_al=[]
for i in range(n_blocks2):
model_res_dec_al += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
model_dec_al=[]
for i in range(n_downsampling):
mult = 2**(n_downsampling - i)
model_dec_al += [nn.Upsample(scale_factor=2,mode='bilinear',align_corners = True),nn.Conv2d(ngf * mult, int(ngf * mult / 2), 3, stride=1,padding=1),norm_layer(int(ngf * mult / 2)),nn.ReLU(True)]
model_dec_al += [nn.ReflectionPad2d(3),nn.Conv2d(ngf, 1, kernel_size=7, padding=0),nn.Tanh()]
...
self.model_res_dec_al=nn.Sequential(*model_res_dec_al)
self.model_al_out=nn.Sequential(*model_dec_al)
...
def forward(self, image,back,seg,multi):
out_dec_al=self.model_res_dec_al(out_dec)
al_out=self.model_al_out(out_dec_al)
附加整个forward过程:
def forward(self, image,back,seg,multi):
img_feat1=self.model_enc1(image)
img_feat=self.model_enc2(img_feat1)
back_feat=self.model_enc_back(back)
seg_feat=self.model_enc_seg(seg)
multi_feat=self.model_enc_multi(multi)
oth_feat=torch.cat([self.comb_back(torch.cat([img_feat,back_feat],dim=1)),self.comb_seg(torch.cat([img_feat,seg_feat],dim=1)),self.comb_multi(torch.cat([img_feat,back_feat],dim=1))],dim=1)
out_dec=self.model_res_dec(torch.cat([img_feat,oth_feat],dim=1))
out_dec_al=self.model_res_dec_al(out_dec)
al_out=self.model_al_out(out_dec_al)
out_dec_fg=self.model_res_dec_fg(out_dec)
out_dec_fg1=self.model_dec_fg1(out_dec_fg)
fg_out=self.model_fg_out(torch.cat([out_dec_fg1,img_feat1],dim=1))
return al_out, fg_out
- 为了提升在真实场景的抠图效果,Background Matting使用了基于pix2pixHD中提出的多尺度判别器(注:论文中给出的是使用PatchGAN,源码的实现是基于多尺度判别器,两个算法大同小异,不影响Background Matting的整体框架,这里以源码为准)的对抗训练对真实场景的无标签数据进行训练。

G r e a l G_{real} Greal为待训练的目标域抠图网络, G A d o b e G_{Adobe} GAdobe为使用Adobe数据训练好的已经初始化过程网络;多尺度判别器D用于判断在目标域上抠图的真实性。
4.2 网络训练的损失函数
- 有监督训练过程损失函数:
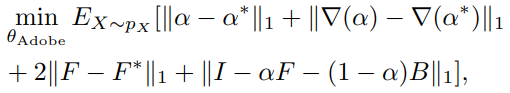
- Alpha包括两个损失函数:alpha的L1 Loss和gradient Loss****。L1 Loss通常作为抠图任务的alpha损失函数,相比于L2 Loss更容易获得尖锐清晰的边缘,同时gradient Loss项也对尖锐清晰的边缘有重要贡献。
- 前景损失函数则是第3项,即同样采用L1 Loss。
- 最后一项为整体合成Loss,即将预测的前景、alpha和输入的背景重新合成一张图,并和输入的图作L1 Loss。
- 四项损失的权重为{1, 1, 2, 1}
计算损失部分代码如下:
l1_loss=alpha_loss()
c_loss=compose_loss()
g_loss=alpha_gradient_loss()
...
al_loss=l1_loss(alpha,alpha_pred,mask0)
al_mask=(alpha_pred>0.95).type(torch.cuda.FloatTensor)
fg_pred_c=image*al_mask + fg_pred*(1-al_mask)
fg_c_loss= c_loss(image,alpha_pred,fg_pred_c,bg,mask0)
al_fg_c_loss=g_loss(alpha,alpha_pred,mask0)
loss=al_loss + 2*fg_loss + fg_c_loss + al_fg_c_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
- 无监督寻训练(对抗训练)损失函数:
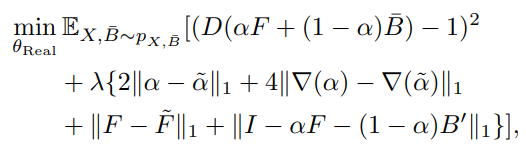
生成器 G r e a l G_{real} Greal损失如上:
- 第一项是来自判别器的损失函数, B ‾ \overline B B是从当前miniBatch中随机选取一张背景图,为了欺骗过判别器,需要判别器将该合成的图判别为真
- 第二项是 G r e a l G_{real} Greal预测的alpha与 G A d o b e G_{Adobe} GAdobe预测的alpha之间的L1 Loss和gradient Loss
- 第三项则是 G r e a l G_{real} Greal预测的前景F与 G A d o b e G_{Adobe} GAdobe预测的前景F之间的L1 Loss
- 第四项则是
G
r
e
a
l
G_{real}
Greal预测的前景F与预测的alpha结合输入的背景合成新图像与原输入图的合成Loss
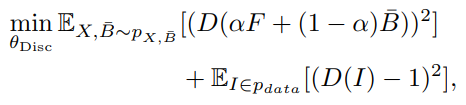
判别器D损失如上: - 第一项是首先从当前miniBatch中随机选取一张背景图 B ‾ \overline B B,然后与预测的alpha和F进行合成,判别器需要将其判别为假
- 第二项则是输入图像,判别器需要将其判别为真
训练过程代码如下:
for i,data in enumerate(train_loader):
#Initiating
bg, image, seg, multi_fr, seg_gt, back_rnd = data['bg'], data['image'], data['seg'], data['multi_fr'], data['seg-gt'], data['back-rnd']
bg, image, seg, multi_fr, seg_gt, back_rnd = Variable(bg.cuda()), Variable(image.cuda()), Variable(seg.cuda()), Variable(multi_fr.cuda()), Variable(seg_gt.cuda()), Variable(back_rnd.cuda())
mask0=Variable(torch.ones(seg.shape).cuda())
tr0=time.time()
#pseudo-supervision
alpha_pred_sup,fg_pred_sup=netB(image,bg,seg,multi_fr)
mask=(alpha_pred_sup>-0.98).type(torch.cuda.FloatTensor)
mask1=(seg_gt>0.95).type(torch.cuda.FloatTensor)
## Train Generator
alpha_pred,fg_pred=netG(image,bg,seg,multi_fr)
##pseudo-supervised losses
al_loss=l1_loss(alpha_pred_sup,alpha_pred,mask0)+0.5*g_loss(alpha_pred_sup,alpha_pred,mask0)
fg_loss=l1_loss(fg_pred_sup,fg_pred,mask)
#compose into same background
comp_loss= c_loss(image,alpha_pred,fg_pred,bg,mask1)
#randomly permute the background
perm=torch.LongTensor(np.random.permutation(bg.shape[0]))
bg_sh=bg[perm,:,:,:]
al_mask=(alpha_pred>0.95).type(torch.cuda.FloatTensor)
#Choose the target background for composition
#back_rnd: contains separate set of background videos captured
#bg_sh: contains randomly permuted captured background from the same minibatch
if np.random.random_sample() > 0.5:
bg_sh=back_rnd
image_sh=compose_image_withshift(alpha_pred,image*al_mask + fg_pred*(1-al_mask),bg_sh,seg)
fake_response=netD(image_sh)
loss_ganG=GAN_loss(fake_response,label_type=True)
lossG= loss_ganG + wt*(0.05*comp_loss+0.05*al_loss+0.05*fg_loss)
optimizerG.zero_grad()
lossG.backward()
optimizerG.step()
##Train Discriminator
fake_response=netD(image_sh); real_response=netD(image)
loss_ganD_fake=GAN_loss(fake_response,label_type=False)
loss_ganD_real=GAN_loss(real_response,label_type=True)
lossD=(loss_ganD_real+loss_ganD_fake)*0.5
# Update discriminator for every 5 generator update
if i%5 ==0:
optimizerD.zero_grad()
lossD.backward()
optimizerD.step()
各个Loss Function的实现如下:
class alpha_loss(_Loss):
def __init__(self):
super(alpha_loss,self).__init__()
def forward(self,alpha,alpha_pred,mask):
return normalized_l1_loss(alpha,alpha_pred,mask)
class compose_loss(_Loss):
def __init__(self):
super(compose_loss,self).__init__()
def forward(self,image,alpha_pred,fg,bg,mask):
alpha_pred=(alpha_pred+1)/2
comp=fg*alpha_pred + (1-alpha_pred)*bg
return normalized_l1_loss(image,comp,mask)
class alpha_gradient_loss(_Loss):
def __init__(self):
super(alpha_gradient_loss,self).__init__()
def forward(self,alpha,alpha_pred,mask):
fx = torch.Tensor([[1, 0, -1],[2, 0, -2],[1, 0, -1]]); fx=fx.view((1,1,3,3)); fx=Variable(fx.cuda())
fy = torch.Tensor([[1, 2, 1],[0, 0, 0],[-1, -2, -1]]); fy=fy.view((1,1,3,3)); fy=Variable(fy.cuda())
G_x = F.conv2d(alpha,fx,padding=1); G_y = F.conv2d(alpha,fy,padding=1)
G_x_pred = F.conv2d(alpha_pred,fx,padding=1); G_y_pred = F.conv2d(alpha_pred,fy,padding=1)
loss=normalized_l1_loss(G_x,G_x_pred,mask) + normalized_l1_loss(G_y,G_y_pred,mask)
return loss
class alpha_gradient_reg_loss(_Loss):
def __init__(self):
super(alpha_gradient_reg_loss,self).__init__()
def forward(self,alpha,mask):
fx = torch.Tensor([[1, 0, -1],[2, 0, -2],[1, 0, -1]]); fx=fx.view((1,1,3,3)); fx=Variable(fx.cuda())
fy = torch.Tensor([[1, 2, 1],[0, 0, 0],[-1, -2, -1]]); fy=fy.view((1,1,3,3)); fy=Variable(fy.cuda())
G_x = F.conv2d(alpha,fx,padding=1); G_y = F.conv2d(alpha,fy,padding=1)
loss=(torch.sum(torch.abs(G_x))+torch.sum(torch.abs(G_y)))/torch.sum(mask)
return loss
class GANloss(_Loss):
def __init__(self):
super(GANloss,self).__init__()
def forward(self,pred,label_type):
MSE=nn.MSELoss()
loss=0
for i in range(0,len(pred)):
if label_type:
labels=torch.ones(pred[i][0].shape)
else:
labels=torch.zeros(pred[i][0].shape)
labels=Variable(labels.cuda())
loss += MSE(pred[i][0],labels)
return loss/len(pred)
def normalized_l1_loss(alpha,alpha_pred,mask):
loss=0; eps=1e-6;
for i in range(alpha.shape[0]):
if mask[i,...].sum()>0:
loss = loss + torch.sum(torch.abs(alpha[i,...]*mask[i,...]-alpha_pred[i,...]*mask[i,...]))/(torch.sum(mask[i,...])+eps)
loss=loss/alpha.shape[0]
return loss
五、参考
https://zhuanlan.zhihu.com/p/148265115?from_voters_page=true

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









