









为了学习Pandas的用法,在网上查了很多帖子,但大部分帖子都是搬运工,不是太简单就是太复杂,不直观,似乎得是行家才行,而且没有讲到有实际意义的时候,就已经断片儿了,在这里分享一些完全是自己的数字+亲测,同时从范围上达到有一定的应用价值,不仅仅只讲一个点。
dishwasher_jobs.xlsx 这是例子数据,下载请用下面链接:
链接:https://pan.baidu.com/s/1MBb0Xq51K_927zjz6Lg52g
提取码:lo7l
如何安装python,这一步推荐廖雪峰的网站:安装Python,有文字和视频教程,很详细;这方面也有不少坑,要看各位运气,在此给几个相关的术语:PyCharm,Jupyter Notebook(小白首选),Anaconda(windows第一次安装很方便),这些都是Python的开发环境,至于哪个更好用需要各位自己决定。我在Windows上运气欠佳,最后选择在Linux上安装了Jupyter Notebook,出错的情况最少,目前使用的环境是 Debian9 + Python3.5 + Jupyter Notebook。
import pandas as pd
from pandas import DataFrame
df=pd.read_excel('dishwasher_jobs.xlsx') #全部读入
df

一共有7列和390行数据,但发布时间(黄色)有两种格式,这个格式可以在Excel里控制,请看下图:
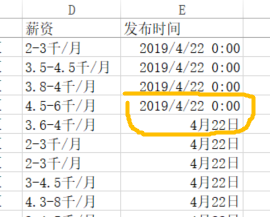
Excel表里的两种格式会直接影响到Python里的可读性。
下面的例子是通过加入列编号筛选usecols=[0,1,2,3]来限制读入的信息,这对很宽的表意义重大,现实中有很多表有50-60列,大部分字段是针对系统的。
如果你的EXCEL表里有更多花样可以看这篇分享,内容丰富。
df=pd.read_excel('dishwasher_jobs.xlsx',usecols=[0,1,2,3])
df

pd显示有很多很多变化,更多关于显示细节可以看这篇分享或PANDAS手册。
用下面的命令可以更改表里“列”的次序
pd.DataFrame(df, columns=[ '薪资', '工作地点','职位','公司名称'])

单例排序->“工作地点”
df=pd.read_excel('dishwasher_jobs.xlsx')
df.sort_values(by="工作地点",ascending=False)

根据“备注”排序
df.sort_values(by="备注",ascending=False)
 双列排序
双列排序
df.sort_values(by=["工作地点","薪资"],ascending=False)

根据序号排序
df.sort_index(ascending=False)
 显示工作地点在->广州-黄埔区,整个字段单选!
显示工作地点在->广州-黄埔区,整个字段单选!

2021年10月更新:显示工作地点在->广州-黄埔区,*整个字段单选!用这个命令更正规一些,用于更多的命令组合时不容易出错:
df.loc[df[‘工作地点’] == ‘广州-黄埔区’]
更复杂一点的工作地点筛选:整个字段多选!
 职位描述里包含“包吃住”,截取字段内容!
职位描述里包含“包吃住”,截取字段内容!
 更多关于字符函数可以看分享。
更多关于字符函数可以看分享。
另外我在原来数据了人工加入了一些“垃圾”字符作为例子,在做两个数据清洗的简单案例:
有“垃圾”字符的地方用红点标出了

用下面的命令就可以清除那些“垃圾”字符。
这个功能是非常有用的,不光可以清除“垃圾”,还可以用去除“固定”的词汇,有时可以帮很大的忙!
import re
bad_chars = ['?', '!', ',', ';', "'", '|', '-', ' ', '(', ')',
'[', ']', '[]', '{', '}', ':', '&', '\\n']
df['职位'] = df['职位'].str.replace('|'.join([re.escape(s) for s in bad_chars]), '')
df
下面是清理过的结果

下面的例子是把中文括号->西文括号,这是一个更简单和直观的替换方法,可以以此类推根据你的需要替换。
df['职位']=df['职位'].str.replace('(','(')
df['职位']=df['职位'].str.replace(')',')')
df
 统计功能
统计功能
data=df.groupby(['工作地点']).size() #分组统计
data

字段的拆分/切片
例子中的薪资99.99%是这样的格式:
3-4.5千/月
4-5万/年
3.5-4.5千/月
0.8-1万/月
如果想进一步分析,就需要拆分,51job招聘网站有非常多的爬网及分析例子,我所看到都用类似 if 循环函数写处理过程,有些分享写得非常漂亮,但Code却无法用,所以在此分享效率非常高,非常炫的两个Pandas功能,先将3-4.5千/月拆分成四个字段“薪资最低”,“薪资最高”,“千/万”,“月/年”
test1=df['薪资'].str.extract(r"^(\d?\.?\d)\-(\d?\.?\d)(\D)\/(\D?)") # 拆分只要一句
test1.columns = ["薪资最低","薪资最高","千/万","月/年"] # 给表头赋值
test1
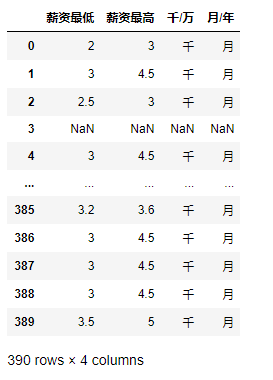
这里用的是正则表达式,这方面好的分享不多,这篇似乎还可以。
然后还要跟原始表拼接在一起。
test2 = pd.concat([df,test1],axis=1, join_axes=[df.index])
test2
 表拼接有好多花样,有兴趣可以看看这篇分享。
表拼接有好多花样,有兴趣可以看看这篇分享。
从上面的例子可以看到Python是非常强大的,当然在短短的命令里包含着很多东西,要完全弄懂需要花不少的时间,希望上面简单直观的例子对读者有点小小的帮助,下面用存入EXCEL文件作为本文的结束。
DataFrame(df).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)
将内存里加工过的内容写到example.xlsx里。
你现在心动了,想了解概貌请看这篇分享,更多详细信息可以访问潘大师中文官网。
还有一个相关的坑:
当pandas无法打开.xlsx文件,出错信息:
xlrd.biffh.XLRDError: Excel xlsx file; not supported
原因是xlrd更新到了2.0.1版本,只支持.xls文件。所以pandas.read_excel(‘xxx.xlsx’)会报错。
可以安装旧版xlrd 1.2.0,在cmd中运行:
pip uninstall xlrd
pip install xlrd==1.2.0 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
2021.10.分享
Pandas将列表(List)转换为数据框(Dataframe)进阶篇















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









