







背景: 视觉里程计
给两张图或者多张图, 去估计它们的相对位姿.
给一张图估计这张图的单目深度.
如果有一张图的深度, 两张图的相对位姿, 可以用一张图插值另一张图.
本质:通过深度学习的方法提取两图之间对应点(深度特征), 然后做两帧之间的位姿变换.
然后得到两帧之间的光流, 通过光流和位姿变换的关系得到深度图.
得到深度图, 光流, 位姿变换三者之间的耦合关系, 就可以构建自监督的约束关系.
自监督原理:
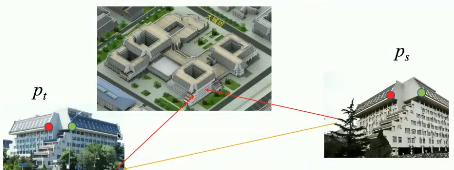
![]()
D(p_t): 第t张图的单目深度.
T: 和下一张图的位姿变换
然后去想象出来, 另外一张图, 想象出来的图, 和真实的图可以做光度误差(像素级别的相减), 进而可以做位姿和深度估计的问题.
问题是: 1. 单目的深度估计是通过网络得到的 2.相对位姿估计(位姿变换)也是通过网络得到
但是, 把预训练好的模型放到白天或者晚上不同, 或者有三维运动的场景, 往往是不work的.
即把预训练的模型, 放到未知的场景下, 往往是不work的.
所以, 文章的主题就是, 如何让任何一个深度模型, 在自监督的情况下, 做在线学习, 在线的适应.
即把模型放到不同的数据集下, 也有很好的效果.
三个挑战:
1.泛化: 如何用已知的模型去适应场景
2.在线学习思想, 在线学习很难得到有标注的数据(真值数据): 把每一张图片都作为一个数据集.
3.在线学习有收敛很慢的问题(灾难性遗忘: 在这个场景好不容易学习到的(或通过学习好不容易适应到这个场景) , 换到另一个场景还是需要很长时间). 我们希望模型在不断变换的过程中, 能够越来越块地收敛.
提出方法:

基于元学习的在线自监督学习.
(1)自监督: 一张图片的单目深度估计, 两张图片的位姿变换, 做自监督训练, 是一个已有方法 (网络: )
(2)在线学习: 第一个时刻进行训练之后, 如何把之前的经验迁移到下一个时刻(迁移:)
(3)元学习: 维护学习更加本质的任务
(和场景无关, 或者能够解耦场景特性的任务的分布)
(虽然场景不同, 但是做的任务都一样)
单纯的深度学习是对一个数据集进行梯度下降, 元学习是对两个数据集进行梯度下降. 目标函数的自变量是前一个时刻的网络参数
符号定义:
![]() : 在滑行窗口中, 采集到的一张图片
: 在滑行窗口中, 采集到的一张图片
![]() : 元学习的损失函数
: 元学习的损失函数
解释: 在即前一个时刻做梯度下降, 得到更新之后的模型, 再把这个模型用到新一个时刻上.
即优化 , 希望在第i个时刻, 和i+1时刻都能达到最小值. 这样就能让元学习的目标有一个预测的性质.
能够天然地泛化, 能够在前一个时刻, 更好地猜测到下一个时刻. 以这种方式更好地在线自监督学习.
其实是对两个数据集, 和
做梯度下降. 并且目标函数的自变量是前一个时刻的网络参数.
??原来的时间感受野是一, 现在是二. 即 在不同的时间有相同的表现.
卖点:
卖点一(在梯度上对齐): 梯度内积: 梯度方向做一致性约束, 让内积最大化
让内积最大化就有可能避免遗忘问题.
传统在线的遗忘问题就是, 它的梯度方向是随机的, 即面临不同时刻数据, 其调整方向是毫无规律的. 内积就可以把前一个时刻的梯度信息迁移到下一个时刻.
如果把前一个时刻的梯度和后一个时刻的梯度对齐, 或者做最大化相似度. 就相当于把前一个时刻的信息迁移到下一个时刻.

将目标函数进行泰勒展开, 发现一共有四项.
第一项:
第二项: 两个时刻梯度的内积, 在一阶优化的空间中提供最优方向.
第三项: 海森矩阵: 一般是0, 以Relu为主的CNN当中, Relu的二阶导一般是零. 所以, 高阶项是零.
第四项: 高阶项
卖点二(在时空上对齐): 将长短时序网络嵌入在CNN中:
对一个模型来说, 如果只用当前的东西做当前的预测可能比较难, 比如给一张图: 告诉其深度. 但是, 如果给一个视频, 或者做得比较好的估计, 去做多张图片的识别就容易许多.
所以, 将长短时序的网络嵌入在CNN的几层中, 做时空时序整合能够更好地预测当前的情况.

卖点三: 在线特征对齐(Online Feature Alignment)
在一个时刻抽取一个图片的多个feature(每一层都有几百维甚至更多维的feature),
一个batch中, 几张图, 某个维度的特征有统计特性(均值方差), 这些统计特性其实代表较为本质的东西. (比如: styleGAN, 本质就是通过均值方差, 把握最本质的东西, 进行人脸的变换),

实验:

(红线是本文的, 虚线是原本的, 可以看到效果较其他算法都好)
(这个实验由上千帧的位姿估计, 即每一个时刻的误差都可以累计到下一个时刻)

(本文误差, online很小)

(在室外的场景预训练, 直接迁移到室内的, 运动方式不一样的场景中. 虽然domain的gap非常大, 但是轨迹还是相对准确的)















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









