






Day 5
常用操作
双重升降序
import pandas as pd
data = pd.DataFrame({'group':['a','a','a','b','b','b','c','c','c'],'data':[4,3,2,1,12,3,4,5,7]})
data
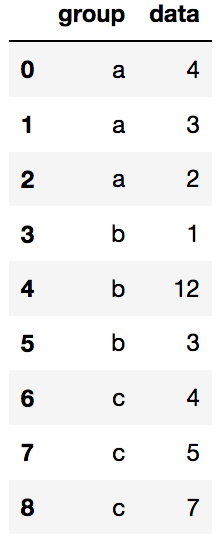
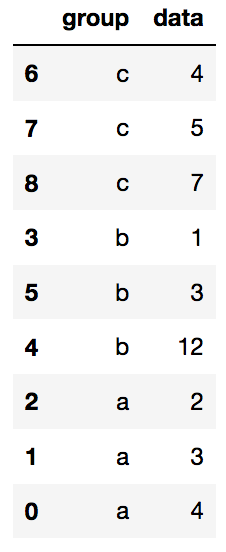
#在保证group降序的情况下,data升序
data.sort_values(by=['group','data'],ascending=[False,True],inplace=True)
data
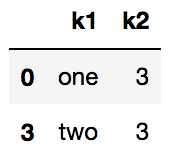
去重
data = pd.DataFrame({'k1':['one']*3+['two']*4,'k2':[3,2,1,3,3,4,4]})
data

data.drop_duplicates()

data.drop_duplicates(subset='k1')
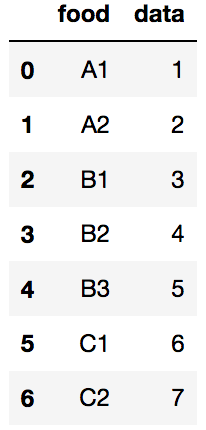
合并同类项
data = pd.DataFrame({'food':['A1','A2','B1','B2','B3','C1','C2'],'data':[1,2,3,4,5,6,7]})
data
#方法1
def food_map(series):
if series['food'] =='A1':
return 'A'
elif series['food'] == 'A2':
return 'A'
elif series['food'] == 'B1':
return 'B'
elif series['food'] == 'B2':
return 'B'
elif series['food'] == 'B3':
return 'B'
elif series['food'] == 'C1':
return 'C'
else:
return 'C'
data['food_map'] = data.apply(food_map,axis='columns')
data
#方法2
food2 = {
'A1':'A',
'A2':'A',
'B1':'B',
'B2':'B',
'B3':'B',
'C1':'C',
'C2':'C'
}
data['Upper'] = data['food'].map(food2)
data

增加属性
import numpy as np
df = pd.DataFrame({'data1':np.random.rand(5),
'data2':np.random.rand(5)})
df2 = df.assign(ration=df['data1']/df['data2'])
df2
# df['ration'] = [1,2,3,4,5]

去掉属性
df2.drop('ration',axis='columns',inplace=True)
df2
替换
data = pd.Series(np.arange(1,10))
data.replace(9,np.nan,inplace=True)
data
'''
0 1.0
1 2.0
2 3.0
3 4.0
4 5.0
5 6.0
6 7.0
7 8.0
8 NaN
dtype: float64
'''
cut操作
ages = [14,17,20,22,25,34,53,64,79,]
bins = [10,40,80]
bins_res = pd.cut(ages,bins)
bins_res
'''
[(10, 40], (10, 40], (10, 40], (10, 40], (10, 40], (10, 40], (40, 80], (40, 80], (40, 80]]
Categories (2, interval[int64]): [(10, 40] < (40, 80]]'
'''
bins_res.codes
# array([0, 0, 0, 0, 0, 0, 1, 1, 1], dtype=int8)
pd.value_counts(bins_res)
'''
(10, 40] 6
(40, 80] 3
dtype: int64
'''
pd.cut(ages,[10,30,50,80])
group_names = ['youth','milee','old']
pd.value_counts(pd.cut(ages,[10,30,50,80],labels=group_names))
'''
youth 5
old 3
milee 1
dtype: int64
'''
缺失值
df = pd.DataFrame([[0,np.nan,0],range(3),[0,0,np.nan],range(3)])
df.isnull()

df.isnull().any()
'''
0 False
1 True
2 True
dtype: bool
'''
df.isnull().any(axis=1)
'''
0 True
1 False
2 True
3 False
dtype: bool
'''
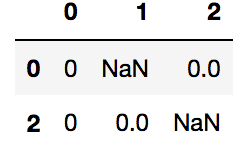
df.fillna(np.average(df,axis=1)[1])

df[df.isnull().any(axis=1)]
group延伸操作
按属性分组
df = pd.DataFrame({'A':['foo','bar','foo','bar','foo','bar','foo','foo'],
'B':['one','two','two','three','two','two','one','three'],
'C':np.random.randn(8),
'D':np.random.randn(8)})
df

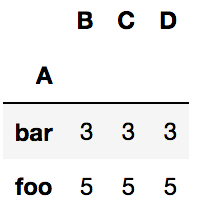
grouped = df.groupby('A')
grouped.count()
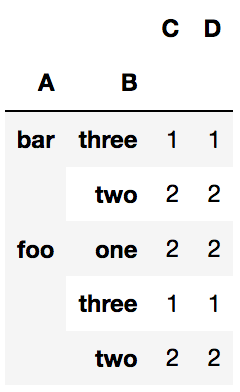
grouped = df.groupby(['A','B'])
grouped.count()
def get_letter_type(letter):
if letter.lower() in 'aeiou':
return 'a'
else:
return 'b'
grouped = df.groupby(get_letter_type,axis=1)
grouped.count()

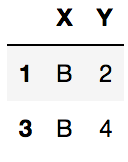
df2 = pd.DataFrame({'X':['A','B','A','B'],'Y':[1,2,3,4]})
df2
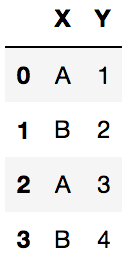
df2.groupby('X').get_group('B')
索引层级
一层
#索引层级
s = pd.Series([1,2,3,6,5,4],index=[8,7,5,8,7,5])
s
'''
8 1
7 2
5 3
8 6
7 5
5 4
dtype: int64
'''
grouped = s.groupby(level=0) #只有一个索引,所以level只能为0,默认升序排列
grouped.count()
'''
5 2
7 2
8 2
dtype: int64
'''
grouped.last()
'''
5 4
7 5
8 6
dtype: int64
'''
grouped.first()
'''
5 3
7 2
8 1
dtype: int64
'''
grouped.sum()
'''
5 7
7 7
8 7
dtype: int64
'''
grouped = s.groupby(level=0,sort=False)
grouped.first()
'''
8 1
7 2
5 3
'''
多层
#多重索引
arrays =[['foo','foo','bar','bar','baz','baz','qux','qux'],
['one','two','one','two','one','two','one','two']]
index = pd.MultiIndex.from_arrays(arrays,names=['first','second'])
s = pd.Series(np.random.randn(8),index=index)
s
'''
first second
foo one -0.271915
two 0.602038
bar one 0.354797
two -0.702492
baz one 0.775625
two 0.300726
qux one -0.012630
two 0.746706
dtype: float64
'''
grouped = s.groupby(level=0)
grouped.sum()
'''
first
bar -0.347695
baz 1.076351
foo 0.330123
qux 0.734077
dtype: float64
'''
grouped = s.groupby(level=1) #也可以指定索引名字
grouped.sum()
'''
second
one 0.845878
two 0.946978
dtype: float64
'''
df = pd.DataFrame({'A':['foo','bar','foo','bar','foo','bar','foo','foo'],
'B':['one','two','two','three','two','two','one','three'],
'C':np.random.randn(8),
'D':np.random.randn(8)})
grouped = df.groupby(['A','B'])
grouped.aggregate(np.sum)

grouped = df.groupby(['A','B'],as_index=False) #显示完整
grouped.aggregate(np.sum)
#or df.groupby(['A','B']).sum().reset_index()

grouped = df.groupby(['A','B'])
grouped.size()
'''
A B
bar three 1
two 2
foo one 2
three 1
two 2
dtype: int64
'''
grouped = df.groupby(['A','B'])
grouped.describe().head()

grouped = df.groupby('A')
grouped['C'].agg([np.sum,np.mean,np.std])
# grouped['C'].agg({'res_sum':np.sum,'res_mean':np.mean,'res_std':np.std})

字符串操作
s = pd.Series(['A','b','B','gaer','AGER',np.nan])
s
'''
0 A
1 b
2 B
3 gaer
4 AGER
5 NaN
dtype: object
'''
s.str.lower() #小写
s.str.upper() #大写
s.str.len() #长度
index = pd.Index([' tang',' yu','di'])
index.str.strip()#去掉空格
index.str.lstrip()#左边空格
index.str.rstrip()#右边空格
df = pd.DataFrame(np.random.randn(3,2),columns=['A a','B b'],index=range(3))
df
df.columns.str.replace(' ','_')
# Index(['A_a', 'B_b'], dtype='object')

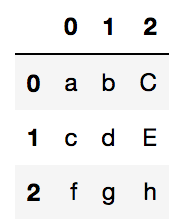
s = pd.Series(['a_b_C','c_d_E','f_g_h'])
s.str.split('_')
'''
0 [a, b, C]
1 [c, d, E]
2 [f, g, h]
dtype: object
'''
s.str.split('_',expand=True)
# or s.str.split('_',expand=True,n=2)
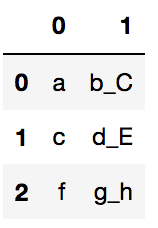
s.str.split('_',expand=True,n=1)
s = pd.Series(['A','Aas','Afgew','Ager','Agre','Ager'])
s
s.str.contains('A')
'''
0 True
1 True
2 True
3 True
4 True
5 True
dtype: bool
'''
s = pd.Series(['a','a|b','a|c'])
s.str.get_dummies(sep='|')
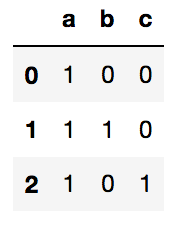
索引进阶
s = pd.Series(np.arange(5),index=np.arange(5)[::-1],dtype='int64')
s
'''
4 0
3 1
2 2
1 3
0 4
dtype: int64
'''
s.isin([1,3,4])
'''
4 False
3 True
2 False
1 True
0 True
dtype: bool
'''
s[s.isin([1,3,4])]
'''
3 1
1 3
0 4
dtype: int64
'''
s[s>2]
'''
1 3
0 4
dtype: int64
'''
s2 = pd.Series(np.arange(6),index=pd.MultiIndex.from_product([[0,1],['a','b','c']]))
s2
'''
0 a 0
b 1
c 2
1 a 3
b 4
c 5
dtype: int64
'''
s2.iloc[s2.index.isin([(1,'a'),(0,'b')])]
'''
0 b 1
1 a 3
dtype: int64
'''
dates = pd.date_range('20201124',periods=8)
df = pd.DataFrame(np.random.randn(8,4),index=dates,columns=['A','B','C','D'])
df

df['A'],df.A
'''
2020-11-24 1.226031
2020-11-25 -0.749144
2020-11-26 1.084139
2020-11-27 1.002452
2020-11-28 0.161032
2020-11-29 0.141020
2020-11-30 -0.502514
2020-12-01 0.372656
Freq: D, Name: A, dtype: float64
'''
df.where(df<0,-df) #小于零的保持,大于零的取反

df = pd.DataFrame(np.random.rand(10,3),columns=list('abc'))
df

df.query('(a<b)&(a>c)')

pandas绘图操作
#折线图
%matplotlib inline
s = pd.Series(np.random.randn(10),index = np.arange(0,100,10))
s.plot()

df = pd.DataFrame(np.random.randn(10,4).cumsum(0),index = np.arange(0,100,10),columns=['A','B','C','D'])
df.plot()

#柱状图
import matplotlib.pyplot as plt
fig,axes = plt.subplots(2,1) #2行一列
data = pd.Series(np.random.rand(16),index=list('abcdefghijklmnop'))
data.plot(ax = axes[0],kind='bar') #第一个图,垂直状
data.plot(ax = axes[1],kind='barh')#第二个图,水平状

df = pd.DataFrame(np.random.rand(6,4),index = ['one','two','three','four','five','six'],columns=pd.Index(['A','B','C','D'],name ='Genus'))
df.head()

df.plot(kind='bar')

#直方图
tips = pd.read_csv('tips.csv')
tips.head()

tips.total_bill.plot(kind='hist',bins=50) #直方图 压缩到50个区间

#散点图
macro = pd.read_csv('macrodata.csv')
macro.head()

data = macro[['quarter','realgdp','realcons']]
data.plot.scatter('realgdp','realcons')

#矩阵图
pd.plotting.scatter_matrix(data,color='k',alpha=0.3)

大数据处理技巧
gl = pd.read_csv('game_logs.csv')
gl.shape
# (171907, 161) 特征很多
gl.info(memory_usage='deep') #数据类型和内存占用
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 171907 entries, 0 to 171906
Columns: 161 entries, date to acquisition_info
dtypes: float64(77), int64(6), object(78) #三种数据类型
memory usage: 861.6 MB #内存占用
'''
#各种类型的数据分别占用的内存情况
for dtype in ['float64','int64','object']:
selected_dtype = gl.select_dtypes(include=[dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
mean_usage_mb = mean_usage_b/1024**2
print('平均内存占用',dtype,mean_usage_mb)
'''
平均内存占用 float64 1.294733194204477
平均内存占用 int64 1.1242000034877233
平均内存占用 object 9.52803864056551
'''
让内存占用少一点
#让内存少一点,其实int32就能满足需求
import numpy as np
int_types = ['uint8','int8','int16','int32','int64']
for it in int_types:
print(np.iinfo(it))
'''
Machine parameters for uint8
---------------------------------------------------------------
min = 0
max = 255
---------------------------------------------------------------
Machine parameters for int8
---------------------------------------------------------------
min = -128
max = 127
---------------------------------------------------------------
Machine parameters for int16
---------------------------------------------------------------
min = -32768
max = 32767
---------------------------------------------------------------
Machine parameters for int32
---------------------------------------------------------------
min = -2147483648
max = 2147483647
---------------------------------------------------------------
Machine parameters for int64
---------------------------------------------------------------
min = -9223372036854775808
max = 9223372036854775807
---------------------------------------------------------------
'''
# 计算内存函数
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame): #pd.DataFrame: pandas.core.frame.DataFrame
usage_b = pandas_obj.memory_usage(deep=True).sum()
else:
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b/1024**2
return '{:03.2f}MB'.format(usage_mb)
#int64降存
gl_int =gl.select_dtypes(include=['int64'])
#向下转化成int32
coverted_int = gl_int.apply(pd.to_numeric,downcast='unsigned')
print(mem_usage(gl_int))
print(mem_usage(coverted_int))
'''
7.87MB
1.48MB
'''
#float64降存
gl_float =gl.select_dtypes(include=['float64'])
coverted_float = gl_float.apply(pd.to_numeric,downcast='float')
print(mem_usage(gl_float))
print(mem_usage(coverted_float))
'''
100.99MB
50.49MB
'''
#整体优化效果
optimized_gl = gl.copy()
optimized_gl[coverted_int.columns] = coverted_int
optimized_gl[coverted_float.columns] = coverted_float
print(mem_usage(gl))
print(mem_usage(optimized_gl))
'''
861.57MB
804.69MB
'''
gl_obj = gl.select_dtypes(include=['object']).copy()
gl_obj.describe()

dtype:object–>dtype:category 如果重复值较多的话
dow = gl_obj.day_of_week
dow.head()
'''
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: object
'''
dow_cat = dow.astype('category')
dow_cat.head()
'''
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: category
Categories (7, object): [Fri, Mon, Sat, Sun, Thu, Tue, Wed]
'''
dow_cat.head().cat.codes
'''
0 4
1 0
2 2
3 1
4 5
dtype: int8
'''
print(mem_usage(dow))
print(mem_usage(dow_cat))
'''
9.84MB
0.16MB
'''
coverted_obj = pd.DataFrame()
for col in gl_obj.columns:
num_unique_values = len(gl_obj[col].unique()) #unique值的个数
num_total_values = len(gl_obj[col]) #所有值的个数
if num_unique_values/num_total_values < 0.5: # 如果unique值不到总体的一半,说明很多数值都是重复的,所以可以转化为category类型
coverted_obj.loc[:,col] = gl_obj[col].astype('category')
else:
coverted_obj.loc[:,col] = gl_obj[col]
#节省了大量内存
print(mem_usage(gl_obj))
print(mem_usage(coverted_obj))
'''
752.72MB
51.67MB
'''
整体优化效果
optimized_gl[coverted_obj.columns] = coverted_obj
print(mem_usage(gl))
print(mem_usage(optimized_gl))
'''
861.57MB
104.29MB
'''
日期格式内存比较
date = optimized_gl.date
date[:5]
'''
0 18710504
1 18710505
2 18710506
3 18710508
4 18710509
Name: date, dtype: uint32
'''
print(mem_usage(date))
#0.66MB
optimized_gl['date'] = pd.to_datetime(date,format='%Y%m%d')
print(mem_usage(optimized_gl['date'] ))
# 1.31MB















 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









