







一文搞定pandas的数据合并
在实际处理数据业务需求中,我们经常会遇到这样的需求:将多个表连接起来再进行数据的处理和分析,类似SQL中的连接查询功能。
pandas中也提供了几种方法来实现这个功能,表现最突出、使用最为广泛的方法是merge。本文中将下面👇四种方法及参数通过实际案例来进行具体讲解。
- merge
- append
- join
- concat

文章目录

导入库
做数据分析的时候这两个库是必须导入的,国际惯例一般。
import pandas as pd
import numpy as np
merge
官方参数
官方提供的merge函数的参数如下:

下面将通过案例讲解几个重要参数的使用方法:
DataFrame.merge(left, right,
how='inner', # {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
on=None,
left_on=None, right_on=None,
sort=False,
suffixes=('_x', '_y'))
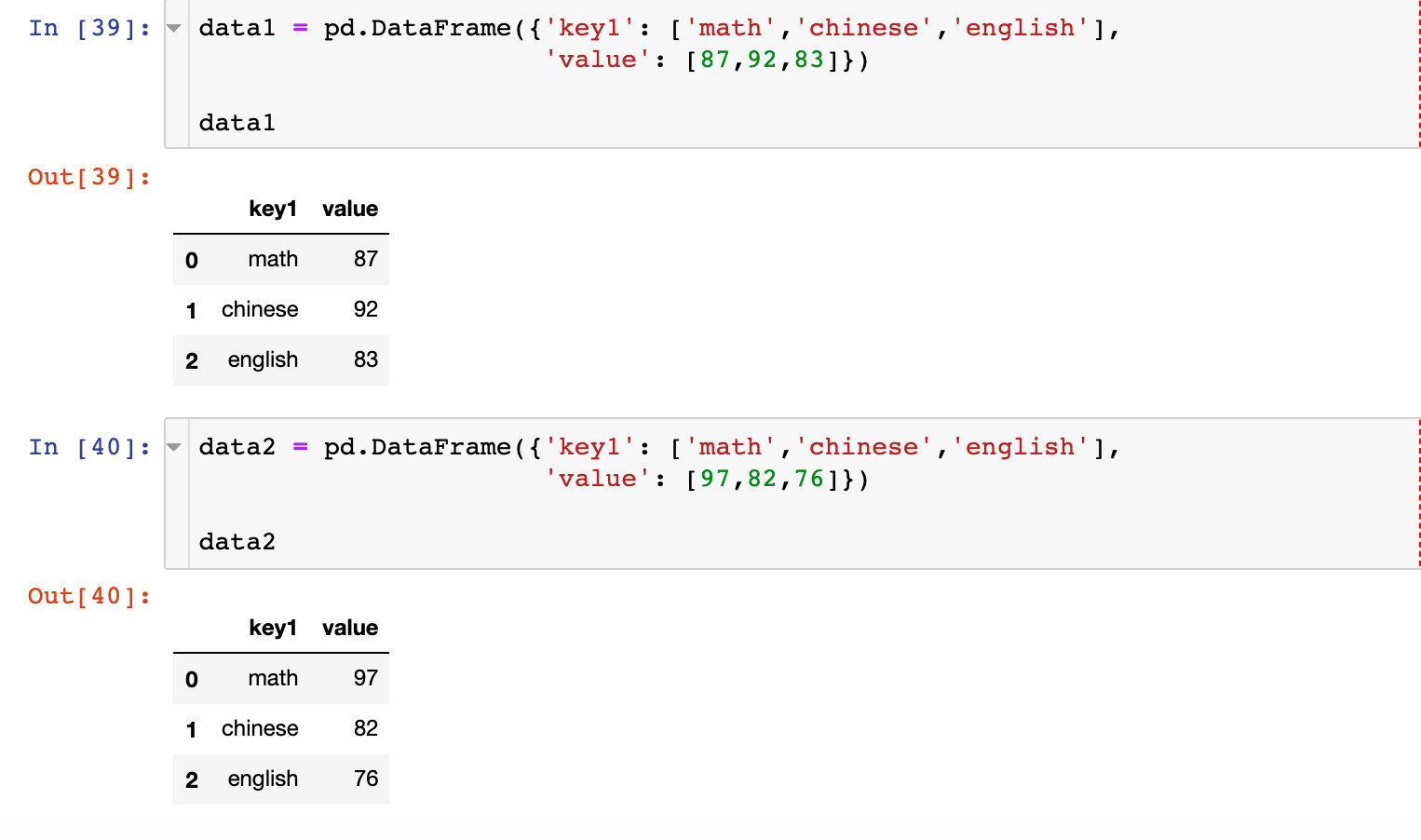
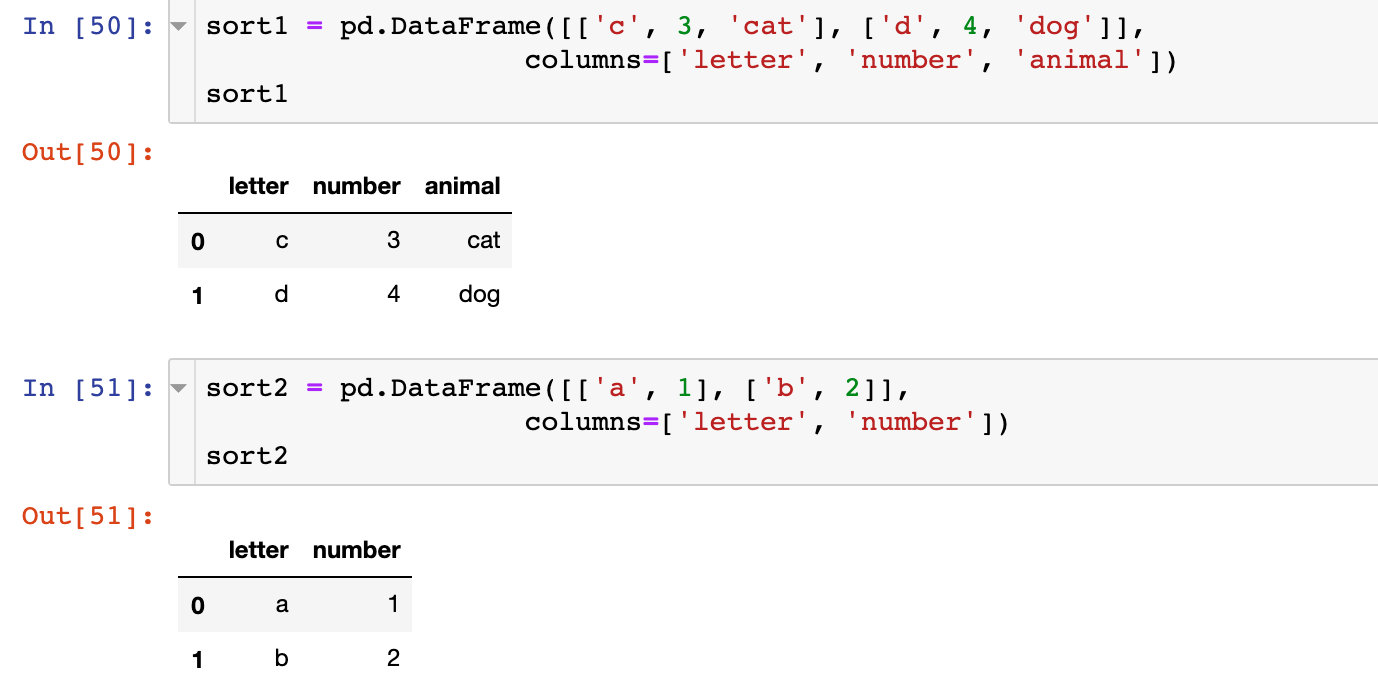
模拟数据
注意4组数据的不同


使用默认参数
两种不同的写法,效果相同

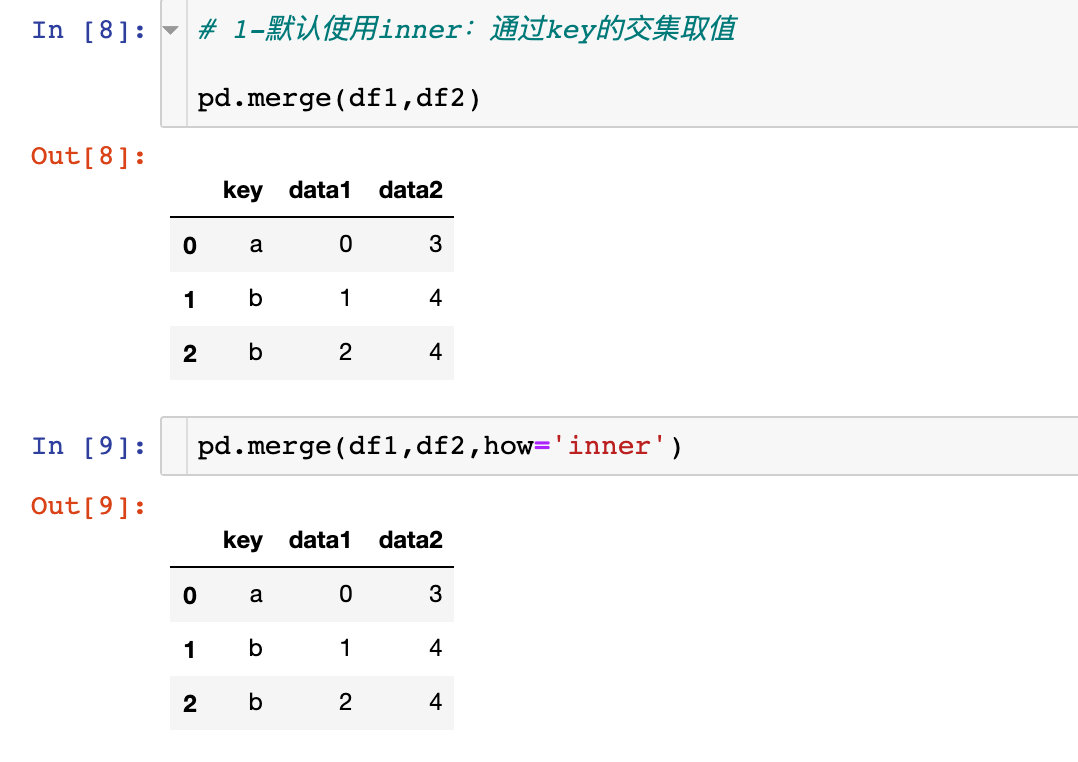
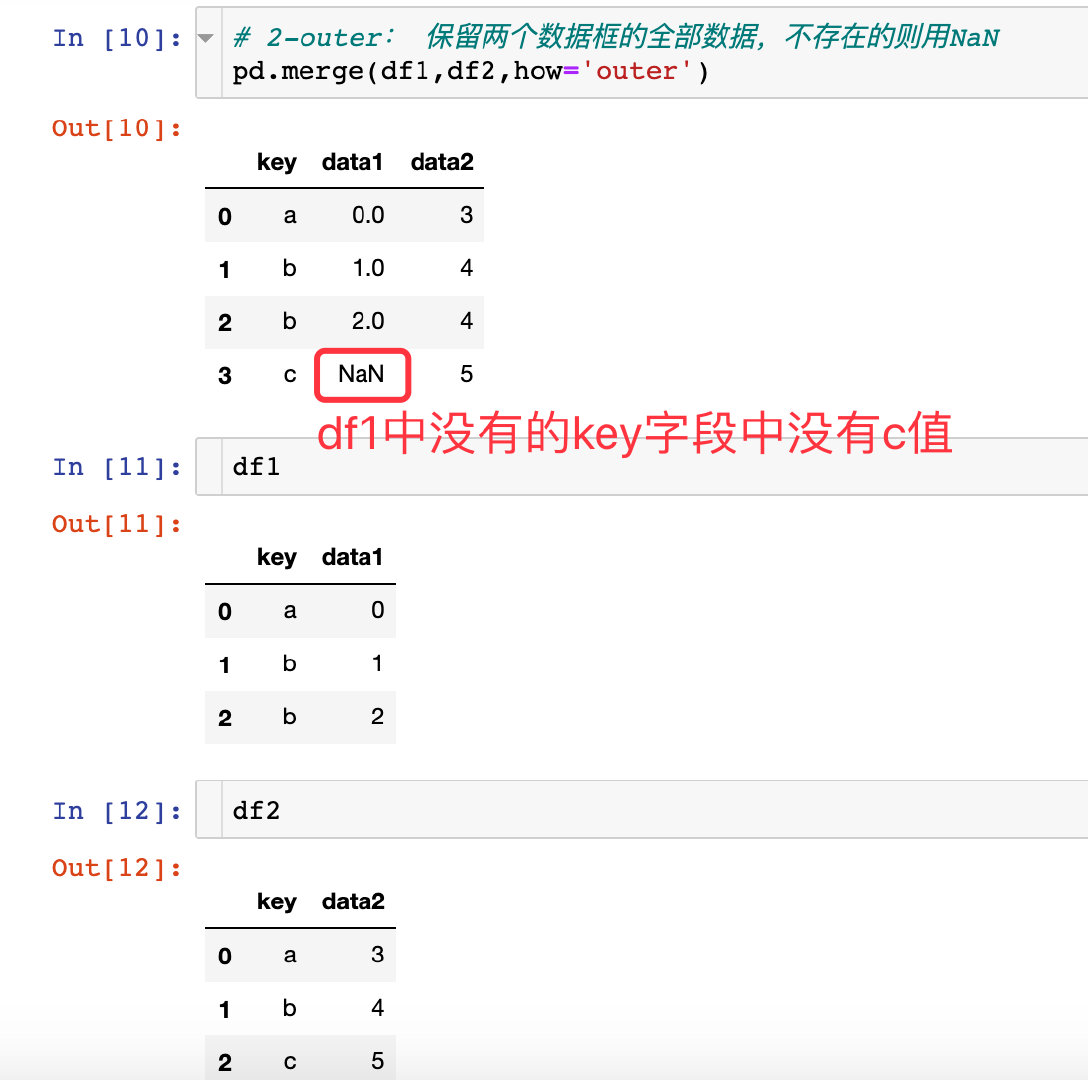
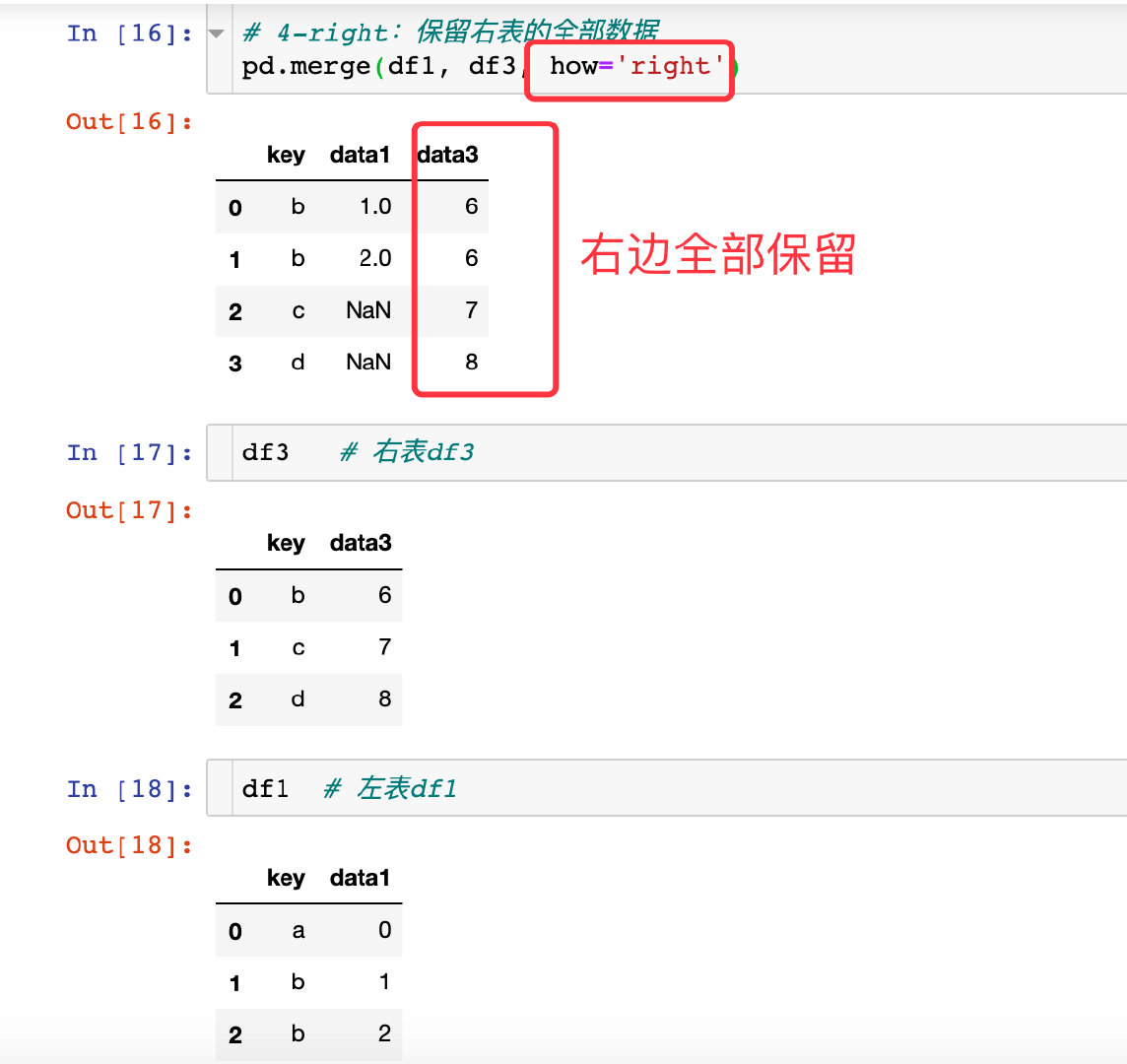
参数how
how参数的取值有4种:
- inner(默认)
- outer
- right
- left

参数on
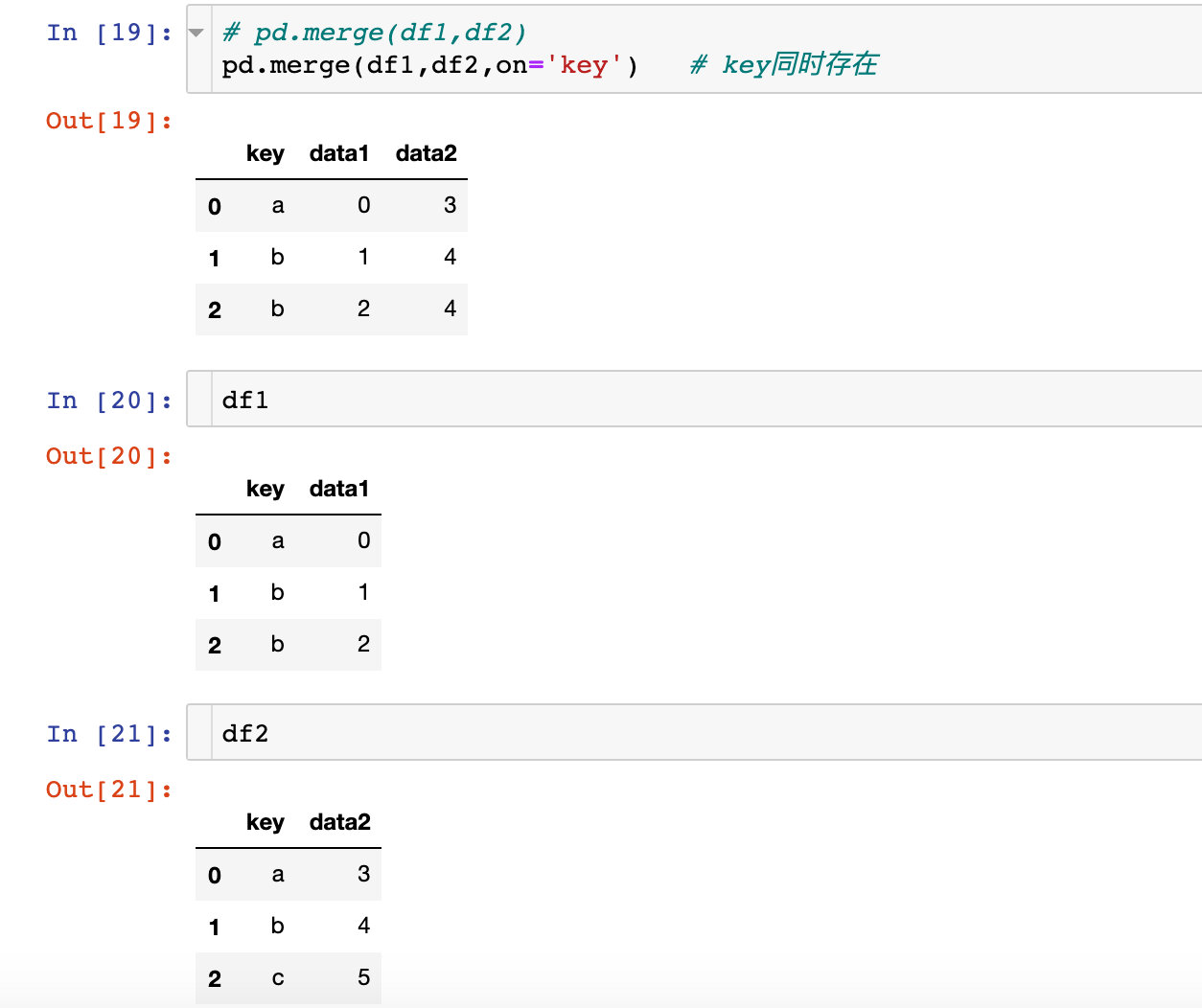
用于连接的列索引列名,必须同时存在于左右的两个dataframe型数据中,类似SQL中两个表的相同字段属性
如果没有指定或者其他参数也没有指定,则以两个dataframe型数据的相同键作为连接键
on参数为单个字段
另一个例子:


on参数为多个字段-列表形式


参数left_on/right_on
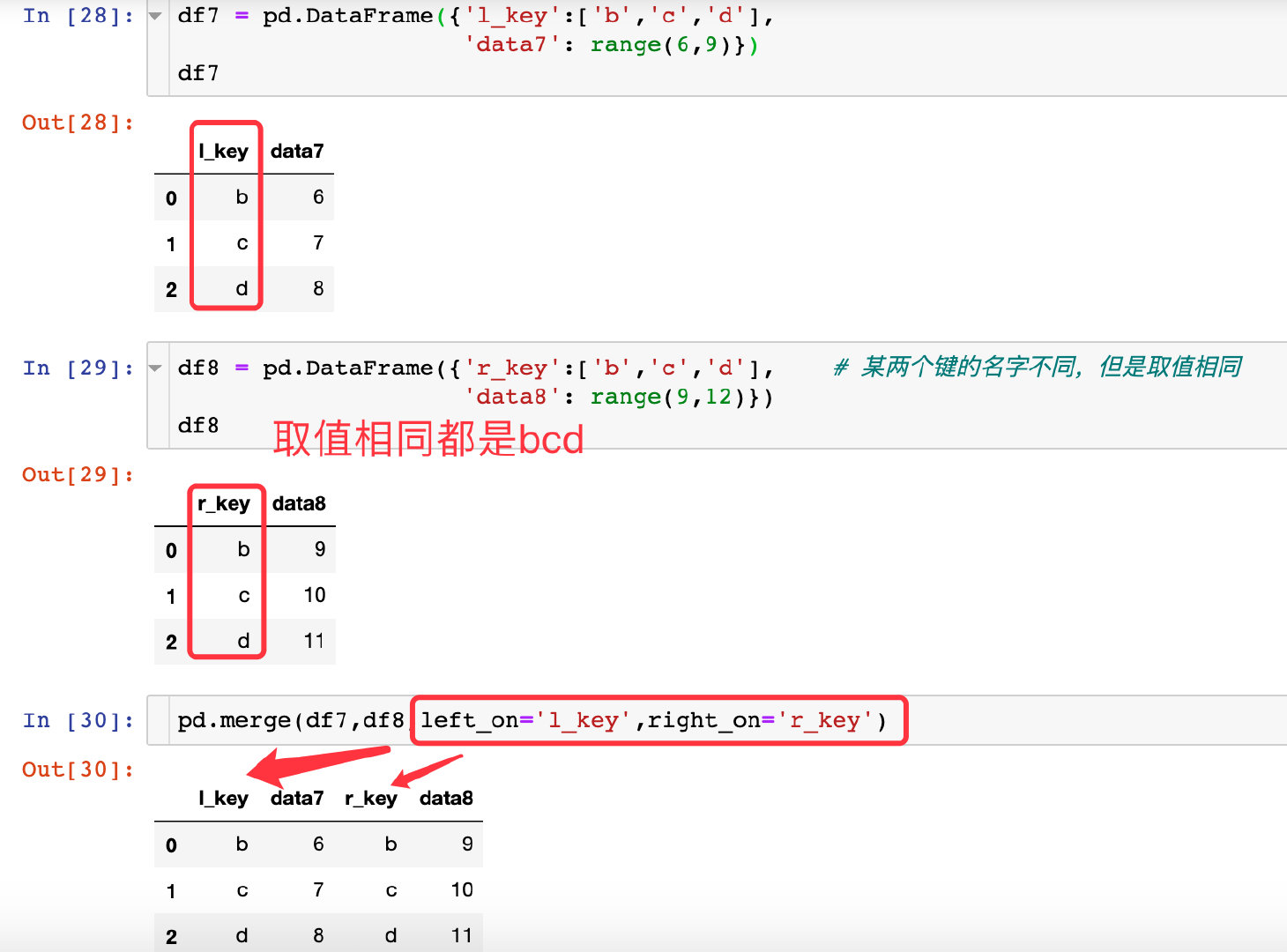
参数suffixes
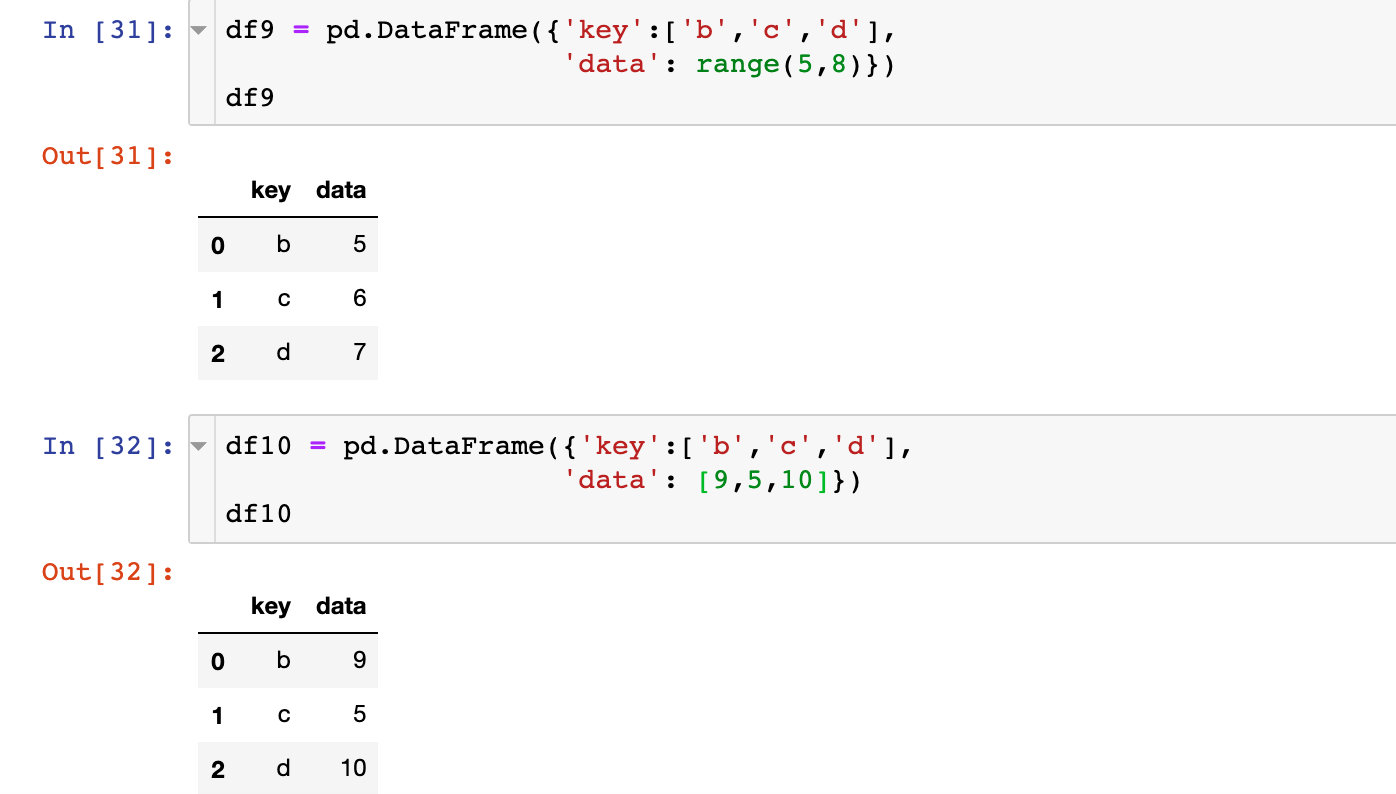
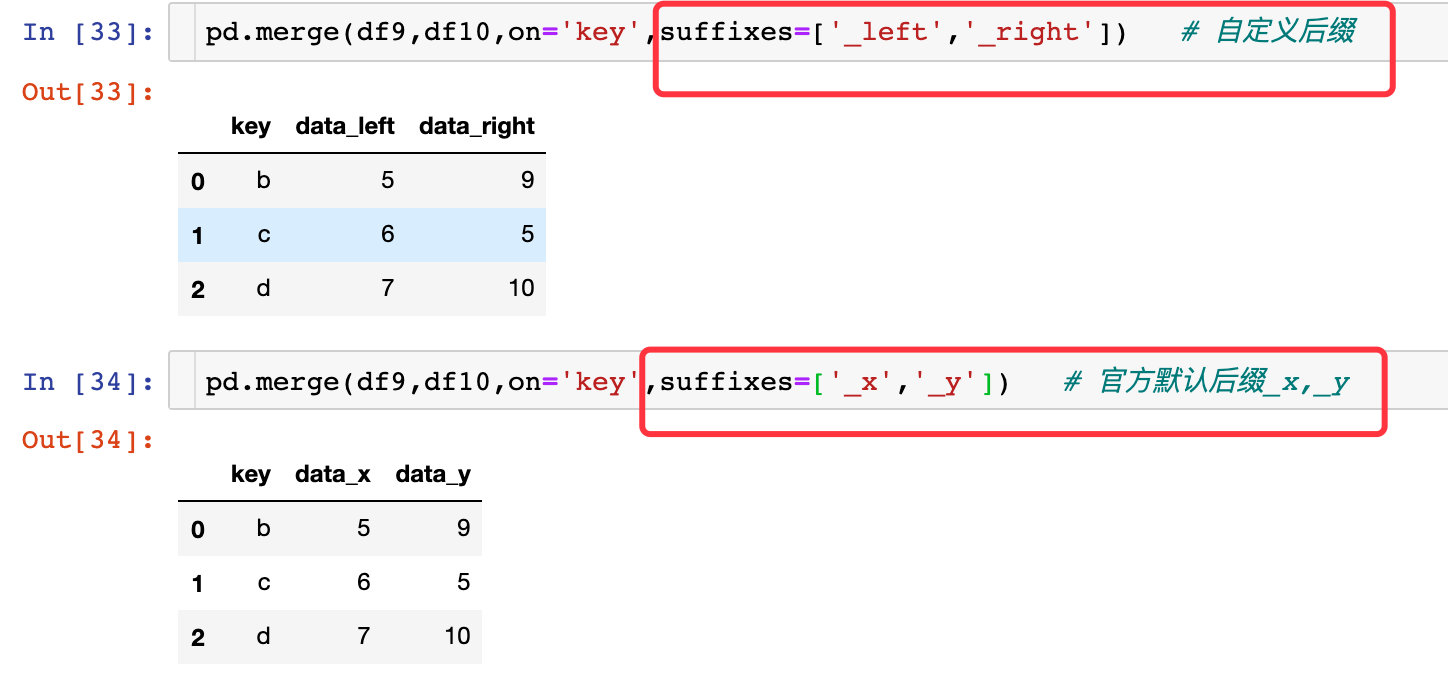
合并的时候一列两个表同名,但是取值不同,如果都想要保存下来,就使用加后缀的方法,默认是_x,_y,可以自己指定
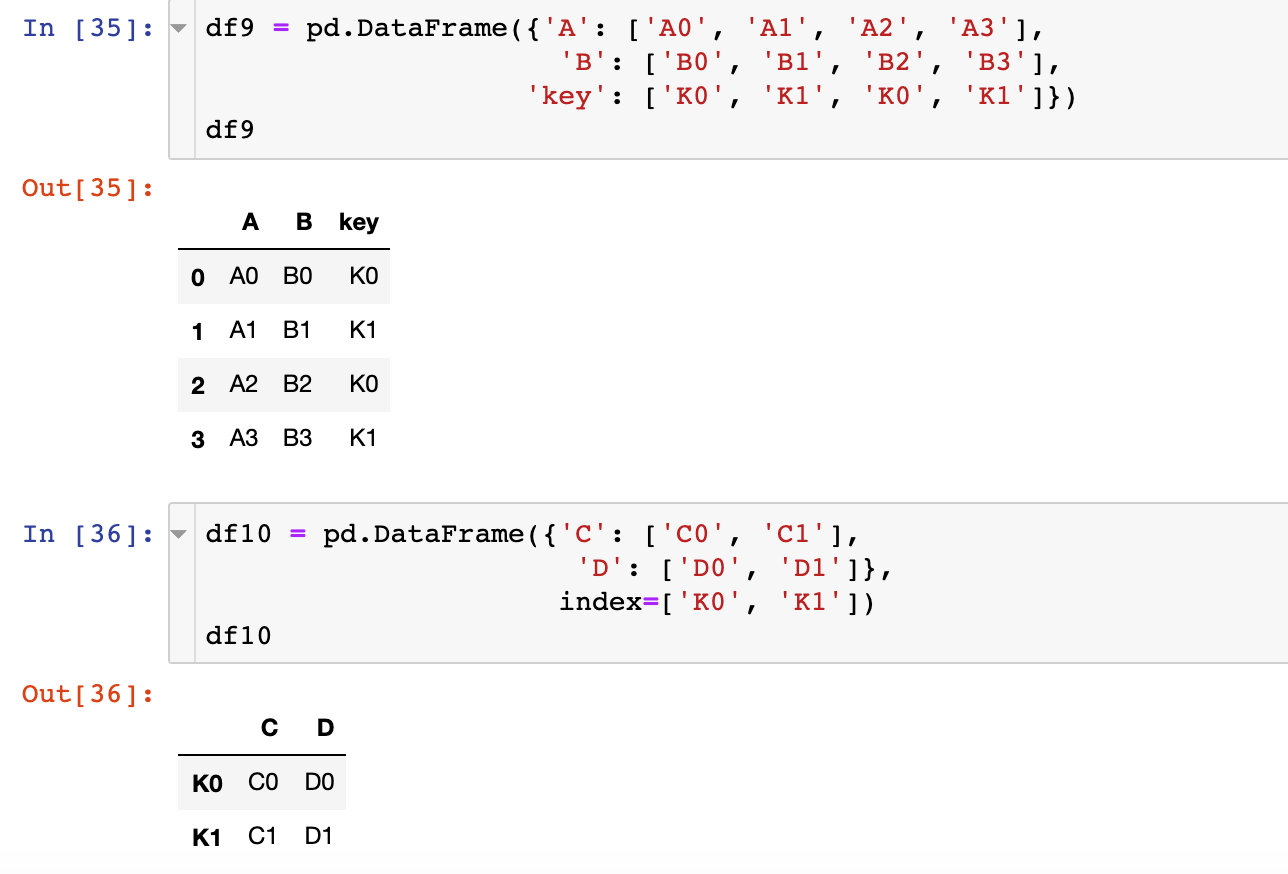
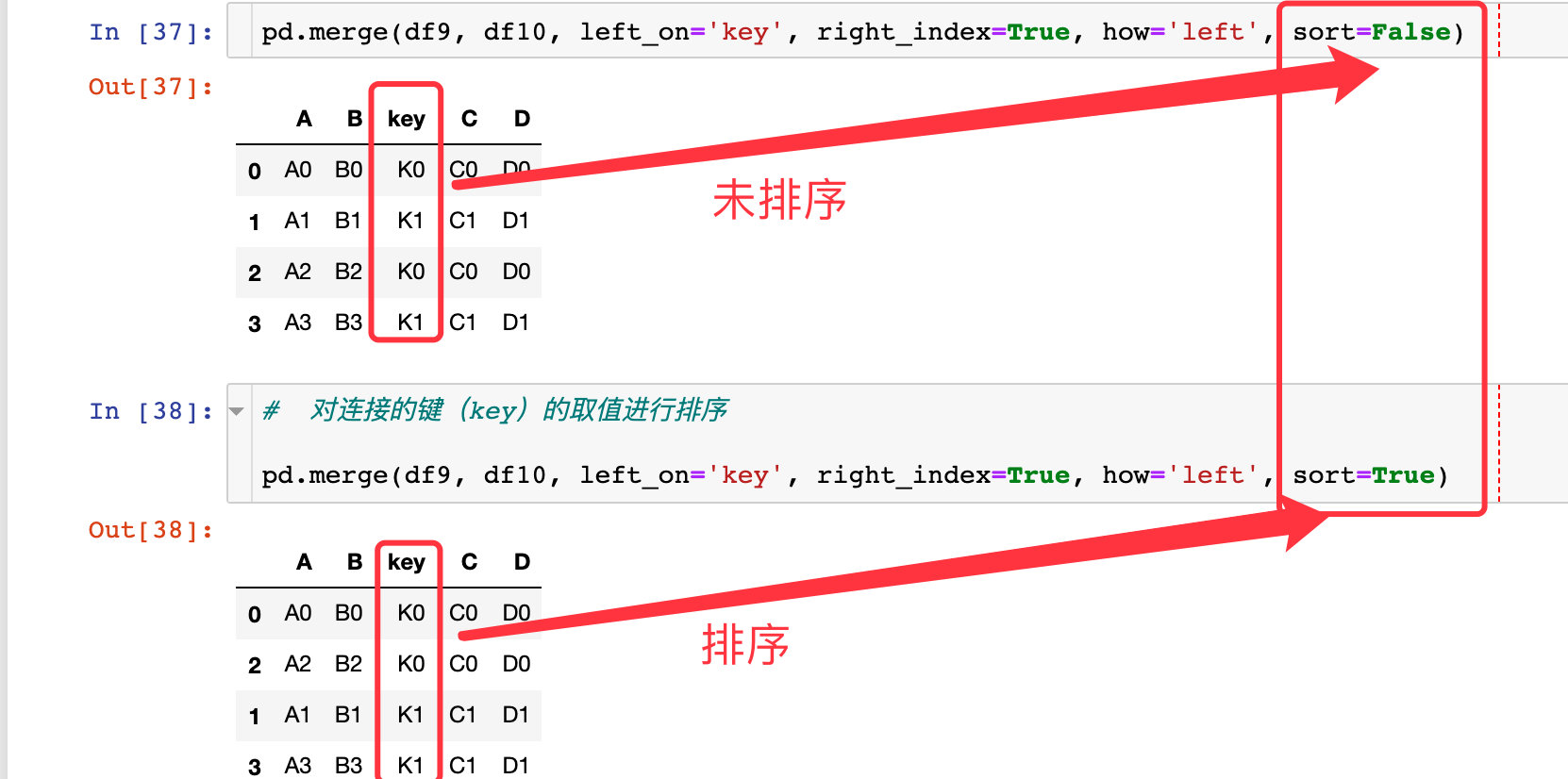
参数sort
对连接的时候相同键的取值进行排序
concat
官方参数
concat方法是将两个DataFrame数据框中的数据进行合并
- 通过axis参数指定是在行还是列方向上合并
- 参数
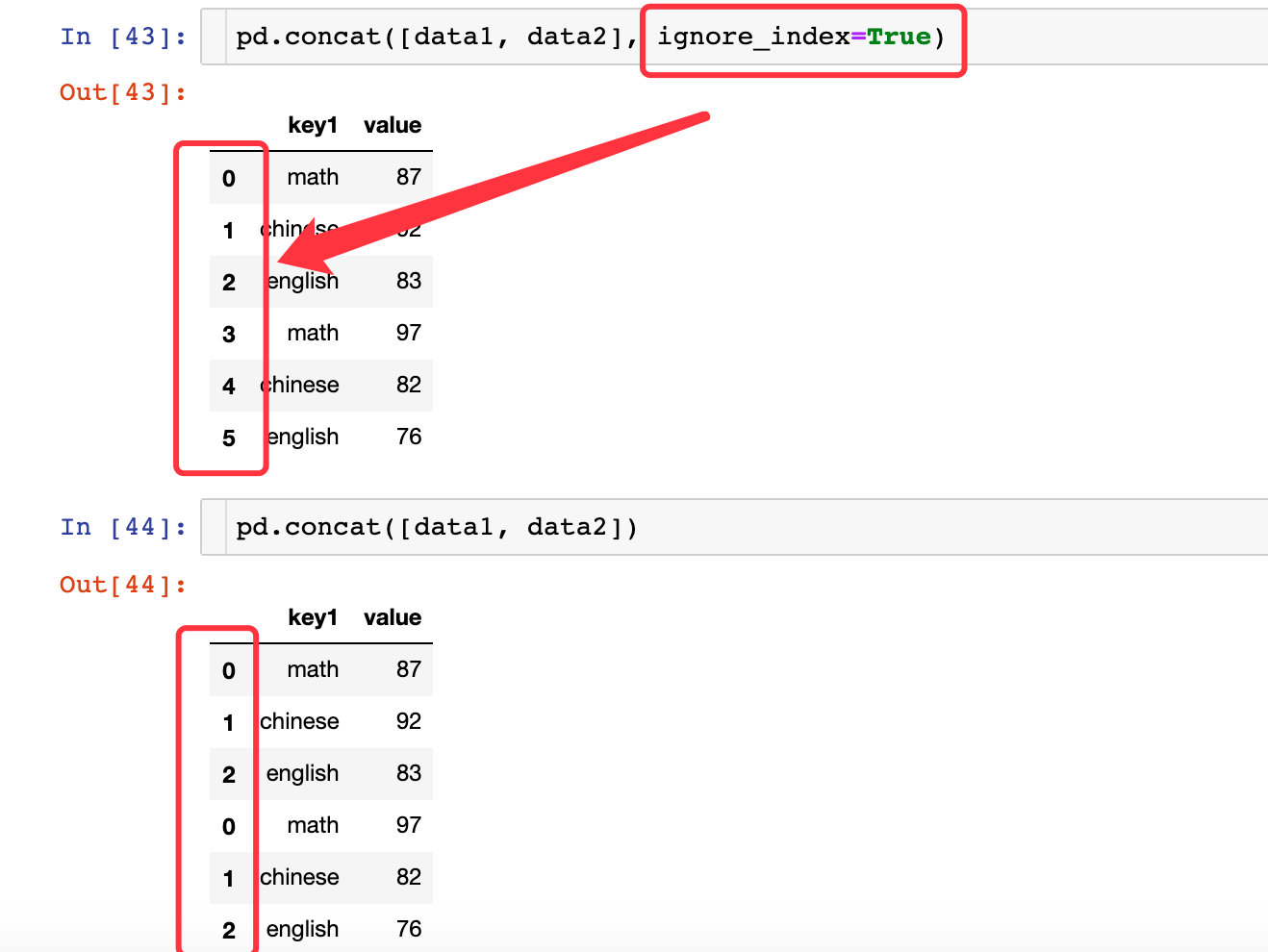
ignore_index实现合并后的索引重排

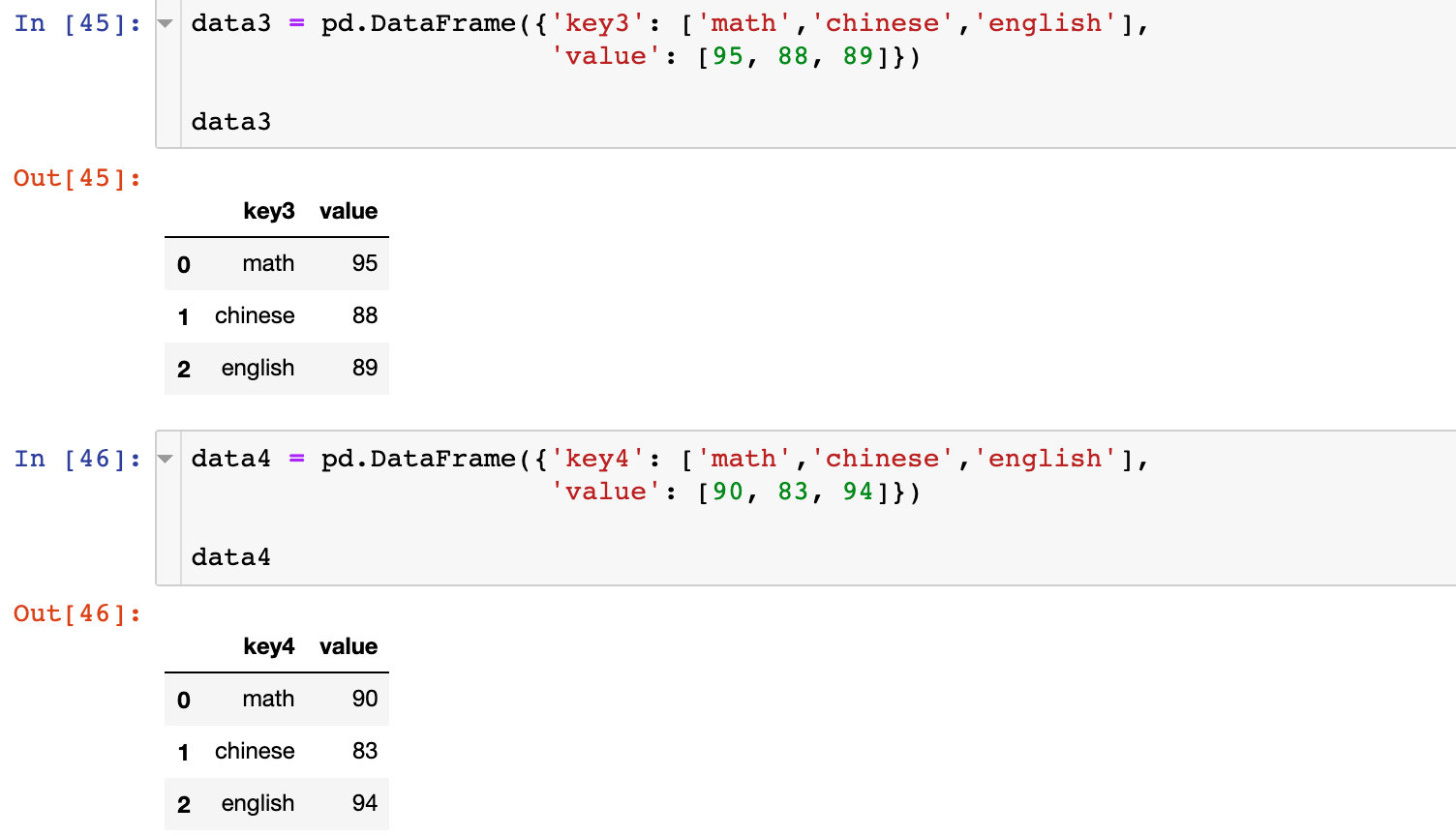
生成数据
指定合并轴

改变索引
join参数
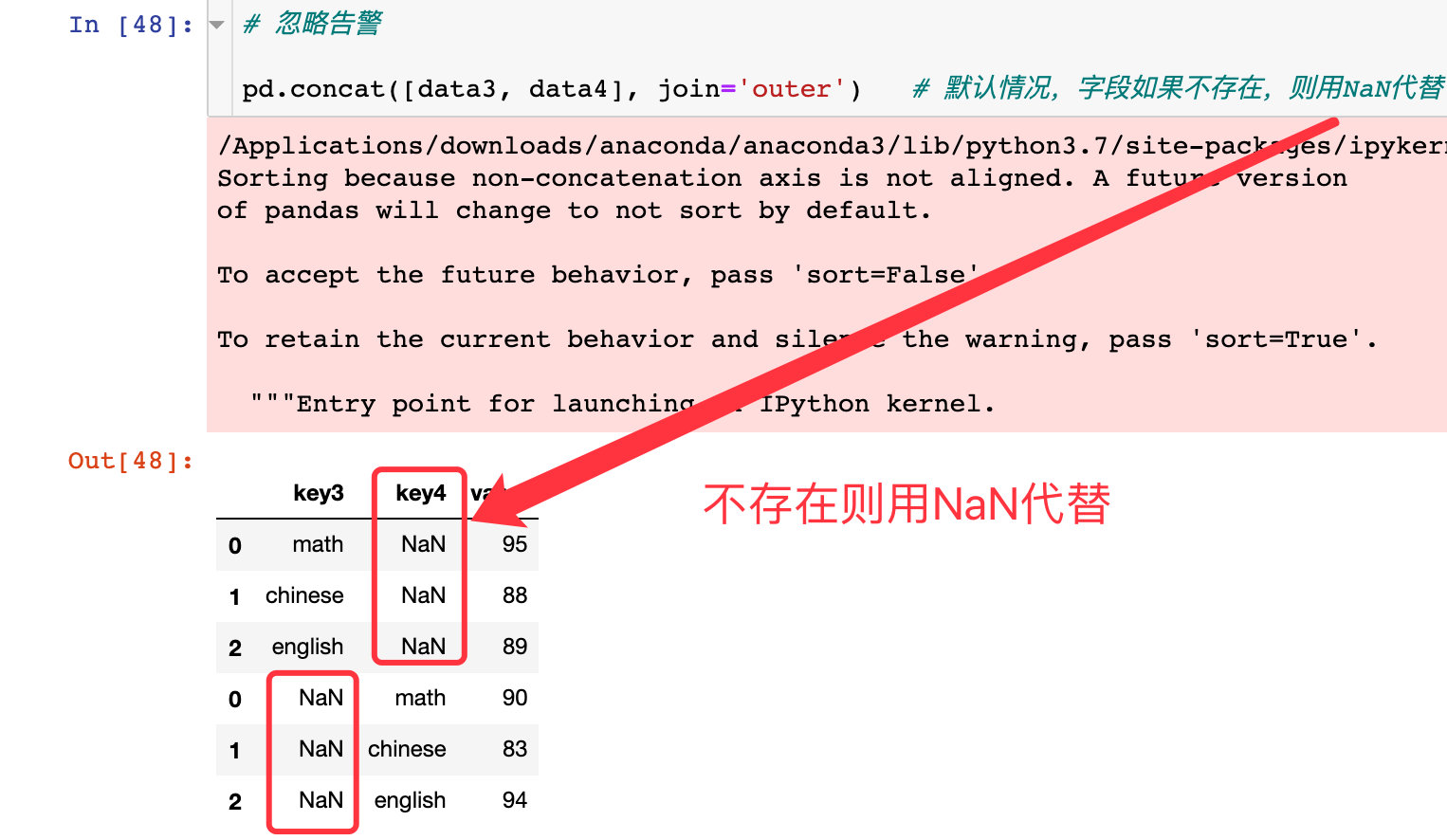
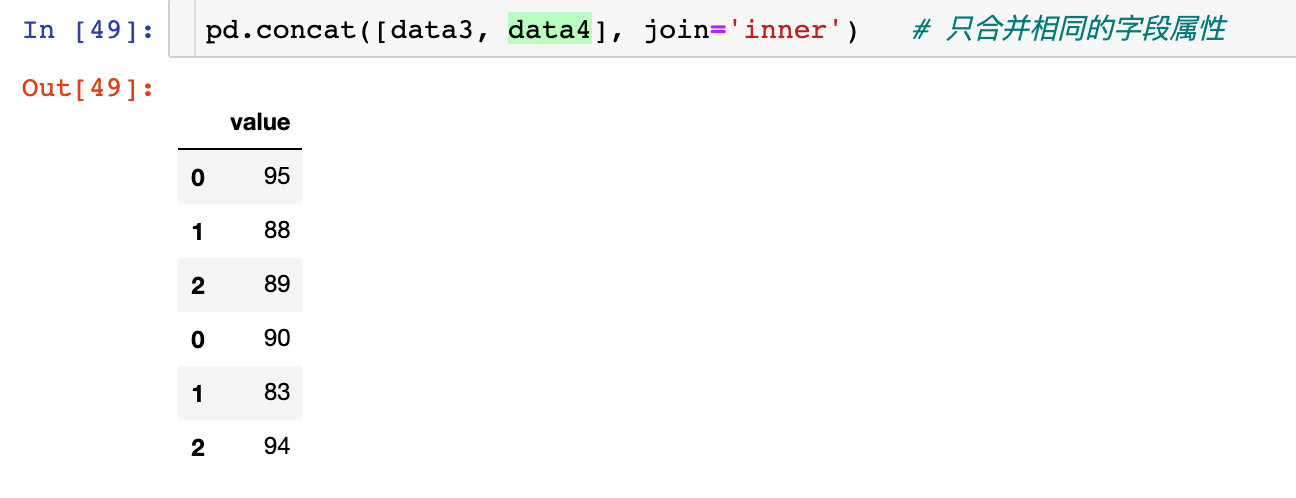
sort-属性排序
append
官方参数

基本使用
data3.append(data4) # 等同于pd.append([data3, data4]) 忽略pandas版本的警告
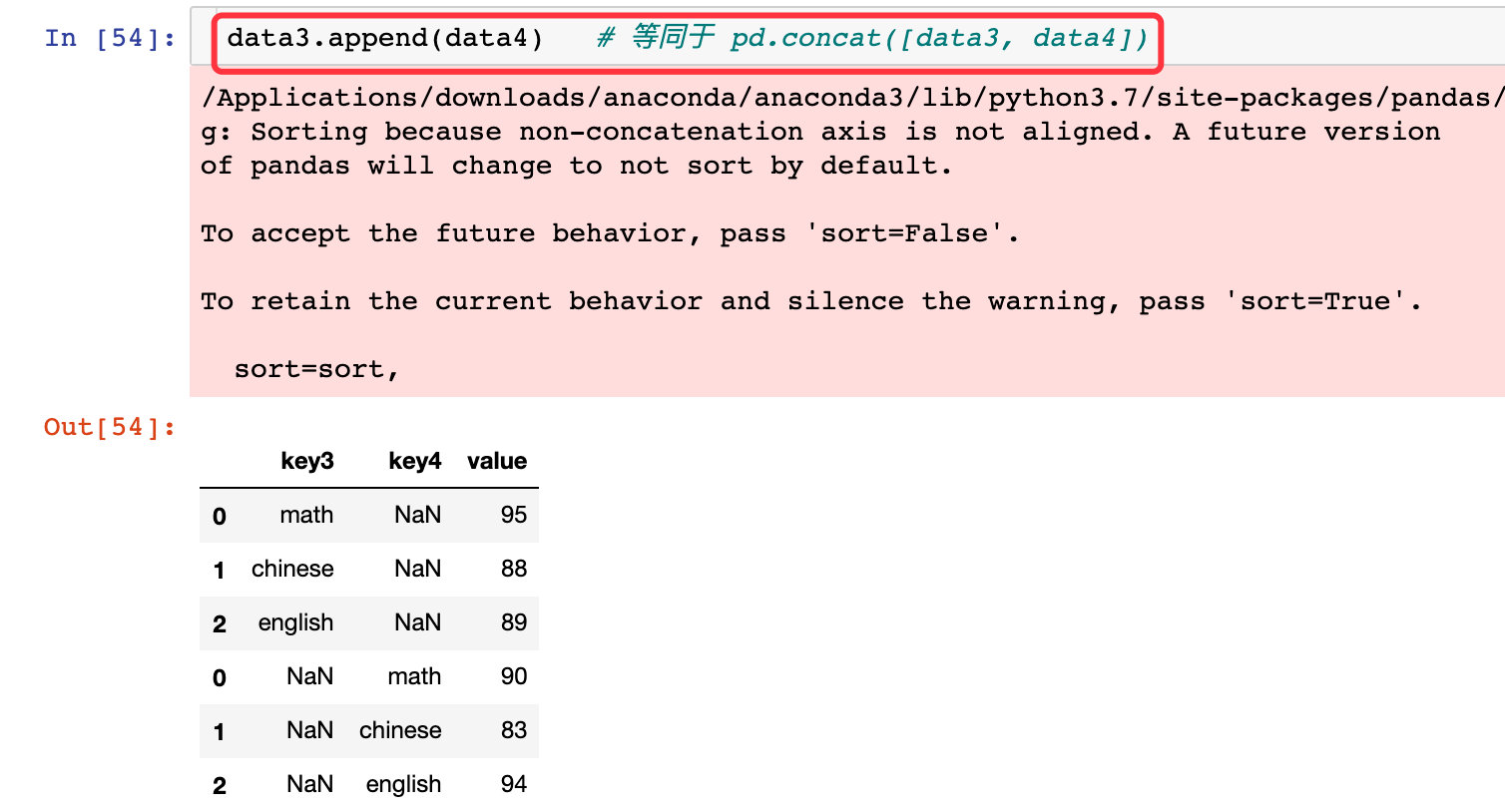
改变索引-自然数排序
data3.append(data4, ignore_index=True) # 设置参数
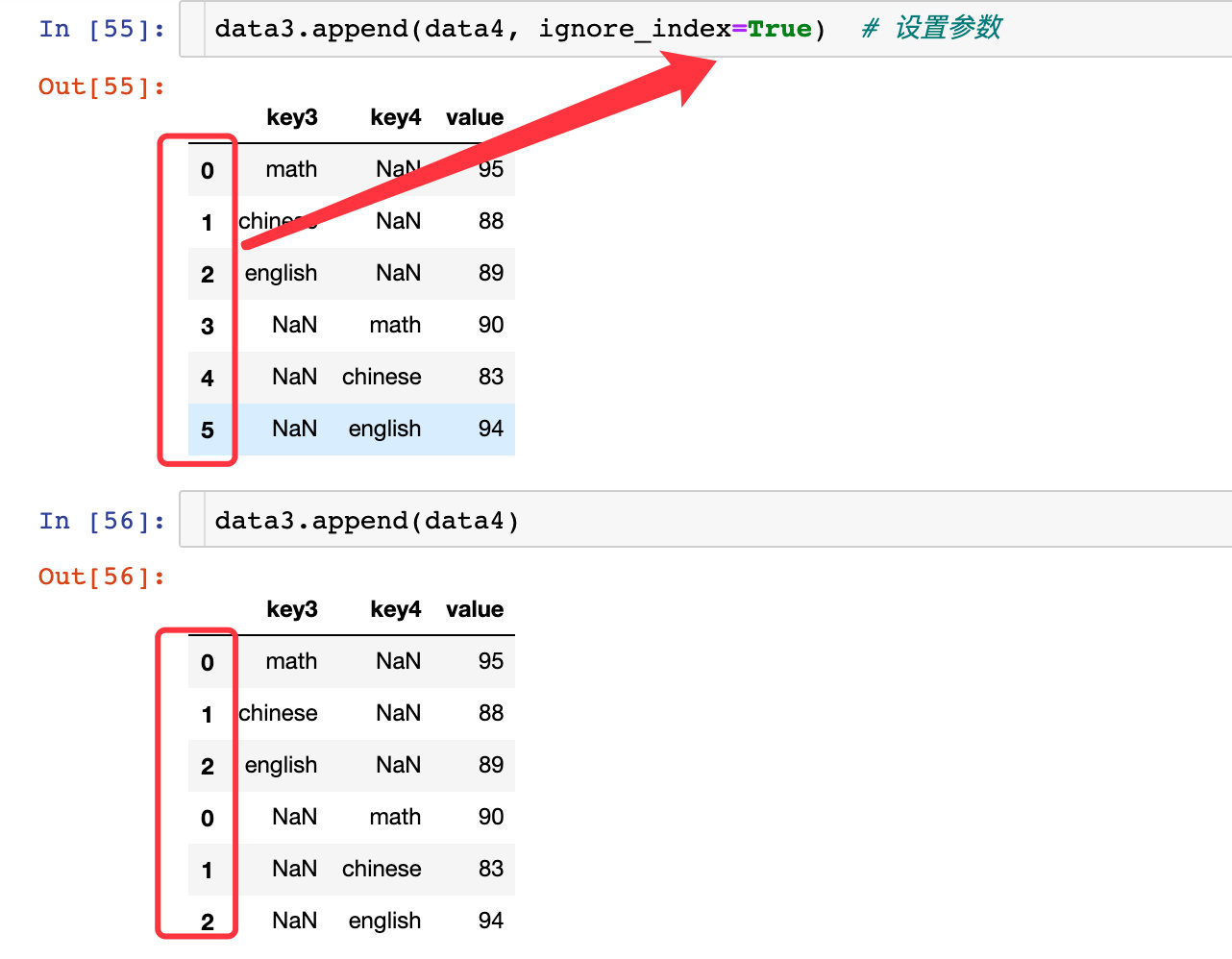
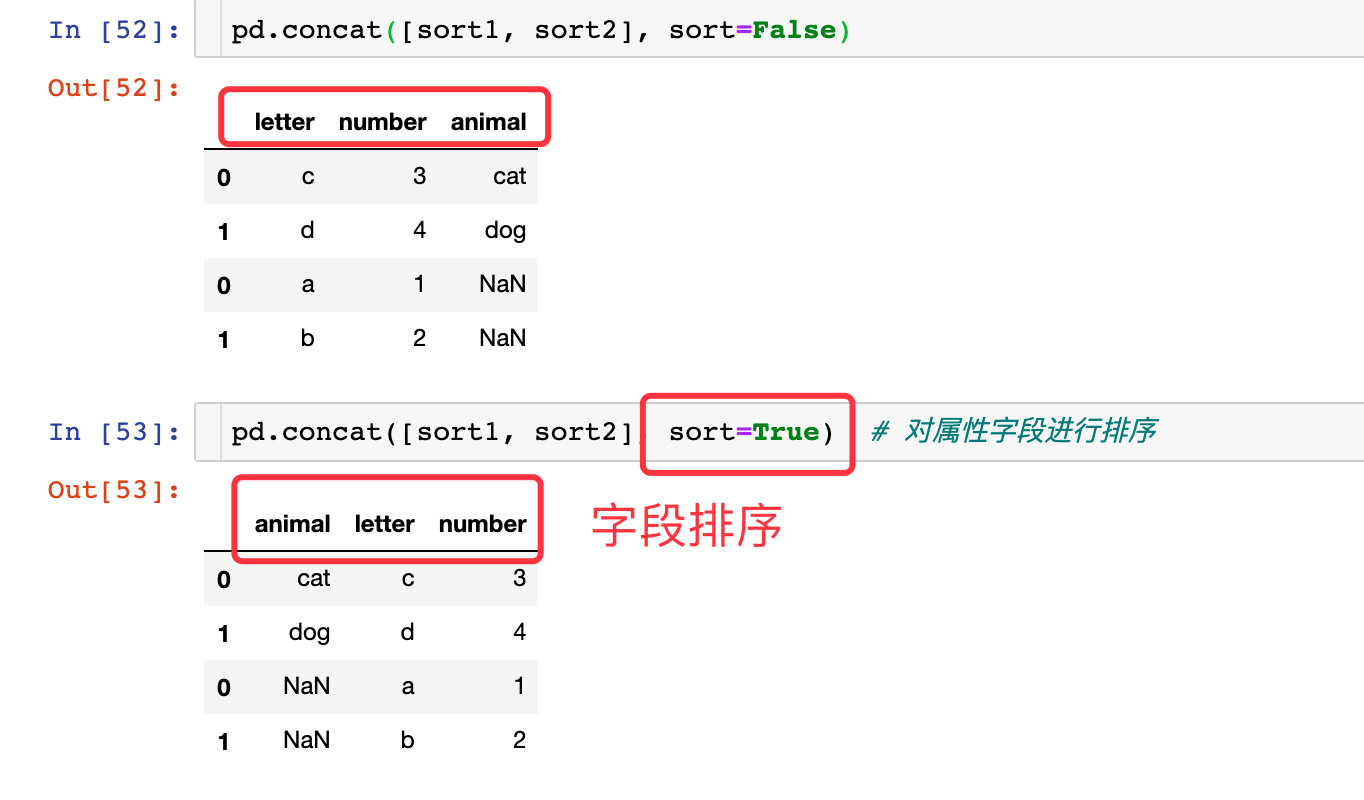
sort=True-属性的排序
data3.append(data4) # 默认对字段属性排序

join
官方参数

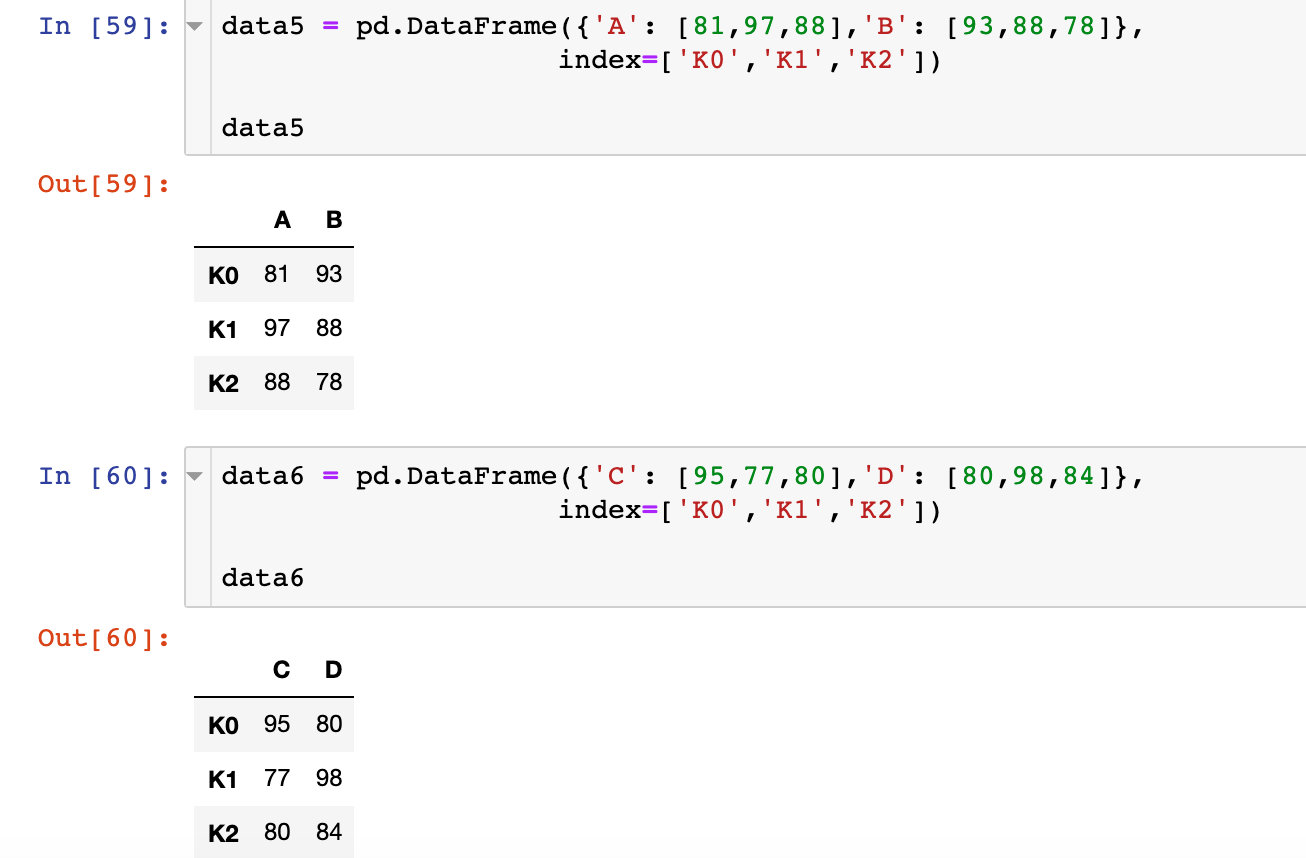
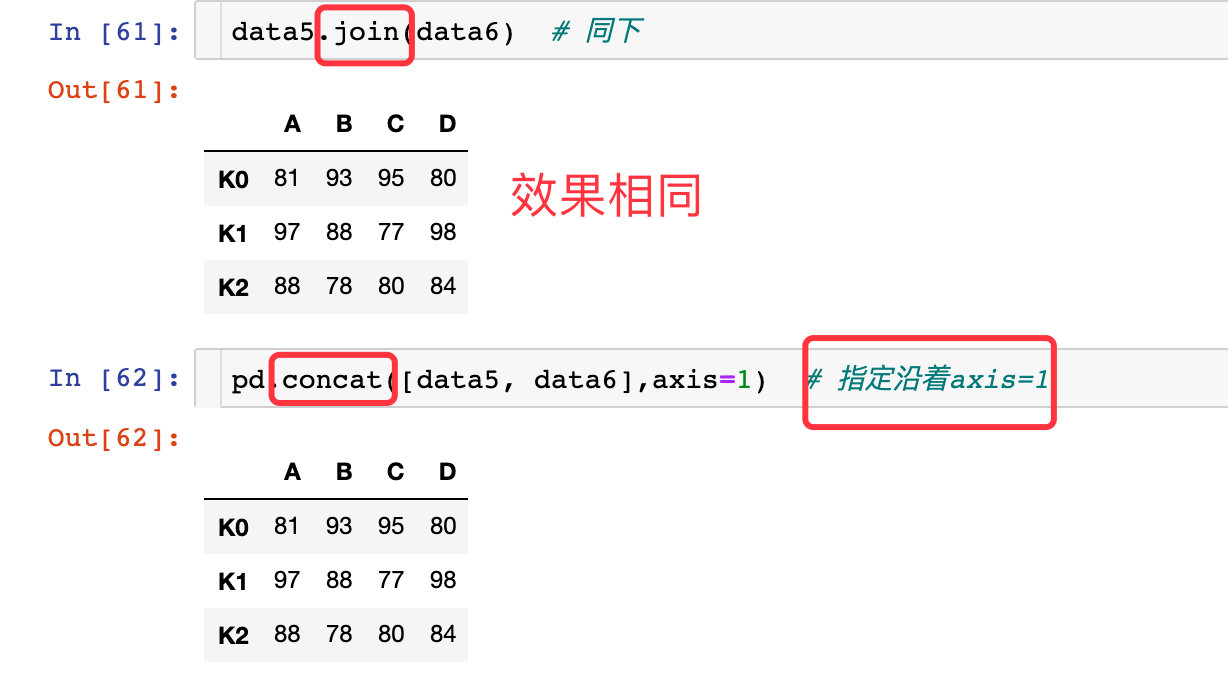
通过相同索引合并
相同字段属性指后缀
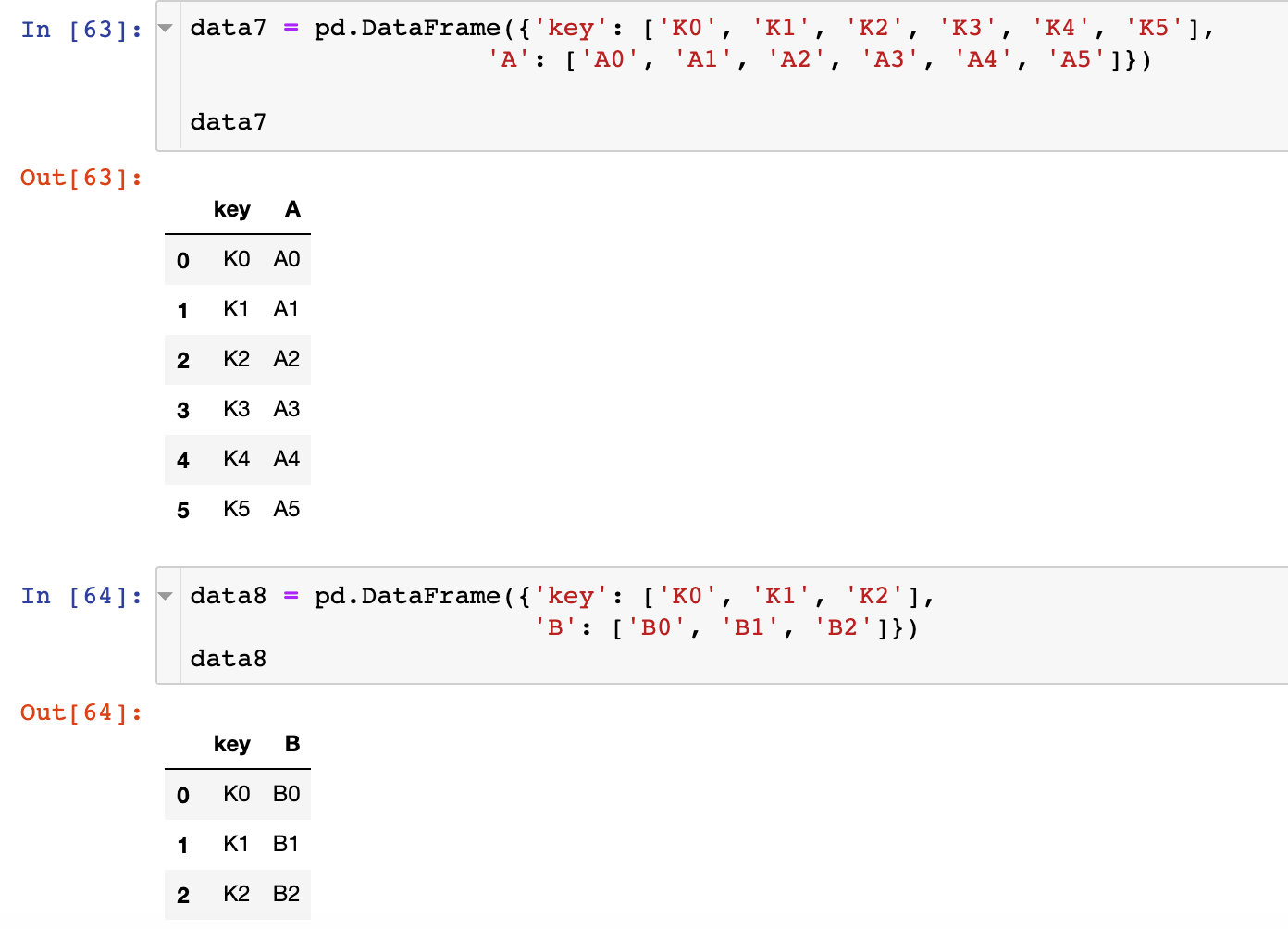

相同字段变成索引index
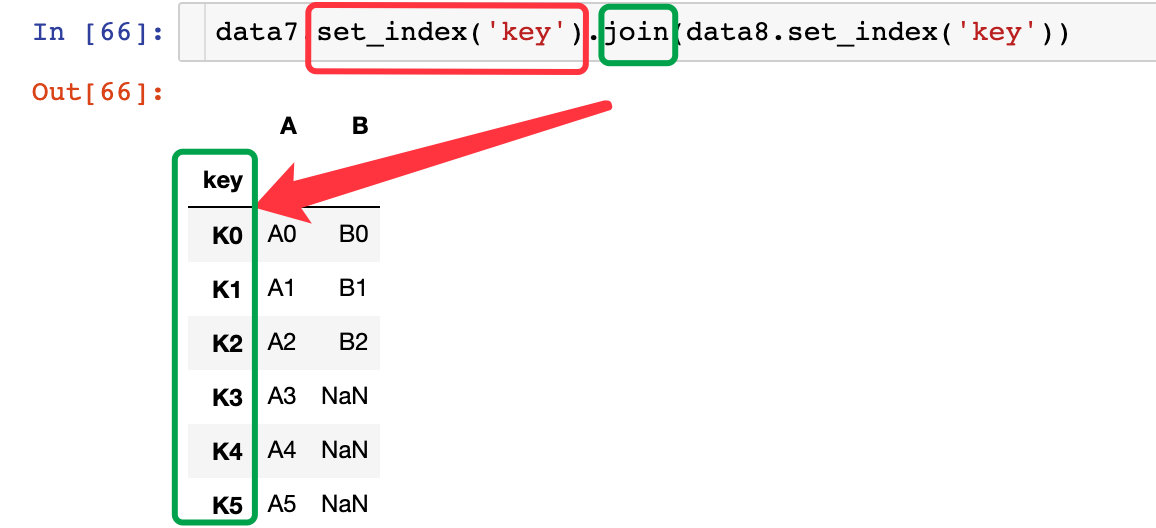
相同字段保留一次
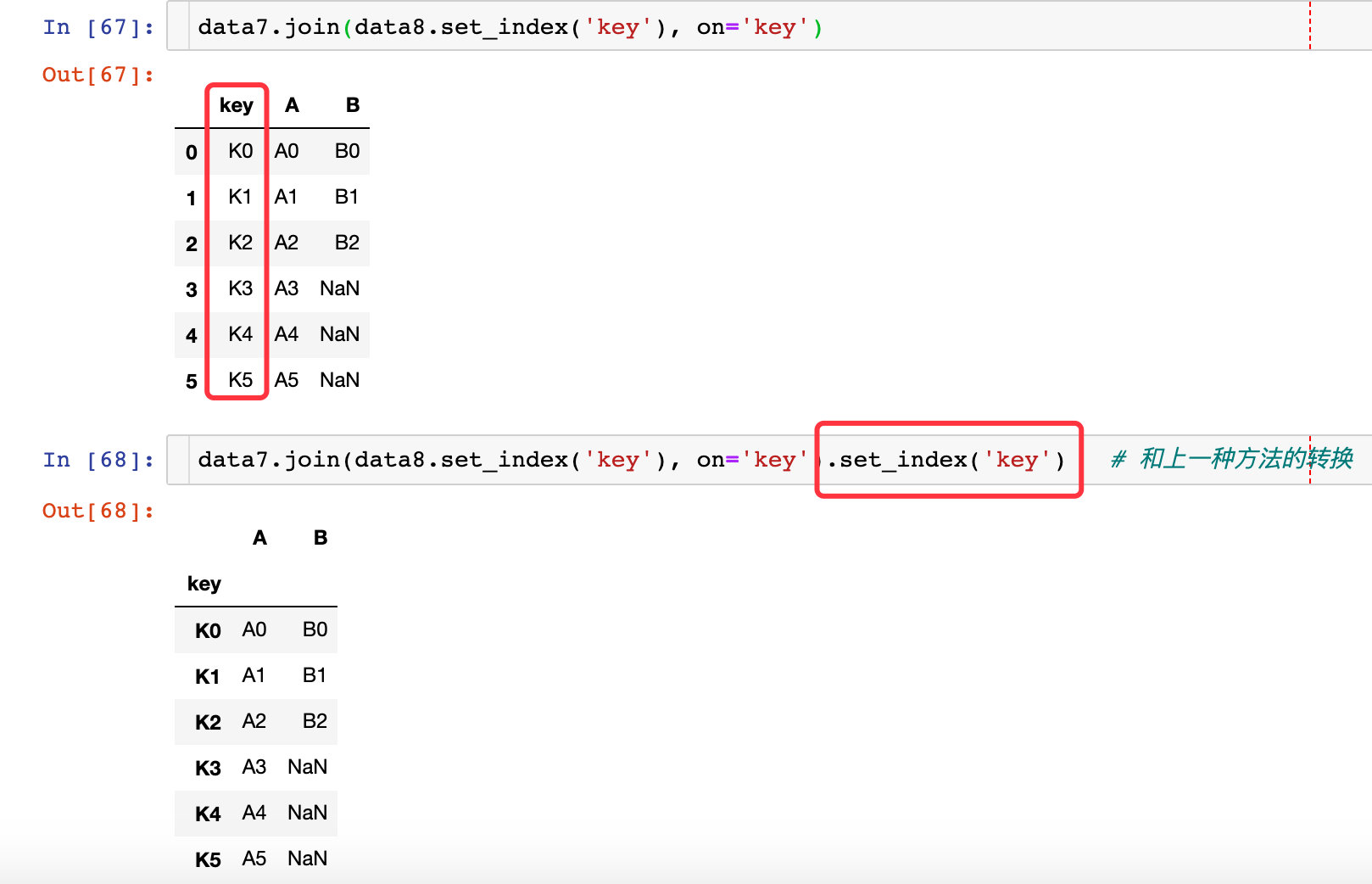
一切看似逝去的,都不曾离开,你所给与的爱与温暖,让我执着地守护着这里。
尤而小屋,一个温馨的小屋。小屋主人,一手代码谋求生存,一手掌勺享受生活,欢迎你的光临😃
















 8171
8171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









