





 本文介绍了针对极其脏的非结构化文本进行清理的创新解决方案,探讨了在自然语言处理(NLP)中如何有效地进行文本预处理,包括使用Python和Java等工具进行数据清洗,并在Linux环境下操作。
本文介绍了针对极其脏的非结构化文本进行清理的创新解决方案,探讨了在自然语言处理(NLP)中如何有效地进行文本预处理,包括使用Python和Java等工具进行数据清洗,并在Linux环境下操作。
自然文本语言处理文本清理
After two whole weeks of trial and error and almost thinking it was impossible…
经过两周的反复试验,几乎认为这是不可能的……
I did it.
我做的。
I’d managed to turn this:
我设法把这个:
“Thsi wass a dificult prbl em to resol ve”
“这是一个难以解决的难题”
Into this:
变成这个:
“This was a difficult problem to resolve”
“这是一个很难解决的问题”
I thought I’d seen it all after working with the likes of Singlish or even Tweets.
我以为与Singlish甚至Tweets之类的东西一起工作后,我已经看完了 。
But never would I have thought I’d come across unstructured text data so dirty.
但是我从来没有想过会遇到如此脏的非结构化文本数据。
I’ve obviously exaggerated the example above but the problem boils down to these two key points:
我显然夸大了上面的示例,但是问题归结为以下两个关键点:
- Misspelling detection and resolution 拼写错误检测和解决
- Handling random white spaces in-between words 处理单词之间的随机空白
As humans, we can easily decipher the statement above as:
作为人类,我们可以轻松地将以上陈述解读为:
“This was a difficult problem to resolve”
“这是一个很难解决的问题”
However, coming up with a methodology to resolve such a data issue proved more challenging than anticipated.
但是,提出解决这种数据问题的方法比预期的更具挑战性。
In this post, I will be going through a novel solution I took to clean up an extremely dirty unstructured text dataset.
在本文中,我将介绍一种新颖的解决方案,用于清理极其脏的非结构化文本数据集。
Here’s a glimpse of how the data looked like:
这是数据的样子:

Note: This is just an example of how the dirty data looked like and not the actual data.
注意:这只是脏数据看起来而不是实际数据的示例。
There won’t be much code snippets today but by the end of the post, you will get an idea of the methodology involved to resolve such a data issue if you ever come across it.
今天不会有太多的代码片段,但是到发布最后,您将了解解决此类数据问题所涉及的方法。
数据质量问题1:拼写错误检测和解决 (Data Quality Issue 1: Misspelling Detection and Resolution)
In one of my previous posts on handling misspellings, I used word vectors and did a lot of translations to form a generalised translation vector to handle misspellings.
在我以前有关处理拼写错误的文章中,我使用了词向量,并做了很多翻译,形成了一个通用的翻译矢量来处理拼写错误。
In this post, I will be falling back on an algorithmic approach to handling misspellings.
在本文中,我将依靠一种算法来处理拼写错误。
There are two parts to this segment:
此部分分为两部分:
- Detect misspelled words 检测拼写错误的单词
- Resolve misspelled words 解决拼写错误的单词
I used SAS Viya’s out of the box misspelling action called tpSpell to do this.
我使用了名为tpSpell的 SAS Viya开箱即用的拼写错误操作来执行此操作。
Note: SAS works with something called Actionsets which are synonymous to Python Packages. Within each Actionset, there are many Actions that can be performed.
注意:SAS与称为Actionset的东西一起使用, Actionsets与Python包同义。 在每个动作集中,可以执行许多动作 。
第1部分:检测拼写错误的单词 (Part 1: Detect Misspelled words)
In this step, the tpSpell action performs what it is known as Candidate Extraction.
在此步骤中,tpSpell操作执行了所谓的候选提取。
Candidate Extraction groups words into two categories:
候选词提取将单词分为两类:
- Correctly-spelled word candidates 拼写正确的单词候选
- Misspelled word candidates 拼写错误的单词候选
A correctly-spelled word candidate is determined by a predetermined parameter (“minimum parents”) before running the procedure.
在运行该程序之前,将通过预定参数(“最小父母”)确定拼写正确的单词候选字。
This parameter specifies the minimum number of documents a term must appear in to be considered a correctly-spelled word candidate.
此参数指定一个词必须被视为正确拼写的候选单词的最少文档数。
All correctly-spelled word candidate takes the form <term>-<role>-<parent> .
所有正确拼写的单词候选词均采用<term>-<role>-<parent> 。
For example, refer to figure 1 below:
例如,请参考下面的图1:
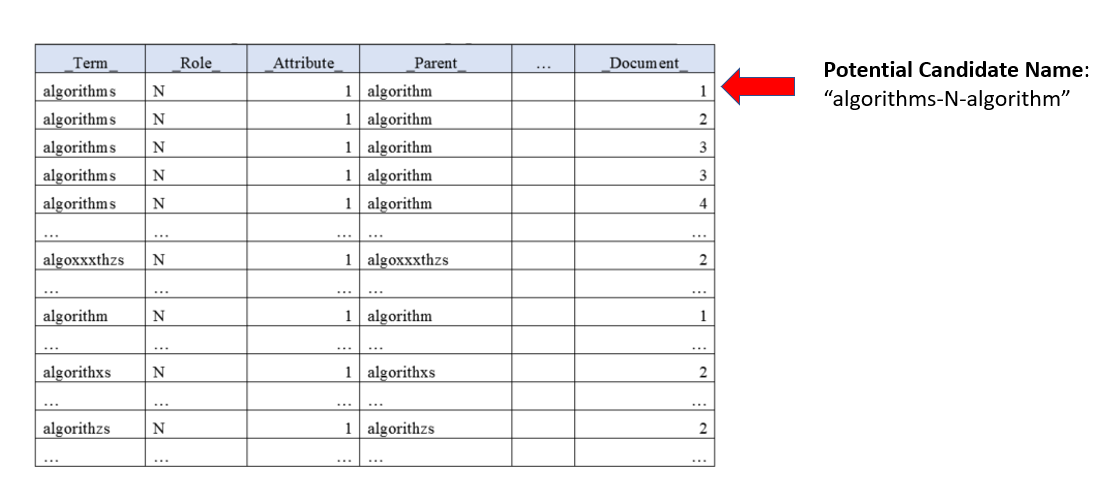
Notice how the potential candidate name is a concatenation of the columns “Term”, “Role” and “Parent” to form “algorithms-N-algorithm”.
请注意,潜在的候选名称是如何将“术语”,“角色”和“父母”列串联在一起形成“ algorithms-N-algorithm”。
Here’s the breakdown of the logic.
这是逻辑的细分。
If the potential candidate name, “algorithms-N-algorithm”, appears 5 times in 4 documents, then the number of documents it appeared in equals to 4.
如果潜在的候选名称“ algorithms-N-algorithm”在4个文档中出现了5次,则 出现的文件数等于4。
- If the predetermined parameter called “minimum parents” is set to 3, since 4 is more 3, the word “algorithms-N-algorithm” is added into a correctly-spelled candidate list. 如果将称为“最小父母”的预定参数设置为3,则由于4等于3,因此将单词“ algorithms-N-algorithm”添加到拼写正确的候选列表中。
Now, what about the misspelled word candidates list? How then do we create this table?
现在,拼写错误的单词候选列表呢? 那我们如何创建这个表呢?
Just like the correctly-spelled word candidate list, there is another predetermined parameter to set.
就像拼写正确的候选单词列表一样,还有另一个要设置的预定参数。
This time, it is called “maximum children”.
这一次,它被称为“最大的孩子”。
Take a look a figure 2 below for instance:
例如,看下面的图2:

The logic is simple.
逻辑很简单。
If the “maximum children” parameter is set to 3 and the number of documents a potential candidate name like “algoxxxthzs-N-algoxxxthzs” appears in is less than 3, then “algoxxxthzs-N-algoxxxthzs” is added into the misspelled word candidate list.
如果将“最大孩子数”参数设置为3, 并且可能出现的候选名称(如“ algoxxxthzs-N-algoxxxthzs”)的文档数少于3,则将“ algoxxxthzs-N-algoxxxthzs”添加到拼写错误的单词候选中清单。
This logic is repeated for the whole table specified in figure 2.
对于图2中指定的整个表,将重复此逻辑。
Now that we have got a correctly-spelled candidate list and a misspelled word candidate list, what follows is the logic in assigning the correctly spelled word to its respective misspellings.
现在我们已经有了一个正确拼写的候选列表和一个单词拼写错误的候选列表 ,接下来是将正确拼写的单词分配给其各自的拼写错误的逻辑。
第2部分:拼写错误的解决方案 (Part 2: Misspelling Resolution)
In this step, Candidate Comparisons are performed to resolve misspellings.
在此步骤中,将执行候选比较来解决拼写错误。
The algorithm will now check all words in the misspelled list against all words in the correctly-spelled list.
现在,该算法将对照拼写正确的列表中的所有单词检查拼写错误的列表中的所有单词。
It compares a misspelled word candidate to every correctly spelled word candidate, and computes a distance between them.
它将拼写错误的单词候选者与每个正确拼写的单词候选者进行比较,并计算它们之间的距离。
Another predetermined parameter called “maximum spell distance” determines if the misspelled word has a correct spelling or not.
另一个称为“最大拼写距离”的预定参数确定拼错的单词是否具有正确的拼写。
For instance, if the word “algoxxxthzs” is the given misspelled word and the word “algorithm” is the correctly spelled candidate, then the distance computed between “algoxxxthzs” and “algorithm” would be 50.
例如,如果单词“ algoxxxthzs”是给定的拼写错误的单词,而单词“ algorithm”是正确拼写的候选单词,则“ algoxxxthzs”和“ algorithm”之间的距离将为50。
If “maximum spell distance” was set to 20. Since 50 is greater than 20, the correctly spelled candidate “algorithm” is now deemed as the correct spelling for the word “algoxxxthzs”.
如果将“最大拼写距离”设置为20。由于50大于20,因此现在将正确拼写的候选“算法”视为单词“ algoxxxthzs”的正确拼写。
There are also other advance parameters you could set here to account for multi-term words like “fire engine”, “carry on” or “join in” etc. You can read the documentation here.
您还可以在此处设置其他高级参数,以说明多个术语,例如“消防车”,“继续”或“加入”等。您可以在此处阅读文档。
Although I made it sound really complicated above…
尽管上面我说的听起来真的很复杂...
It is not.
它不是。
Here’s how to run all of the above.
这是运行上述所有程序的方法。
proc cas;
textParse.tpSpell /
table={name="pos", caslib="public"}
minParents=3
maxChildren=6
maxSpellDist=15
casOut={name="tpSpell_Out", replace=true};
run;
quit;The result will look as such:
结果将如下所示:

One thing I love about SAS programming is how easy it is to make use of complicated algorithms with just a few lines of code.
我喜欢SAS编程的一件事是,只需几行代码即可使用复杂的算法非常容易。
Yes, Python packages do the same thing but sometimes, the packages are not as advanced as SAS.
是的,Python软件包做同样的事情,但是有时,这些软件包不如SAS先进。
A good example would be how SAS does optimization for deep learning hyperparameters and parameters within the layers. As an anecdote, it was really easy to do hyper-parameter tuning in SAS.
一个很好的例子是SAS如何针对层中的深度学习超参数和参数进行优化。 作为轶事,在SAS中进行超参数调整确实非常容易。
SAS combines Latin Hypercube with the Genetic Algorithm optimized with the Hyperband method to account for resource utilization. In addition, everything is automatically multi-threaded.
SAS将Latin Hypercube与通过Hyperband方法优化的遗传算法相结合,以解决资源利用问题。 此外,所有内容均自动为多线程。
Coding what SAS does out of the box in Python would have definitely taken more time, effort and not to mention, the knowledge needed on how to distribute processing with Python, accounting for resource allocation and utilization — which I think the majority of the people aren’t familiar with.
编码SAS在Python中开箱即用的做法肯定会花费更多的时间,精力,更不用说,有关如何使用Python分配处理,解决资源分配和利用问题所需的知识了-我认为大多数人都不会不熟悉。
数据质量问题2:处理随机空白 (Data Quality Issue 2: Handling Random White Spaces)
This problem really had me testing multiple methodologies. All of which did not perform well except for the methodology I’ll be going through now.
这个问题确实让我测试了多种方法。 除了我将要介绍的方法论之外,所有这些方法均表现不佳。
To re fresh your m emry, thee probl em loked lik e thsi
为了让您的记忆焕然一新,您可能会喜欢
There are a few data quality issues worth pointing out above:
上面有一些数据质量问题值得指出:
- Space in-between the words i.e. “probl em” 单词之间的空格,即“ probl em”
- Missing characters i.e. “loked” 缺少字符,即“ loked”
- Swapped characters i.e. “thsi” 交换字符,即“ thsi”
- Double characters i.e. “thee” 双字符,即“ thee”
- Combination of issues i.e. “m emry” — combination of 1 and 2. 问题组合,例如“存储器”-1和2的组合。
I had to find a way to resolve the spaces in-between words while at the same time, account for the misspellings (numbers 2, 3 and 4).
我必须找到一个方法来解决空间在中间的话,而在同一时间 ,占了拼写错误(数字2,3和4)。
Thankfully, handling the misspellings can be taken care of relatively easily as I have shown above with tpSpell.
值得庆幸的是,如我上面使用tpSpell所示,可以很容易地处理错拼。
But the complexity comes in with the combinations of issues (number 5).
但是,复杂性来自问题的组合(第5个)。
For a combination problem like this, I first needed to resolve the white spaces before applying the misspelling resolution.
对于这样的组合问题,在应用拼写错误的分辨率之前,我首先需要解决空格。
While thinking about the best solution for the job, I took inspiration from how encoder-decoder networks worked.
在考虑最佳工作解决方案时,我从编码器-解码器网络的工作方式中获得了启发。
Could I somehow “encode” the sentences and “decode” them after?
我能以某种方式对句子进行“编码”,然后再对其进行“解码”吗?
Obviously I’m using the terms inappropriately here. By “encode” I actually meant to remove all white spaces between words. Like such:
显然,我在这里不恰当地使用了这些术语。 “编码”实际上是指删除单词之间的所有空白。 像这样:
torefreshyourmemrytheeproblemlokedlikethsi
刷新您的内存问题
By “decode”, I mean to break the words back into their individual words after resolving misspellings:
我所说的“解码”是指在解决拼写错误后,将单词分解成单独的单词:
to refresh your memory the problem looked like this
刷新您的记忆,问题看起来像这样
“解码”问题(第1部分) (The Problem with “Decoding” Part 1)
One of the biggest problem I had to resolve was when to insert a white space once a string had been “encoded”.
我必须解决的最大问题之一是,一旦对字符串进行“编码”,何时插入空白。
Take the words “torefresh” for instance.
以单词“ torefresh ”为例。
How would you know to insert a white space between “to” and “refresh”? Why not “to”, “re” and “fresh”?
您如何知道在“ 至 ”和“ 刷新 ”之间插入空格? 为什么不“ 改为 ”,“ 重新 ”和“ 新鲜 ”?
Here’s how I did it and the logic of my SAS script.
这是我的操作方式以及SAS脚本的逻辑。
Decoded words are based off the longest match of the word.
解码的单词基于单词的最长匹配 。
For example, if I saw the words “helloworld”, I am first going to perform a look up for the word “hell” in a predefined potential candidate list. i.e. dictionary table
例如,如果我看到单词“ helloworld ”,那么我将首先在预定义的潜在候选者列表中查找单词“ hello ”。 即字典表
Until the next character “o” appears, since “hell+o” = “hello”, “hello” becomes the better potential candidate.
在下一个字符“ o ”出现之前,由于“ hell + o ” =“ hello ”,因此“ hello ”成为更好的潜在候选者。
I drop the word “hell” as main candidate and keep the word “hello” as the new main candidate.
我删除“ 地狱 ”一词作为主要候选人,而保留“ 你好 ”一词作为新的主要候选人。
As the next character gets read in, “hello+w” = “hellow”, since “hellow” is not a proper word in the potential candidate list, the best candidate to split off is “hello”.
随着下一个字符的读入,“ hello + w ” =“ hellow ”,因为“ hellow ”在潜在候选列表中不是正确的单词,因此,最好的候选词是“ hello ”。
Once these checks are completed, I add a white space after “hello” and continue the logic above for “w”, “o”, “r”, “l” and “d” until I get “hello world”
完成这些检查后,我在“ hello ”之后添加一个空格,并继续上面的“ w ”,“ o ”,“ r ”,“ l ”和“ d ”的逻辑,直到得到“ hello world ”
So what is this potential candidate list and how did I get this dictionary?
那么,这个潜在的候选人名单是什么?我是怎么得到这本词典的呢?
It is a dictionary I created from the correctly-spelled word list generated from the tpSpell action earlier.
这是我根据前面的tpSpell操作生成的正确拼写单词列表创建的字典。
Meaning to say, all correctly-spelled words are placed into this dictionary table for me to look up as I “decode” each string.
意思是说,所有正确拼写的单词都放在此字典表中,以便我在“解码”每个字符串时查询。
“解码”第2部分的问题 (The Problem with “Decoding” Part 2)
There were other issues that needed to be resolved to make the “decoder” work.
为了使“解码器”正常工作,还需要解决其他问题。
That is, I had to remove stop words, all forms of punctuation, lower cased all words and only keep parent terms.
也就是说,我必须删除停用词,所有形式的标点符号,所有单词都小写并仅保留父项。
Why?
为什么?
Because if I didn’t there would have been a lot of issues that surfaced.
因为如果我不这样做,将会出现很多问题。
Take this sentence for instance:
以这句话为例:
“the series of books”
《丛书》
After “encoding” it will be:
在“编码”之后,它将是:
“theseriesofbooks”
“系列丛书”
Recall that the algorithm I created takes the longest match in the dictionary during the “decoding” process.
回想一下,我创建的算法会在最长匹配 在“解码”过程中的字典。
If I kept all stop words, the “decoder” would have parsed the first word as “these” and not “the”.
如果我保留所有停用词,则“解码器”会将第一个词解析为“ 这些 ”而不是“ the ”。
Because of this, the next characters “ries” in the word “series” will no longer be a word in my dictionary, and will be discarded.
正因为如此,下一个字符“ 的故事。”单词“ 本身 的故事。”将不再是在我的字典一个字,并且将被丢弃。
This would mean the “decoded” string will end up being “these of books”, which is obviously incorrect.
这将意味着“解码后的”字符串最终将变成“ 这些书 ”,这显然是错误的。
Another intricacy that affects the “decoder” looks something like this:
影响“解码器”的另一个复杂性看起来像这样:
“bicycle sports” → “bicyclesports” → “bicycles ports” (wrong)
“自行车运动”→“自行车运动”→“自行车港口”(错误)
To counter this issue, I only kept parent terms in my dictionary table.
为了解决这个问题,我只将父项保留在字典表中。
Example 1: bicycles → bicycle
实施例1:自行车小号 →自行车
Example 2: sports → sport
实施例2: 网球及→运动
By only looking at parent terms, my output looked like this:
仅查看父项,我的输出如下所示:
“bicycle sport” → “bicyclesport” → “bicycle sport” (correct)
“自行车运动”→“自行车运动”→“自行车运动”(正确)
Because “bicycles” is no longer in my dictionary and “bicycle” is, the decoder parses it correctly and does not output “bicycles port”.
因为在我的词典中不再是“ bicycle s ”,而在我的词典中是“ bicycle ”,所以解码器会正确解析它,并且不会输出“ bicycles port”。
So there you have it!
所以你有它!
My very own “encoder-decoder” methodology to clean extremely dirty unstructured text! 😉
我自己的“编码器-解码器”方法可清除极其脏的非结构化文本! 😉
It’s not a perfect solution but it does get the job done enough for me to start my downstream NLP task proper.
这不是一个完美的解决方案,但是它确实完成了足够的工作,足以让我正确启动下游NLP任务。
看到一切都在行动! (Seeing it all in Action!)
Just to show you an example of how the would look like after running the code, I ran the code against a books review corpus with mocked up data quality issues.
只是为了向您展示运行代码后代码的示例,我针对带有模拟数据质量问题的书评语料库运行了代码。
Here’s how the sample and the process looks like:
示例和过程如下所示:

尾注 (Ending Notes)
Well, that’s it then!
好吧,就是这样!
I hope you found this post insightful! 😃
希望您发现这篇文章有见地! 😃
Albeit spending close to 2 weeks trying out many methodologies, I had tons of fun with this!
尽管花了将近2周的时间尝试了许多方法,但我对此还是充满了乐趣!
Till next time, farewell!
下次,再见!
Linkedin Profile: Timothy Tan
领英简介: Timothy Tan
自然文本语言处理文本清理















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









