





 本文是word2vec的入门指南,深入讲解了用于生成词嵌入的CBOW和skip-gram两种主要架构,提供实践经验。
本文是word2vec的入门指南,深入讲解了用于生成词嵌入的CBOW和skip-gram两种主要架构,提供实践经验。
This post is a beginner’s guide to generate word embeddings using word2vec. There are two primary architectures for implementing word2vec: namely continuous bag-of-words (CBOW) and skip-gram (SG). In this article, we’ll explore the problem of word embeddings in more detail and get some hands-on experience with both architectures.
这篇文章是生成单词嵌入的初学者指南 使用word2vec。 有两种实现word2vec的主要体系结构:即连续词袋(CBOW)和skip-gram(SG) 。 在本文中,我们将更详细地探讨词嵌入的问题,并获得有关这两种体系结构的一些动手经验。
问题 (The Problem)
AI models ain’t very good at making sense out of raw text. Content should be changed over into a numerical structure to be properly processed by ML models. A typical practice in natural language processing(NLP) is to change text into vectors containing numerical values. There are different methods used in NLP for accomplishing this—some of them are:
AI模型并不是很好地利用原始文本。 内容应转换为数字结构,以由ML模型正确处理。 自然语言处理 (NLP)中的一种典型做法是将文本更改为包含数值的向量。 NLP中使用了不同的方法来实现此目的-其中一些是:
- One-Hot Encoding 一站式编码
- Label Encoding 标签编码
- Custom Binary Encoding 自定义二进制编码
The problem with the above techniques is the loss of context. Let’s take 2 sentences: This food was so tasty and This food was so amazing. These sentences have almost the same meaning. But with the use of the above methods, the result would show no relationship between the two sentences. The reason being that these techniques use vectors, which are sparse and high-dimensional. The dimensions increase with the increase in vocabulary, without having any relationship to the dimensions.
上述技术的问题是上下文的丢失。 让我们用两句话: 这食物真好吃 , 这食物真神奇。 这些句子的含义几乎相同。 但是使用上述方法,结果将显示两个句子之间没有任何关系。 原因是这些技术使用的是稀疏的高维向量。 尺寸随着词汇量的增加而增加,而与尺寸没有任何关系。
解决方案:Word2vec (The Solution: Word2vec)
One of the major breakthroughs in the field of NLP is word2vec (developed by Tomas Mikolov, et al. in 2013). Word2vec attempts to decide the importance of a word by breaking down its neighboring words (the context) and thus resolving the context loss issue.
NLP领域的重大突破之一是word2vec(由Tomas Mikolov等人于2013年开发)。 Word2vec尝试通过分解单词的相邻单词( 上下文 )来确定单词的重要性,从而解决上下文丢失问题。
It uses neural networks to establish word embeddings. Word embedding is another popular method for representing words as vector. It is a good fit for catching the context of a given word in an archive, semantic and syntactic likeness, connection with different words, and so on.
它使用神经网络来建立单词嵌入。 词嵌入是将词表示为矢量的另一种流行方法。 非常适合捕获存档中给定单词的上下文,语义和句法相似性,与不同单词的联系等等。
As a reminder, the two major architectures for word2vec are continuous bag-of-words (CBOW) and skip-gram (SG).
提醒一下,word2vec的两个主要体系结构是连续词袋(CBOW)和跳过语法(SG)。
CBOW vs SG (CBOW vs SG)
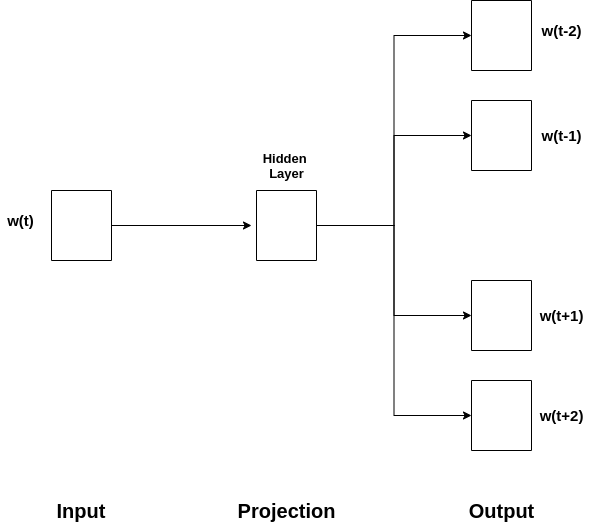
In SG, the model iterates over the words in the corpus and predicts the neighbors (i.e. the context). As shown in the SG architecture below, the current word is used as the input layer, and the context words are present in the output.
在SG中 ,模型对语料库中的单词进行迭代并预测邻居(即上下文)。 如下所示的SG体系结构所示,当前单词用作输入层,上下文单词出现在输出中。
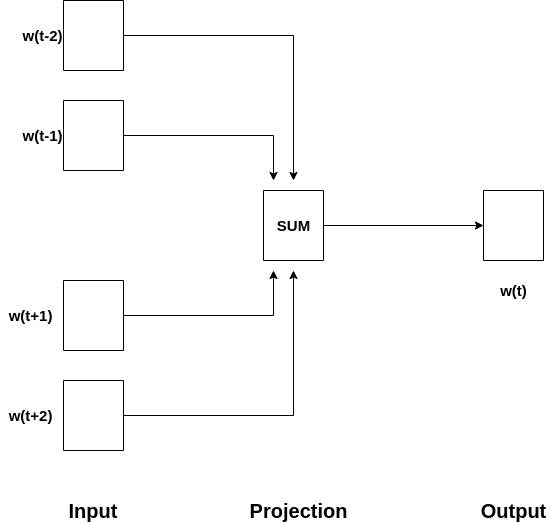
In CBOW, the model uses the context to make a prediction about the current word. As shown in the architecture for CBOW below, the context words are present in the input layer, and the current word is present in the output layer.
在CBOW中,模型使用上下文对当前单词进行预测。 如以下CBOW的体系结构所示,上下文单词出现在输入层中,而当前单词出现在输出层中。
In both the architectures, the number of dimensions used to depict the current word is presented in the hidden layer. Also, both CBOW and SG are shallow neural networks, meaning they only contain one hidden layer.
在两种体系结构中,用于描述当前单词的维数都在隐藏层中显示。 同样,CBOW和SG都是浅层神经网络,这意味着它们仅包含一个隐藏层。
The essential thought of word embedding, then, is that words that occur in a comparative context will (in general) be nearer to one another in the vector space.
因此,词嵌入的基本思想是,在比较上下文中出现的词(通常)在向量空间中彼此更接近。
Now that we have the basic idea of word2vec and these two architectures, let’s get our hands dirty with implementations.
现在我们有了word2vec和这两种体系结构的基本思想,让我们开始着手实现。
The modules we’re going to need are ntlk (used for language processing), gensim (used for topic modeling, document indexing, and similarity retrieval) and wordcloud(to visualize our dataset)
我们将需要的模块是ntlk (用于语言处理), gensim (用于主题建模,文档索引和相似性检索)和wordcloud (用于可视化我们的数据集)
Let’s first install them:
首先安装它们:
$ pip install nltk gensim wordcloudThe dataset we’re using (the first chapter of Alice in Wonderland) can be found here: https://gist.github.com/phillipj/4944029.
我们正在使用的数据集(《爱丽丝梦游仙境》的第一章)可以在以下位置找到: https : //gist.github.com/phillipj/4944029 。
Lets jump into the code…
让我们跳入代码...
NOTE: We need to download a dependency for tokenization (i.e., breaking the sentence, documents, etc., into smaller units or words)—Punkt Tokenizer Model—it’s a ~13 MB file and can be downloaded as shown below:
注意:我们需要下载一个用于标记化的依赖项( 即,将句子,文档等分解为较小的单位或单词 )— Punkt Tokenizer Model —它约为13 MB,可以如下所示下载:
nltk.download('punkt')or using the terminal:
或使用终端:
$ python -m nltk.downloader 'punkt'In the output, we can visualize the similarity between the words ‘alice’ , ‘wonderland’ and ‘machines’. You can learn about the parameters used here and try playing with them yourself.
在输出中,我们可以可视化单词“ alice”,“ wonderland”和“ machines”之间的相似性。 您可以了解此处使用的参数,然后尝试自己使用它们。
Some very interesting applications of word2vec can be found here:
在这里可以找到word2vec的一些非常有趣的应用程序:
Machine learning is rapidly moving closer to where data is collected — edge devices. Subscribe to the Fritz AI Newsletter to learn more about this transition and how it can help scale your business.
机器学习正Swift向收集数据的地方(边缘设备)靠近。 订阅Fritz AI新闻简报,以了解有关此过渡及其如何帮助您扩展业务的更多信息。
在CBOW和SG之间决定 (Deciding between CBOW & SG)
There’s no definitive answer when it comes to picking between these two methods. To do so, we should really take a careful look at the dataset we’re using. As indicated by Mikolov, SG works admirably with a modest quantity of information and is found to work especially well with uncommon words. Then again, CBOW is faster and works a bit better with frequently occurring words.
在这两种方法之间进行选择时,没有明确的答案。 为此,我们确实应该仔细查看正在使用的数据集。 正如米科洛夫(Mikolov)指出的那样,SG的信息量适中,并且使用不常见的单词效果特别好。 再说一次,CBOW更快,并且对于经常出现的单词来说效果更好。
Word2vec的缺点 (Drawbacks of Word2vec)
While word2vec is powerful and super easy to understand, it also has its flaws. Some of them are:
虽然word2vec功能强大且超级易于理解,但也有其缺陷。 他们之中有一些是:
- If a word isn’t present in our vocabulary, the model won’t be able to represent its vector. 如果我们的词汇表中没有单词,则该模型将无法表示其向量。
- There is no cross-language support. 没有跨语言支持。
GitHub Gist link:
GitHub Gist链接:
Word2vec的原始纸: (Original paper for word2vec:)
结论 (Conclusion)
In this article, we explored the ideas and concepts behind word2vec and implemented our own word2vec model using both a continuous-bag-of-words and a skip-gram model. You can further tweak the model to perform better (read more about how to do that here).
在本文中,我们探讨了word2vec背后的思想和概念,并使用连续词袋和跳跃语法模型实现了自己的word2vec模型。 您可以进一步调整模型以使其表现更好( 在此处了解有关如何执行此操作的更多信息)。
Word2vec was indeed a breakthrough in the field of AI (and especially NLP), but there have since been many more advancements in the field. One of them is doc2vec, which is based on the foundation of word2vec. In future articles, I’ll examine doc2vec, so stay tuned. Feedback is welcome!
Word2vec确实是AI(尤其是NLP)领域的突破,但是此后在该领域有了许多进步。 其中之一是doc2vec ,它基于word2vec的基础。 在以后的文章中,我将检查doc2vec,请继续关注。 欢迎反馈!
Happy Learning :)
快乐学习:)
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to exploring the emerging intersection of mobile app development and machine learning. We’re committed to supporting and inspiring developers and engineers from all walks of life.
编者注: 心跳 是由贡献者驱动的在线出版物和社区,致力于探索移动应用程序开发和机器学习的新兴交集。 我们致力于为各行各业的开发人员和工程师提供支持和启发。
Editorially independent, Heartbeat is sponsored and published by Fritz AI, the machine learning platform that helps developers teach devices to see, hear, sense, and think. We pay our contributors, and we don’t sell ads.
Heartbeat在编辑上是独立的,由以下机构赞助和发布 Fritz AI ,一种机器学习平台,可帮助开发人员教设备看,听,感知和思考。 我们向贡献者付款,并且不出售广告。
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Fritz AI Newsletter), join us on Slack, and follow Fritz AI on Twitter for all the latest in mobile machine learning.
如果您想做出贡献,请继续我们的 呼吁捐助者 。 您还可以注册以接收我们的每周新闻通讯(《 深度学习每周》 和《 Fritz AI新闻通讯》 ),并加入我们 Slack ,然后继续关注Fritz AI Twitter 提供了有关移动机器学习的所有最新信息。
翻译自: https://heartbeat.fritz.ai/getting-started-with-word2vec-f44576d61eda















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









