






gpt2模型
Originally published at https://www.philschmid.de on September 6, 2020.
最初于 2020年9月6日 在 https://www.philschmid.de 上 发布 。
介绍 (introduction)
Unless you’re living under a rock, you probably have heard about OpenAI’s GPT-3 language model. You might also have seen all the crazy demos, where the model writes JSX, HTML code, or its capabilities in the area of zero-shot / few-shot learning. Simon O'Regan wrote an article with excellent demos and projects built on top of GPT-3.
除非您生活在岩石之下,否则您可能听说过OpenAI的GPT-3语言模型。 您可能还已经看过所有疯狂的演示,其中该模型在零镜头学习/少镜头学习领域中编写了JSX , HTML代码或其功能。 Simon O'Regan撰写了一篇文章,其中包含基于GPT-3的出色演示和项目 。
A Downside of GPT-3 is its 175 billion parameters, which results in a model size of around 350GB. For comparison, the biggest implementation of the GPT-2 iteration has 1,5 billion parameters. This is less than 1/116 in size.
GPT-3的缺点是其1,750亿个参数,导致模型大小约为350GB。 为了进行比较,GPT-2迭代的最大实现具有15亿个参数。 它的大小小于1/116。
In fact, with close to 175B trainable parameters, GPT-3 is much bigger in terms of size in comparison to any other model else out there. Here is a comparison of the number of parameters of recent popular NLP models, GPT-3 clearly stands out.
实际上,GPT-3具有接近175B的可训练参数,与其他模型相比,其尺寸要大得多。 这是对最近流行的NLP模型的参数数量的比较,GPT-3显然很突出。
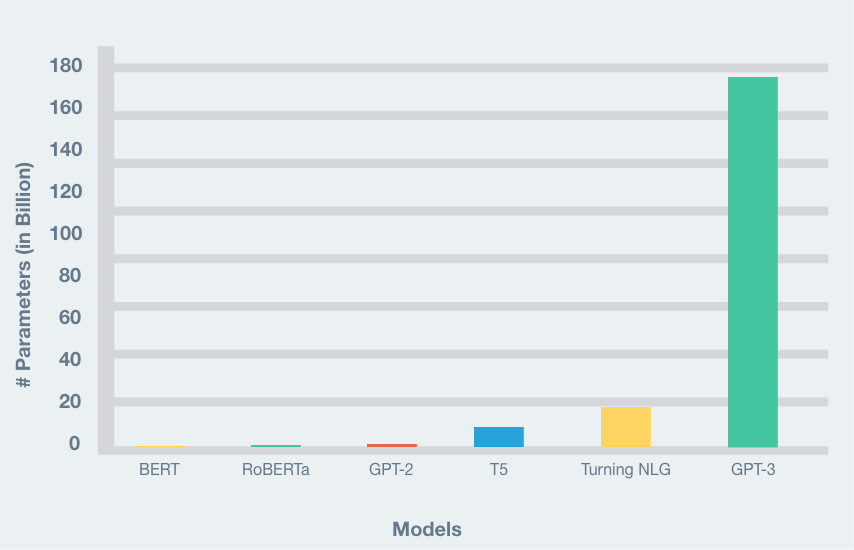
This is all magnificent, but you do not need 175 billion parameters to get good results in text-generation.
这一切都是宏伟的,但您不需要1750亿个参数即可在text-generation获得良好的结果。
There are already tutorials on how to fine-tune GPT-2. But a lot of them are obsolete or outdated. In this tutorial, we are going to use the transformers library by Huggingface in their newest version (3.1.0). We will use the new Trainer class and fine-tune our GPT-2 Model with German recipes from chefkoch.de.
已经有关于如何微调GPT-2的教程。 但是其中许多已经过时或过时了。 在本教程中,我们将使用Huggingface的最新版本(3.1.0)的transformers库。 我们将使用新的Trainer类,并使用来自Chefkoch.de的德国食谱对GPT-2模型进行微调 。
You can find everything we are doing in this colab notebook.
您可以在此
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









