





bert 对话
by Brandon Janes
布兰登·简斯(Brandon Janes)
For over a year I have been trying to automate appointment scheduling using NLP and python, and I finally got it to work thanks to an amazing free open-source dialogue tool called Rasa.
一年多来,我一直在尝试使用NLP和python自动执行约会计划,由于一个了不起的免费开源对话工具Rasa,我终于使它可以工作。
The truth is a year ago, when I started this project, the tools I am using now were hardly available. Certainly not in the easy-to-use form that we find them today. As a testament to how quickly this science of artificial intelligence and NLP is moving, this time last year (June 2019) transformers like BERT had barely left the domain of academic research and were just beginning to be seen in production at tech giants like Google and Facebook. The BERT paper itself was only published in October 2018 (links to papers below).
事实是一年前,当我开始这个项目时,我现在使用的工具几乎不可用。 当然不是我们今天可以找到的易于使用的形式。 为了证明人工智能和自然语言处理科学的发展速度之快,去年的这个时候(2019年6月)像BERT这样的变压器几乎没有离开学术研究的领域,并且刚刚开始在Google和Google等科技巨头的生产中出现。脸书 BERT论文本身仅在2018年10月发表(以下文章的链接)。
Today, thanks to open-source platforms like Rasa and HuggingFace, BERT and other transformer architectures are available in an easy plug-and-play manner. Moreover, the data scientists at Rasa have developed a special transformer-based classifier called the Dual Intent Entity Transformer or DIET classifier that is tailor-made for the task of extracting entities and classifying intents simultaneously, which is exactly what we do with our product MyTurn, an appointment scheduling virtual assistant developed with my team at Kunan S.A. in Argentina.
如今,由于使用了Rasa和HuggingFace之类的开源平台,BERT和其他变压器体系结构都可以通过即插即用的方式轻松获得。 此外,Rasa的数据科学家还开发了一种特殊的基于变压器的分类器,称为双重意图实体变压器或DIET分类器,该分类器专为提取实体和同时对意图进行分类的任务而量身定制,这正是我们使用产品MyTurn所做的是与我的团队在阿根廷的Kunan SA共同开发的约会调度虚拟助手。
证明是在p̶u̶d̶d̶i̶n̶g̶f1分数中 (The proof is in the p̶u̶d̶d̶i̶n̶g̶ f1 score)
For quantitative folks out there, after I replaced ye ole Sklearn-based classifier with DIET my F1 score surged in both entity extraction and intent classification by more than 30 percent!!!! Compare SklearnIntentClassifier with diet_BERT_combined in the figures below. If you have ever designed machine learning models, you’d know that 30 percent is huge. Like that time you realized you had parked your car on the hose to the sprinkler. What a wonderful surprise when things work the way they should!
对于在那里的定量研究人员来说,在我用DIET替换了基于ole Sklearn的分类器之后,我的F1分数在实体提取和意图分类上均猛增了30%以上!!! 将SklearnIntentClassifier与Diet_BERT_combined在下图中进行比较。 如果您曾经设计过机器学习模型,那么您会知道其中的30%是巨大的。 那时,您意识到自己已经将汽车停在洒水装置的软管上。 当事情以应有的方式运作时,真是一个奇妙的惊喜!
情报的蓝图:config.yml (The blueprint for intelligence: config.yml)
Is it science or art? It’s neither. It’s trying every possible combination of hyperparameters and choosing the configuration that gives you the highest metrics. It’s called grid search.
是科学还是艺术? 都不是 它正在尝试超参数的所有可能组合,并选择可为您提供最高指标的配置。 这就是所谓的网格搜索。
It’s important to note that BERT is not a magic pill. In fact, for my specific task and training data, the BERT pretrained word embeddings alone did not provide good results (see diet_BERT_only above). These results were significantly worse than the old Sklearn-based classifier of 2019. Perhaps this can be explained by the regional jargon and colloquialisms found in the informal Spanish chats of Córdoba, Argentina, from where our training data was generated. The multilingual pretrained BERT embeddings we used were “trained on cased text in the top 104 languages with the largest Wikipedias,” according to HuggingFace documentation.
重要的是要注意,BERT不是魔术药。 实际上,对于我的特定任务和训练数据,仅BERT预先训练的单词嵌入并不能提供良好的结果(请参见上文Diet_BERT_only)。 这些结果比旧的基于Sklearn的2019年分类器差很多。也许这可以用产生阿根廷训练数据的阿根廷科尔多瓦非正式西班牙聊天中的区域性术语和口语来解释。 根据HuggingFace的文档,我们使用的多语言预训练BERT嵌入“已在使用最大的Wikipedia的前104种语言中的带大小写的文本上进行了训练”。
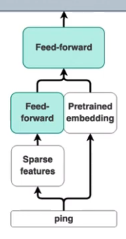
However, the highest performing model we obtained was by training custom features on our own Córdoba data using DIET and then combining these supervised embeddings with the BERT pretrained embeddings in a feed forward layer (see results in diet_BERT_combined above). The small diagram below shows how “sparse features,” trained on Córdoba data, can be combined with BERT “pretrained embeddings” in a feed forward layer. This option is ideal for Spanish language projects with little training data. That being said, the combined model performed only slightly better than the model that used DIET with no BERT pretrained embeddings (see results for diet_without_BERT above). This means for non-English language chatbots with a moderate amount of training data, the DIET architecture is probably all you need.
但是,我们获得的性能最高的模型是通过使用DIET在我们自己的Córdoba数据上训练自定义特征,然后将这些受监督的嵌入与BERT预训练的嵌入在前馈层中组合在一起的(请参见上方Diet_BERT_combined的结果)。 下面的小图显示了如何在Córdoba数据上训练的“稀疏特征”与前馈层中的BERT“预训练的嵌入”相结合。 此选项非常适合培训数据很少的西班牙语项目。 就是说,组合模型的性能仅比使用没有BERT预训练嵌入的DIET的模型稍好(请参见上面Diet_without_BERT的结果)。 这意味着对于具有中等量训练数据的非英语聊天机器人,DIET体系结构可能就是您所需要的。
即插即用,用于realz (Plug and play, for realz)
After installing Rasa, and building an assistant to your needs (I suggest watching Rasa’s YouTube tutorial before doing this), the implementation of BERT embeddings is so easy it is almost disappointing.
安装Rasa并构建满足您需求的助手之后(我建议您在这样做之前先看一下Rasa的YouTube 教程 ),BERT嵌入的实现是如此简单,几乎令人失望。
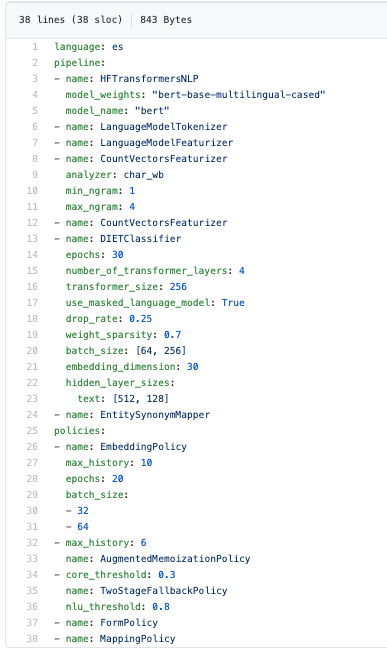
Below is an example of the configuration file we used. The long list of hyperparameters may seem overwhelming, but trust me, this is much easier than it was a year ago.
以下是我们使用的配置文件的示例。 长长的超参数列表似乎不胜枚举,但请相信我,这比一年前容易得多。
You must download the BERT dependencies:
您必须下载BERT依赖项:
pip install "rasa[transformers]"To integrate BERT or any of the other pretrained models available on the HuggingFace website, just replace the model_weights hyperparemeter in following line with whatever pretrainined embeddings you want to use.
要集成BERT或HuggingFace网站上可用的任何其他预训练模型,只需用要使用的任何预训练嵌入替换下面一行中的model_weights超参数表。
- name: HFTransformers NLP
model_weights: “bert-base-multilingual-cased”
model_name: “bert”We used bert-base-multilingual-cased because is was the best model available for Spanish.
我们使用bert-base-multilingual-cased是因为它是适用于西班牙语的最佳模型。
See our github for full examples of configuration files mentioned in this article and additional links.
有关本文中提到的配置文件的完整示例以及其他链接,请参见我们的github 。
结论 (Conclusion)
The beauty of Rasa is that it streamlines model training for Natural Language Understanding (NLU), Named Entity Recognition (NER) and Dialogue Management (DM), the three essential tools needed for task-oriented dialogue systems. Although we did a lot of good programming to make our system work as well as it does, you could probably get away with about 80 percent of building a Rasa virtual assistant without any real Python skills.
Rasa的优点在于,它简化了自然语言理解(NLU),命名实体识别(NER)和对话管理(DM)的模型训练,这是面向任务的对话系统所需的三个基本工具。 尽管我们做了很多很好的编程来使我们的系统正常工作,但是您可能无需使用任何真正的Python技能就可以构建大约80%的Rasa虚拟助手。
With exciting advancements in NLP, such as transformers and pretrained word embeddings, the field of conversational AI has leaped forward in recent years, from bots that say, “Sorry, I don’t understand,” to truly becoming feasible solutions to daily tasks that once required tedious human work.
随着NLP的激动人心的进步,例如转换器和预训练的词嵌入,近年来,对话式AI的领域已经飞跃起来,从说“对不起,我不明白”的机器人到真正成为日常任务的可行解决方案。曾经需要繁琐的人类工作。
Philosophically, the goal of this technology is not to replace humans with robots, but rather to assign the repetitive and “robotic” daily tasks, such as data entry or appointment scheduling, to virtual assistants, and reserve the brainspace of humans for the types of work that require skills that only humans have, such as creativity and critical thinking. MyTurn is a simple but prescient example of how conversational AI is not a tool reserved for Big Tech companies, but is in fact accessible to everybody through free and open-source technologies like Rasa and HuggingFace.
从哲学上讲,该技术的目标不是用机器人代替人类,而是将重复的“机器人”日常任务(例如数据输入或约会计划)分配给虚拟助手,并为人类的大脑类型保留大脑空间。这项工作需要只有人类才能拥有的技能,例如创造力和批判性思维。 MyTurn是一个简单但有先见之明的示例,它说明了对话式AI并非为大型科技公司保留的工具,但实际上所有人都可以通过Rasa和HuggingFace等自由和开源技术来访问它。

Suggested readings:
建议阅读:
Tom Bocklisch, Joey Faulkner, Nick Pawlowski, Alan Nichol, Rasa: Open Source Language Understanding and Dialogue Management,15 December 2017
Tom Bocklisch,Joey Faulkner,Nick Pawlowski,Alan Nichol, Rasa:开源语言理解和对话管理 ,2017年12月15日
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Attention Is All You Need, 6 December 2017
艾希什·瓦斯瓦尼(Ashish Vaswani),诺姆·谢泽(Noam Shazeer),妮基·帕玛(Niki Parmar),雅各布·乌斯科瑞特(Jakob Uszkoreit),里里昂·琼斯(Llion Jones),请注意 ,2017年12月6日
Jianfeng Gao (Microsoft), Micahel Galley (Microsoft), Lihong Li (Google), Neural Approaches to Conversational AI: Question Answering, Task-Oriented Dialogues and Social Chatbots, 10 September 2019
高剑峰(微软),米卡赫尔·加利(微软),李丽红(谷歌), 对话人工智能的神经方法:问题解答,面向任务的对话和社交聊天机器人 ,2019年9月10日
Jacob Devlin Ming-Wei Chang Kenton Lee Kristina Toutanova Google AI Language, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 11 October 2018
Jacob Devlin Ming-Wei Chang Kenton Lee Kristina Toutanova谷歌AI语言, BERT:用于语言理解的深度双向变压器的预培训, 2018年10月11日
翻译自: https://medium.com/@bubjanes/conversational-ai-with-bert-made-easy-1608ce23e58b
bert 对话















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









