





cnn lenet-5
技术和规范 (Technical and Code)
介绍 (Introduction)
LeNet was introduced in the research paper “Gradient-Based Learning Applied To Document Recognition” in the year 1998 by Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner. Many of the listed authors of the paper have gone on to provide several significant academic contributions to the field of deep learning.
Yannet LeCun , Leon Bottou , Yoshua Bengio和Patrick Haffner于1998年在研究论文“ 基于梯度的学习应用于文档识别 ”中介绍了L eNet。 该论文的许多列出的作者继续为深度学习领域提供了一些重要的学术贡献。
This article will introduce the LeNet-5 CNN architecture as described in the original paper, along with the implementation of the architecture using TensorFlow 2.0.
本文将介绍原始论文中所述的LeNet-5 CNN架构,以及使用TensorFlow 2.0实现的架构。
This article will then conclude with the utilization of the implemented LeNet-5 CNN for the classification of images from the MNIST dataset.
然后,本文将总结利用已实现的LeNet-5 CNN对MNIST数据集中的图像进行分类。
在本文中可以找到什么: (What to find in this article:)
Understanding of components within a convolutional neural network
了解卷积神经网络中的组件
Key definitions of terms commonly used in deep learning and machine learning
深度学习和机器学习中常用术语的关键定义
Understanding of LeNet-5 as presented in the original research paper
原始研究论文中介绍的对LeNet-5的理解
Implementation of a neural network using TensorFlow and Keras
使用TensorFlow和Keras实现神经网络
The content in this article is written for Deep learning and Machine Learning students of all levels.
本文中的内容适用于所有级别的深度学习和机器学习学生。
For those who are eager to get coding, scroll down to the ‘LeNet-5 TensorFlow Implementation’ section.
对于那些渴望获得编码的人,请向下滚动至“ LeNet-5 TensorFlow实施”部分。
卷积神经网络 (Convolutional Neural Networks)
Convolutional Neural Networks is the standard form of neural network architecture for solving tasks associated with images. Solutions for tasks such as object detection, face detection, pose estimation and more all have CNN architecture variants.
卷积神经网络是解决与图像相关的任务的神经网络体系结构的标准形式。 诸如对象检测,面部检测,姿势估计等任务的解决方案均具有CNN体系结构变体。
A few characteristics of the CNN architecture makes them more favourable in several computer vision tasks. I have written previous articles that dive into each characteristic.
CNN体系结构的一些特性使它们在某些计算机视觉任务中更为有利。 我写过以前的文章,深入探讨了每个特征。
LeNet-5 (LeNet-5)
LeNet-5 CNN architecture is made up of 7 layers. The layer composition consists of 3 convolutional layers, 2 subsampling layers and 2 fully connected layers.
LeNet-5 CNN体系结构由7层组成。 层组成包括3个卷积层,2个子采样层和2个完全连接的层。
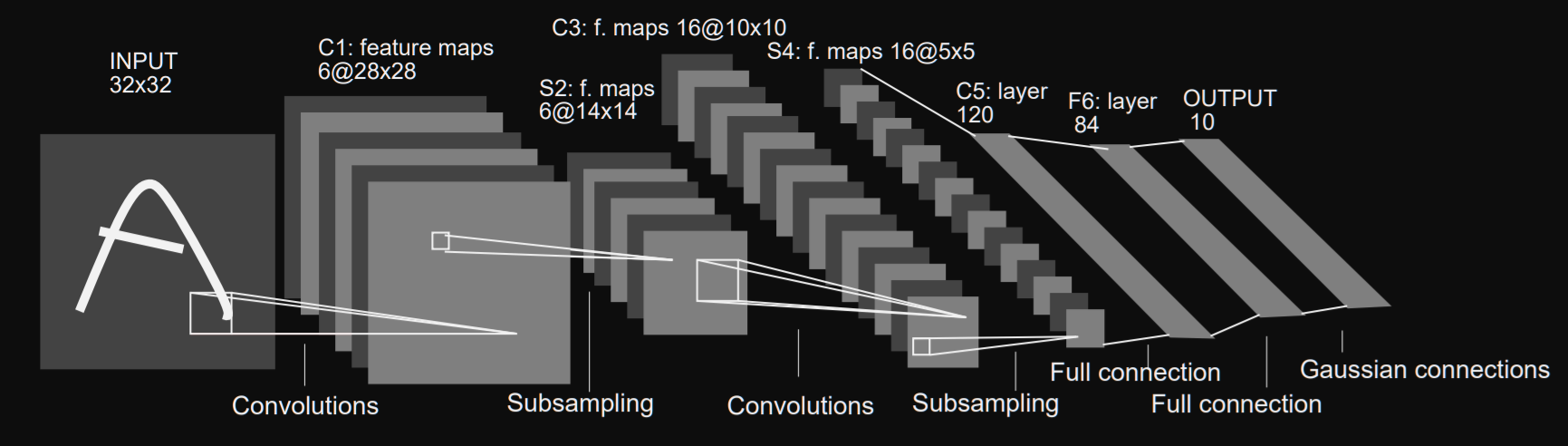
The diagram above shows a depiction of the LeNet-5 architecture, as illustrated in the original paper.
上图显示了LeNet-5架构的描述,如原始论文所示 。
The first layer is the input layer — this is generally not considered a layer of the network as nothing is learnt in this layer. The input layer is built to take in 32x32, and these are the dimensions of images that are passed into the next layer. Those who are familiar with the MNIST dataset will be aware that the MNIST dataset images have the dimensions 28x28. To get the MNIST images dimension to the meet the requirements of the input layer, the 28x28 images are padded.
第一层是输入层-通常不将其视为网络的一层,因为在这一层没有任何知识。 输入层的构建采用32x32,这是传递到下一层的图像的尺寸。 那些熟悉MNIST数据集的人会意识到MNIST数据集图像的尺寸为28x28。 为了使MNIST图像尺寸达到输入层的要求,请填充28x28图像。
The grayscale images used in the research paper had their pixel values normalized from 0 to 255, to values between -0.1 and 1.175. The reason for normalization is to ensure that the batch of images have a mean of 0 and a standard deviation of 1, the benefits of this is seen in the reduction in the amount of training time. In the image classification with LeNet-5 example below, we’ll be normalizing the pixel values of the images to take on values between 0 to 1.
研究论文中使用的灰度图像的像素值从0到255归一化为-0.1到1.175之间。 进行标准化的原因是要确保这批图像的平均值为0,标准差为1,这在减少训练时间方面可以看到好处。 在下面的LeNet-5示例的图像分类中,我们将对图像的像素值进行归一化,使其值介于0到1之间。
The LeNet-5 architecture utilizes two significant types of layer construct: convolutional layers and subsampling layers.
LeNet-5体系结构利用了两种重要的层构造类型:卷积层和子采样层。
Within the research paper and the image below, convolutional layers are identified with the ‘Cx’, and subsampling layers are identified with ‘Sx’, where ‘x’ is the sequential position of the layer within the architecture. ‘Fx’ is used to identify fully connected layers. This method of layer identification can be seen in the image above.
在研究论文和下面的图像中,卷积层由“ Cx”标识,子采样层由“ Sx”标识,其中“ x”是该层在体系结构中的顺序位置。 “ Fx”用于标识完全连接的层。 在上图中可以看到这种层识别方法。
The official first layer convolutional layer C1 produces as output 6 feature maps, and has a kernel size of 5x5. The kernel/filter is the name given to the window that contains the weight values that are utilized during the convolution of the weight values with the input values. 5x5 is also indicative of the local receptive field size each unit or neuron within a convolutional layer. The dimensions of the six feature maps the first convolution layer produces are 28x28.
官方的第一层卷积层C1生成6个特征图作为输出,并且内核大小为5x5。 内核/过滤器是给窗口的名称,其中包含权重值与权重值卷积期间使用的权重值。 5x5还表示卷积层内每个单元或神经元的局部感受野大小。 第一卷积层生成的六个特征贴图的尺寸为28x28。
A subsampling layer ‘S2’ follows the ‘C1’ layer’. The ‘S2’ layer halves the dimension of the feature maps it receives from the previous layer; this is known commonly as downsampling.
子采样层“ S2”紧跟在“ C1”层之后。 “ S2”层将其从上一层接收的特征图的尺寸减半; 这通常称为下采样。
The ‘S2’ layer also produces 6 feature maps, each one corresponding to the feature maps passed as input from the previous layer. This link contains more information on subsampling layers.
“ S2”层还产生6个特征图,每个特征图对应于从上一层作为输入传递的特征图。 该链接包含有关子采样层的更多信息。
More information on the rest of the LeNet-5 layers is covered in the implementation section.
在实现部分中涵盖了有关LeNet-5其余层的更多信息。
Below is a table that summarises the key features of each layer:
下表总结了每一层的主要功能:

LeNet-5 TensorFlow实施 (LeNet-5 TensorFlow Implementation)
We begin implementation by importing the libraries we will be utilizing:
我们通过导入将要使用的库来开始实施:
TensorFlow: An open-source platform for the implementation, training, and deployment of machine learning models.
TensorFlow :一个用于实施,培训和部署机器学习模型的开源平台。
Keras: An open-source library used for the implementation of neural network architectures that run on both CPUs and GPUs.
Keras :一个开放源代码库,用于实现在CPU和GPU上运行的神经网络体系结构。
Numpy: A library for numerical computation with n-dimensional arrays.
Numpy :用于使用n维数组进行数值计算的库。
import tensorflow as tf
from tensorflow import keras
import numpy as npNext, we load the MNIST dataset using the Keras library. The Keras library has a suite of datasets readily available for use with easy accessibility.
接下来,我们使用Keras库加载MNIST数据集。 Keras库具有易于使用且易于访问的一组数据集。
We are also required to partition the dataset into testing, validation and training. Here are some quick descriptions of each partition category.
我们还需要将数据集划分为测试,验证和培训。 这是每个分区类别的一些快速描述。
Training Dataset: This is the group of our dataset used to train the neural network directly. Training data refers to the dataset partition exposed to the neural network during training.
训练数据集 :这是我们的数据集,用于直接训练神经网络。 训练数据是指训练期间暴露于神经网络的数据集分区。
Validation Dataset: This group of the dataset is utilized during training to assess the performance of the network at various iterations.
验证数据集 :在训练期间利用该组数据集来评估网络在各种迭代中的性能。
Test Dataset: This partition of the dataset evaluates the performance of our network after the completion of the training phase.
测试数据集 :训练阶段完成后, 数据集的 此分区评估了我们网络的性能。
It is also required that the pixel intensity of the images within the dataset are normalized from the value range 0–255 to 0–1.
还需要将数据集中图像的像素强度从0–255到0–1的值范围进行归一化。
(train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data()
train_x = train_x / 255.0
test_x = test_x / 255.0train_x = tf.expand_dims(train_x, 3)
test_x = tf.expand_dims(test_x, 3)val_x = train_x[:5000]
val_y = train_y[:5000]In the code snippet above, we expand the dimensions of the training and dataset. The reason we do this is that during the training and evaluation phases, the network expects the images to be presented within batches; the extra dimension is representative of the numbers of images in a batch.
在上面的代码段中,我们扩展了训练和数据集的范围。 我们这样做的原因是,在训练和评估阶段,网络希望图像能够分批呈现。 额外的尺寸代表批次中的图像数量。
下面的代码是我们实现基于LeNet-5的实际神经网络的主要部分。 (The code below is the main part where we implement the actual LeNet-5 based neural network.)
Keras provides tools required to implement the classification model. Keras presents a Sequential API for stacking layers of the neural network on top of each other.
Keras提供了实现分类模型所需的工具。 Keras提供了一个顺序API,用于将神经网络的各个层堆叠在一起。
lenet_5_model = keras.models.Sequential([
keras.layers.Conv2D(6, kernel_size=5, strides=1, activation='tanh', input_shape=train_x[0].shape, padding='same'), #C1
keras.layers.AveragePooling2D(), #S2
keras.layers.Conv2D(16, kernel_size=5, strides=1, activation='tanh', padding='valid'), #C3
keras.layers.AveragePooling2D(), #S4
keras.layers.Flatten(), #Flatten
keras.layers.Dense(120, activation='tanh'), #C5
keras.layers.Dense(84, activation='tanh'), #F6
keras.layers.Dense(10, activation='softmax') #Output layer
])We first assign the variable’lenet_5_model'to an instance of the tf.keras.Sequential class constructor.
我们首先将变量“ lenet_5_model'分配给tf.keras.Sequential类构造函数的实例。
Within the class constructor, we then proceed to define the layers within our model.
然后,在类构造函数中,继续定义模型中的层。
The C1 layer is defined by the linekeras.layers.Conv2D(6, kernel_size=5, strides=1, activation='tanh', input_shape=train_x[0].shape, padding='same'). We are using the tf.keras.layers.Conv2D class to construct the convolutional layers within the network. We pass a couple of arguments which are described here.
C1层由行keras.layers.Conv2D(6, kernel_size=5, strides=1, activation='tanh', input_shape=train_x[0].shape, padding='same') 。 我们正在使用tf.keras.layers.Conv2D类来构造网络中的卷积层。 我们传递了一些在这里描述的论点。
Activation Function: A mathematical operation that transforms the result or signals of neurons into a normalized output. An activation function is a component of a neural network that introduces non-linearity within the network. The inclusion of the activation function enables the neural network to have greater representational power and solve complex functions.
激活函数 :将神经元的结果或信号转换为标准化输出的数学运算。 激活函数是神经网络的组成部分,它在网络内引入了非线性。 包含激活函数使神经网络具有更大的表示能力并能够解决复杂的函数。
The rest of the convolutional layers follow the same layer definition as C1 with some different values entered for the arguments.
其余的卷积层遵循与C 1相同的层定义,并为参数输入一些不同的值。
In the original paper where the LeNet-5 architecture was introduced, subsampling layers were utilized. Within the subsampling layer the average of the pixel values that fall within the 2x2 pooling window was taken, after that, the value is multiplied with a coefficient value. A bias is added to the final result, and all this is done before the values are passed through the activation function.
在介绍LeNet-5架构的原始论文中,使用了二次采样层。 在子采样层内,获取落在2x2合并窗口内的像素值的平均值,然后,将该值与系数值相乘。 将偏差添加到最终结果中,并在将值通过激活函数传递之前完成所有这些操作。
But in our implemented LeNet-5 neural network, we’re utilizing the tf.keras.layers.AveragePooling2D constructor. We don’ t pass any arguments into the constructor as some default values for the required arguments are initialized when the constructor is called. Remember that the pooling layer role within the network is to downsample the feature maps as they move through the network.
但是在我们已实现的LeNet-5神经网络中,我们利用了tf.keras.layers.AveragePooling2D构造函数。 我们不会将任何参数传递给构造函数,因为在调用构造函数时会初始化一些必需参数的默认值。 请记住,网络中的池层角色是在要素地图通过网络时对其进行下采样。
There are two more types of layers within the network, the flatten layer and the dense layers.
网络中还有两种类型的层:扁平层和密集层。
The flatten layer is created with the class constructor tf.keras.layers.Flatten.
flatten图层是使用类构造函数tf.keras.layers.Flatten创建的。
The purpose of this layer is to transform its input to a 1-dimensional array that can be fed into the subsequent dense layers.
该层的目的是将其输入转换为一维数组,该数组可以馈送到后续的密集层中。
The dense layers have a specified number of units or neurons within each layer, F6 has 84, while the output layer has ten units.
密集层在每层中具有指定数量的单位或神经元,F6具有84,而输出层具有十个单位。
The last dense layer has ten units that correspond to the number of classes that are within the MNIST dataset. The activation function for the output layer is a softmax activation function.
最后一个密集层具有十个单位,对应于MNIST数据集中的类数。 输出层的激活功能是softmax激活功能。
Softmax: An activation function that is utilized to derive the probability distribution of a set of numbers within an input vector. The output of a softmax activation function is a vector in which its set of values represents the probability of an occurrence of a class/event. The values within the vector all add up to 1.
Softmax :激活函数,用于导出输入向量内一组数字的概率分布。 softmax激活函数的输出是一个向量,其中的一组值表示发生类/事件的概率。 向量中的值总计为1。
Now we can compile and build the model.
现在我们可以编译并构建模型。
lenet_5_model.compile(optimizer=’adam’, loss=keras.losses.sparse_categorical_crossentropy, metrics=[‘accuracy’])Keras provides the ‘compile’ method through the model object we have instantiated earlier. The compile function enables the actual building of the model we have implemented behind the scene with some additional characteristics such as the loss function, optimizer, and metrics.
Keras通过我们先前实例化的模型对象提供了“ 编译”方法。 编译功能使我们能够在幕后实现实际构建的模型,并具有一些其他特征,例如损失函数,优化器和度量。
To train the network, we utilize a loss function that calculates the difference between the predicted values provided by the network and actual values of the training data.
为了训练网络,我们利用损失函数来计算网络提供的预测值与训练数据的实际值之间的差。
The loss values accompanied by an optimization algorithm(Adam) facilitates the number of changes made to the weights within the network. Supporting factors such as momentum and learning rate schedule, provide the ideal environment to enable the network training to converge, herby getting the loss values as close to zero as possible.
损耗值与优化算法( Adam )相伴随,简化了网络中权重变化的次数。 诸如动量和学习速率计划之类的支持因素为使网络培训收敛提供了理想的环境,从而使损耗值尽可能接近零。
During training, we’ll also validate our model after every epoch with the valuation dataset partition created earlier
在训练期间,我们还将在每个时期之后使用之前创建的评估数据集分区来验证我们的模型
lenet_5_model.fit(train_x, train_y, epochs=5, validation_data=(val_x, val_y))After training, you will notice that your model achieves a validation accuracy of over 90%. But for a more explicit verification of the performance of the model on an unseen dataset, we will evaluate the trained model on the test dataset partition created earlier.
训练后,您会注意到您的模型的验证精度达到90%以上。 但是,为了更清晰地验证模型在看不见的数据集上的性能,我们将在之前创建的测试数据集分区上评估训练后的模型。
lenet_5_model.evaluate(test_x, test_y)
>> [0.04592850968674757, 0.9859]After training my model, I was able to achieve 98% accuracy on the test dataset, which is quite useful for such a simple network.
训练完模型后,我能够在测试数据集上达到98%的准确度,这对于如此简单的网络非常有用。
Here’s GitHub link for the code presented in this article:
这是本文提供的代码的GitHub链接:
我希望您觉得这篇文章有用。 (I hope you found the article useful.)
To connect with me or find more content similar to this article, do the following:
要与我联系或查找更多类似于本文的内容,请执行以下操作:
cnn lenet-5

















 3528
3528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









