






机器学习 预测模型
In my last article, I gave a gentle overview of what Machine Learning was about and the framework of building a Machine Learning model. The data was cleaned and some Exploratory Data Analysis were carried out, in order to gain insight into the data. In this article, we will be continuing from there. If you’ve not seen the last post, click here to read it, so you can follow along easily.
在上一篇文章中,我对机器学习的内容以及构建机器学习模型的框架进行了简要的概述。 清理数据并进行一些探索性数据分析,以深入了解数据。 在本文中,我们将从那里继续。 如果您没有看到上一篇文章,请单击此处阅读它,以便您轻松进行后续操作。
特征工程 (Feature Engineering)
Feature engineering is a vital preprocessing technique in building any machine learning model. It involves pulling out some features from the data using domain knowledge. First, the ‘location’ and ‘engine’ columns were dropped from the dataframe. The ‘location’ because it does not affect the price. The ‘engine’, on the other hand, because the entries were mostly unique, so the algorithm does not learn from the feature.
特征工程是构建任何机器学习模型的重要预处理技术。 它涉及使用领域知识从数据中提取一些功能。 首先,从数据框中删除了“位置”和“引擎”列。 “位置”,因为它不影响价格。 另一方面,“引擎”由于条目大多是唯一的,因此算法无法从该功能中学习。
ML algorithms deal purely with numerical inputs and outputs. Therefore, the string-type/categorical features were converted to numerical data. This was done using One Hot encoding which creates separate columns for every entry in a column and fills in 1 to indicate an entry’s presence and 0 if otherwise. The get_dummies method performed this operation.
ML算法仅处理数字输入和输出。 因此,将字符串类型/类别特征转换为数值数据。 这是使用One Hot编码完成的,该编码为列中的每个条目创建单独的列,并填充1表示条目的存在,否则填充0。 get _ dummies方法执行了此操作。
data = data.drop(['Location', 'Engine'], axis=1)
cat_features = [x for x in data.columns if data[x].dtype == 'O']
data = pd.get_dummies(data, cat_features)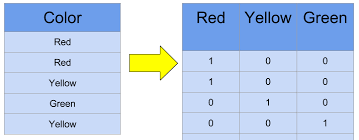
The data was then split into train and test data. The ML model learns with the train data while the test data, as the name implies, is used to check how well the model has learnt. Outliers and other anomalous data distribution were handled with Feature Scaling. Features Scaling compresses the data within a particular range of values. Features can either be standardized or normalized. In this case, the data was normalized using the StandardScaler class. The scaling was fitted on the train data alone since the test data should be treated as unseen data.
然后将数据分为训练数据和测试数据。 ML模型通过火车数据进行学习,而顾名思义,测试数据用于检查模型的学习程度。 离群值和其他异常数据分布通过特征缩放处理。 功能缩放可在特定值范围内压缩数据。 功能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









