





熵 机器学习
TL;DR: Entropy is a measure of chaos in a system. Because it is much more dynamic than other more rigid metrics like accuracy or even mean squared error, using flavors of entropy to optimize algorithms from decision trees to deep neural networks has shown to increase speed and performance.
TL; DR:熵是对系统中混沌的一种度量。 因为它比诸如准确性甚至均方误差之类的其他更严格的度量标准更具动态性,所以使用熵来优化从决策树到深度神经网络的算法已显示出可以提高速度和性能。
It appears everywhere in machine learning: from the construction of decision trees to the training of deep neural networks, entropy is an essential measurement in machine learning.
它在机器学习中无处不在:从决策树的构建到深度神经网络的训练,熵是机器学习中必不可少的度量。
Entropy has roots in physics — it is a measure of disorder, or unpredictability, in a system. For instance, consider two gases in a box: initially, the system has low entropy, in that the two gasses are cleanly separable; after some time, however, the gasses intermingle and the system’s entropy increases. It is said that in an isolated system, the entropy never decreases — the chaos never dims down without external force.
熵源于物理学-它是系统中无序或不可预测性的量度。 例如,在一个盒子里考虑两种气体:一开始,系统的熵很低,因为这两种气体是完全可分离的。 但是,一段时间后,气体混合在一起,系统的熵增加。 有人说,在一个孤立的系统中,熵永远不会减小,没有外力,混沌就不会减弱。
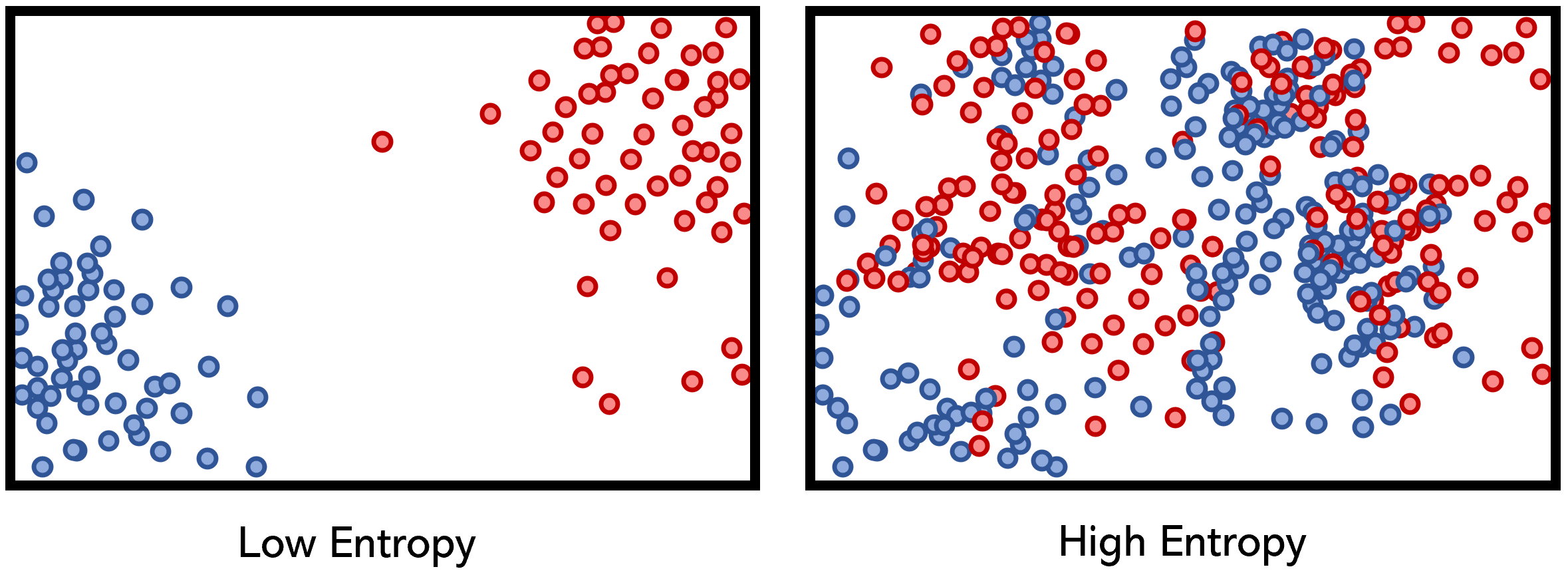
Consider, for example, a coin toss — if the toss the coin four times and the events come up [tails, heads, heads, tails]. If you (or a machine learning algorithm) were to predict the next coin flip, you would be able to predict an outcome with any certainty — the system contains high entropy. On the other hand, a weighted coin with events [tails, tails, tails, tails] has very low entropy, and given the current information, we can almost definitively say that the next outcome will be tails.
例如,考虑掷硬币-如果掷硬币四次而事件出现[tails, heads, heads, tails] 。 如果您(或机器学习算法)要预测下一次硬币翻转,则可以确定地预测结果-系统包含很高的熵。 另一方面,具有事件[tails, tails, tails, tails]的加权硬币的熵极低,并且根据当前信息,我们几乎可以肯定地说下一个结果将是尾巴。
Most scenarios applicable to data science are somewhere between astronomically high and perfectly low entropy. A high entropy means low information gain, and a low entropy means high information gain. Information gain can be thought of as the purity in a system: the amount of clean knowledge available in a system.
适用于数据科学的大多数情况都介于天文学的高熵和极低的熵之间。 高熵意味着低信息增益,低熵意味着高信息增益。 可以将信息获取视为系统中的纯净性:系统中可用的干净知识的数量。
Decision trees use entropy in their construction: in order to be as effective as possible in directing inputs down a series of conditions to a correct outcome, feature splits (conditions) with lower entropy (higher information gain) are placed higher on the tree.
决策树在其构造中使用熵:为了尽可能有效地将一系列条件下的输入定向到正确的结果,将熵较低(信息增益较高)的特征拆分(条件)放在树上较高位置。

To illustrate the idea of low and high-entropy conditions, consider hypothetical features with class marked by color (red or blue) and the split marked by a vertical dashed line.
为了说明低熵条件和高熵条件的概念,请考虑假设的特征,其类别用颜色(红色或蓝色)标记,而拆分用垂直虚线标记。

Decision trees calculate the entropy of features and arranges them such that the total entropy of the model is minimized (and the information gain maximized). Mathematically, this means placing the lowest-entropy condition at the top such that it may assist split nodes below it in decreasing entropy.
决策树计算特征的熵并对其进行排列,以使模型的总熵最小(并使信息增益最大)。 从数学上讲,这意味着将最低熵条件放在顶部,以便它可以帮助降低其下方的拆分节点的熵。
Information gain and relative entropy, used in the training of Decision Trees, are defined as the ‘distance’ between two probability mass distributions p(x) and q(x). It’s also known as Kullback–Leibler (KL) divergence or Earth Mover’s Distance, which is used in the training of Generative Adversarial Networks to evaluate the performance of generated images compared to images in the original dataset.
决策树训练中使用的信息增益和相对熵定义为两个概率质量分布p ( x )和q ( x )之间的“距离”。 它也称为Kullback-Leibler(KL)散度或Earth Mover的距离,用于训练对抗性生成网络以评估生成的图像与原始数据集中的图像相比的性能。

One of the favorite loss functions of neural networks is cross-entropy. Be it categorical, sparse, or binary cross-entropy, the metric is one of the default go-to loss functions for high-performing neural nets. It can also be used for the optimization of almost any classification algorithm, like logistic regression. Like other applications of entropy, such as joint entropy and conditional entropy, cross-entropy is one of many flavors of a rigid definition of entropy fitted for a unique application.
神经网络最喜欢的损失函数之一是交叉熵。 无论是分类的,稀疏的还是二进制的交叉熵,该度量都是高性能神经网络的默认去损失函数之一。 它也可以用于几乎所有分类算法的优化,例如逻辑回归。 像熵的其他应用(例如联合熵和条件熵)一样,交叉熵是对熵进行严格定义的多种口味之一,适合于独特的应用。
Cross-entropy, like Kullback-Lieber Divergence (KLD), also deals with relationships between two distributions p and q, representing the true distribution p and the approximated distribution q. However, KLD measures the relative entropy between two distributions, whereas cross-entropy measures the ‘total entropy’ between the distributions.
像Kullback-Lieber发散(KLD)一样,交叉熵也处理两个分布p和q之间的关系,代表真实分布p和近似分布q 。 但是,KLD度量两个分布之间的相对熵,而交叉熵度量两个分布之间的“总熵”。
The measure is defined as the average number of bits needed to encode data coming from a source with distribution p using model distribution q. If we consider a target distribution p and the approximation q, we would want to reduce the number of bits required to represent an event using q instead of p. On the other hand, relative entropy (KLD) measures the additional number of bits required to represent an event from p in a distribution q.
该度量定义为使用模型分布q 对具有分布p的源中的数据进行编码所需的平均位数。 如果考虑目标分布p和近似值q ,我们希望减少使用q而不是p表示事件所需的位数。 另一方面,相对熵(KLD)衡量从分布q中的 p表示事件所需的额外位数。
Cross-entropy may seem like a round-about way of measuring the performance of a model, but there are several advantages:
交叉熵似乎是衡量模型性能的一种回旋方式,但是有几个优点:
- Accuracy/error-based metrics have several problems, including extreme sensitivity to the order of training data, doesn’t consider confidence, and has a lack of robustness to various attributes of the data that may give faulty results. They are very crude measures of performance (during training, at least). 基于准确性/错误的指标存在多个问题,包括对训练数据顺序的极端敏感性,不考虑置信度,并且对可能导致错误结果的数据的各种属性缺乏鲁棒性。 它们是非常粗略的绩效指标(至少在培训期间)。
- Cross-entropy measures information content, and is hence more dynamic and robust than metrics that simply place a heavy emphasis on ticking all the boxes. Predictions and targets are treated as distributions rather than a list of questions waiting to be answered. 交叉熵可衡量信息内容,因此比简单强调所有复选框的度量标准更具动态性和可靠性。 预测和目标被视为分布,而不是等待回答的问题列表。
- It is closely related to the nature of probability, and works especially well with sigmoid and SoftMax activations (even if they are only used in the last neuron), helping to reduce the vanishing gradient problem. Logistic regression can be considered a version of binary cross-entropy. 它与概率的性质密切相关,并且特别适用于S型和SoftMax激活(即使仅在最后一个神经元中使用),有助于减少消失的梯度问题。 Logistic回归可以视为二进制交叉熵的一种形式。
While entropy is not always the best loss function — especially in cases where the target function p is not clearly defined — it has shown to generally be performance-enhancing, which explains its abundant presence everywhere.
尽管熵并不总是最佳的损失函数(尤其是在目标函数p尚未明确定义的情况下),但熵通常表现为性能增强,这说明了熵在任何地方都存在。
By using entropy in machine learning, the core component of it — uncertainty and probability — is best represented through ideas like cross-entropy, relative-entropy, and information gain. Entropy is explicit about dealing with the unknown, which is something much to be desired in model-building. When models are optimized on entropy, they are able to wander through plains of unpredictability with an elevated sense of knowledge and purpose.
通过在机器学习中使用熵,它的核心组成部分(不确定性和概率)可以通过交叉熵,相对熵和信息增益等思想得到最好的体现。 熵对于处理未知数非常明确,这在模型构建中非常需要。 当模型在熵上得到优化时,它们能够以增强的知识和目标意识在不可预测的平原上徘徊。
熵 机器学习















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









