





创建dqn的深度神经网络
深层钢筋学习介绍— 17 (DEEP REINFORCEMENT LEARNING EXPLAINED — 17)
This is the third post devoted to Deep Q-Network (DQN), in the “Deep Reinforcement Learning Explained” series, in which we show how to use TensorBoard to obtain a graphical view of the performance of the model. We also present a way to see how our trained Agent is able to play Pong.
这是“ 深度强化学习解释 ”系列中的第三篇有关深度Q网络(DQN)的文章,其中我们展示了如何使用TensorBoard获取模型性能的图形视图。 我们还提供了一种方法来查看我们训练有素的特工如何打乒乓球。
The entire code of this post can be found on GitHub (and can be run as a Colab google notebook using this link).
这篇文章的完整代码可以在GitHub上找到 (并且可以使用此链接作为Colab谷歌笔记本运行 )。
运行训练循环 (Running the training loop)
When we run the notebook of this example, we obtain this output in our console:
当运行本示例的笔记本时,我们在控制台中获得以下输出:

. . .
。 。 。
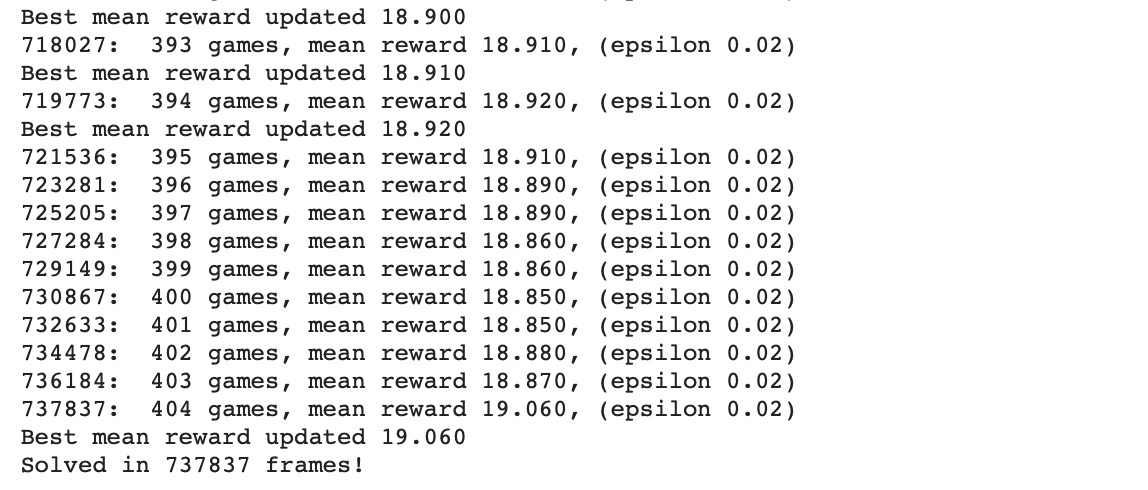
Due to randomness in the training process, your actual dynamics will differ from what is displayed here.
由于训练过程中的随机性,您的实际动态将不同于此处显示的动态。
But, although it is informative, it is difficult to draw conclusions from a million lines. The reader will remember that in the previous post 5 (PyTorch Performance Analysis with TensorBoard) we introduced the tool TensorBoard that helps to follow the progress of different parameters and can represent an excellent support to find the values of the hyperparameters.
但是,尽管它提供了很多信息,但是很难从一百万行得出结论。 读者会记得,在上一篇文章5(使用TensorBoard进行PyTorch性能分析 )中,我们介绍了工具TensorBoard 这有助于跟踪不同参数的进度,并且可以很好地支持查找超参数的值。
We will not repeat here the explanations of what code should be inserted, but the reader can find the detailed code of this example in the GitHub that obtain for the DQN a traces for being plotted in an interactive TensorFlow window as:
我们不会在这里重复说明应该插入什么代码,但是读者可以在GitHub中找到该示例的详细代码,该示例的代码为DQN获得了在交互式TensorFlow窗口中绘制的轨迹,如下所示:
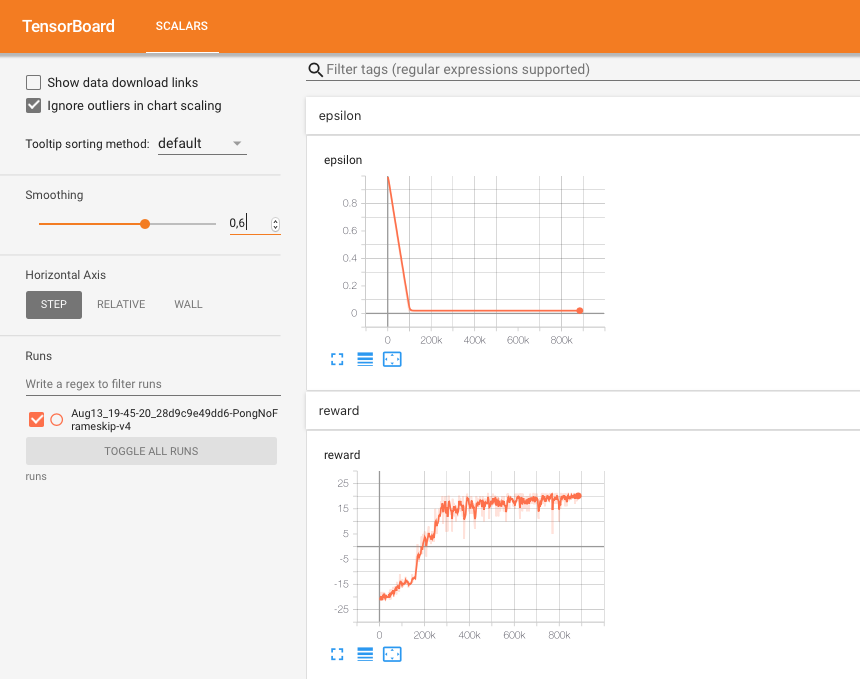
For instance, with this code we obtain traces to monitor the behaviour of the epsilon, reward and the average reward:
例如,使用此代码,我们可以获得跟踪以监控epsilon,奖励和平均奖励的行为的跟踪:
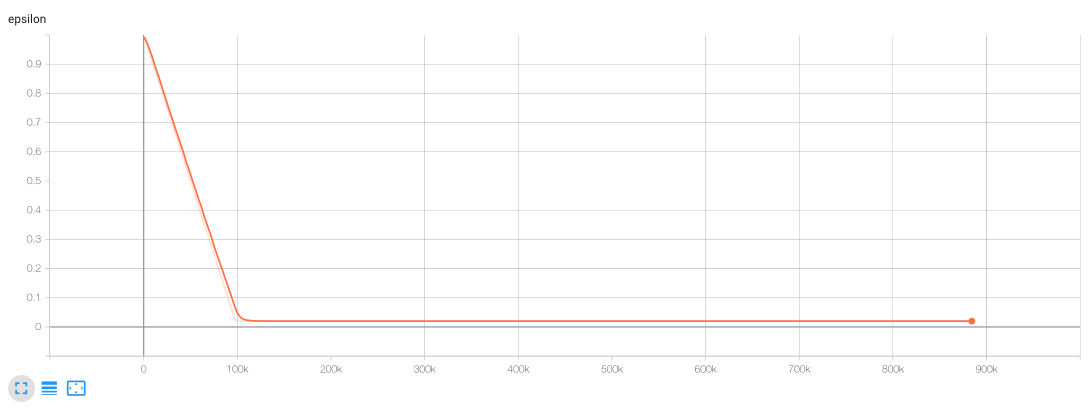
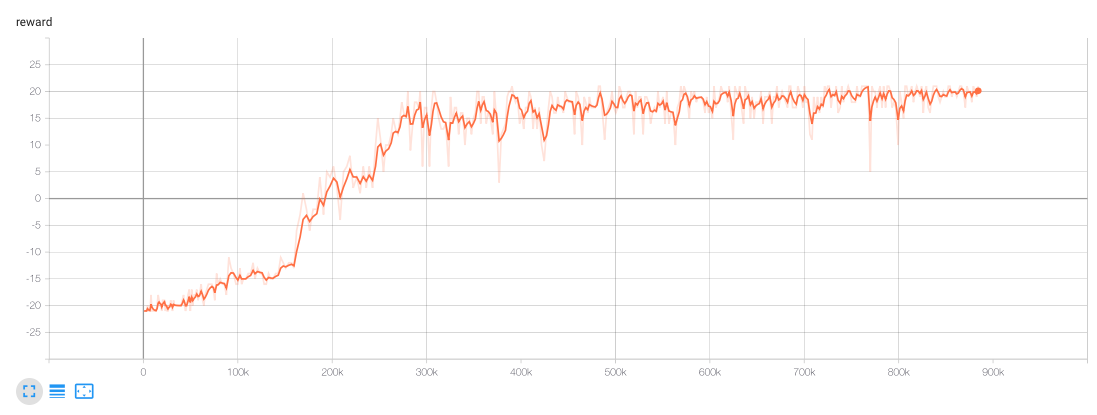
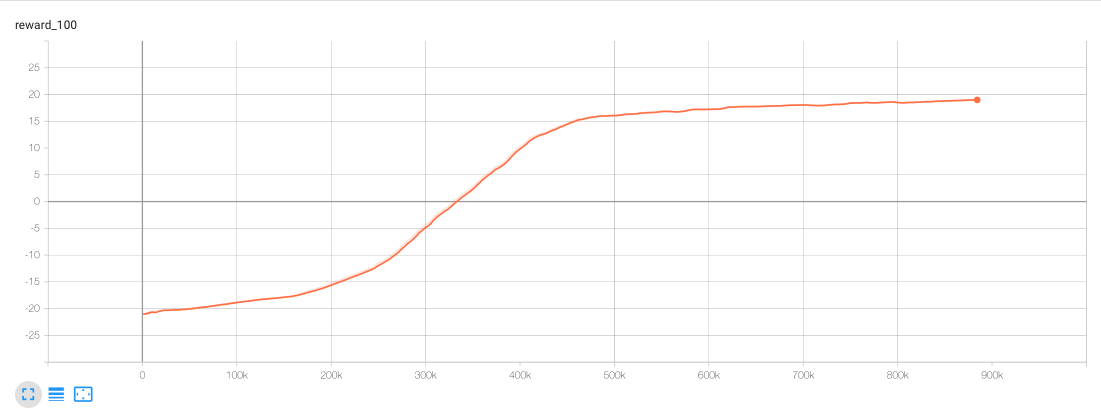
With this tool, I invite the user to find better hyperparameters.
使用此工具,我邀请用户找到更好的超参数。
使用模型 (Using the model)
Finally, in the GitHub the reader could find the code that allows us to see how our trained Agent is able to play Pong:
最后,在GitHub上 ,读者可以找到使我们看到受过训练的Agent如何打Pong的代码:
We have prepared the code that generates a video with one episode of the game. The video is stored in the folder video.
我们已经准备了生成带有游戏一集视频的代码。 视频存储在文件夹video 。
The code is almost an exact copy of the Agent class’ method play_step(), without the epsilon-greedy action selection. We just pass our observation to the agent and select the action with maximum value. The only new thing here is the render() method in the Environment, which is a standard way in Gym to display the current observation.
该代码几乎是Agent类的play_step()方法的精确副本,没有选择epsilon-greedy操作。 我们只是将观察结果传递给代理,然后选择具有最大价值的操作。 这里唯一的新东西是环境中的render()方法,这是Gym中显示当前观察值的标准方法。
The main loop in the code, pass the action to the environment, count the total reward, and stop the loop when the episode ends. After the episode, it shows the total reward and the count of times that the agent executed the action.
代码中的主循环,将动作传递给环境,计算总奖励,并在情节结束时停止循环。 情节结束后,它会显示总奖励以及坐席执行该动作的次数。
Because it is needed to have a graphical user interface (GUI) and we are executing our code in a colab environment, not in our personal computer, we need to run a set of commands (obtained from this link).
因为需要具有图形用户界面(GUI),并且我们正在colab环境中而不是在个人计算机中执行代码,所以我们需要运行一组命令(从此链接获得)。
摘要 (Summary)
This is the third of three posts devoted to present the basics of Deep Q-Network (DQN), in which we present how we can use TensorBoard in order to help us in the process of parameter turning. We also show how we can visualize the behaviour of our Agent. See you in the next post!
这是专门介绍Deep Q-Network(DQN)基础知识的三篇文章中的第三篇,其中我们介绍了如何使用TensorBoard来帮助我们进行参数转换。 我们还将展示如何可视化代理的行为。 下篇再见!
翻译自: https://towardsdatascience.com/deep-q-network-dqn-iii-c5a83b0338d2
创建dqn的深度神经网络















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









