





深度学习计算机视觉的简介
计算机视觉概论 (Introduction to Computer Vision)
What is computer vision? Why is it something worth dedicating time and energy to understanding and applying? How does it work? And what applications could it be useful in the business world? If you have yet to find simple-to-understand answers to these questions, then this blog post is for you.
什么是计算机视觉? 为什么值得花时间和精力去理解和应用呢? 它是如何工作的? 什么样的应用程序在商业世界中可能有用? 如果您还没有找到这些问题的简单易懂的答案,那么此博客文章适合您。
计算机视觉概论 (Introduction to Computer Vision)
什么? (What?)

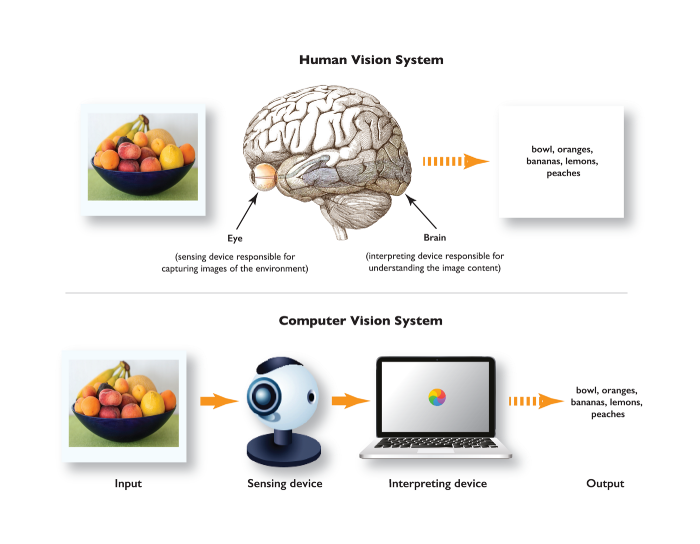
What is computer vision? It is defined as using computers to automatically perform the tasks that the human visual system can do. Where human eyes receive light stimulus from the external environment, computers use digital cameras. Where the brain interprets these sensory inputs, the computer uses an algorithm to interpret the images.
什么是计算机视觉? 定义为使用计算机自动执行人类视觉系统可以完成的任务。 在人眼从外部环境接收光刺激的地方,计算机使用数码相机。 在大脑解释这些感觉输入的地方,计算机使用一种算法来解释图像。
Obtaining accurate images of our physical environment with digital cameras has long been solved with our current technology. And for the most part, assigning meaningful labels to objects in these digital images has also been solved in the past decade. The 2012 edition of the ILSVRC (ImageNet Large Scale Visual Recognition Challenge) [1] challenged research teams from across the world to classify the 1000 object classes from the over one million images in its ImageNet dataset. In that year, a deep learning method took first place for the first time in the image classification task.
长期以来,使用当前的技术已经无法解决使用数码相机获取物理环境的精确图像的问题。 在大多数情况下,在过去的十年中也已经解决了为这些数字图像中的对象分配有意义的标签的问题。 2012年版的ILSVRC(ImageNet大规模视觉识别挑战) [1]挑战了世界各地的研究团队,从其ImageNet数据集中超过一百万个图像中分类了1000个对象类别。 在那一年,深度学习方法在图像分类任务中首次获得了第一名。
This deep learning method, named AlexNet [2] (after the first author, Alex Krizhevsky), was developed by a team from the University of Toronto called SuperVision, and utilized a convolutional neural network (CNN) architecture (more on this later) to obtain a top-5 error (i.e. the percentage of wrong top-5 guesses out of 1000 object classes) of 15.315%, compared to the runner-up method’s top-5 error of 26.172% (which used a classical machine learning approach). As machine learning practitioners like to emphasize over and over ad nauseam, this is a 10.857% reduction in error! By comparison, Andrej Karpathy trained himself to do the image classification task and came up with an informal (and unpublished) error of 5.1%. At that time, ILSVRC 2014’s top-performing method, GoogLeNet [3] had already improved to a top-5 error of 6.7%. And as Karpathy himself noted, his less dedicated and less trained lab mates performed much more poorly. Clearly, not all humans have the patience and training for large-scale pattern recognition:
这种名为AlexNet [2]的深度学习方法(在第一作者Alex Krizhevsky之后)是由多伦多大学一个名为SuperVision的团队开发的,并利用了卷积神经网络(CNN)架构(稍后会详细介绍)获得亚军方法的前5名错误为26.172%(使用经典机器学习方法),则前5名错误(即1000个对象类别中前5名猜测错误的百分比)为15.315%。 就像机器学习从业人员一遍又一遍地强调广告恶心一样 ,这减少了10.857%的错误! 相比之下,Andrej Karpathy 训练自己可以完成图像分类任务,并得出了5.1%的非正式(且未出版)错误。 那时,ILSVRC 2014的最佳方法GoogLeNet [3]已经提高到了前5个错误,误差为6.7%。 而且,正如Karpathy本人指出的那样,他的专心致志,训练有素的实验室伙伴的表现要差得多。 显然,并非所有人都对大型模式识别有耐心和训练:
It was still too hard — people kept missing categories and getting up to ranges of 13–15% error rates.
这仍然太难了–人们一直缺少类别,错误率上升到13-15%的范围。
Does this mean that computers are now able to “see” as well as humans can? No, not necessarily.
这是否意味着计算机现在能够像人类一样“看见”? 不,不一定。
In 2015, researchers discovered that many state-of-the-art computer vision models are prone to maliciously-designed high-frequency patterns known as “adversarial attacks” [4], which trick the models into modifying their predictions without being visible to humans.
2015年,研究人员发现,许多最新的计算机视觉模型都容易受到恶意设计的高频模式的攻击 ,这些模式被称为“ 对抗性攻击 ” [4],从而诱骗模型修改其预测而人类看不见。
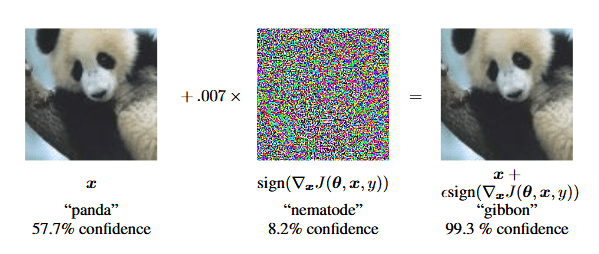
Here’s another humorous example of how adversarial attacks can fool computer vision algorithms. Researchers from MIT developed a special pattern that they placed on a toy turtle specially developed to fool the network into predicting a “rifle”.
这是另一个对抗性攻击如何欺骗计算机视觉算法的幽默示例。 麻省理工学院的研究人员开发了一种特殊的图案,将它们放在专门设计的玩具乌龟上,以欺骗网络以预测“步枪”。

为什么? (Why?)
Ok, but adversarial attacks but highly-specialized researchers aside, why should we care about computer vision? Well, for the same reason that Andrej Karpathy identified — training humans to do fine-grained, large-scale visual recognition requires significant training, dedication, and time. At the end of the day, there will still be human error. From Karpathy’s single experience in competing against computational methods in ILSVRC, he had already dispensed with the idea of:
好的,但是除了对抗性攻击之外,还有高度专业化的研究人员, 为什么我们还要关心计算机视觉? 好吧,出于与Andrej Karpathy相同的原因-训练人类进行细粒度的大规模视觉识别需要大量的训练,奉献精神和时间。 最终,仍然会有人为错误。 根据Karpathy在ILSVRC中与计算方法竞争的单一经验,他已经放弃了以下想法:
- Out-sourcing the task to multiple individuals for money (i.e. to paid undergrads or paid labellers on Amazon Mechanical Turk) 将任务外包给多个人以赚钱(例如,将其外包给Amazon Mechanical Turk上的付费本科生或付费贴标商)
- Out-sourcing the task to unpaid fellow academic researchers 将任务外包给无薪的学术研究人员
In the end, Karpathy decided to perform all of the task on his own to reduce labelling inconsistencies between human labellers.
最后,Karpathy决定独自执行所有任务,以减少人类贴标机之间的标签不一致问题。
In the end I realized that to get anywhere competitively close to GoogLeNet, it was most efficient if I sat down and went through the painfully long training process and the subsequent careful annotation process myself.
最后,我意识到,要想与GoogLeNet保持竞争关系,我坐下来经历痛苦的漫长的训练过程以及我自己随后的仔细注释过程,这是最有效的。
Karpathy stated that it took him roughly 1 minute to recognize each image for the 1,500 images in the smaller test set. By contrast, modern convolutional neural networks can recognize objects in images in under a second with a decent GPU. If we had to recognize the full test set of 100,000 images? Although developing a computer vision pipeline requires development time and specialized expertise, computers can perform visual recognition more consistently than humans without being fatigued and scale better when needed.
Karpathy表示,他花了大约1分钟的时间才能在较小的测试集中识别出1,500张图像中的每张图像。 相比之下,现代的卷积神经网络可以使用不错的GPU在不到一秒钟的时间内识别图像中的对象。 如果我们必须识别100,000张图像的完整测试集? 尽管开发计算机视觉管道需要开发时间和专业知识,但是计算机可以比人类更一致地执行视觉识别,而不会感到疲劳,并且在需要时可以更好地扩展。
怎么样? (How?)
To a computer, images are 2D arrays of pixel intensities. If the image is black and white, there is one channel per pixel. If the image is colour, there are (usually) three channels per pixel. If the image is from a video, then there is a time component as well. Since arrays are easily manipulated mathematically (cf. linear algebra), we can develop quantitative ways of detecting what is present in the images.
对于计算机,图像是像素强度的2D阵列。 如果图像是黑白图像,则每个像素有一个通道。 如果图像是彩色的,则每个像素通常有三个通道。 如果图像来自视频,则还存在时间分量。 由于数组很容易在数学上进行操作(参见线性代数),因此我们可以开发定量的方法来检测图像中存在的内容。
Hand-tuned Approach
手动调整方法
For example, let’s say we wanted the computer to detect whether a handwritten number in an image is a 0 or a 1. We know that 0’s are curvier than 1’s, so we take the image arrays and fit a line through the strokes. Then, we find the curvature of these lines and pass it through a threshold to determine whether it’s a 0 or a 1.
例如,假设我们希望计算机检测图像中的手写数字是0还是1。我们知道0的曲线比1的曲线更弯曲,因此我们获取图像数组并通过笔划拟合一条线。 然后,我们找到这些线的曲率,并将其通过阈值,以确定它是0还是1。

This is known as the “hand-tuned approach”, because it requires a human operator to develop a rule-based theory of how to detect a given pattern that a computer can understand. It is probably the most obvious way of performing computer vision. But while it works for simple problems like recognizing simple digits and letters, it quickly falls apart once you give it a more complicated image with lighting variations, background, occlusion, and viewpoint variations.
这被称为“手动调整的方法”,因为它要求操作人员开发基于规则的理论,该理论关于如何检测计算机可以理解的给定模式。 这可能是执行计算机视觉的最明显方式。 但是,尽管它可以解决一些简单的问题,例如识别简单的数字和字母,但是一旦给它提供了具有光照变化,背景,遮挡和视点变化的更复杂的图像,它就会Swift瓦解。
Machine Learning Approach
机器学习方法
This is where the “machine learning approach” comes in. Simply put, machine learning is the development of algorithms on a set of labelled training data which will then (hopefully) perform well on a set-aside test set during deployment. In general, the more complicated the data to learn, the more complicated the model also needs to be.
这就是“机器学习方法”的用武之地。简单来说,机器学习是在一组标记的训练数据上开发算法,然后(希望)在部署过程中在预留的测试集上表现良好。 通常,要学习的数据越复杂,模型也就越需要复杂。
For example, say you wanted to detect whether an image contained a dog or a cat. At training time, you get a large collection of images labelled as either dog or cat. You take an algorithm and train it until it can recognize most of these training images well. To check if it still works well on unseen images, you give it new images of dogs and cats and verify how well it performs.
例如,假设您要检测图像中是否包含狗或猫。 在训练时,您会获得大量标有狗或猫的图像集合。 您采用一种算法并对它进行训练,直到它可以很好地识别出大多数训练图像为止。 要检查它在看不见的图像上是否仍能正常工作,请给它提供新的猫狗图像,并验证其性能。

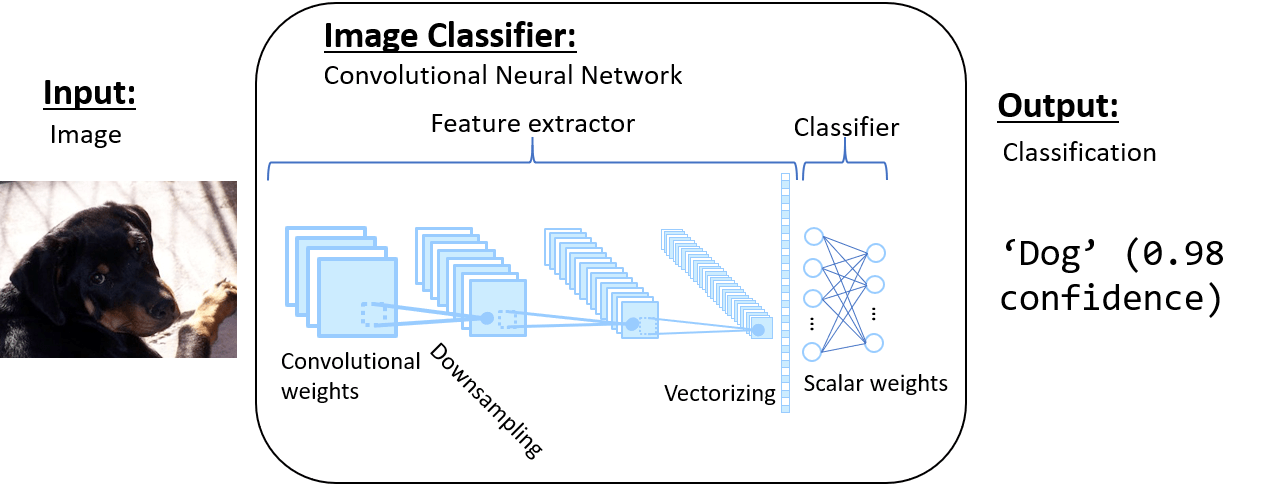
The “boom” in machine learning in recent years is actually a boom in what are known as “deep learning” models. These models use layers of learnable weights to extract features and classify, whereas previous models used hand-tuned features and shallow learnable weights to classify them. As we mentioned before, one of the most fundamental models in computer vision is known as the “convolutional neural network” (CNN or ConvNet for short). These models extract features from the image by repeatedly convolving (think of this as a 2D multiplication) it with 3D weights and downsampling. Then, the features are converted into a 1D vector and multiplied with scalar weights to produce the output classification.
近年来,机器学习的“繁荣”实际上是所谓的“深度学习”模型的繁荣。 这些模型使用可学习权重的层来提取特征并进行分类,而先前的模型使用手动调整的特征和浅可学习的权重来对其进行分类。 如前所述,计算机视觉中最基本的模型之一就是“卷积神经网络”(简称CNN或ConvNet)。 这些模型通过反复对3D权重和下采样进行卷积(将其视为2D乘法)从图像中提取特征。 然后,将要素转换为一维矢量,然后与标量权重相乘以生成输出分类。
(核心)计算机视觉任务 ((Core) Computer Vision Tasks)
Since the human visual system performs many different tasks at the same time and computer vision is supposed to replicate it, there are many ways to break it down into discrete tasks. In general, the core tasks computer vision tries to solve are the following (in order of increasing difficulty):
由于人类视觉系统可以同时执行许多不同的任务,而计算机视觉应该可以复制它,因此有很多方法可以将其分解为离散的任务。 通常,计算机视觉要解决的核心任务如下(以难度递增的顺序):
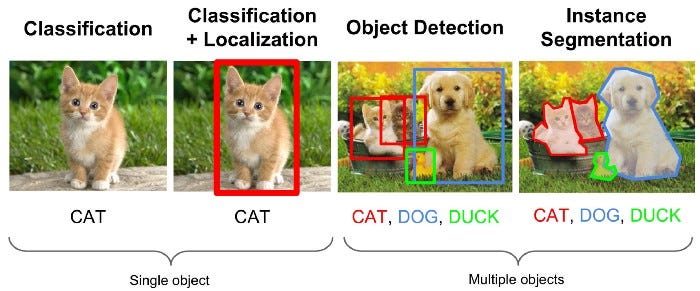
Image Classification: given an image with a single object, predict what object is present (useful for tagging, searching, or indexing images by object, tag, or other attributes)
图像分类 :给定具有单个对象的图像,预测存在的对象(对于按对象,标签或其他属性标记,搜索或索引图像很有用)
Image Localization: given an image with a single object, predict both what object is present and draw a bounding box around it (useful for locating or tracking the appearance or motion of an object)
图像本地化 :给定具有单个对象的图像,预测存在的对象并在其周围绘制一个边框(用于定位或跟踪对象的外观或运动)
Object Detection: given an image with multiple objects, predict both which objects are present and draw a bounding box around each object instance (useful for locating or tracking the appearance or motion of multiple objects)
对象检测:给定具有多个对象的图像,预测两个对象均存在,并在每个对象实例周围绘制一个边界框(用于定位或跟踪多个对象的外观或运动)
Semantic Segmentation (not shown in figure): given an image with multiple objects, predict both which objects are present and predict which pixels belong to each object class (e.g. the cat class) (useful for analyzing the shape of multiple object classes)
语义分割(图中未显示) :给定具有多个对象的图像,预测存在的两个对象并预测属于每个对象类别(例如猫类别)的像素(用于分析多个对象类别的形状)
Instance Segmentation: given an image with multiple objects, predict both which objects are present and predict which pixels belong to each instance (e.g. cat #1 vs. cat #2) of an object class (useful for analyzing the shape of multiple object instances)
实例分割:给定包含多个对象的图像,预测存在的两个对象,并预测哪些像素属于对象类的每个实例(例如Cat#1与Cat#2)(可用于分析多个对象实例的形状)
可用的数据集和模型 (Available Datasets and Models)
Just as ILSVRC provided already-annotated data (ImageNet) to objectively compare algorithms from different researchers, the competing researchers in turn released their models to back up their claims and promote further research. This culture of open collaboration means that many state-of-the-art datasets and models are openly available to the general public for use and the top models can be readily applied without even requiring re-training.
正如ILSVRC提供已注释数据(ImageNet)来客观比较不同研究人员的算法一样,竞争研究人员又发布了他们的模型以支持其主张并促进进一步的研究。 这种开放式协作的文化意味着许多最新的数据集和模型可供公众公开使用,并且顶级模型可以容易地应用,甚至不需要重新培训。
Of course, if the objects one needs to recognize are not covered under “tape_player” and “grey_whale” (perhaps “machine_1” or “door_7”), it will be necessary to collect custom data and annotations. But in most cases, the state-of-the-art models can simply be retrained with the new data and still perform well.
当然,如果“ tape_player”和“ grey_whale”(也许是“ machine_1”或“ door_7”)未涵盖需要识别的对象,则有必要收集自定义数据和注释。 但是在大多数情况下,可以使用新数据简单地对最新模型进行重新训练,并且仍然可以保持良好的性能。
图像分类(单个标签) (Image Classification (single label))
Dataset: ImageNet (e.g. tape_player, grey_whale)
数据集: ImageNet (例如tape_player,grey_whale)
Annotated Sample Image:
带注释的样本图像:

State-of-the-Art Model (with Code): FixEfficientNet-L2 (2020), top-1 accuracy=88.5%
最先进的模型(带代码) : FixEfficientNet-L2(2020) ,top-1精度= 88.5%
对象本地化(多个边界框) (Object Localization (multiple bounding boxes))
Dataset: KITTI Cars (e.g. car bounding boxes, orientation)
数据集: KITTI汽车 (例如汽车边界框,方向)
Annotated Sample Image:
带注释的样本图像:

State-of-the-Art Model (with Code): Frustum PointNets (2017), AP=84.00%
最先进的模型(带代码) : Frustum PointNets(2017) ,AP = 84.00%
语义细分(多个类别细分) (Semantic Segmentation (multiple class segments))
Dataset: PASCAL Context (e.g. grass, table)
数据集: PASCAL上下文 (例如草,表)
Annotated Sample Image:
带注释的样本图像:

State-of-the-Art Model (with Code): ResNeSt-269 (2020), mIoU=58.9%
最新模型(含编码) : ResNeSt-269(2020) ,mIoU = 58.9%
实例细分(多个实例细分) (Instance Segmentation (multiple instance segments))
Dataset: CityScapes (e.g. road, person)
数据集: CityScapes (例如道路,人)
Annotated Sample Image:
带注释的样本图像:

State-of-the-Art Model (with Code): EfficientPS (2019), AP=39.1%
最新模型(含代码) : EfficientPS(2019) ,AP = 39.1%
可能的业务用例 (Possible Business Use-Cases)
Now that we have gone through what computer vision is, why it is useful, and how it is performed, what are some potential applications for businesses? Unlike text or database records, images are typically not well catalogued and stored by companies. However, we believe that certain companies in specialized fields would have the data and motivation to benefit from using computer vision to extract extra value from their stored image data.
现在,我们已经了解了什么是计算机视觉,它为何有用以及如何执行,对于企业来说有哪些潜在应用程序? 与文本或数据库记录不同,图像通常不被公司很好地分类和存储。 但是,我们相信,某些专业领域的公司将有数据和动力,可以从使用计算机视觉从其存储的图像数据中提取额外的价值中受益。
产业 (Industrial)
The first field is the manufacturing, resource extraction, and construction industry. These companies typically work on manufacturing products, extracting resources, or constructing civil works in large quantities and many of the monitoring or predictive analytics are done manually or with simple analytical techniques. However, we think that computer vision would be useful for automating the following tasks:
第一个领域是制造业,资源开采和建筑业。 这些公司通常会大量生产产品,开采资源或建造土建工程,并且许多监视或预测分析是手动完成的或使用简单的分析技术完成的。 但是,我们认为计算机视觉对于自动化以下任务会很有用:
Defect detection, quality control: by learning the appearance of normal products, a computer vision system could flag a machine operator once it detects a likely defect (e.g. Ai Maker, from AiBuild)
缺陷检测,质量控制 :通过学习正常产品的外观,计算机视觉系统可以在机器操作员检测到可能的缺陷时对其进行标记(例如,来自AiBuild的Ai Maker)

Predictive maintenance: by learning the appearance of a given machinery near the end of its operational life, a computer vision system could monitor the machinery in real time, quantify its state (e.g. 90% strength), and forecast when it will need maintenance
预测性维护 :通过了解给定机械在其使用寿命即将结束时的外观,计算机视觉系统可以实时监视机械,量化其状态(例如强度为90%)并预测何时需要维护
Remote measurement: by learning to draw a bounding box around an object of interest (e.g. a crack in a material), a computer vision system could determine the real-world size of that object
远程测量 :通过学习在感兴趣的对象(例如,材料中的裂缝)周围画一个边界框,计算机视觉系统可以确定该对象的实际大小
Robotics: by learning to recognize objects in its field of view, a computer vision system embedded inside a robot could learn to manipulate objects (e.g. in a factory) or navigate its environment
机器人技术 :通过学习识别其视野中的物体,嵌入机器人内部的计算机视觉系统可以学习操纵物体(例如在工厂中)或导航其环境
医疗类 (Medical)
The medical field is a similar field that could benefit from computer vision, since much of the work centres around monitoring and measuring the physical state of human patients (instead of machinery or manufactured products).
医学领域是可以从计算机视觉中受益的类似领域,因为许多工作集中在监视和测量人类患者的身体状况(而不是机械或制成品)上。
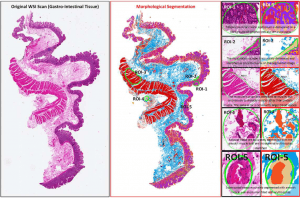
Medical diagnostic aids: by learning the appearance of tissues of diagnostic interest to doctors, a computer vision system could suggest relevant regions and speed up diagnosis (e.g. segmenting histological tissue types from pathology slides with HistoSegNet)
医学诊断辅助工具 :通过学习医生感兴趣的诊断组织的外观,计算机视觉系统可以建议相关区域并加快诊断速度(例如,使用HistoSegNet从病理切片中分割组织学类型)
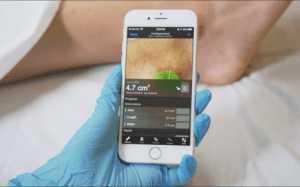
Remote measurement: again, by learning to draw a bounding box around an object of interest (e.g. a lesion), a computer vision system could determine the real-world size of that object for monitoring a patient’s progression over time (e.g. Swift Skin and Wound, from Swift Medical)
远程测量 :同样,通过学习在感兴趣的对象(例如病变)周围绘制边界框,计算机视觉系统可以确定该对象的实际大小,以监视患者随时间的进展(例如,Swift Skin和Wound (来自Swift Medical)
文件和多媒体 (Documents and Multimedia)
Documents and multimedia are another field that could benefit from computer vision because of the vast quantity of unstructured (and un-annotated) information that most companies hold in the form of scanned documents, images, and videos. Although most companies tend not to label these images, some might have useful tags that could be exploited (e.g. an online retail store’s product information).
文档和多媒体是可以从计算机视觉中受益的另一个领域,因为大多数公司以扫描的文档,图像和视频的形式保存大量的非结构化(和未注释)信息。 尽管大多数公司倾向于不标记这些图像,但有些公司可能具有可以被利用的有用标签(例如,在线零售商店的产品信息)。
Optical Character Recognition (OCR): scanned documents can have their text recognized and extracted for further processing
光学字符识别(OCR) :可以识别并提取扫描文档的文本以进行进一步处理
Image search engine: images can be used to search for other images (e.g. for an online retail website, search for visually-similar products or stylistically-similar products to the most recently purchased product)
图像搜索引擎 :图像可用于搜索其他图像(例如,用于在线零售网站,搜索与最近购买的产品类似的视觉相似产品或造型相似产品)
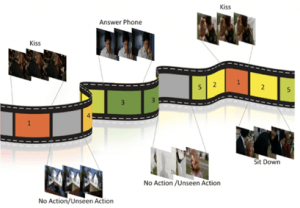
Visual Question Answering (VQA): users can ask the computer vision system questions about the scene depicted in an image and receive a human-language response — this is important for video captioning (e.g. “What is Bob doing on the ground?” > “Bob is sleeping on the ground.”)
视觉问题解答(VQA) :用户可以向计算机视觉系统询问有关图像中描绘的场景的问题,并接收人为语言的响应-这对于视频字幕很重要(例如“鲍勃在地面上做什么?”>“鲍勃在地上睡觉。”)

Video summarization: a computer vision system can summarize the events in a video and return a concise summary — this is important for automatically generating video descriptions (e.g. “A man is giving a talk to a crowd of listeners before being interrupted by a dog that runs in.”)
视频摘要 :计算机视觉系统可以总结视频中的事件并返回简明摘要-这对于自动生成视频描述非常重要(例如,“一个人在被奔跑的狗打断之前先向一群听众讲话)在。”)
零售和监视 (Retail and Surveillance)
Retail (which we touched on in previously) and surveillance are other fields that could benefit from computer vision. They rely on monitoring human actors and their behaviour in real time to optimize a desired outcome (e.g. purchasing behaviour, illegal behaviour). If the behaviour can be observed visually, computer vision can be a good solution.
零售(我们之前已经提到过)和监控是可以从计算机视觉中受益的其他领域。 他们依靠实时监控人类行为者及其行为来优化所需的结果(例如购买行为,非法行为)。 如果可以从视觉上观察到该行为,则计算机视觉可以是一个很好的解决方案。
Human Activity Recognition: a computer vision system can be trained to identify a human’s current activity in a video feed (e.g. walking, sitting), which can be useful for quantifying the number of people sitting in a crowd or identifying crowd flow bottlenecks
人类活动识别 :可以训练计算机视觉系统来识别视频馈送中人类当前的活动(例如,步行,坐着),这对于量化人群中坐拥的人数或识别人群流量瓶颈很有用
Human Pose Estimation: a computer vision system can also be trained to localize the position and orientation of a human’s joints, which can be useful for virtual reality interactions, gesture control, or analyzing a person’s motions for medical or sports purposes
人体姿势估计 :还可以训练计算机视觉系统来定位人体关节的位置和方向,这对于虚拟现实交互,手势控制或出于医疗或体育目的分析人的动作非常有用
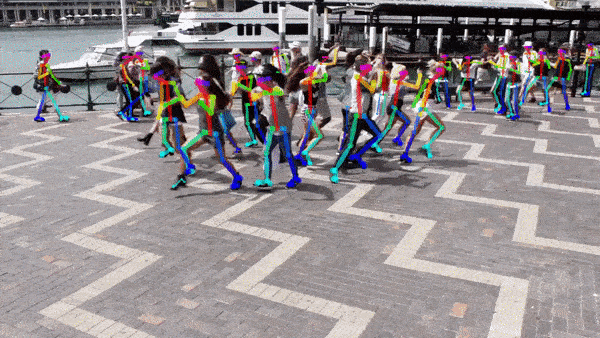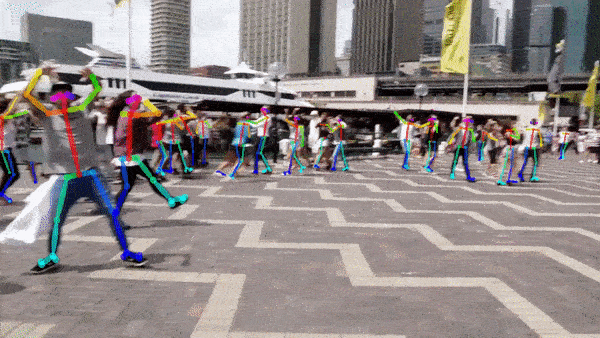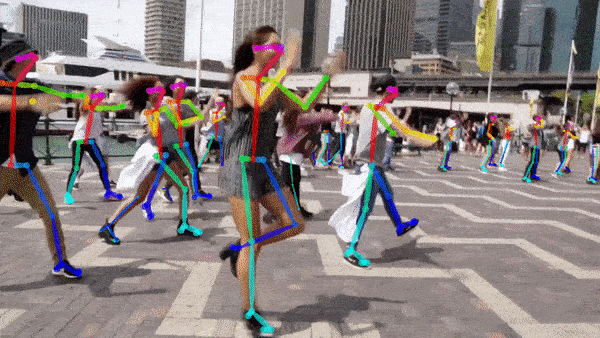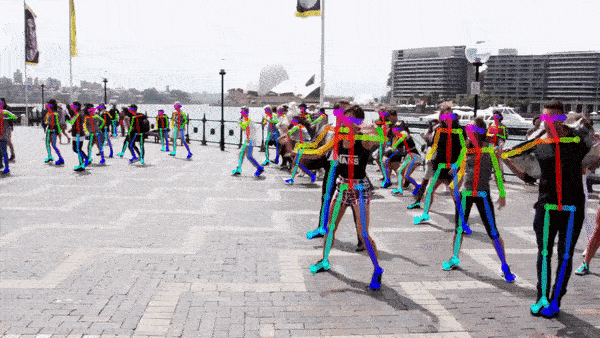
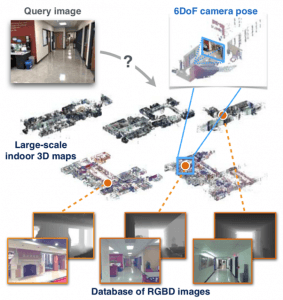
Indoor Visual Localization: a computer vision system can be used to match a current real-time image or video feed of an indoor environment with a database of known snapshots and locate the current user’s position in that indoor environment (e.g. a user takes a picture in a university campus and an app shows them where they are)
室内视觉本地化 :计算机视觉系统可用于将室内环境的当前实时图像或视频馈送与已知快照的数据库进行匹配,并在该室内环境中定位当前用户的位置(例如,用户在室内拍照)大学校园,并有一个应用显示他们所在的位置)
卫星影像 (Satellite Imagery)
Satellite imagery is the final field that we could see computer vision being useful, since it is often used to monitor land use and environmental changes over time through tedious manual annotation by experts. If trained well, computer vision systems could speed up real-time analysis of satellite imagery and assess which regions are affected by natural disasters or human activity.
卫星图像是我们可以看到计算机视觉有用的最后领域,因为它经常被用于通过专家繁琐的手动注释来监视土地使用和环境随时间的变化。 如果训练有素,计算机视觉系统可以加快对卫星图像的实时分析,并评估哪些地区受到自然灾害或人类活动的影响。
Ship/Wildlife Tracking: from satellite imagery or a port or wildlife reserve, a computer vision system could quickly count and locate ships and wildlife without needing tedious human annotation and tracking
船舶/野生生物跟踪 :从卫星图像或港口或野生生物保护区中,计算机视觉系统可以快速计数和定位船舶和野生生物,而无需繁琐的人工注释和跟踪


Crop/Livestock Monitoring: a computer vision system could also monitor the state of agricultural land (e.g. by locating diseased or low-yield areas) to optimize the allocation of pesticide use and irrigation
作物/牲畜监测 :计算机视觉系统还可以监测农业用地的状况(例如,通过定位患病或低产地区)来优化农药使用和灌溉的分配
实际考虑 (Practical Considerations)
You see, computer vision has lots of exciting applications for businesses. However, before jumping on the bandwagon, businesses should first consider the following:
您会看到,计算机视觉为企业带来了许多激动人心的应用程序。 但是,在加入潮流之前,企业应该首先考虑以下几点:
Data: do you source the image data from a third-party, from a vendor, or collect it yourself? Most digital data is either unusable or not analyzed
数据 :您是从第三方,供应商处获取图像数据还是自己收集图像数据? 大多数数字数据不可用或未分析
Annotations: do you source the annotations from a third-party, from a vendor, or collect it yourself?
注释 :您是从第三方,供应商处获取注释还是自己收集注释?
Problem formulation: what sort of problem are you trying to solve? This is where domain expertise will come in handy (e.g. is it enough to detect when a machine is defective (image recognition) or do we also need to locate the defective areas (object detection)?)
问题表述 :您要解决什么样的问题? 这是领域专业知识将派上用场的地方(例如,足以检测机器何时有缺陷(图像识别),还是我们还需要定位缺陷区域(对象检测)?)
Transfer learning: can pre-trained models already do the job well enough (if so, there is less research and development work required)?
转移学习 :预训练的模型是否已经可以很好地完成工作(如果是,则需要较少的研发工作)?
Computational resources: do you have enough computing power for training/inference (computer vision models typically need cloud computing or powerful, local GPUs)?
计算资源 :您是否有足够的计算能力用于训练/推理(计算机视觉模型通常需要云计算或强大的本地GPU )?
Human resources: do you have enough time or expertise to implement the models (computer vision typically needs machine learning engineers, data scientists, or research scientists with graduate-level education and enough working hours to dedicate themselves to working on research problems)?
人力资源 :您是否有足够的时间或专业知识来实施模型(计算机视觉通常需要机器学习工程师,数据科学家或具有研究生教育水平且工作时间专用于研究问题的研究科学家)?
Trust issues: does the end-user / customer trust the computer vision approach? Good relationships must be established and explainability methods implemented to ensure transparency and accountability, which in turn promote higher user acceptance
信任问题 :最终用户/客户是否信任计算机视觉方法? 必须建立良好的关系,并采用可解释性的方法来确保透明度和问责制,从而促进更高的用户接受度
深度学习计算机视觉的简介















 7262
7262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









