






机器学习中的分类(Classification in Machine Learning)
Classification is a process of categorizing a given set of data into classes. The process starts with predicting the class of given data points where the classes can be referred to as target, label, or categories.
分类是将给定数据集分类为类的过程。 该过程从预测给定数据点的类别开始,其中这些类别可以称为目标,标签或类别。
Classification can be performed on both structured or unstructured data. The main goal of classification is to identify which class/category the new data will fall into and is best used when the output has finite and discrete values.
分类可以在结构化或非结构化数据上执行。 分类的主要目标是确定新数据将属于哪个类别/类别,并在输出具有有限值和离散值时最好使用。
The different types of classification algorithms are —
分类算法的不同类型是-
Linear Models
线性模型
- Logistic Regression逻辑回归
- Support Vector Machines (SVM)支持向量机(SVM)
Nonlinear models
非线性模型
- K-nearest Neighbors (KNN)K近邻(KNN)
- Kernel Support Vector Machines (SVM) 内核支持向量机(SVM)
- Naïve Bayes 朴素贝叶斯
- Decision Tree Classification决策树分类
- Random Forest Classification随机森林分类
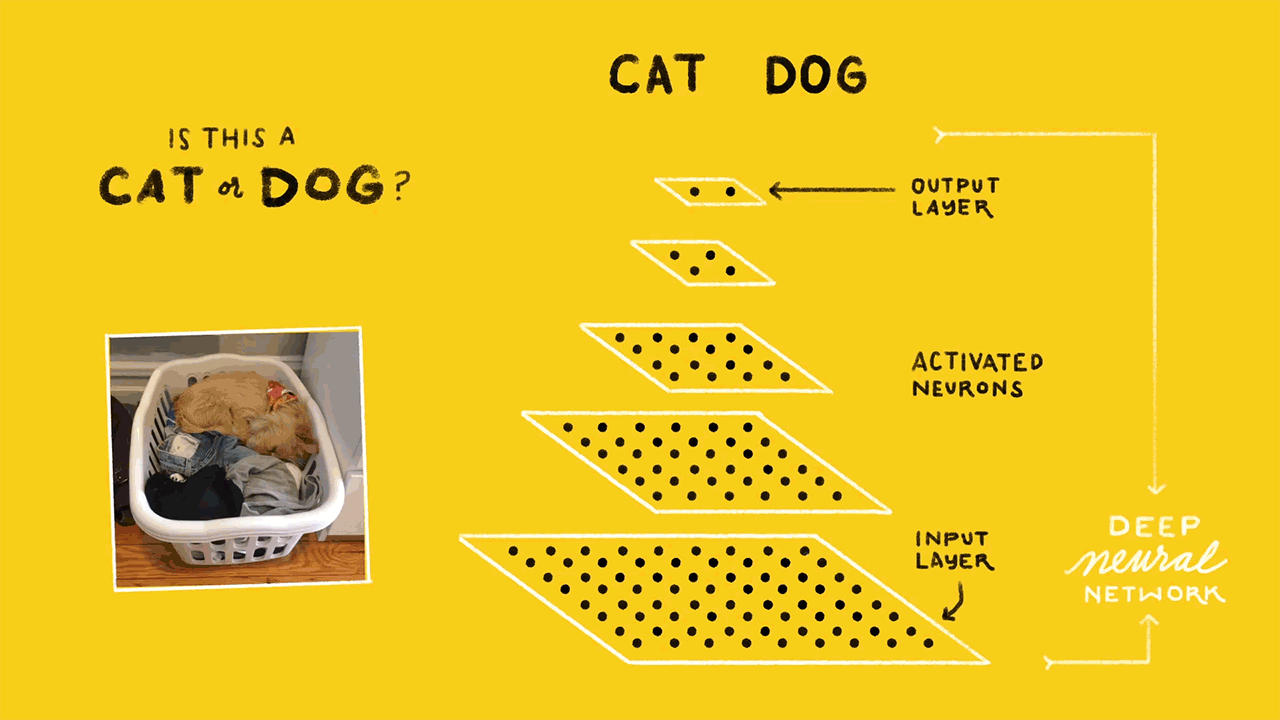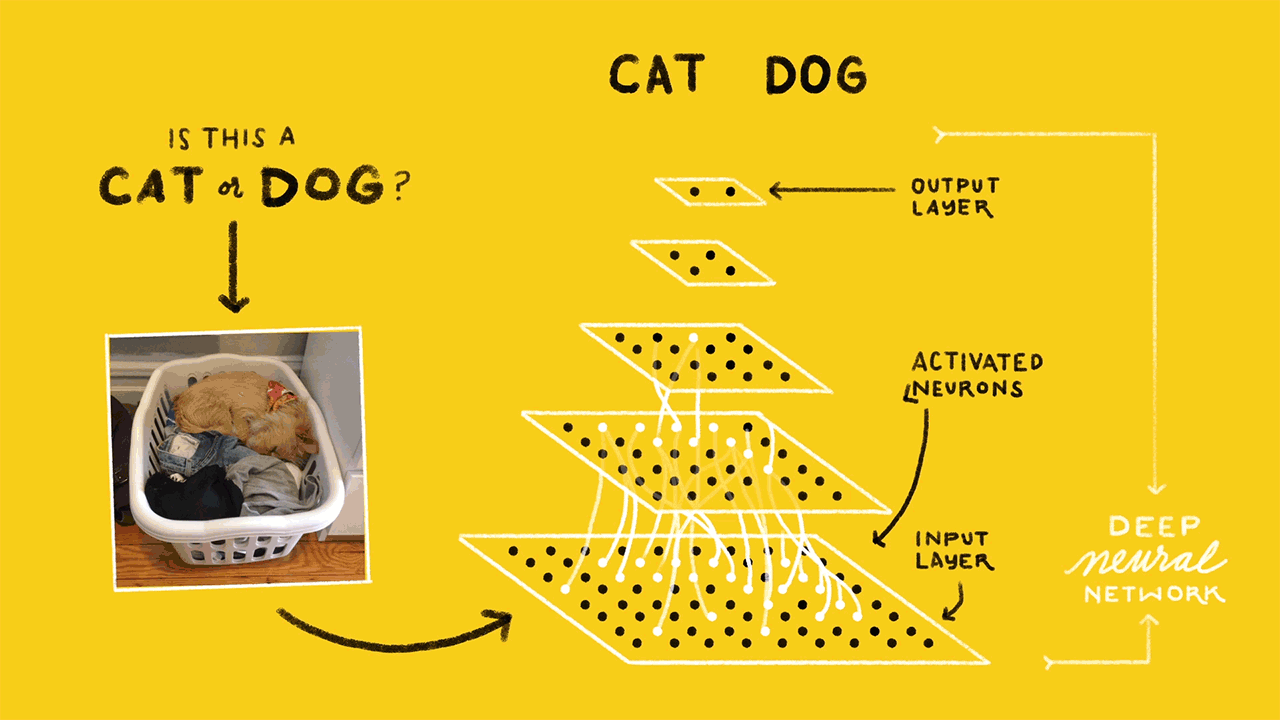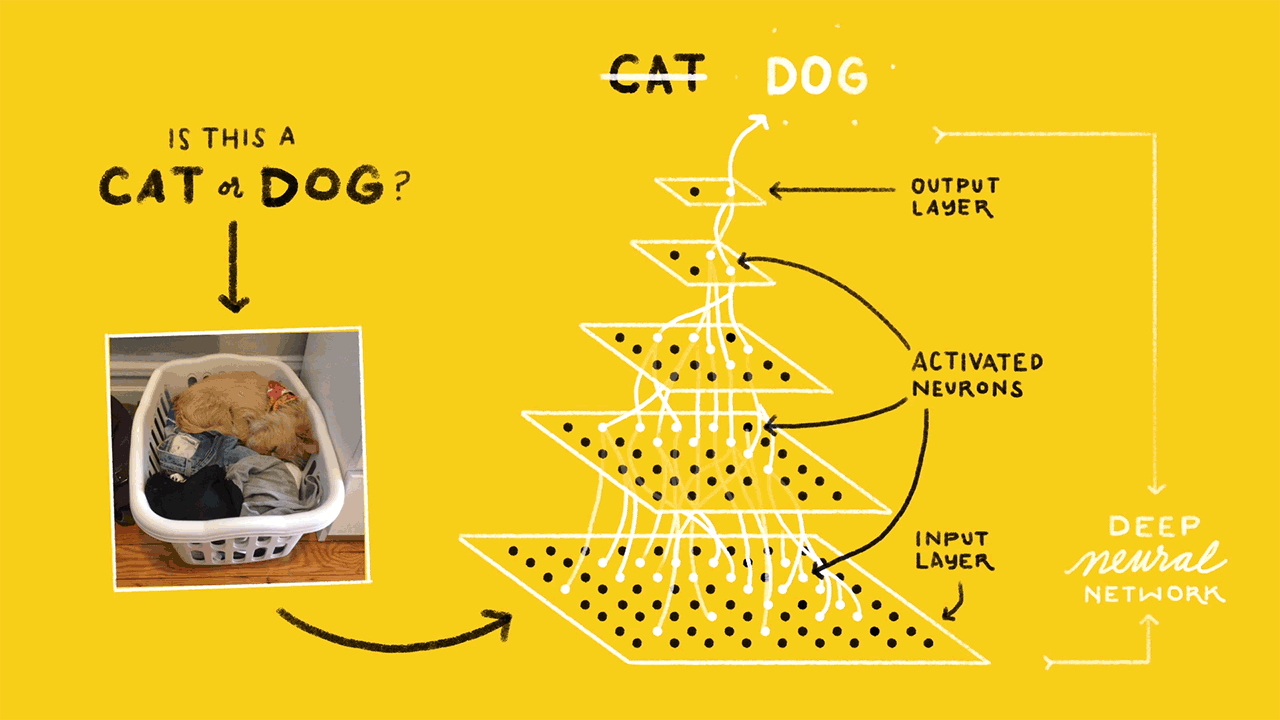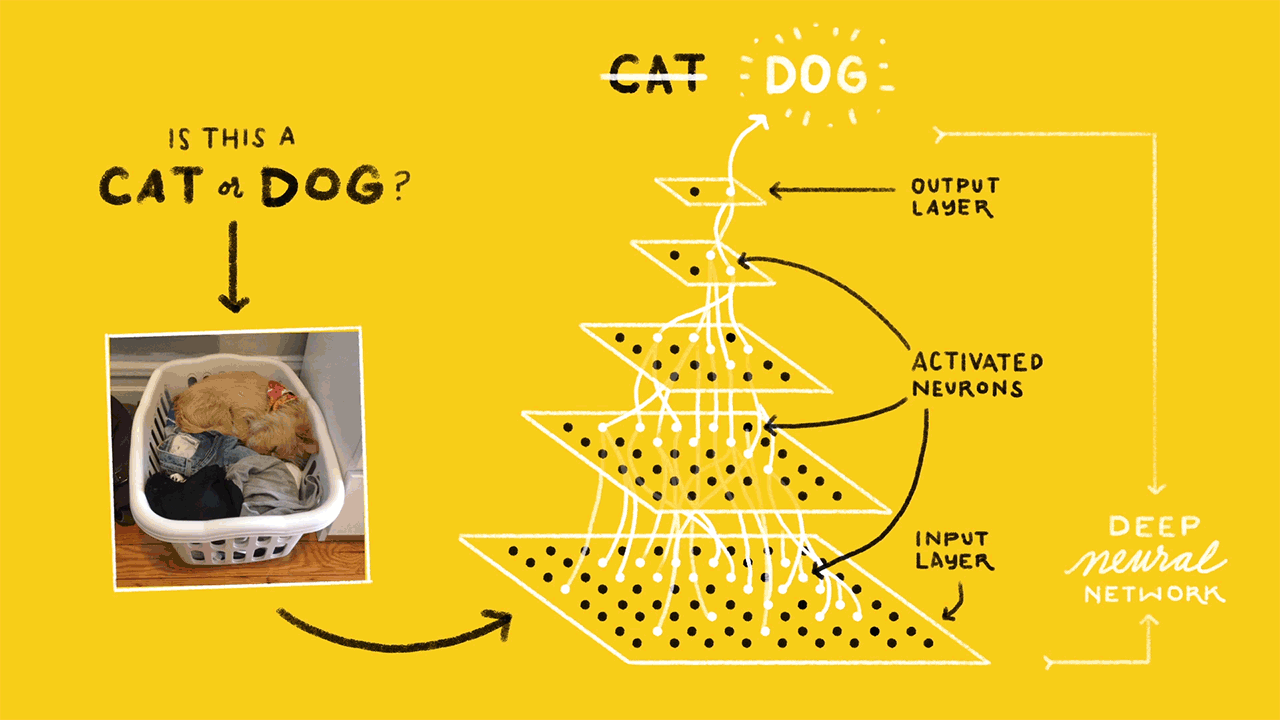
什么是神经网络?(What is a neural network?)
In simple terms, Neural networks are multi-layer networks of neurons designed to recognize patterns. The patterns they recognize are numerical, contained in vectors, into which all real-world data, be it images, sound, text, etc., must be transformed.
简单来说,神经网络是旨在识别模式的多层神经元网络。 他们识别的模式是数字,包含在矢量中,所有真实世界的数据(图像,声音,文本等)都必须转换为矢量。
A simple neural network consists of —
一个简单的神经网络由-
- Input Layer — this layer takes large volumes of data as input to build the neural network 输入层-该层将大量数据作为输入来构建神经网络
- Hidden layer — this layer processes data by performing complex computations and carries out feature extraction隐藏层-该层通过执行复杂的计算来处理数据并进行特征提取
- Output Layer — Using suitable activation functions it generates predicted output输出层-使用适当的激活功能,它可以生成预测的输出
- Arrows — Connect the layers and shows how data travels from the input layer through hidden layers to the output layer.箭头—连接各层,并显示数据如何从输入层通过隐藏层传输到输出层。

什么是张量流? (What is Tensor Flow?)
TensorFlow, developed initially for large numerical computations, is an open-source library developed by Google’s Brain team and written in C++, Python, and CUDA for deep learning and machine learning applications.
TensorFlow最初是为大型数值计算而开发的,是Google的Brain团队开发的开放源代码库,用C ++,Python和CUDA编写,用于深度学习和机器学习应用程序。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









