





便筏已损坏
The most important problem in computer vision is correspondence learning. That is, given two images of an object, how to find the corresponding pixels of the object from the two images?
计算机视觉中最重要的问题是对应学习。 也就是说,给定一个对象的两个图像,如何从两个图像中找到对象的相应像素?
Correspondence learning, mainly for videos, has broad applications in object detection and tracking. Especially when the objects are occluded, color-changed, deformed in a video.
对应学习(主要用于视频)在对象检测和跟踪中具有广泛的应用。 尤其是当对象在视频中被遮挡,变色,变形时。
什么是光流? (What is optical flow?)
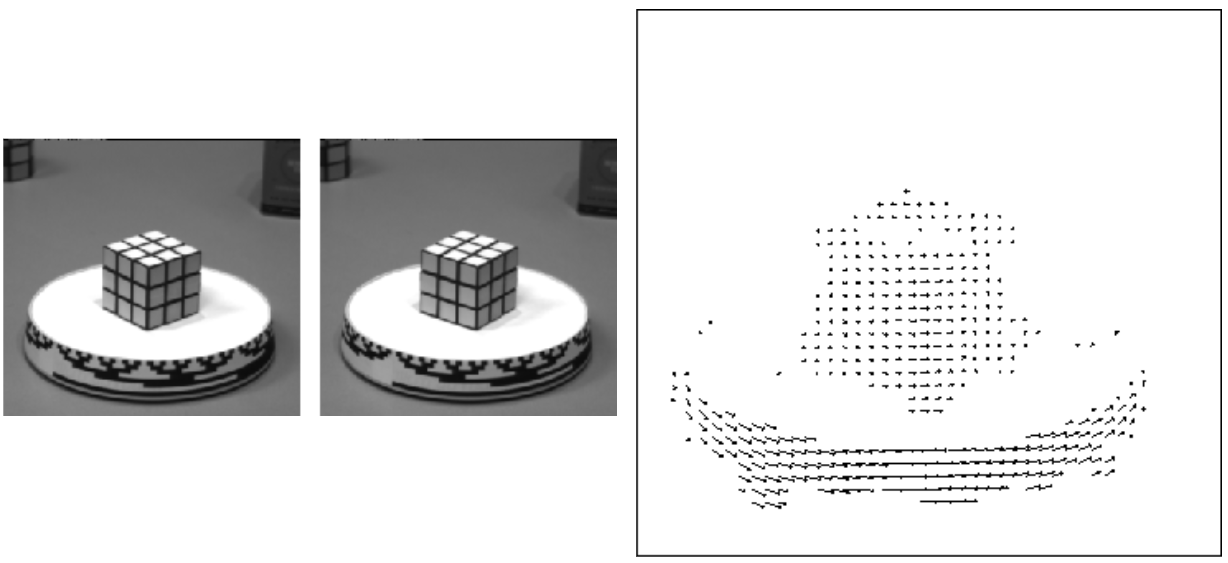
Optical flow is a vector field between two images, showing how the pixels of an object in the first image can be moved to form the same object in the second image. It is a kind of correspondence learning, because if the corresponding pixels of an object are known, the optical flow field can be calculated.
光流是两个图像之间的矢量场,显示了如何移动第一幅图像中某个对象的像素以在第二幅图像中形成同一对象。 这是一种对应学习,因为如果知道对象的相应像素,则可以计算光流场。
光流方程和传统方法 (Optical flow equation & traditional methods)
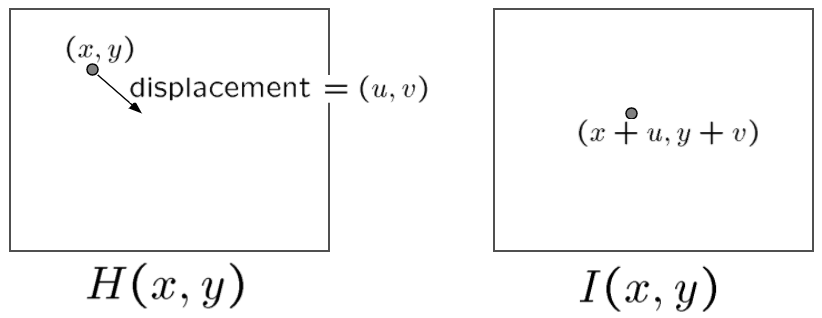
Let ‘s take the most succinct form: one point flow between two images. Imagine a pixel at (x, y) in H flows to (x+u, y+v) in I, the optical flow vector is therefore (u, v).
让我们采取最简洁的形式:两张图片之间的一点流动。 想象一下,H中的(x,y)处的像素流向I中的(x + u,y + v),因此光流矢量为(u,v)。
How to solve for (u, v) ? Is there any constraints for us to build some equations ?
如何解决(u,v)? 我们建立一些方程式是否有任何限制?
Firstly, as H(x, y) = I(x+u, y+v), let ‘s break I(x+u, y+v) using Taylor series:
首先,由于H(x,y)= I(x + u,y + v),让我们使用泰勒级数打破I(x + u,y + v):
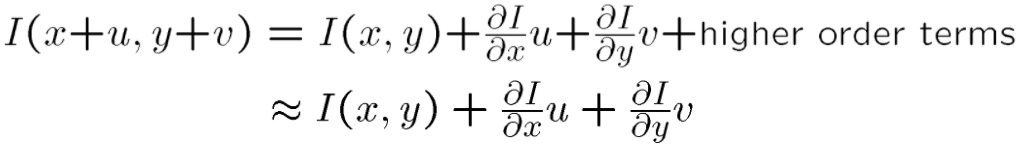
Then, abandon higher order terms and combine with H(x, y) = I(x+u, y+v):
然后,放弃高阶项并与H(x,y)= I(x + u,y + v)结合:
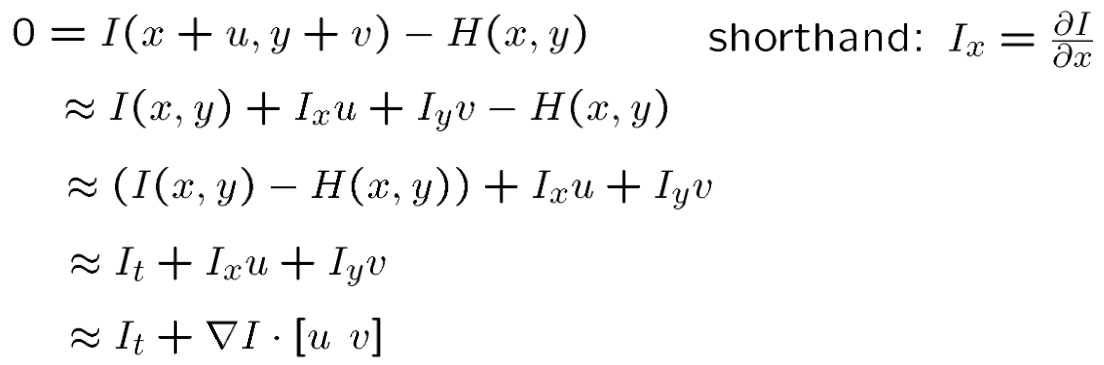
Finally, in the limit as u and v go to zero, we got the optical flow equation as:
最后,在u和v变为零的极限中,我们得到的光流方程为:
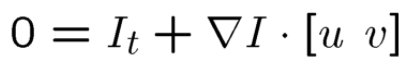
However, in real applications, u and v might be large or small, spanning several to tens of pixels, other than being zero-limit. Thus we can only get an approximation of the real optical flow. However, the flow field would be more accurate if u and v are closer to zero.
但是,在实际应用中,u和v可能会很大,也可能很小,跨越数个像素到数十个像素,而不是零限制。 因此,我们只能得到真实光流的近似值。 但是,如果u和v接近零,则流场将更加准确。
In the above equation, the unknowns are u and v, because other variables can be calculated from differences from x, y and time dimensions. Thus, there are two unknowns in one equation, which cannot be solved. Therefore, in the past 40 years, many researchers tried to provide other set of equations of u, v to make it solvable. Among them, the most famous method is Lucas-Kanade method.
在上面的公式中,未知数是u和v,因为可以根据x,y和时间维的差异来计算其他变量。 因此,一个方程式中有两个未知数,无法解决。 因此,在过去的40年中,许多研究人员试图提供u,v的其他方程组以使其可求解。 其中,最著名的方法是Lucas-Kanade方法。
In deep learning era, can we solve optical flow by deep neural networks ? If we can, what is the point of network designing ?
在深度学习时代,我们可以通过深度神经网络解决光流吗? 如果可以,网络设计的重点是什么?
The answer is yes, and there are works on this area these years, the result is getting better and better. I will introduce a representing work called RAFT, which got the Best paper award of ECCV 2020.
答案是肯定的,这些年来在这方面已有很多工作,结果越来越好。 我将介绍一个名为RAFT的代表性作品,该作品获得了ECCV 2020最佳论文奖。
筏 (RAFT)
RAFT, aka Recurrent All-Pairs Field Transforms, is a deep learning method to solve optical flow iteratively.
RAFT,又名递归全对场变换,是一种深度学习方法,可以迭代地解决光流。
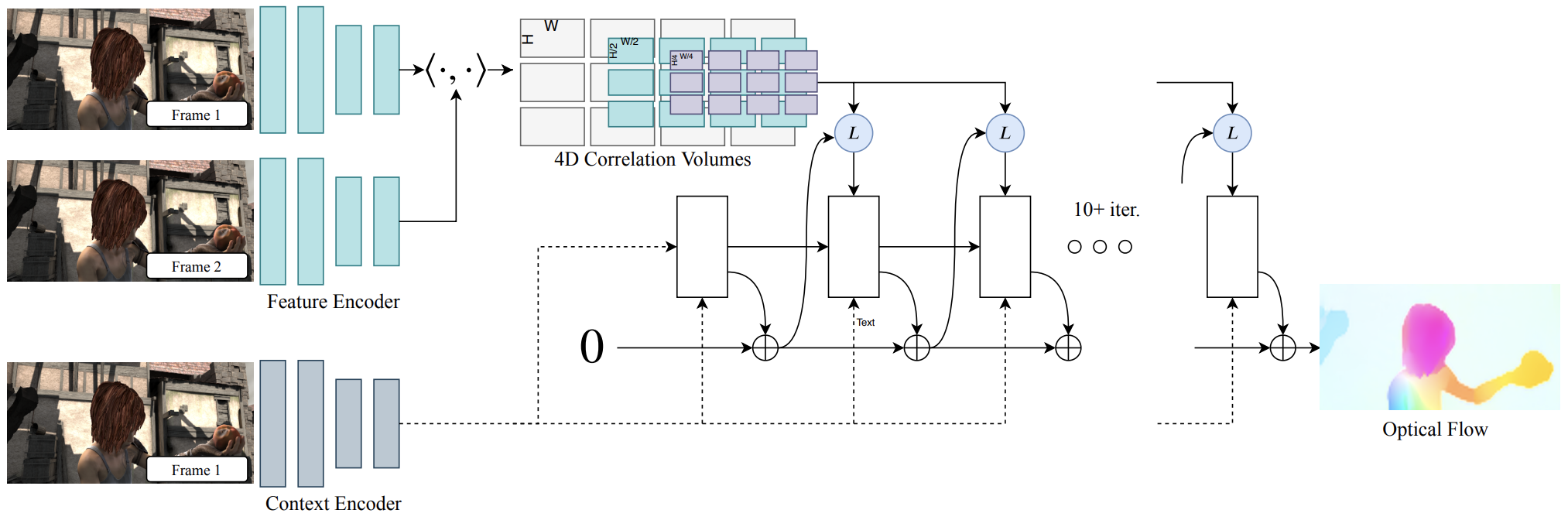
As discussed above, given two images, finding the corresponding pixel pairs of the same objects between them is the core. In deep learning, everything is based on the latent feature maps, which brings efficiency and accuracy. Thus the corresponding pixel pairs could be extracted by correlation field.
如上所述,给定两个图像,找到它们之间相同对象的对应像素对是核心。 在深度学习中,一切都基于潜在特征图,这带来了效率和准确性。 因此,可以通过相关场提取相应的像素对。

Correlation shows the relationship between two pixels from two images. For two images with size (H, W), the size of their correlation field would be (H, W, H, W), which is called C1. If we pool the last two dimensions, we get C2 and C3 etc. For a pixel of image 1, C1 shows the pixel-wise correlation, C2 shows the 2x2-pixel-wise correlation, C3 shows the 4x4-pixel-wise correlation to image 2 etc. This multi-scale manner can help find small to large displacements, which is important for optical flow estimations in videos with large time steps.
相关显示两个图像中两个像素之间的关系。 对于大小为(H,W)的两个图像,其相关字段的大小为(H,W,H,W),称为C1。 如果合并最后两个维度,则得到C2和C3等。对于图像1的像素,C1显示像素相关,C2显示2x2像素相关,C3显示4x4像素相关。图2等。这种多尺度方式可以帮助找到较小或较大的位移,这对于具有较大时间步长的视频中的光流估计非常重要。
For every pixel of image 1, its optical flow is initialized to zero, and its surrounding area in multi-scale correlation maps are looked up to search for its corresponding pixel in image 2. Then the optical flow is estimated between the pixel in image 1 and its searched correspondence pixel in image 2. Finally, the pixel in image 1 is moved according to the estimated optical flow to a new place and the process is repeated until convergence. In this iterative manner, only a step of flow is estimated each time, and the final flow is their summation.
对于图像1的每个像素,将其光流初始化为零,并在多尺度相关图中查找其周围区域,以搜索图像2中其对应的像素。然后在图像1的像素之间估计光流。以及其在图像2中搜索到的对应像素。最后,根据估计的光流将图像1中的像素移动到新位置,并重复该过程直到收敛。 以这种迭代方式,每次仅估计一个流程步骤,而最终流程是它们的总和。
关于RAFT的实施(On the implementation of RAFT)
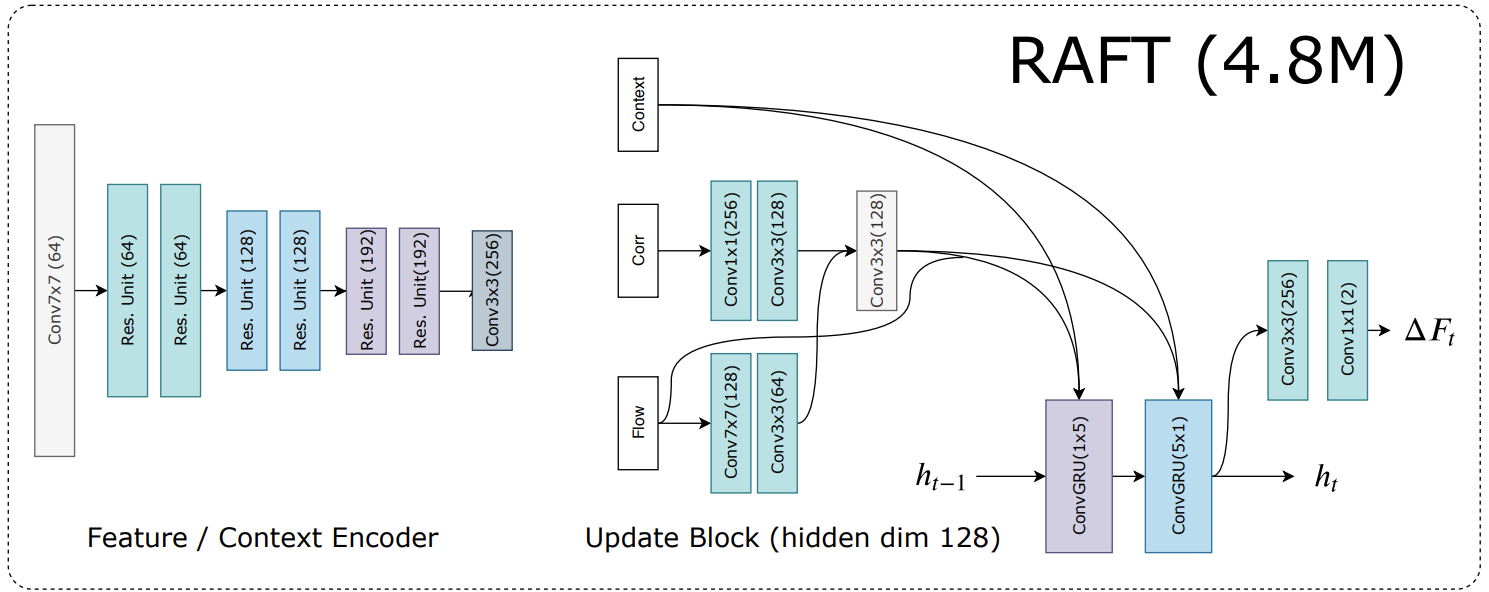
The RAFT model can be separated to two parts: encoder and iterator. Encoder part is similar to those in encoder-decoder networks, which is used to extract latent feature maps of input images. Iterator is implemented as ConvGRU module, which is a kind of RNN structure that can predict a sequence of flow steps and be optimized iteratively, with shared parameters.
RAFT模型可以分为两部分:编码器和迭代器。 编码器部分类似于编码器-解码器网络中的部分,用于提取输入图像的潜在特征图。 迭代器实现为ConvGRU模块,该模块是一种RNN结构,可以预测流步骤序列并使用共享参数进行迭代优化。
Furthermore, norm and activation layers are only used in encoders.
此外,规范层和激活层仅在编码器中使用。
RAFT的预测结果 (Prediction results from RAFT)

I tested the source provided by the authors and the result seems good. I used a video clip with 10 frames. As shown above, the first row is frame 0, the second row is frame 1~9, and the third row is the predicted optical flow between frame 0 and frame 1~9, respectively. The result shows that optical flow between two video frames, with both small and large time intervals and displacements, can be predicted smoothly.
我测试了作者提供的源,结果似乎很好。 我使用了一个10帧的视频剪辑。 如上所示,第一行是帧0,第二行是帧1〜9,第三行分别是帧0和帧1〜9之间的预测光流。 结果表明,可以平稳地预测两个视频帧之间的光流,无论时间间隔和位移都小而大。
翻译自: https://medium.com/@dushuchen/understanding-optical-flow-raft-accb38132fba
便筏已损坏














 2527
2527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









