






Have you ever wondered how a machine translates language? Or how voice assistants respond to questions? Or how mail gets automatically classified into spam or not spam?
您是否想过机器如何翻译语言? 还是语音助手如何回答问题? 或者如何将邮件自动分类为垃圾邮件?
All these tasks are done through Natural Language Processing (NLP), which processes text into useful insights that can be applied to future data. In the field of artificial intelligence, NLP is one of the most complex areas of research due to the fact that text data is contextual. It needs modification to make it machine-interpretable, and requires multiple stages of processing for feature extraction.
所有这些任务都通过自然语言处理(NLP)完成,该处理将文本处理为有用的见解 , 这些见解可应用于将来的数据。 在人工智能领域,由于文本数据是上下文相关的,因此NLP是最复杂的研究领域之一。 它需要进行修改以使其可以机器解释,并且需要多个处理阶段才能进行特征提取。
Classification problems can be broadly split into two categories: binary classification problems, and multi-class classification problems. Binary classification means there are only two possible label classes, e.g. a patient’s condition is cancerous or it isn’t, or a financial transaction is fraudulent or it is not. Multi-class classification refers to cases where there are more than two label classes. An example of this is classifying the sentiment of a movie review into positive, negative, or neutral.
分类问题可以大致分为两类:二元分类问题和多分类问题。 二进制分类意味着只有两种可能的标签类别,例如,患者的状况是癌变还是不是癌变,或者金融交易是否是欺诈性或不是。 多类别分类是指标签类别超过两个的情况。 例如,将电影评论的情绪分为正面,负面或中性。
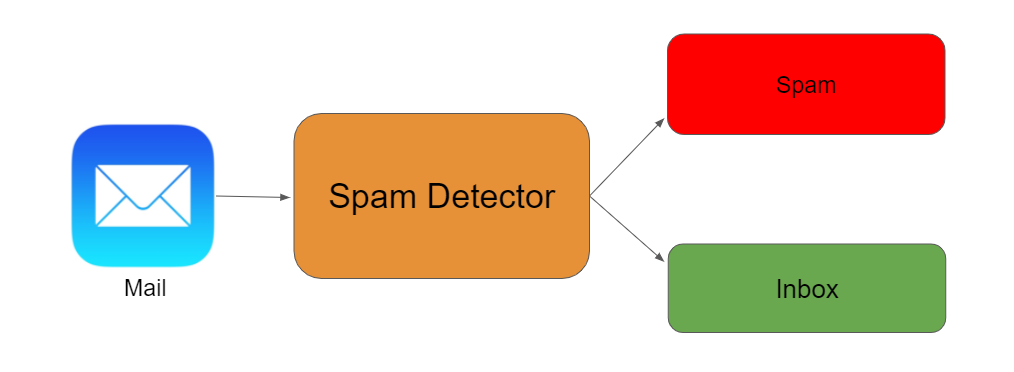
There are many types of NLP problems, and one of the most common types is the classification of strings. Examples of this include the classification of movies/news articles into different genres, and the automated classification of emails into spam or not spam. I’ll be looking into this last example in more detail for this article.
NLP问题有很多类型,最常见的一种是string的分类 。 这样的示例包括将电影/新闻文章分类为不同类型,以及将电子邮件自动分类为垃圾邮件或非垃圾邮件。 我将在本文中更详细地研究最后一个示例。
问题描述 (Problem Description)
Understanding the problem is a crucial first step in solving any machine learning problem. In this article, we will explore and understand the process of classifying emails as spam or not spam. This is called Spam Detection, and it is a binary classification problem.
理解问题是解决任何机器学习问题的关键的第一步。 在本文中,我们将探索和理解将电子邮件分类为垃圾邮件或非垃圾邮件的过程。 这称为垃圾邮件检测,它是一个二进制分类问题。
The reason to do this is simple: by detecting unsolicited and unwanted emails, we can prevent spam messages from creeping into the user’s inbox, thereby improving user experience.
这样做的原因很简单:通过检测未经请求和不需要的电子邮件,我们可以防止垃圾邮件爬入用户的收件箱,从而改善用户体验。
数据集 (Dataset)
Let’s start with our spam detection data. We’ll be using the open-source Spambase dataset from the UCI machine learning repository, a dataset that contains 5569 emails, of which 745 are spam.
让我们从垃圾邮件检测数据开始。 我们将使用UCI机器学习存储库中的开源Spambase数据集 ,该数据集包含5569封电子邮件,其中745 封为垃圾邮件。
The target variable for this dataset is ‘spam’ in which a spam email is mapped to 1 and anything else is mapped to 0. The target variable can be thought of as what you are trying to predict. In machine learning problems, the value of this variable will be modeled and predicted by other variables.
此数据集的目标变量是“垃圾邮件”,在该垃圾邮件中, 垃圾邮件被映射为1 ,其他任何内容都被映射为0。可以将目标变量视为您要预测的内容。 在机器学习问题中,此变量的值将由其他变量建模和预测。
A snapshot of the data is presented in figure 1.
数据快照如图1所示。

Task: To classify an email into spam or not spam.
任务:将电子邮件分为垃圾邮件或非垃圾邮件。
To get to our solution we need to understand the four processing concepts below. Please note that the concepts discussed here can also be applied to other text classification problems.
为了获得我们的解决方案,我们需要了解以下四个处理概念。 请注意,此处讨论的概念也可以应用于其他文本分类问题。
- Text Processing 文字处理
- Text Sequencing 文字排序
- Model Selection 选型
- Implementation 实作
1.文字处理 (1. Text Processing)
Data usually comes from a variety of sources and often in different formats. For this reason, transforming your raw data is essential. However, this transformation is not a simple process, as text data often contains redundant and repetitive words. This means that processing the text data is the first step in our solution.
数据通常来自各种来源,并且通常采用不同的格式。 因此,转换原始数据至关重要。 但是,这种转换不是一个简单的过程,因为文本数据通常包含冗余和重复的单词。 这意味着处理文本数据是我们解决方案的第一步。
The fundamental steps involved in text preprocessing are,
文本预处理涉及的基本步骤是:
- Cleaning the raw data
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









