





nlp 深度学习张量的维度
Here is an example of how a recurrent neural network can be used to detect spam messages. The dataset used in this example is sourced from Kaggle (original authors Almeida and Hidalgo, 2011).
这是如何使用递归神经网络检测垃圾邮件的示例。 本示例中使用的数据集来自Kaggle (原始作者Almeida和Hidalgo,2011年)。
In the training set, certain messages are marked as “spam” (this has been replaced with a 1 for this purpose). Non-spam messages are marked as “ham” (replaced with a 0 for this purpose).
在训练集中,某些邮件被标记为“垃圾邮件”(为此已被替换为1)。 非垃圾邮件标记为“ ham”(为此目的替换为0)。
The recurrent neural network is built using the original Word Embeddings and Sentiment notebook from the TensorFlow Authors — the original notebook is available here.
循环神经网络是使用TensorFlow Authors的原始Word Embeddings和Sentiment笔记本构建的-原始笔记本可在此处获得。
The analysis is conducted through the following steps:
通过以下步骤进行分析:
- The data is loaded, with the sentences split into training and test sets. 加载数据,将句子分为训练集和测试集。
dataset = pd.read_csv('spam.csv')
datasetsentences = dataset['Message'].tolist()
labels = dataset['Category'].tolist()# Separate out the sentences and labels into training and test sets
training_size = int(len(sentences) * 0.8)training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]# Make labels into numpy arrays for use with the network later
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)2. The dataset is tokenized. In other words, a unique number is assigned to each word — which is necessary for the neural network to interpret the input.
2.数据集被标记化。 换句话说,为每个单词分配一个唯一的数字-这对于神经网络解释输入是必不可少的。
vocab_size = 1000
embedding_dim = 16
max_length = 100
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencestokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index3. These tokens are then sorted into sequences, to ensure that the tokens for each word follow the correct order as dictated by each sentence.
3.然后将这些标记分类为序列,以确保每个单词的标记遵循每个句子指示的正确顺序。
sequences = tokenizer.texts_to_sequences(training_sentences)4. Padding is then introduced — which introduces 0s at the end of each sentence. This is necessary when one sentence is longer than another, as each sentence must have the same length for the purposes of analysis by the RNN.
4.然后引入填充-在每个句子的末尾引入0。 当一个句子比另一个句子长时,这是必要的,因为为了RNN分析的目的,每个句子必须具有相同的长度。
padded = pad_sequences(sequences,maxlen=max_length, padding=padding_type,
truncating=trunc_type)testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences,maxlen=max_length,
padding=padding_type, truncating=trunc_type)5. The recurrent neural network is built and trained across 20 epochs — with the input layer comprised of an embedding layer which represents the sentences with dense vector representation.
5.循环神经网络的构建和训练跨越20个时期,输入层由嵌入层组成,该嵌入层用密集的矢量表示法表示句子。
递归神经网络(RNN) (Recurrent Neural Network (RNN))
Here is the recurrent neural network configuration:
这是递归神经网络配置:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()Here is a closer look at the model parameters:
以下是模型参数的详细信息:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 16000
_________________________________________________________________
flatten (Flatten) (None, 1600) 0
_________________________________________________________________
dense (Dense) (None, 6) 9606
_________________________________________________________________
dense_1 (Dense) (None, 1) 7
=================================================================
Total params: 25,613
Trainable params: 25,613
Non-trainable params: 0The model produces the following training and validation loss:
该模型产生以下训练和验证损失:
num_epochs = 20
history=model.fit(padded, training_labels_final, epochs=num_epochs, validation_data=(testing_padded, testing_labels_final))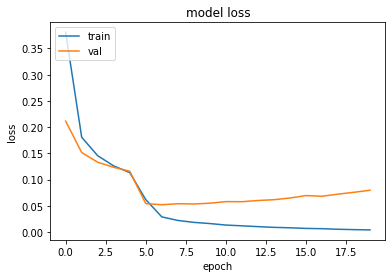
In this instance, we see that the validation loss bottoms out after 5 epochs. In this regard, the model is run again with 5 epochs chosen.
在这种情况下,我们看到验证损失在5个时期后触底。 在这方面,该模型将在选择的5个时间段内再次运行。
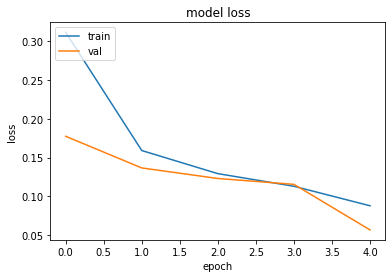
测试看不见的数据(Testing on unseen data)
Now that the model has been built, let’s see how the classifier does in identifying spam on the following messages (which I invented randomly):
现在已经构建了模型,让我们看看分类器如何根据以下消息(我是随机发明的)识别垃圾邮件:
- ‘Greg, can you call me back once you get this?’ (intended as genuine) “格雷格,一旦得到这个,你能给我回电话吗?” (原汁原味)
- ‘Congrats on your new iPhone! Click here to claim your prize…’ (intended as spam) “恭喜您使用了新的iPhone! 单击此处索取您的奖金…'(打算作为垃圾邮件)
- ‘Really like that new photo of you’ (intended as genuine) “真的像您的新照片”(原汁原味)
- ‘Did you hear the news today? Terrible what has happened…’ (intended as genuine) “你今天听到新闻了吗? 发生了什么可怕的事情……'(原汁原味)
- ‘Attend this free COVID webinar today: Book your session now…’ (intended as spam) “今天参加这个免费的COVID网络研讨会:立即预订会议…”(意为垃圾邮件)
Here are the scores generated (the closer the score is to 1, the higher the probability that the sentence is spam:
以下是生成的分数(分数越接近1,则该句子是垃圾邮件的可能性越高:
['Greg, can you call me back once you get this?', 'Congrats on your new iPhone! Click here to claim your prize...', 'Really like that new photo of you', 'Did you hear the news today? Terrible what has happened...', 'Attend this free COVID webinar today: Book your session now...']
Greg, can you call me back once you get this?
[0.0735679]
Congrats on your new iPhone! Click here to claim your prize...
[0.91035014]
Really like that new photo of you
[0.01672107]
Did you hear the news today? Terrible what has happened...
[0.02904579]
Attend this free COVID webinar today: Book your session now...
[0.54472804]We see that for the two messages intended as spam — the classifier shows a significant probability for both. In the case of the sentence, “Attend this free COVID webinar today: Book your session now…” — the classifier does reasonably well at marking a higher than 50% probability of being spam — even though COVID was not a term at the time the training set was constructed.
我们看到,对于打算作为垃圾邮件的两条消息,分类器对这两种消息均显示出很大的可能性。 以“今天参加此免费的COVID网络研讨会:立即预订会话……”为例,分类器在标记垃圾邮件可能性高于50%的情况下做得相当好-尽管当时COVID并不是术语训练集已构建。
In this regard, it is evident that the classifier relies on the context in which the words are being used — as opposed to individual words simply being marked as spam in their own right.
在这方面,很明显,分类器依赖于使用单词的上下文,而不是将单个单词本身简单地标记为垃圾邮件。
Given that the recurrent neural network is effective at modelling sequential data and identifying patterns between words — this simple spam detector built using TensorFlow has been shown to be quite effective on the limited data we have used for testing purposes.
鉴于递归神经网络可以有效地建模顺序数据并识别单词之间的模式-使用TensorFlow构建的这种简单的垃圾邮件检测器已证明对我们用于测试目的的有限数据非常有效。
结论 (Conclusion)
In this example, we have seen:
在此示例中,我们看到了:
- How recurrent neural networks can be used for text classification 递归神经网络如何用于文本分类
- Preparation of text data for analysis using tokenization, sequences and padding准备文本数据以使用标记化,序列和填充进行分析
- Configuration of a neural network model to analyse text data配置神经网络模型以分析文本数据
In addition, we saw how the model can then be used to predict unseen data (or messages in this case) to determine how the model would potentially work in real-world scenarios.
此外,我们看到了如何将模型用于预测看不见的数据(在这种情况下为消息),以确定模型在现实场景中的潜在工作方式。
Many thanks for reading, and the associated GitHub repository for this example can be found here.
非常感谢您的阅读,有关此示例的GitHub存储库可在此处找到。
Update: You can also find updates made to this model under Part II of this article, available here.
更新:您还可以在本文的第二部分中找到对此模型所做的更新,可在此处获得。
Disclaimer: This article is written on an “as is” basis and without warranty. It was written with the intention of providing an overview of data science concepts, and should not be interpreted as any sort of professional advice. The author has no relationships with any parties mentioned in this article, nor is this article or its findings endorsed by the same.
免责声明:本文按“原样”撰写,不作任何担保。 本文档旨在概述数据科学概念,不应将其解释为任何专业建议。 作者与本文提到的任何各方均没有关系,本文或本文的发现也未得到本文的认可。
翻译自: https://towardsdatascience.com/nlp-detecting-spam-messages-with-tensorflow-b12195b8cf0e
nlp 深度学习张量的维度















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









