







 本文介绍了使用朴素贝叶斯分类器进行垃圾邮件检测的方法,包括贝叶斯公式、判别模型与生成模型的概念,以及如何通过拉普拉斯修正和防溢出策略处理数据。通过构建词向量、训练分类器和测试,最终得出60%的错误率。
本文介绍了使用朴素贝叶斯分类器进行垃圾邮件检测的方法,包括贝叶斯公式、判别模型与生成模型的概念,以及如何通过拉普拉斯修正和防溢出策略处理数据。通过构建词向量、训练分类器和测试,最终得出60%的错误率。
目录
一、前言
对于分类问题,其实谁都不会陌生,日常生活中我们每天都进行着分类过程。例如,当你看到一个人,你的脑子下意识判断他是学生还是社会上的人;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱、”之类的话,其实这就是一种分类操作。
既然是贝叶斯分类算法,那么分类的数学描述又是什么呢?
从数学角度来说,分类问题可做如下定义:已知集合![]() 和
和![]() ,确定映射规则y = f(),使得任意
,确定映射规则y = f(),使得任意![[公式]](https://i-blog.csdnimg.cn/blog_migrate/a00b33115d29ad16bb0f9901161781a5.png) 有且仅有一个
有且仅有一个![[公式]](https://i-blog.csdnimg.cn/blog_migrate/cea594d5c9d1d7956f26c579967fff19.png) ,使得
,使得![[公式]](https://i-blog.csdnimg.cn/blog_migrate/6cb9b8e3d9cee3b9d260b3fa45b6c074.png) 成立。
成立。
其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合(特征集合),其中每一个元素是一个待分类项,f叫做分类器。分类算法的任务就是构造分类器f。
二、朴素贝叶斯原理
1.贝叶斯公式:
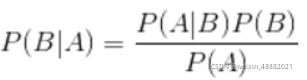
换个表达形式就会明朗很多,如下:
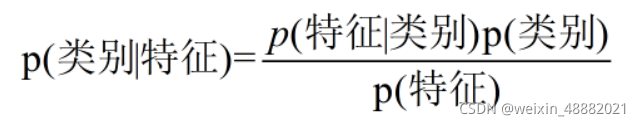
2.判别模型和生成模型
判别模型:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻,感知级,决策树,支持向量机等。
生成模型:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立样本的联合概率概率密度模型P(X,Y),然后再得到后验概率P(Y|X),再利用它进行分类,就像上面说的那样。注意了哦,这里是先求出P(X,Y)才得到P(Y|X)的,然后这个过程还得先求出P(X)。P(X)就是你的训练数据的概率分布。
3.朴素贝叶斯分类器
朴素贝叶斯分类器(Naïve Bayes Classifier)采用了“属性条件独立性假设”,即每个属性独立地对分类结果发生影响。
为方便公式标记,不妨记
P
(
C
=
c
|
X
=x)
为
P
(
c
|x)
,基于属性条件独立性假设,贝叶斯公式可重写为
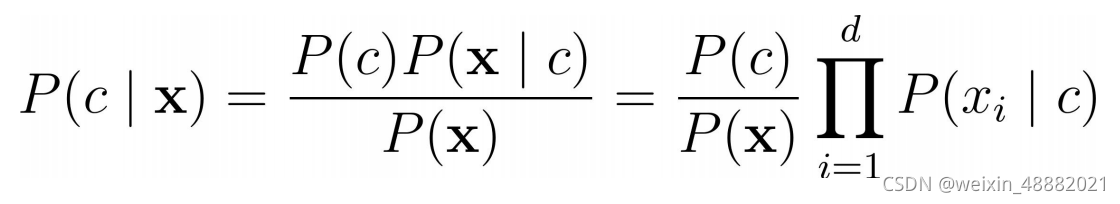
其中d为属性数目,xi为 x 在第i个属性上的取值。
朴素贝叶斯分类器的训练器的训练过程就是基于训练集
D
估计类先验概率
P
(
c
),并为每个属性估计条件概率
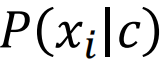 。 令
。 令
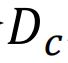 表示训练集D
中第
c
类样本组合的集合,则类先验概率:
表示训练集D
中第
c
类样本组合的集合,则类先验概率:
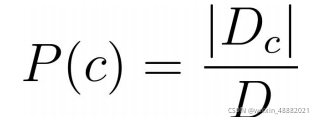
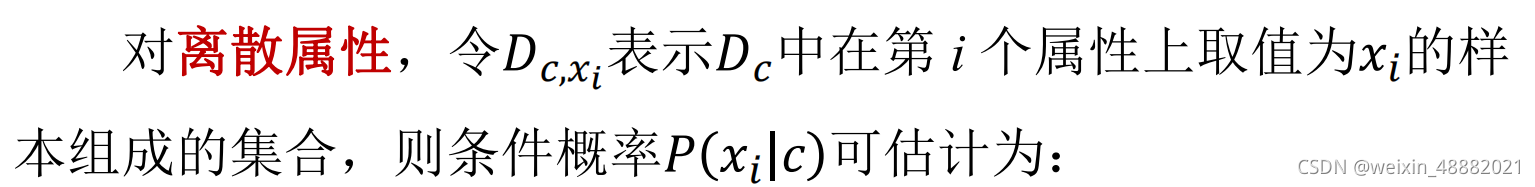
![]()

4.拉普拉斯修正
若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现
over-fitting
现象。比如“敲声
=
清脆”测试例,训练
集中没有该样例,因此连乘式计算的概率值为
0
,无论其他属性上
明显像好瓜,分类结果都是“好瓜
=
否”,这显然不合理。
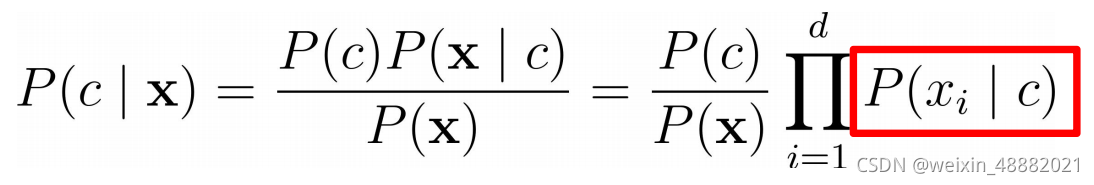
为了避免其他属性携带的信息,被训练集中未出现的属性值“抹去”,在估计概率值时通常要进行“拉普拉斯修正”:
令
N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









