





星巴克 销售数据分析
介绍 (Introduction)
项目概况 (Project Overview)
The data for this case simulates how people make purchasing decisions and how those decisions are influenced by promotional offers.
该案例的数据模拟了人们如何做出购买决定以及促销决定如何影响这些决定。
Each person in the simulation has some hidden traits that influence their purchasing patterns and are associated with their observable traits.
模拟中的每个人都有一些隐藏的特征,这些特征会影响他们的购买方式,并与他们的可观察特征相关联。
People produce various events, including receiving offers, opening offers, and making purchases.
人们产生各种事件,包括接收要约,公开要约和进行购买。
As a simplification, there are no explicit products to track. Only the amounts of each transaction or offer are recorded.
为简化起见,没有明确的产品可追踪。 仅记录每笔交易或要约的金额。
There are three types of offers that can be sent: buy-one-get-one (BOGO), discount, and informational.
可以发送三种类型的报价:买一送一(BOGO),折扣和信息性。
- BOGO: a user needs to spend a certain amount to get a reward equal to that threshold amount. BOGO:用户需要花费一定的金额才能获得等于该阈值金额的奖励。
- Discount: a user gains a reward equal to a fraction of the amount spent. 折扣:用户获得的奖励等于所花费金额的一小部分。
- Informational: there is no reward, but neither is there a requisite amount that the user is expected to spend. 信息性:没有奖励,但也没有期望用户花费的必要金额。
Offers can be delivered via multiple channels: Email, Mobile, Social, Web
优惠可以通过多种渠道传递:电子邮件,移动,社交,网络
问题陈述 (Problem Statement)
We will use the data to find a better promotion strategy by trying to answer the following questions:
我们将通过尝试回答以下问题,使用这些数据找到更好的促销策略:
a) Identify which groups of people are most responsive to each type of offer.
a)确定哪些人群对每种类型的提议最敏感。
b) How best to present each type of offer?
b)如何最好地展示每种报价?
c) How many people across different categories actually completed the transaction in the offer window?
c)在报价窗口中,实际上有多少人来自不同类别?
d) Which individual attributes contributed the most during the offer window?
d)在报价窗口期间,哪些个人属性贡献最大?
We will also try to train a model to predict the amount that can be spent by an individual given the individual’s traits and offer details. This will help us decide which promotional offer best suits the individual and respond to the target audience with better accuracy.
我们还将尝试训练模型,以根据个人的特征预测个人可以花费的金额并提供详细信息。 这将有助于我们确定最适合个人的促销优惠,并以更高的准确性响应目标受众。
指标 (Metrics)
In order to try to answer the four questions mentioned above, we need to focus on the offer window, i.e., the time between beginning of an offer rollout and it’s expiry. Some key definitions before we continue:
为了尝试回答上面提到的四个问题,我们需要关注“ 报价”窗口 ,即从报价推出到到期之间的时间。 我们继续之前的一些关键定义:
Let t_receipt denote the time of receipt for an offer, t_view denote the time when user first views the offer, t_completion denote the time at which the user pays for an item with promotion applied and, t_expiry denote the time when the offer expires.
令t_receipt表示收到商品的时间, t_view表示用户首次查看商品的时间, t_completion表示用户为应用了促销的商品付款的时间, t_expiry表示商品过期的时间。
We have an offer window if t_receipt ≤ t_view ≤ t_expiry.
如果t_receipt≤t_view≤t_expiry,我们有一个报价窗口。
An offer window is considered as open if t_view ≥ t_receipt and t_completion is null
要约窗口被视为开放的 ,如果t_view≥t_receipt 并且t_completion为null
A transaction is said to be done in the offer window if t_view ≥ t_receipt and t_completion ≥ t_receipt.
如果t_view≥t_receipt并且t_completion≥t_receipt,则说要在要约窗口中完成交易。
SUCCESSFUL OFFER: An offer is considered successful if t_receipt ≤ t_view, t_view ≤ t_completion and t_completion ≤ t_expiry [PAID].
成功要约:报价被认为是成功的 ,如果t_receipt≤t_view,t_view≤t_completion和t_completion≤t_expiry [付费。
TRIED OFFER: An offer is considered to have been tried if t_receipt ≤ t_view, t_view ≤ t_expiry and t_completion > t_expiry [PURCHASED AFTER OFFER EXPIRED]
受审要约:提供被认为已经尝试过 ,如果t_receipt≤t_view,t_view≤t_expiry和t_completion> t_expiry [AFTER购买的OFFER过期]
FAILED OFFER: An offer is considered to have been failed if it is neither successful nor tried.
失败要约:如果要约既未成功也未尝试,则视为已失败 。
The metric we will use to analyze the performance of the model to predict amount spent by each individual is R2 score.
我们将用来分析模型性能以预测每个人花费的量度的指标是R2分数。
R-squared is a statistical measure of how close the data are to the fitted regression line.
R平方是数据与拟合回归线的接近程度的统计量度。
分析 (Analysis)
数据探索 (Data Exploration)
Portfolio data
投资组合数据
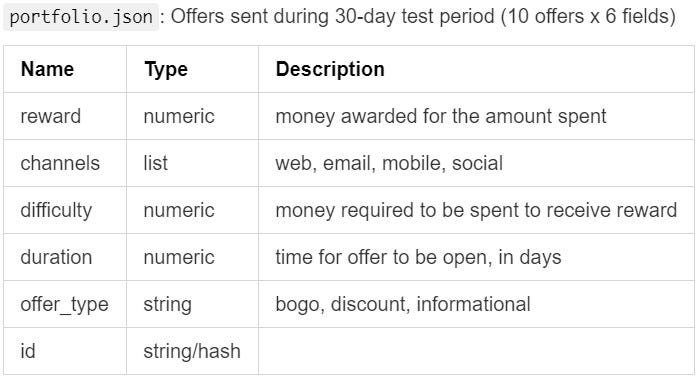
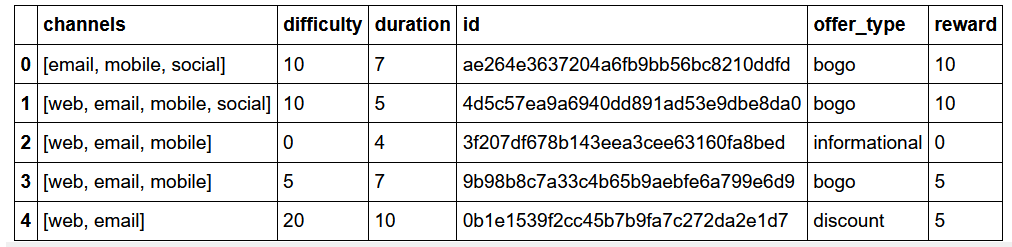
There are 10 types of offers available.
有10种类型的优惠。
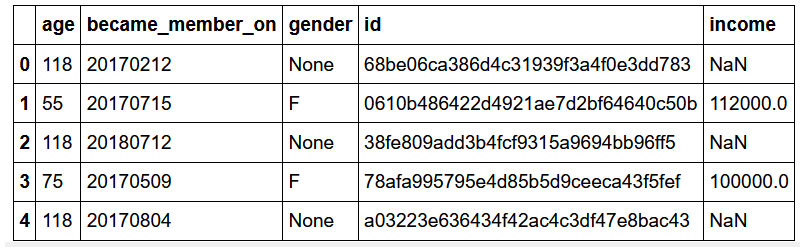
Profile data
个人资料数据

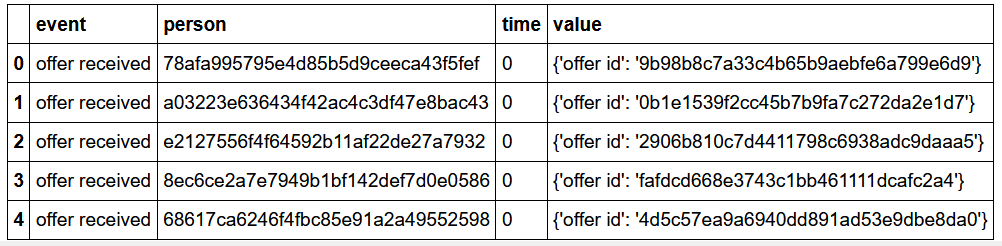
Transcript data
成绩单数据

缺失数据 (Missing data)
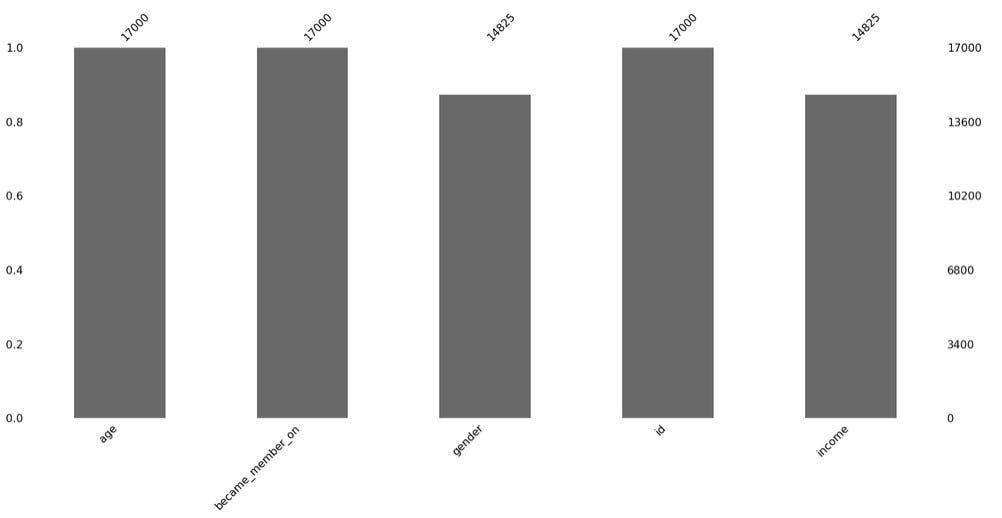
There are 2175 records in profile data, where income and gender are missing.
个人资料数据中有2175条记录,其中缺少收入和性别。
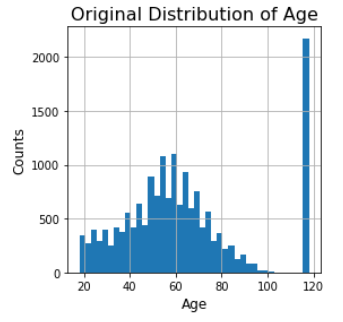
In the same 2175 records, age was set to be 118, which clearly seems to be a placeholder for the null value as shown to the left.
在相同的2175条记录中,年龄设置为118,如左所示,它显然是空值的占位符。
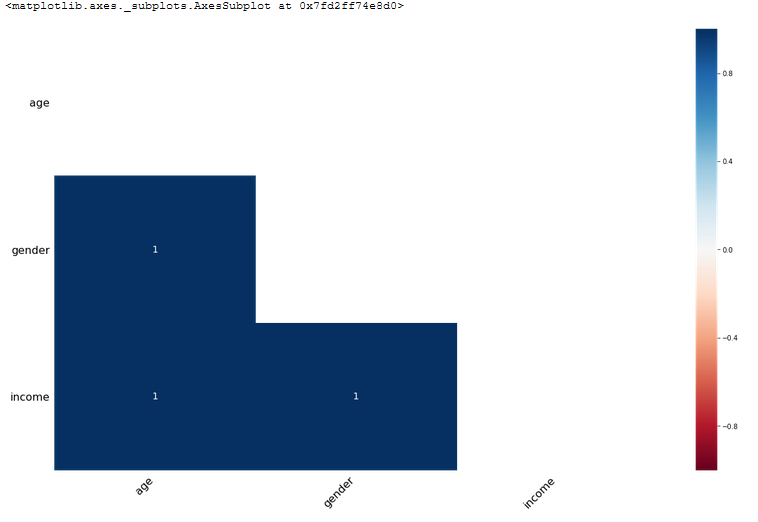
This became clear by setting all the 118 ages to null and visualizing the heat map as shown below:
通过将所有118个年龄都设置为零并可视化热图,这一点变得很清楚,如下所示:
数据预处理 (Data Preprocessing)
We created a Python class to preprocess the data, store the preprocessed data, create models, train models and save models, along with few helper methods to help with one-hot encoding.
我们创建了一个Python类来预处理数据,存储经过预处理的数据,创建模型,训练模型和保存模型,以及一些辅助方法来帮助进行一键编码。
作品集 (Portfolio)
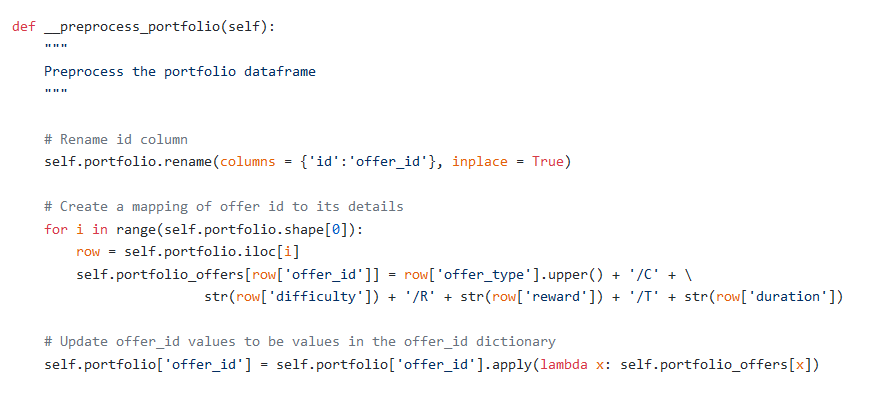
Renamed column
idtooffer_id将列
id重命名为offer_idModified values in column
offer_idto contain values of the format<offer_type>/C<difficulty>/R<reward>/T<duration. The reason behind doing this is readability.在
offer_id列中的修改后的值包含格式为<offer_type>/C<difficulty>/R<reward>/T<duration。 这样做的原因是可读性。Modified values in column
offer_idto contain values of the format<offer_type>/C<difficulty>/R<reward>/T<duration. The reason behind doing this is readability.{‘ae264e3637204a6fb9bb56bc8210ddfd’: ‘BOGO/C10/R10/T7’, ‘4d5c57ea9a6940dd891ad53e9dbe8da0’: ‘BOGO/C10/R10/T5’, ‘3f207df678b143eea3cee63160fa8bed’: ‘INFORMATIONAL/C0/R0/T4’, ‘9b98b8c7a33c4b65b9aebfe6a799e6d9’: ‘BOGO/C5/R5/T7’, ‘0b1e1539f2cc45b7b9fa7c272da2e1d7’: ‘DISCOUNT/C20/R5/T10’, ‘2298d6c36e964ae4a3e7e9706d1fb8c2’: ‘DISCOUNT/C7/R3/T7’, ‘fafdcd668e3743c1bb461111dcafc2a4’: ‘DISCOUNT/C10/R2/T10’, ‘5a8bc65990b245e5a138643cd4eb9837’: ‘INFORMATIONAL/C0/R0/T3’, ‘f19421c1d4aa40978ebb69ca19b0e20d’: ‘BOGO/C5/R5/T5’, ‘2906b810c7d4411798c6938adc9daaa5’: ‘DISCOUNT/C10/R2/T7’}在
offer_id列中的修改后的值包含格式为<offer_type>/C<difficulty>/R<reward>/T<duration。 这样做的原因是可读性。{'ae264e3637204a6fb9bb56bc8210ddfd': 'BOGO/C10/R10/T7', '4d5c57ea9a6940dd891ad53e9dbe8da0': 'BOGO/C10/R10/T5', '3f207df678b143eea3cee63160fa8bed': 'INFORMATIONAL/C0/R0/T4', '9b98b8c7a33c4b65b9aebfe6a799e6d9': 'BOGO/C5/R5/T7', '0b1e1539f2cc45b7b9fa7c272da2e1d7': 'DISCOUNT/C20/R5/T10', '2298d6c36e964ae4a3e7e9706d1fb8c2': 'DISCOUNT/C7/R3/T7', 'fafdcd668e3743c1bb461111dcafc2a4': 'DISCOUNT/C10/R2/T10', '5a8bc65990b245e5a138643cd4eb9837': 'INFORMATIONAL/C0/R0/T3', 'f19421c1d4aa40978ebb69ca19b0e20d': 'BOGO/C5/R5/T5', '2906b810c7d4411798c6938adc9daaa5': 'DISCOUNT/C10/R2/T7'}
个人资料 (Profile)
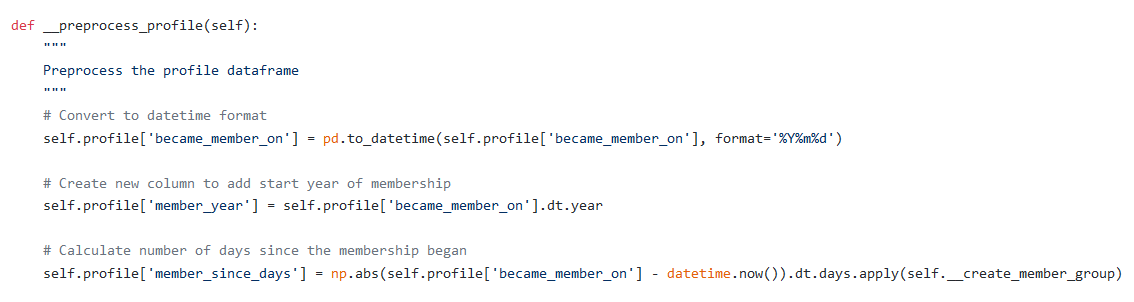
1. Created a new column member_year from the column became_member_on to contain the year representing the beginning of a user’s membership
1.从became_member_on列中创建一个新列member_year ,以包含代表用户成员资格开始的年份
2. Calculate number of days since the membership began and store it in the column member_since_days
2.计算自成员资格开始以来的天数,并将其存储在member_since_days列中
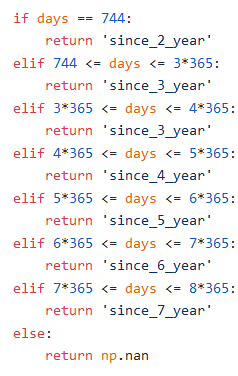
3. Created age groups — 1, 2, 3, and 4 representing age ≤ 38, 39 ≤ age ≤ 54, 55 ≤ age ≤ 73 and 74 ≤ age ≤ 101 respectively.
3.创建的年龄组-分别代表年龄≤38、39≤年龄54、55≤年龄≤73和74≤年龄101的年龄组1、2、3和4。


4. Renamed the id column to person to keep in consistent with the transcript data frame
4.将id列重命名为person以与transcript数据框保持一致
5. Replace age 118 with NaN as it is a placeholder for null values and appeared consistently in records where income and gender are unavailable.
5.用NaN代替118岁,因为它是空值的占位符,并且在income和gender均不可用的记录中始终出现。
6. Removed the records with null values as there were only three important attributes for each person — income, age and gender, and in 2175 out of 17000 records, all of the three were missing.
6.删除具有空值的记录,因为每个人只有三个重要属性-收入,年龄和性别,并且在17000条记录中的2175条中,所有这三个都丢失了。
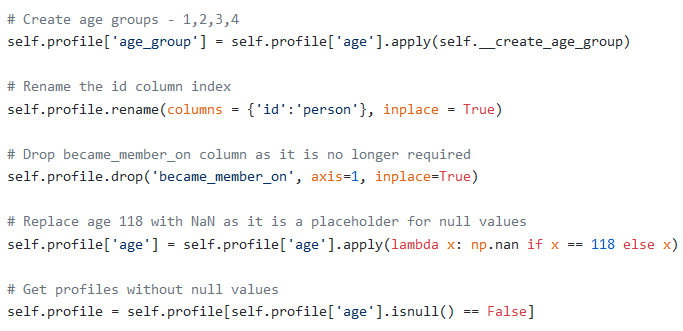
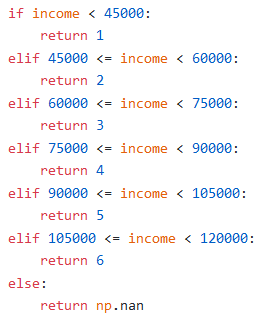
7. Created a column income_group based on income ranges 45000 ≤ income < 60000, 60000 ≤ income < 75000, 75000 ≤ income < 90000, 90000 ≤ income < 105000, and 105000 ≤ income < 120000 respectively.
7. income_group基于收入范围income_group 收入< income_group 收入< income_group 收入< income_group 收入<105000和105000≤收入<120000 ,创建了一个收入组列。

成绩单 (Transcript)
The transcript’s
valuecolumn contained data in the following format:笔录的“
value列包含以下格式的数据:For events of type ‘offer viewed’:
对于“已查看提供”类型的事件:
{‘offer id’: ‘f19421c1d4aa40978ebb69ca19b0e20d’}{'offer id': 'f19421c1d4aa40978ebb69ca19b0e20d'}For events of type ‘offer received’:
对于“已收到要约”类型的事件:
{‘offer id’: ‘9b98b8c7a33c4b65b9aebfe6a799e6d9’}{'offer id': '9b98b8c7a33c4b65b9aebfe6a799e6d9'}For events of type ‘offer completed’:
对于“提供完成”类型的事件:
{‘offer_id’: ‘2906b810c7d4411798c6938adc9daaa5’, ‘reward’: 2}{'offer_id': '2906b810c7d4411798c6938adc9daaa5', 'reward': 2}For events of type ‘transaction’:
对于“交易”类型的事件:
{‘amount’: 0.8300000000000001}{'amount': 0.8300000000000001}{‘amount’: 0.8300000000000001}To keep it simple, a new column calledtypewith two values: offer_id or amount was created.{'amount': 0.8300000000000001}为简单{'amount': 0.8300000000000001},创建了一个名为type的新列,它具有两个值: offer_id或amount 。

2. Created a new column offer_id containing the offer id as mentioned in point 2 under the Portfolio section or NoPromotionApplied if the event is of type transaction.
2.创建了一个新列offer_id其中包含项目2部分第2点中提到的要约ID,如果事件是事务类型,则NoPromotionApplied 。

在报价窗口中查找完成交易的记录 (Finding records with transaction done within the offer window)
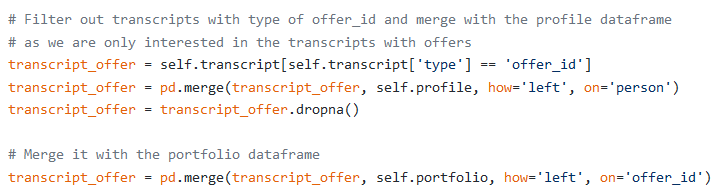
3. Filtered out transcripts with type of offer_id and merge with the profile and portfolio data frames:
3.过滤掉offer_id类型的offer_id并与个人资料和投资组合数据帧合并:
4. Find out true success and tried records. To do this, we filtered out records based on event type: offer received , offer viewed , and offer completed into separate data frames, each with a new column for time denoting time of receipt, time of view and time of completion. Then we merge them back.
4.找出真正的成功和尝试过的记录。 为此,我们基于事件类型过滤了记录: offer received offer viewed和offer completed到单独的数据框中,每个数据框中都有一个新列,用于表示接收时间,查看时间和完成时间。 然后我们将它们合并。

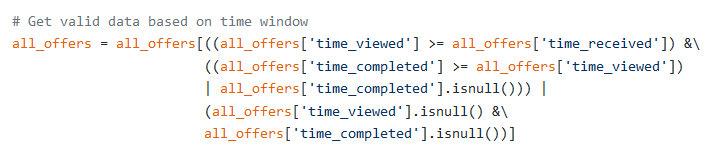
5. Next we filter out data that fall in the offer time window (refer definition under the Metrics section in the beginning of this article) as shown below:
5.接下来,我们过滤掉落在要约时间窗口中的数据 ( 请参阅本文开头“指标”部分下的定义) ,如下所示:
6. Calculate the time left for the offer to expire as shown below:
6.计算要约到期的剩余时间,如下所示:

7. Create columns denoting if a record represents successful, tried or failed offer as shown below:
7.创建表示记录是成功,尝试还是失败的列,如下所示:

8. Then we clean the data frame as it might have introduced duplicate records and null values because of the merge operation performed in point number 4.
8.然后我们清理数据框,因为由于在第4点执行合并操作,它可能引入了重复的记录和空值。

9. Finally we identify if the amount spent by the individual is during the offer period or outside the offer period.
9.最后,我们确定个人花费的金额是在要约期内还是在要约期以外。
To do this we calculate the amount spent from the original transcript data set and the time taken to spend the money from the beginning of the pro. Then we get all the data related to the non-failed offer, i.e., records dealing with either success or tried offers and merge it with the transaction data. Finally, we check if transaction is done within the offer period or not and create a new column to indicate this information as shown below:
为此,我们从原始成绩单数据集中计算花费的金额,以及从专业人士开始花费的时间。 然后,我们获得与未失败报价有关的所有数据,即处理成功报价或尝试报价的记录,并将其与交易数据合并。 最后,我们检查交易是否在报价期内完成,并创建一个新列以指示此信息,如下所示:

Let t_spent denote the time spent till transaction.
令t_spent表示交易之前所花费的时间。
There might be some data where information is presented incorrectly. To deal with this, we check if t_spent ≥ t_receipt and (t_spent ≤ t_completed | t_spent ≤ t_expiry), then the transaction is done within the offer time frame else it is not part of the offer window.
可能有些数据显示的信息不正确。 为了解决这个问题,我们检查t_spent≥t_receipt和(t_spent≤t_completed | t_spent≤t_expiry),然后在报价时间范围内完成交易,否则不属于报价窗口。

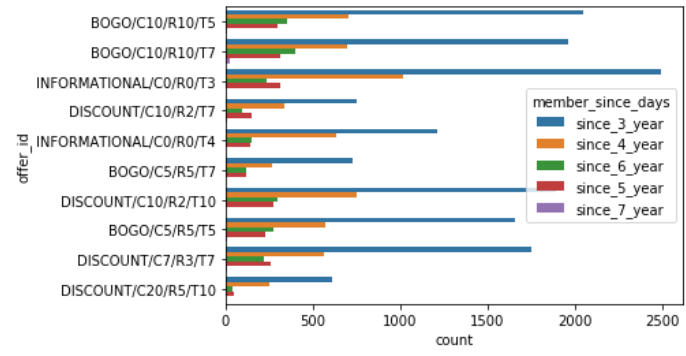
数据可视化 (Data Visualization)
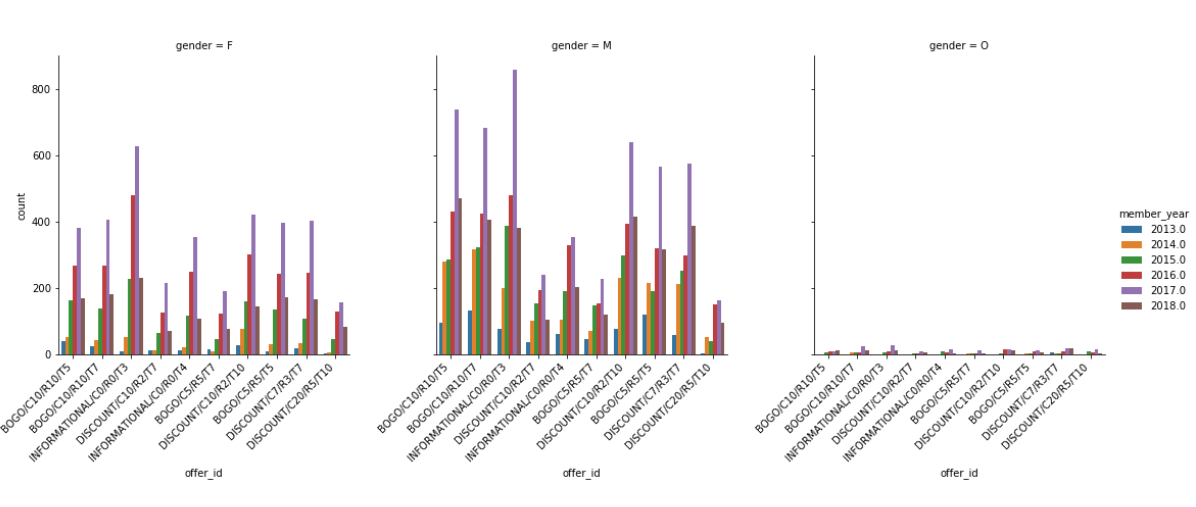
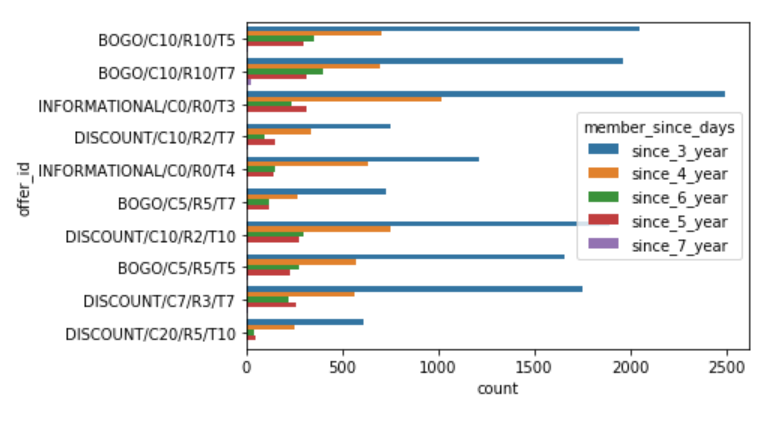
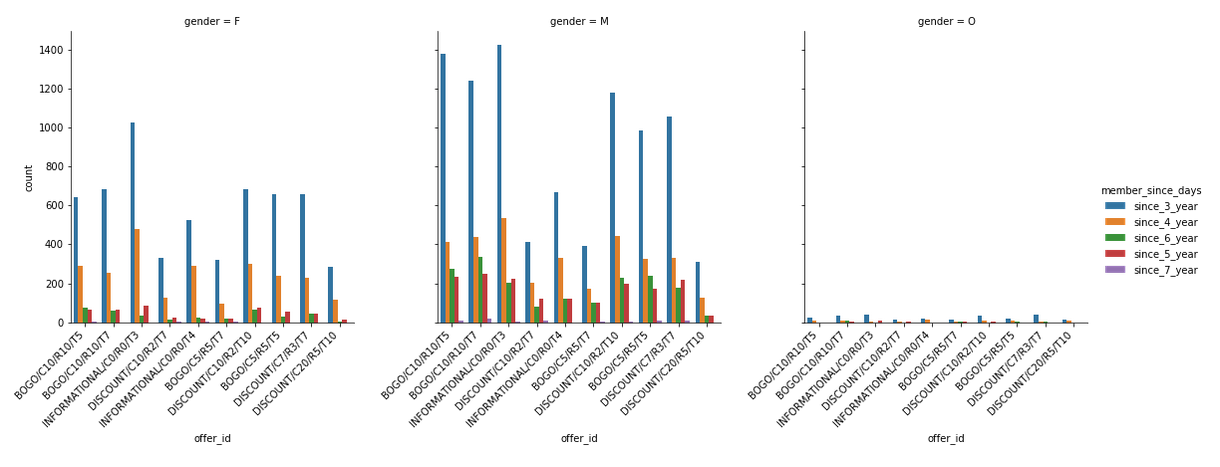
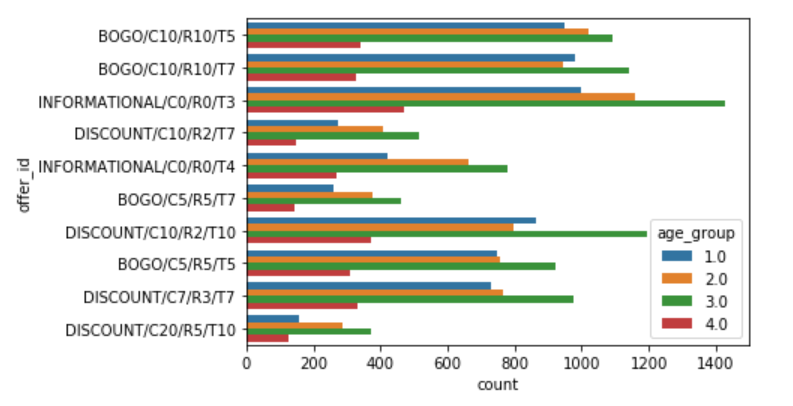
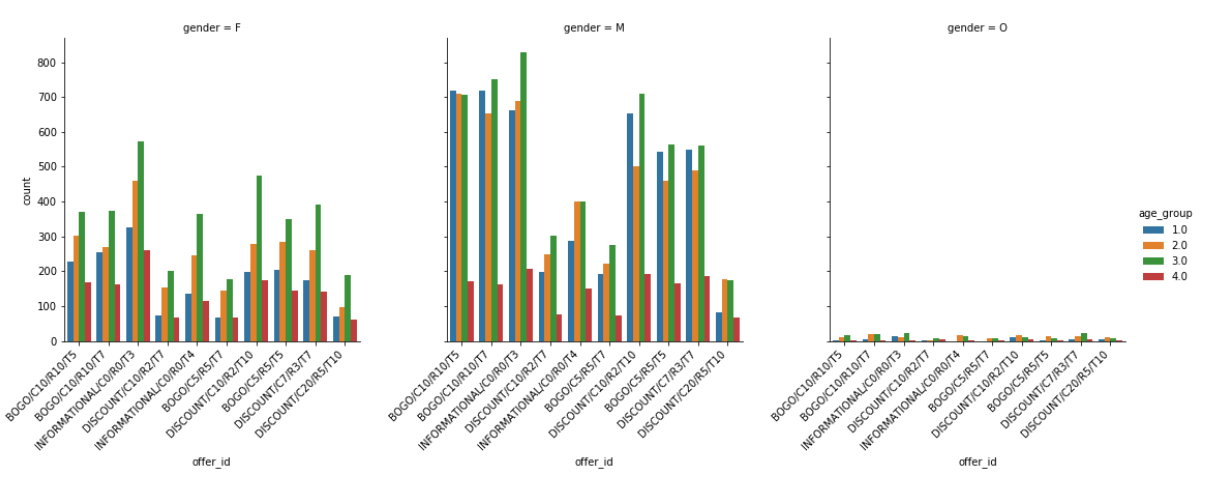
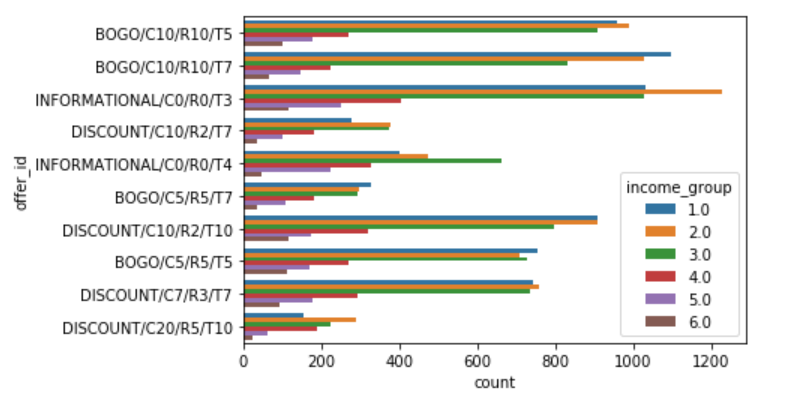
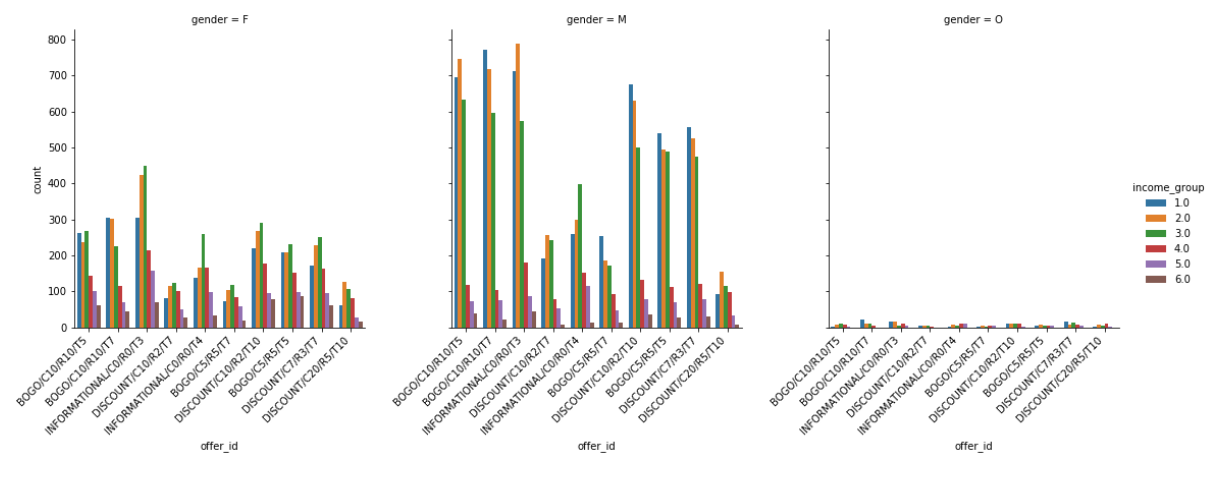
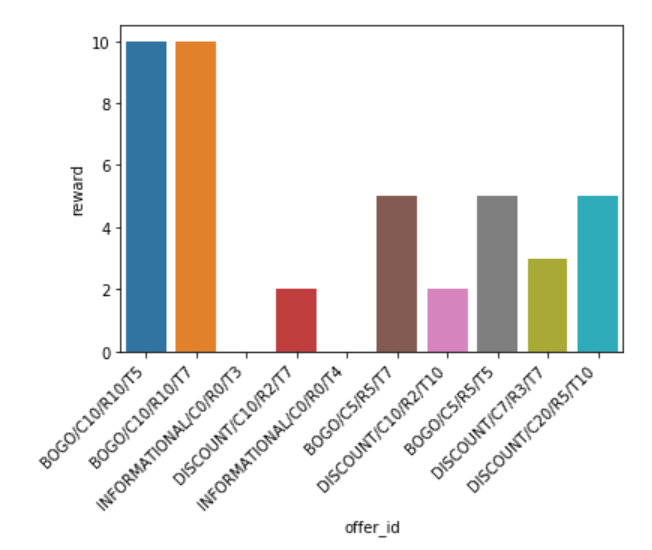
结果 (Results)
模型评估与验证 (Model Evaluation and Validation)
I tried to build a model to predict the amount spent based on individual attributes and offer type. Since, this is a regression task, we went ahead with R2 score as the metric for evaluation.
我试图建立一个模型来根据各个属性和商品类型预测花费的金额。 由于这是一项回归任务,因此我们继续使用R2评分作为评估指标。
The model and hyper parameters used are as follows:
使用的模型和超参数如下:
SVRwith polynomial kernel and a degree of 7 — the base model具有多项式内核和7度的
SVR基本模型

2. RandomForestRegressor with the following hyper parameters:
2.具有以下超级参数的RandomForestRegressor :
3. Grid search for the RandomForestRegressor in the following hyper parameter space:
3.在以下超级参数空间中网格搜索RandomForestRegressor :

We then used the RandomForestRegressor with the best model parameters to train the model again.
然后,我们使用具有最佳模型参数的RandomForestRegressor再次训练模型。
Final results on the different trained models are:
不同训练模型的最终结果是:

The final R2 score is better than that obtained with a SVM and with the default Random Forest.
最终的R2分数要好于使用SVM和默认的Random Forest所获得的分数。
理由 (Justification)
Q1. Identify which groups of people are most responsive to each type of offer.
Q1。 确定哪些人群对每种类型的报价最敏感。
Members who joined one to two years back relative to 2018, seem to be equally responsive to each offer while the trend decreases with new members (1 year or less than 1 year) and old members (more than two years).
相对于2018年加入一到两年后加入的会员似乎对每个提议都具有同等的响应,而新会员(不到1年或少于1年)和老会员(超过2年)的趋势有所下降。
Males in age groups 1 (< 38 years) and 3 (between 55 years and 73 years) dominated across almost all the offers while females showed domination in group 3 (between 55 years and 73 years).
在年龄组1(<38 年)和(岁之间的55和73年)3 男在几乎所有优惠为主,而女性表现在统治集团3( 在55年和73年)。
Males in income groups 2 (45000 <= income < 60000) and 3 (60000 <= income < 75000) showed domination for informational discounts.
收入组2 (45000 <=收入<60000)和3 (60000 <=收入<75000)的 男性显示出信息折扣优势。
Q2. How best to present each type of offer?
Q2。 如何最好地呈现每种类型的报价?
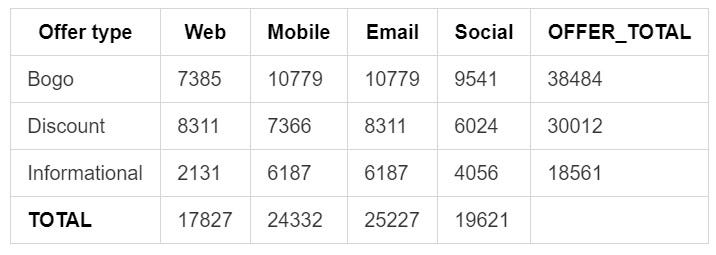
Mobile and Email seem to be the channels from where most of the individual transactions came in on average.
平均而言, 移动和电子邮件似乎是大多数独立交易的渠道。
Q3. How many people across different categories actually completed the transaction in the offer window?
Q3。 在报价窗口中,实际上有多少人属于不同类别?
Approximately 12.8% of the total population for offer type BOGO completed the transaction in the offer window; 12% for offer type discount and 18% for informational type respectively.
约12.8% 要约类型BOGO的总人口中有多少人在要约窗口中完成了交易; 优惠类型的折扣分别为12%和信息类型的18% 。
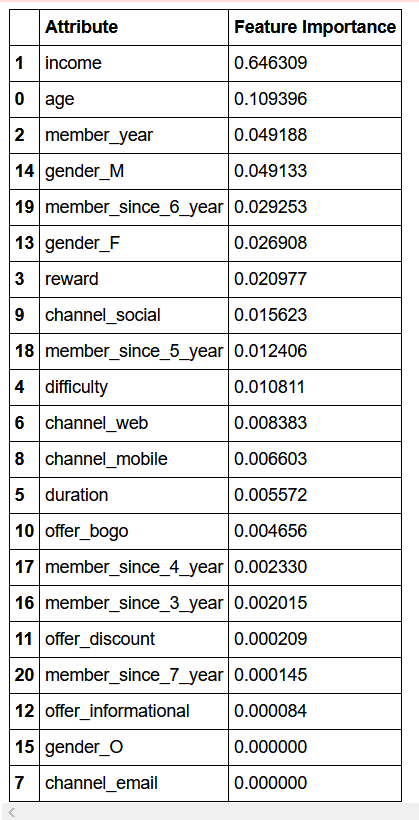
Q4. Which individual attributes contributed the most during the offer window?
Q4。 哪些个人属性在“报价”窗口中贡献最大?
The top three individual attributes that contributed the most are as follows:
贡献最大的前三个属性如下:
1. Income
1.收入
2. Age
2.年龄
3. Start year of membership
3.入会年份
结论 (Conclusion)
We found out that
我们发现
- Buy-one-get-one offers brought in higher revenue compared to the others 买一送一的报价比其他报价带来更高的收入
- Income, age and membership period have the highest impact in the amount spent during an offer period 优惠期间的收入,年龄和会员期限影响最大
- Mobile and email channels are the best in promoting an offer. 移动和电子邮件渠道是推广优惠的最佳途径。
改进之处 (Improvements)
As part of an improvement task, we can try out PCA to find out newer dimenstions leading to exploring different customer segments based on the amount spent across each offer category. Comparing these distributions with the distributions we performed earlier, might give use much more information about which individuals to send different offer codes.
作为改进任务的一部分,我们可以尝试PCA来发现更新的维度,从而根据每个优惠类别上花费的金额来探索不同的客户群。 将这些分布与我们之前执行的分布进行比较,可能会提供更多有关哪些人发送不同报价代码的信息。
星巴克 销售数据分析














 2461
2461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









