





Azure / GCP / AWS / Terraform / Spark (Azure/GCP/AWS/Terraform/Spark)
Five years back when I started working on enterprise big data platforms, the prevalent data lake architecture was to go with a single public cloud provider or on-prem platform. Quickly these data lakes grew into several terabytes to petabytes of structured and unstructured data(only 1% of unstructured data is analyzed or used at all). On-prem data lakes hit capacity issues, while single cloud implementations risked so-called vendor lockin.
五年前,当我开始在企业大数据平台上工作时,流行的数据湖架构是与单个公共云提供商或本地平台一起使用。 这些数据湖很快就增长到数TB到PB的结构化和非结构化数据( 仅对1%的非结构化数据进行了分析或使用 )。 本地数据湖遇到容量问题,而单个云实施存在所谓的供应商锁定风险。
Today, Hybrid Multi-Cloud architectures that use two or more public cloud providers are the preferred strategy. 81% of public cloud users reported using two or more cloud providers.
如今,首选的策略是使用两个或多个公共云提供商的混合多云架构。 81%的公共云用户报告使用了两个或多个云提供商 。

Cloud providers offer various tools and services to move data to the cloud as well as to transform the data. Here in this article, we will create a cloud-native data pipeline using Apache Spark.
云提供商提供了各种工具和服务,可将数据移至云以及进行数据转换。 在本文的此处,我们将使用Apache Spark创建一个云原生数据管道。
创建多云数据平台并在其上运行Spark处理作业 (Create a Multi-Cloud Data Platform and run a Spark Processing job on it)
The use case we are going to build here is:
我们将在此处构建的用例是:
- Create a hybrid cloud infrastructure using Terraform 使用Terraform创建混合云基础架构
Read European Center for Disease Prevention and Control Covid19 Dataset publically available in Azure open datasets
阅读Azure公开数据集中公开提供的欧洲疾病预防和控制中心Covid19数据集
- Extract US, Canadian and German data from the above dataset 从上述数据集中提取美国,加拿大和德国数据
- Create and write the country wise data into separate tables on Amazon Redshift, Azure SQL, and Google Bigquery 创建国家/地区明智数据并将其写入Amazon Redshift,Azure SQL和Google Bigquery上的单独表中
- Use your favorite data analytics tools on AWS, Azure, or GCP to explore the mysteries of Covid19. 在AWS,Azure或GCP上使用您喜欢的数据分析工具来探索Covid19的奥秘。
We will create a Spark ETL Job on Google Cloud Dataproc, which will load ECDC Covid19 data from Azure Blob storage, transform it and then load it to 3 different cloud stores: Amazon Redshift, Azure SQL, and Google BigQuery.
我们将在 Google Cloud Dataproc 上创建一个Spark ETL Job ,它将 从 Azure Blob存储中 加载 ECDC Covid19 数据 ,对其进行转换,然后将其加载到3个不同的云存储中: Amazon Redshift , Azure SQL 和 Google BigQuery 。
Here we automate cloud infrastructure provisoining using Infrastructure as Code(IaC)with Terraform . IaC allows you to easily spin up and shutdown clusters, this way you only run the cluster when you use it.
在这里,我们使用Terraform将基础设施作为代码(IaC)使用来自动化云基础设施的提供。 IaC允许您轻松启动和关闭集群,这样您就可以仅在使用集群时运行它。

先决条件: (Prerequisite:)
This use case can be built and run on AWS/Azure/GCP resources which qualify under free tier. Sign up for Azure/ GCP and AWS public cloud services free credits. Follow the links below to create each of them.
可以在符合免费套餐资格的AWS / Azure / GCP资源上构建和运行此用例。 注册以获得Azure / GCP和AWS公共云服务免费积分。 请按照下面的链接创建每个链接。
Sign up with GCP, get the 300$ free trial
注册GCP,即可获得300美元的免费试用
GCP Free Tier — Free Extended Trials and Always Free | Google CloudGet hands-on experience with popular products, including Compute Engine and Cloud Storage, up to monthly limits. These…cloud.google.com
GCP免费套餐—免费的扩展试用版,并且始终免费| Google Cloud 获得流行产品(包括Compute Engine和Cloud Storage)的动手经验,最高限额为每月。 这些… cloud.google.com
Once you signed up and logged in to the GCP console. Activate Cloud Shell by clicking on the icon highlighted in the below screenshot. Cloud Shell provides command-line access to a virtual machine instance, and this is where we are going to set up our use case. (Alternatively, you can also do this on your laptop terminal)
注册并登录GCP控制台后。 通过单击以下屏幕快照中突出显示的图标来激活Cloud Shell。 Cloud Shell提供了对虚拟机实例的命令行访问,这就是我们要设置用例的地方。 (或者,您也可以在笔记本电脑终端上执行此操作)


a. Create a new GCP project
一个。 创建一个新的GCP项目
Setup the env variables
设置环境变量
Run the following command in the cloud shell terminal:
在云shell终端中运行以下命令:
export PROJECT_NAME=${USER}-dataflow
export TF_ADMIN=${USER}-TFADMIN
export TF_CREDS=~/.config/gcloud/${TF_ADMIN}-terraform-admin.json
export PROJECT_BILLING_ACCOUNT=YOUR_BILLING_ACCOUNT## To get YOUR_BILLING_ACCOUNT run
gcloud beta billing accounts list## To get YOUR_BILLING_ACCOUNT run
gcloud beta billing accounts listCreate and enable project:
创建并启用项目:
gcloud projects create ${PROJECT_NAME} --set-as-default
gcloud config set project ${PROJECT_NAME}gcloud beta billing projects link $PROJECT_NAME \
--billing-account ${PROJECT_BILLING_ACCOUNT}Create a terraform service account:
创建一个terraform服务帐户:
gcloud iam service-accounts create terraform \
--display-name "Terraform admin account"gcloud iam service-accounts keys create ${TF_CREDS} \
--iam-account terraform@${PROJECT_NAME}.iam.gserviceaccount.com \
--user-output-enabled falseGrant terraform service account permission to view and manage cloud storage:
授予terraform服务帐户权限以查看和管理云存储:
gcloud projects add-iam-policy-binding ${PROJECT_NAME} \
--member serviceAccount:terraform@${PROJECT_NAME}.iam.gserviceaccount.com \
--role roles/viewergcloud projects add-iam-policy-binding ${PROJECT_NAME} \
--member serviceAccount:terraform@${PROJECT_NAME}.iam.gserviceaccount.com \
--role roles/storage.admin
gcloud projects add-iam-policy-binding $PROJECT_NAME \
--member serviceAccount:terraform@${PROJECT_NAME}.iam.gserviceaccount.com \
--role roles/bigquery.dataOwner \
--user-output-enabled falseEnable Dataproc API service:
启用Dataproc API服务:
gcloud services enable dataproc.googleapis.com
gcloud services enable bigquery-json.googleapis.comb. Create Dataproc cluster and BigQuery data warehouse using terraform:
b。 使用terraform创建Dataproc集群和BigQuery数据仓库:
Install terraform on the cloud shell terminal(Debina VM), execute
在云Shell终端(Debina VM)上安装terraform,执行
Clone the bellow project for the terraform scripts to create Dataproc and Bigquery
克隆terraform脚本的波纹管项目以创建Dataproc和Bigquery
cd ~
git clone https://github.com/ksree/dataflow-iac.gitRun terraform to create Dataproc cluster, BigQuery data warehouse, and GCS bucket
运行terraform以创建Dataproc集群,BigQuery数据仓库和GCS存储桶
cd ~/dataflow-iac/dataproc
terraform init
terraform apply -auto-approve \
-var="project_name=$PROJECT_NAME" \
-var="bucket_name=${PROJECT_NAME}_file_output_store"2. Sign up with Azure for free
2.免费注册Azure
Create your Azure free account today | Microsoft AzureTest and deploy enterprise apps Use Azure Virtual Machines, managed disks, and SQL databases while providing high…azure.microsoft.com
立即创建您的Azure免费帐户| Microsoft Azure 测试和部署企业应用程序使用Azure虚拟机,托管磁盘和SQL数据库,同时提供较高的性能 。azure.microsoft.com
Terraform supports a number of different methods for authentication to Azure:
Terraform支持多种用于Azure身份验证的方法:
We will use the Service Principal authentication method because this will come in handy when we what to automate this whole process(think CICD)
我们将使用服务主体身份验证方法,因为这在我们使整个过程自动化时会派上用场(请考虑一下CICD)
Register terraform with Azure AD and create a service principal * :
向Azure AD注册terraform并创建服务主体 * :
a. Create Application and Service Principal:
一个。 创建应用程序和服务主体:
Navigate to the Azure Active Directory overview within the Azure Portal — then select the App Registrations blade. Click the New registration button at the top to add a new Application within Azure Active Directory. On this page, set the following values then press Create:
导航到Azure门户内的Azure Active Directory概述 -然后选择“ 应用程序注册”刀片 。 单击顶部的“ 新建注册”按钮以在Azure Active Directory中添加新的应用程序。 在此页面上,设置以下值,然后按创建 :
Name — DataflowTerraformApp
名称 — DataflowTerraformApp
Supported Account Types — this should be set to “Accounts in this organizational directory only (single-tenant)”
支持的帐户类型 -应设置为“仅此组织目录中的帐户(单租户)”
Redirect URI — you should choose “Web” in for the URI type. the actual value can be left blank
重定向URI-您应在URI类型中选择“ Web”。 实际值可以留为空白

b. Generating a Client Secret for the Azure Active Directory Application
b。 为Azure Active Directory应用程序生成客户端密钥
Now that the Azure Active Directory Application exists we can create a Client Secret that can be used for authentication — to do this select Certificates & secrets. This screen displays the Certificates and Client Secrets (i.e. passwords) which are associated with this Azure Active Directory Application.
现在,Azure Active Directory应用程序已经存在,我们可以创建可用于身份验证的客户端密钥-为此,请选择证书和密钥 。 此屏幕显示与此Azure Active Directory应用程序关联的证书和客户端机密(即密码)。
Click the “New client secret” button, then enter a short description, choose an expiry period, and click “Add”. Once the Client Secret has been generated it will be displayed on screen — the secret is only displayed once so be sure to copy it now (otherwise you will need to regenerate a new one). This is the client_secretyou will need.
单击“新客户密码”按钮,然后输入简短说明,选择有效期,然后单击“添加”。 生成客户机密后,它将显示在屏幕上- 该机密仅显示一次,因此请确保立即复制它 (否则,您将需要重新生成一个新的机密 )。 这是您需要的client_secret。

export ARM_CLIENT_ID=”d9644b52-ae20–410f-bf70–32d0e324084d”export ARM_CLIENT_SECRET=”XXXXXXXXXXXXXXXX”export ARM_TENANT_ID=”fa6dd69f-ba26–418c-8dc5–525f88d2d963"
导出ARM_CLIENT_ID =” d9644b52-ae20–410f-bf70–32d0e324084d”导出ARM_CLIENT_SECRET =” XXXXXXXXXXXXXXXX”导出ARM_TENANT_ID =” fa6dd69f-ba26–418c-8dc5dc-525f88d2d963”

Assign a role to the applicationTo access resources in your subscription, you must assign a role to the application. Here we will assign a role at the subscription scope.
为应用程序分配角色要访问订阅中的资源,必须为应用程序分配角色。 在这里,我们将在订阅范围内分配角色。
a). Search for and select Subscriptions or select Subscriptions on the Home page
一个)。 搜索并选择“ 订阅”,或者在主页上选择“ 订阅 ”

b). On the subscriptions page, click on your free subscription
b)。 在订阅页面上,单击免费订阅
Store the subscription ID as environment variables, as bellow:
将订阅ID存储为环境变量,如下所示:
For me the value is:
对我来说,价值是:
export ARM_SUBSCRIPTION_ID=”728ed9d5-a71a-4f39-b25b-a293943d7a06"
导出ARM_SUBSCRIPTION_ID =” 728ed9d5-a71a-4f39-b25b-a293943d7a06”

c). Select Access control (IAM).
C)。 选择访问控制(IAM) 。
d). Select Add role assignment.
d)。 选择添加角色分配 。
For the role select Owner(Contributor role will not work)
为角色选择所有者(贡献者角色将不起作用)
Select DataflowTerraformApp
选择DataflowTerraformApp

e). Select Save to finish assigning the role. You see your application in the list of users with a role for that scope.
e)。 选择保存以完成角色分配。 您会在具有该作用域角色的用户列表中看到您的应用程序。
Your service principal is set up.
您的服务主体已设置。
On Google Cloud Shell terminal, run the below commands to set up the environment variables for Azure auth
在Google Cloud Shell终端上 ,运行以下命令来设置Azure身份验证的环境变量
export ARM_CLIENT_ID="" #Fill in your client secret
export ARM_CLIENT_SECRET="" #Fill in your client secret
export ARM_TENANT_ID="" #Fill in your tenant id
export ARM_SUBSCRIPTION_ID="" #Fill in your subscription idOn Google Cloud Shell terminal, run the bellow terraform command to create Azure SQL database
在Google Cloud Shell终端上 ,运行bellow terraform命令以创建Azure SQL数据库
cd ~/dataflow-iac/azure
export ip4=$(/sbin/ip -o -4 addr list eth0 | awk '{print $4}' | cut -d/ -f1)
terraform init
terraform plan
terraform apply -auto-approveThis will create your Azure SQL Database, and you will see the output as bellow
这将创建您的Azure SQL数据库,并且您将在下面看到输出

Verify Azure SQL installation:
验证Azure SQL安装:
Search for and select Azure SQL, or select Azure SQL on the Home page
搜索并选择Azure SQL ,或在主页上选择Azure SQL

On the Azure SQL Home page, you will see the newly created SQL server and database.
在Azure SQL主页上,您将看到新创建SQL Server和数据库。

3. Sign up with AWS free tier
3.使用 AWS免费套餐进行 注册
Follow the AWS documentation to create a user with Programmatic access and Administrator permissions by attaching the AdministratorAccess policy directly. *
按照AWS文档的说明 ,通过直接附加AdministratorAccess策略来创建具有程序访问和管理员权限的用户。 *
Create a user DataflowTerraformApp, and attach the existing policies directly:
创建一个用户DataflowTerraformApp,并直接附加现有策略:
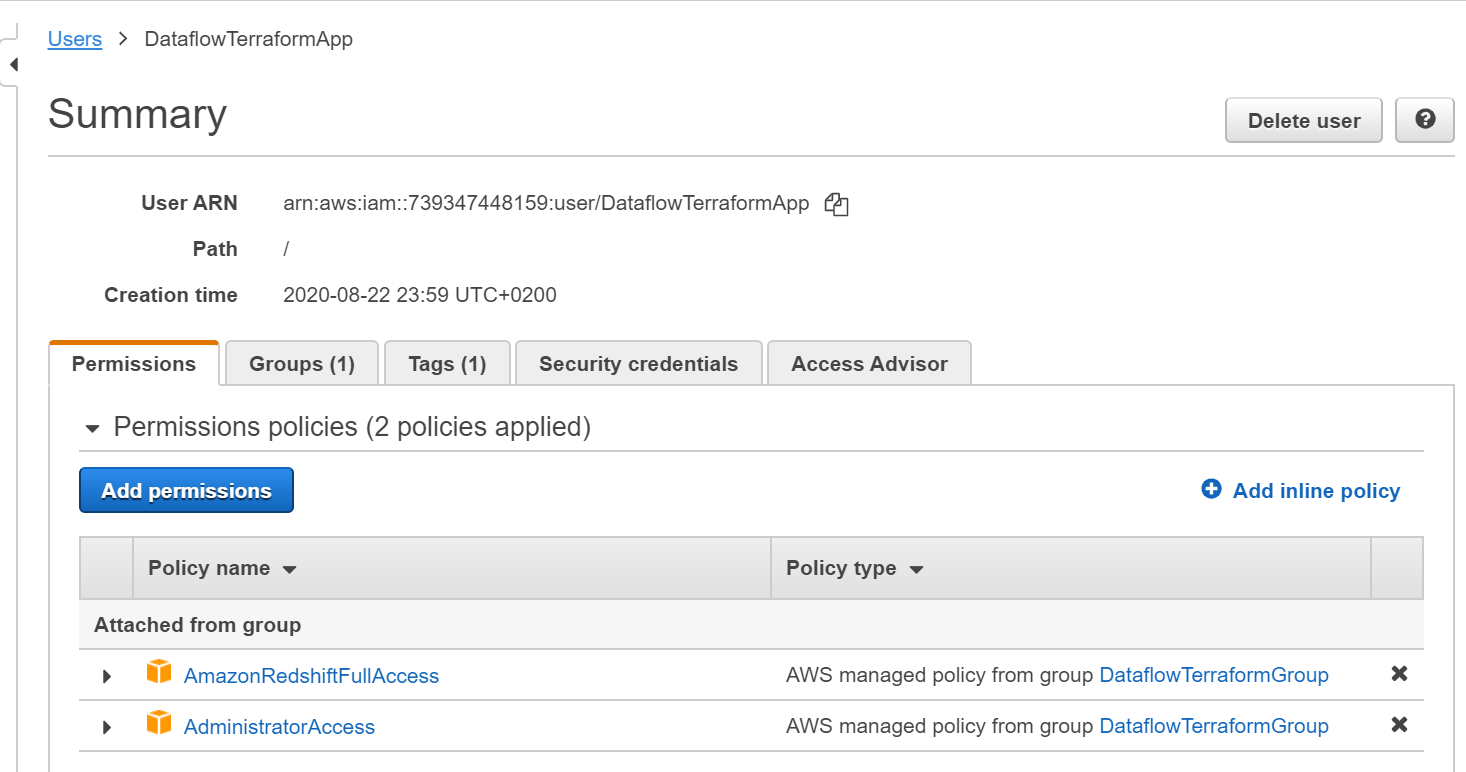
When you create the user, you will receive an Access Key ID and a secret access key. Create new environment variables as bellow, and run it in Google Terminal Shell
创建用户时,您将收到一个访问密钥ID和一个秘密访问密钥 。 在下面创建新的环境变量,然后在Google Terminal Shell中运行它
export AWS_ACCESS_KEY_ID="YOUR_ACCESS_ID"
export AWS_SECRET_ACCESS_KEY="YOUR_SECRECT_ACCESS_KEY"Create Amazon Redshift cluster and database:
创建Amazon Redshift集群和数据库:
cd ~/dataflow-iac/aws
terraform init
terraform apply -auto-approveVerify the Redshift cluster on your AWS console:
在您的AWS控制台上验证Redshift集群:

Finally, we are done with the infrastructure setup. We have created the required resources on GCP, AWS, and Azure.
最后,我们完成了基础架构设置。 我们已经在GCP,AWS和Azure上创建了所需的资源。
The next step is to set up the Spark Job.
下一步是设置Spark Job。
Download and build the spark ETL framework.
下载并构建spark ETL框架。
https://github.com/ksree/dataflow.git
https://github.com/ksree/dataflow.git
Execute the following command on your cloud shell terminal:
在您的Cloud Shell终端上执行以下命令:
sudo apt-get install -y openjdk-8-jre
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
cd ~
git clone https://github.com/ksree/dataflow.git
cd ~/dataflow/#Update the storage bucket name in the covid job config file
sed -i -e 's/<BUCKET_NAME>/'${PROJECT_NAME}'_file_output_store/g' ~/dataflow/src/main/resources/config/covid_tracking.yaml
mvn clean install -DskipTestsOutput:
输出:

Run spark job
运行火花作业
Execute the below command on cloud shell
在云外壳上执行以下命令
Verify the output:
验证输出:
Azure SQL Server
Azure SQL服务器
a. On the Azure SQL page, click on the database dataflowazuresqldatabase
一个。 在Azure SQL页面上,单击数据库数据流Azure SQL数据库
b. On the SQL Database page, click on Query editor to open
b。 在“ SQL数据库”页面上,单击查询编辑器以打开
You will see the two newly created tables: dbo.casesInCanada and dbo.casesInUs
您将看到两个新创建的表:dbo.casesInCanada和dbo.casesInUs


2. AWS Redshift:
2. AWS Redshift:
Login to Amazon console, Redshift Query editor, to view the 2 new tables generated.
登录到Amazon控制台,Redshift Query编辑器,以查看生成的2个新表。


3. GCP BigQuery
3. GCP BigQuery
Login to GCP BigQuery console to view your newly generated tables
登录到GCP BigQuery控制台以查看您新生成的表

Awesome !!!
太棒了!!!
Now that we are done, its time to terminate all the cloud resources that we created.
现在我们已经完成了,是时候终止我们创建的所有云资源了。
#Terminate AWS resources
cd ~/dataflow-iac/aws/
terraform destroy -auto-approve#Terminate Azure resources
cd ~/dataflow-iac/azure/
terraform destroy -auto-approve#Terminate GCP resources
cd ~/dataflow-iac/gcp/
terraform destroy -auto-approve \
-var="project_name=$PROJECT_NAME" \
-var="bucket_name=${PROJECT_NAME}_file_output_store"回顾: (Recap:)
Here we created a hybrid cloud infrastructure and used Apache Spark to read process and write real-time Covid19 dataset into three different cloud storage locations.
在这里,我们创建了一个混合云基础架构,并使用Apache Spark读取过程并将实时Covid19数据集写入三个不同的云存储位置。
Infrastructure Provisioning: Infrastructure as Code(IaC) to provision and manage multi-cloud infrastructure using Terraform
基础架构设置 :基础架构即代码(IaC),可使用Terraform设置和管理多云基础架构
Data Processor: Apache Spark running on Google Dataproc
数据处理器 :在Google Dataproc上运行的Apache Spark
Data Source: ECDC Covid-19 dataset on Azure Blog Storage
数据源 : Azure Blog Storage上的ECDC Covid-19数据集
Data Sink/Destination: We wrote to 3 different cloud storage.
数据接收器/目标 :我们写入了3种不同的云存储。















 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









