





Rendering 3D models from 2D images is a challenging problem in the computer vision area. Even though we have camera position supervision for each image, previous 3D rendering models are not sufficient to use in practice. NeRF, which is selected as an oral paper in ECCV, proposed a state-of-the-art method that constructs a 3D model with 2D images and their corresponding camera positions.
从2D图像渲染3D模型是计算机视觉领域的一个难题。 即使我们对每个图像都进行了摄像机位置监控,但以前的3D渲染模型仍不足以在实践中使用。 NeRF被选为ECCV的口头论文,它提出了一种先进的方法,该方法可构建具有2D图像及其对应相机位置的3D模型。
术语 (Terminologies)
Ray: Line connected from a camera center, determined by camera position parameters, in a particular direction, determined by camera angle parameters.
射线 :从相机中心连接的线,由相机位置参数确定,在特定方向上,由相机角度参数确定。
Color: RGB value that each 3D volume has.
颜色 :每个3D体积具有的RGB值。
Volume Density: Determines how much it is affecting the final color determination.
体积密度 :确定影响最终颜色确定的程度。
Ray Color: RGB values that we can observe when we are following the ray. The formal definition is in Equation 1.
射线颜色 :跟随射线时可以观察到的RGB值。 正式定义在公式1中。
什么是NeRF? (What is NeRF?)
NeRF is the first paper that introduces neural scene representation. It is advantageous for rendering high-resolution photorealistic novel views of real objects. This paper’s key idea is to predict the color values and the opacity values along the ray, which is determined by five extrinsic camera parameters (3 camera positions, two camera angles).
NeRF是介绍神经场景表示的第一篇论文。 渲染真实对象的高分辨率逼真的新颖视图是有利的。 本文的主要思想是预测光线的颜色值和不透明度值,该值由五个外部相机参数(3个相机位置,两个相机角度)确定。
Eventually, with estimated colors and opacities, NeRF determines a ray’s expected color (Equation 1). For practical implementation, NeRF approximates integral to a finite sum(Equation 2), called stratified sampling. The number of samples is 64, 128, 256 in the experiments.
最终,通过估计的颜色和不透明度,NeRF可以确定射线的预期颜色(公式1)。 对于实际实现,NeRF将积分近似为一个有限的总和(方程式2),称为分层采样 。 在实验中,样本数量为64、128、256。
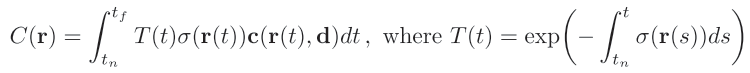
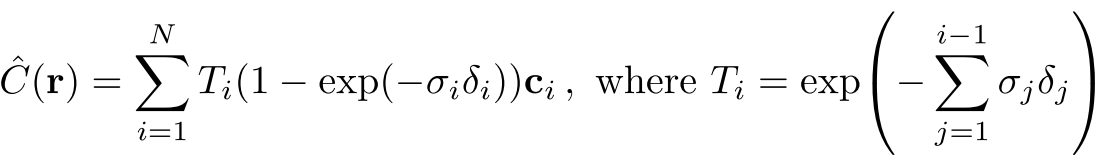
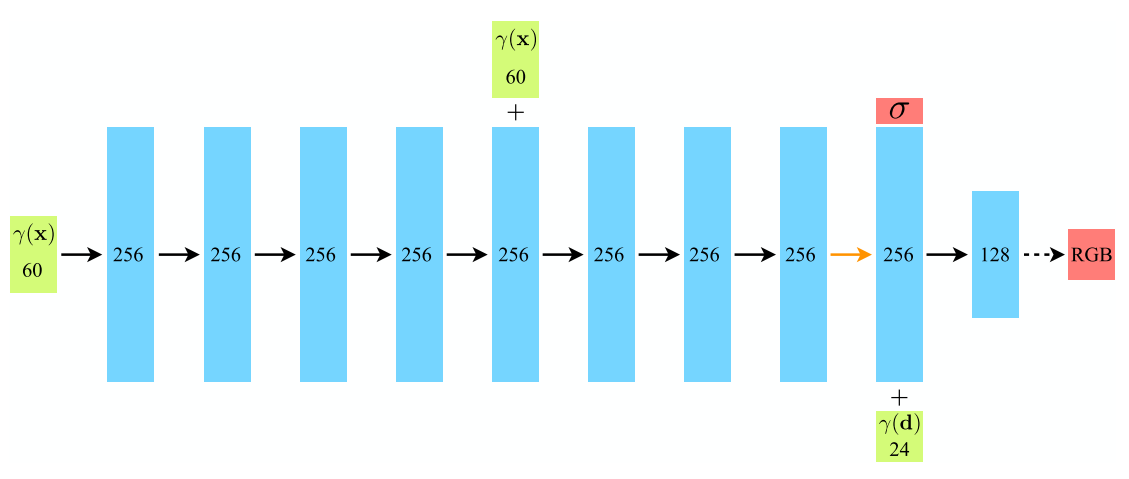
NeRF architecture doesn’t need to conserve each feature; thus, NeRF is composed of MLP rather than CNN. It also uses two techniques to improve its performance: positional encoding and hierarchical volume sampling.
NeRF架构不需要保留每个功能; 因此,NeRF由MLP而非CNN组成。 它还使用两种技术来改善其性能: 位置编码和分层体积采样 。
位置编码 (Positional Encoding)
Rather than using five naive camera parameters, NeRF uses positional encoding, which is often used in NLP(Natural Language Processing). Using naive input often performs poorly at high-frequency variation in color and geometry. Positional encoding facilitates the network to optimize the parameters by mapping input to higher-dimensional space easily. NeRF showed that using a high-frequency function for mapping original input enables better fitting of data that contains high-frequency variation. The ablation study is evidence for this argument(Table 1).
NeRF不使用五个朴素的相机参数,而是使用位置编码,该编码通常在NLP(自然语言处理)中使用。 在色彩和几何形状发生高频变化时,使用朴素的输入通常效果不佳。 位置编码通过轻松地将输入映射到高维空间来促进网络优化参数。 NeRF显示,使用高频函数映射原始输入可以更好地拟合包含高频变化的数据。 消融研究证明了这一观点(表1)。
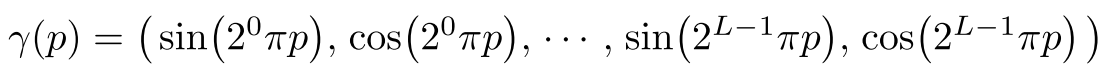

分层体积采样 (Hierarchical Volume Sampling)
NeRF proposes a hierarchical structure. The overall network architecture is composed of two networks: the coarse network and the fine network.
NeRF提出了一种层次结构。 整个网络架构由两个网络组成: 粗略网络和精细网络 。
The coarse network uses N_c sample points to evaluate the expected color of a ray. As its name reveals, it first optimizes from the coarse sampling. Equation 4 is the formal definition of the coarse network.
粗略网络使用N_c个采样点来评估射线的预期颜色。 顾名思义,它首先从粗采样中进行优化。 公式4是粗略网络的形式定义。
The fine network uses N_c + N_f = N sample points to evaluate a ray’s expected color. The equation for this is the same as Equation 2. Table 2 shows an ablation study about the effect of hierarchical structure. However, in my humble opinion, it is not a fair comparison between (4) and (7) in Table 2. It is because N_c + N_f is not the same between (4) and (7). If the N_f value in (4) is 192(=128 + 64), it might be a more fair comparison.
精细网络使用N_c + N_f = N个采样点来评估射线的预期颜色。 此公式与公式2相同。表2显示了有关分层结构效果的消融研究。 但是,以我的拙见,表2中的(4)和(7)之间不是一个公平的比较。这是因为N_c + N_f在(4)和(7)之间不相同。 如果(4)中的N_f值为192(= 128 + 64),则比较可能更公平。

损失函数 (Loss Function)
The ultimate goal of this network is to predict the expected color value for the ray correctly. Since we can estimate the ground truth ray color with the ground truth 3D model, we can use L2-distance with the RGB values as a loss. Fortunately, every step is differentiable; thus, we can optimize the network by the predicted RGB value of rays.
该网络的最终目标是正确预测射线的预期颜色值。 由于我们可以使用地面真实3D模型估算地面真实光线颜色,因此可以将L2距离与RGB值一起用作损失。 幸运的是,每一步都是不同的。 因此,我们可以通过光线的RGB预测值优化网络。
The authors designed the loss function to achieve two goals.
作者设计了损失函数以实现两个目标。
- Well optimizes the coarse network. 很好地优化了粗略网络。
- Well optimizes the fine network. 好优化精细网络。
结果 (Result)
-评估指标 (- Evaluation Metric)
PSNR(Peak Signal-to-Noise Ratio): higher PSNR, lower MSE. Lower MSE implies less difference between the ground truth image and the rendered image. Thus, higher PSNR, the better model.
PSNR (峰值信噪比):较高的PSNR,较低的MSE。 较低的MSE表示地面真实图像和渲染图像之间的差异较小。 因此,PSNR越高,模型越好。
SSIM(Structural Similarity Index): Checks the structural similarity with the ground truth image model. Higher SSIM, the better model.
SSIM (结构相似性指数): 与地面真实图像模型检查结构相似性。 SSIM越高,模型越好。
LPIPS(Learned Perceptual Image Patch Similarity): Determines the similarity with the view of perception; using VGGNet. Lower LPIPS, the better model.
LPIPS (学习的知觉图像补丁相似度):确定与感知角度的相似度; 使用VGGNet。 LPIPS越低,模型越好。
-实验结果(定量结果) (- Experiment Result (Quantitative Result))

NeRF achieved state-of-the-art performance for all tasks.
NeRF在所有任务上均达到了最先进的性能。
-可视化(定性结果) (- Visualization (Qualitative Result))

NeRF also solved the view-dependency problem that models have different colors depending on the view. As shown in Figure 3, NeRF architecture automatically learns view-dependent color value, unlike other models.
NeRF还解决了视图依赖问题 ,即模型根据视图具有不同的颜色。 如图3所示,与其他模型不同,NeRF体系结构会自动学习与视图相关的颜色值。

结论 (Conclusion)
NeRF demonstrated that representing scenes as 5D neural radiance fields produces better renderings than the previously-dominant approach of training deep convolutional networks to output discretized voxel representations. The authors expect that the NeRF model can be further optimized with different structures. Moreover, the interpretability of NeRF is inferior to the previous approaches, such as voxel and mesh.
NeRF证明,将场景表示为5D神经辐射场比以前训练深层卷积网络输出离散体素表示的主流方法能产生更好的渲染。 作者期望可以使用不同的结构进一步优化NeRF模型。 而且,NeRF的可解释性不如以前的方法,例如体素和网格。
Paper Link: https://arxiv.org/abs/2003.08934
论文链接: https : //arxiv.org/abs/2003.08934
Official NeRF Link: https://www.matthewtancik.com/nerf
官方NeRF链接: https ://www.matthewtancik.com/nerf
Feel free to contact me! “ jeongyw12382@postech.ac.kr”
随时联系我! “ jeongyw12382@postech.ac.kr”














 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









