







 NeRF-W是一种基于NeRF的扩展,旨在从非结构化的互联网照片集合中重建复杂场景。它通过学习潜在的外观模型来处理光照变化和瞬时对象,提供时间一致的新视图渲染。NeRF-W在不受控制的图像上显著改善了重建质量和一致性,适用于大规模野外场景的3D重建。
NeRF-W是一种基于NeRF的扩展,旨在从非结构化的互联网照片集合中重建复杂场景。它通过学习潜在的外观模型来处理光照变化和瞬时对象,提供时间一致的新视图渲染。NeRF-W在不受控制的图像上显著改善了重建质量和一致性,适用于大规模野外场景的3D重建。
目录
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections不受约束的照片集
4.1. Latent Appearance Modeling
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections不受约束的照片集
Abstract
我们提出了一种基于学习的方法,仅使用野外照片的非结构化集合using only unstructured collections of in-the-wild photographs来合成复杂场景的新视图。我们建立在神经辐射场(NeRF)的基础上,它使用多层感知器的权重来模拟场景的密度和颜色作为3D坐标的函数。虽然NeRF在受控设置下under controlled settings捕捉的静态对象static subjects图像上工作良好,但它无法在不受控制的图像uncontrolled images中建模许多普遍存在的真实世界现象ubiquitous, real-world phenomena ,如可变照明或瞬时遮光器variable illumination or transient occluders。我们引入了一系列对NeRF的扩展来解决这些问题,从而使从互联网上获取的非结构化图像集合的精确重建成为可能。我们将我们的系统(称为NeRF-W)应用于著名地标的互联网照片集合,并展示了比现有技术更接近照片真实感的时间一致temporally consistent 的新视图渲染。
1.Introduction
从一组稀疏的捕获图像中合成场景的新视图是计算机视觉中长期存在的问题,也是许多AR和VR应用程序的先决条件。虽然经典技术已经使用基于运动的结构[11]或基于图像的渲染[29]解决了这个问题,但由于神经渲染技术——嵌入3D几何背景中的基于学习的模块,并经过训练以重建观察到的图像,该领域最近取得了重大进展。神经辐射场(NeRF)方法[24]使用神经网络的权重对场景的辐射场和密度进行建模。然后使用体绘制来合成新的视图,在一系列具有挑战性的场景中展示了前所未有的逼真度。然而,NeRF仅被证明在受控设置controlled settings中工作良好:场景在短时间内被捕获,在此期间照明效果保持不变,并且场景中的所有内容都是静态的。正如我们将要证明的,当遇到移动物体或变化的照明时,NeRF的性能会显著下降。这一限制禁止将NeRF直接应用于大规模野外场景large-scale in-the-wild scenarios,在这些场景中,输入图像可能相隔数小时或数年拍摄,并且可能包含行人和车辆。
我们在这里讨论的NeRF的主要局限性是它假设世界在几何上、物质上和光度上是静态的geometrically, materially, and photometrically static——世界的密度density和亮度radiance是恒定的。因此,NeRF要求在同一位置和方向拍摄的任何两张照片必须相同。这一假设在许多真实世界的数据集中被严重违反,例如旅游地标的大规模互联网照片集合。两个摄影师可能站在同一个地点,拍摄同一个地标,但是在这两张照片之间的时间里,世界可能会发生巨大的变化:汽车和人可能会移动,施工可能会开始或结束,季节和天气可能会改变,太阳可能会在天空中移动,等等。即使是在同一时间和同一地点拍摄的两张照片也可能表现出相当大的差异:曝光、色彩校正和色调映射exposure, color correction, and tone-mapping都可能因相机和后期处理而异。我们将证明天真地将NeRF应用于野外照片集合会导致不准确的重建,表现出严重的重影、过度平滑和更多的伪像severe ghosting, oversmoothing, and further artifacts。
为了处理这些苛刻的场景,我们提出了NeRF- W,它是NeRF的一个扩展,放宽了严格的一致性假设strict consistency as- sumptions。首先,我们在学习的低维潜在空间learned low-dimensional latent space中对每个图像的外观变化进行建模,如曝光、照明、天气和后处理appearance variations such as exposure, lighting, weather, and post-processing。遵循生成潜在优化Generative Latent Optimization[3]的框架,我们优化了每个输入图像的外观嵌入appearance embedding,从而赋予NeRF-W 通过学习整个照片集合的共享外观表示来解释图像之间的光度和环境变化的 灵活性。如图1所示,所学习的潜在空间提供了对输出渲染外观的控制。(b)。第二,我们将场景建模为共享元素和依赖于图像的元素的联合union of shared and image-dependent elements,从而能够将场景内容无监督地分解为“静态”和“瞬时”组件“static” and “transient” components。我们的方法使用与数据相关的不确定性场data-dependent uncertainty field相结合的次级体积辐射场secondary volumetric radiance field来模拟瞬态元素,其中不确定性场捕捉可变的观测噪声variable observation noise并进一步减少瞬态对象对静态场景表示的影响。因为优化能够识别和忽略瞬时图像内容,所以我们可以通过仅渲染静态组件来合成新视图的真实渲染。

图1:仅给定一个互联网照片集合(a),我们的方法能够渲染具有可变照明(b).的新视图。
我们将NeRF-W应用于几个具有挑战性的文化地标野外照片集in-the-wild photo collections of cultural landmarks,并表明它可以从新视角产生详细的高保真效果detailed, high-fidelity renderings,大大超过了的现有技术水平的PSNR和MS-SSIM。与以前的工作不同,我们的模型渲染显示出平滑的外观插值和时间一致性smooth appearance interpolation and tem- poral consistency,即使对于宽相机轨迹wide camera trajectories。我们发现NeRF-W在出现外观变化和短暂性遮挡物appearance variation and transient occluders的情况下比NeRF显著提高了质量,而在受控设置下in controlled settings获得了类似的质量。

图2:来自用于训练NeRF-W的摄影旅游数据集Phototourism dataset[13]的野外照片示例。由于可变照明和后处理variable illumination and post-processing(上图),同一物体的颜色可能因图像而异。野外照片也可能包含短暂的遮挡对象transient occluding subjects(下图)。
3. Background
我们的目标是生成一个系统,它将照片集合作为输入,然后学习能够生成该集合的照片的3D表示。这种场景表示应该将场景的3D结构与外观信息一起编码,以便能够合成新的、看不见的视图。下面我们描述神经辐射场[24] (NeRF),NeRF-W扩展的3D场景重建方法。
NeRF使用在有界3D体积上定义的学习的连续体积辐射场Fθ来表示场景。使用多层感知器(MLP)对Fθ建模,该感知器将3D位置x = (x,y,z)和单位范数观察方向d = (dx,dy,dz)作为输入,并产生密度σ和颜色c = (r,g,b)作为输出。为了计算单个像素的颜色,NeRF使用数值积分来近似体绘制积分[21]。设r(t) = o + td是通过图像平面上的给定像素从摄像机o的投影中心发出的摄像机光线。该像素的预期颜色cˇ(r)的NeRF近似值为:
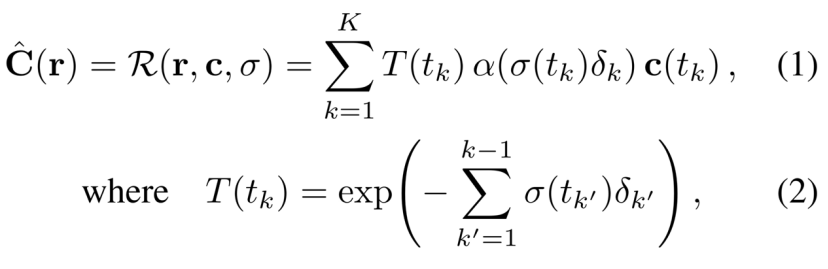
其中R(r,c,σ)是颜色c和密度σ的体绘制,其中c(t)和σ(t)是r(t)点的颜色和密度,α(x)= 1 -exp(-x),δk = tk+1 tk是两个正交点之间的距离。分层采样用于选择tn和tf(摄像机的近平面和远平面)之间的正交点{tk}Kk=1。


生成σ(t)和c(t)的最终激活分别是ReLU和sigmoid,因为密度必须是非负的,颜色必须在[0,1]中。与[24]不同,我们将神经网络描述为两个MLP,其中后者取决于前者的一个输出z(t),以强调体积密度σ(t)与观察方向d无关的事实。

为了拟合参数θ,NeRF使RGB图像集合{Ii }Ni=1,Ii ∈ [0,1]H ×W ×3的重建误差平方和最小。每个图像Ii都与其相应的内在和外在的camera参数配对,这些参数可以使用运动结构来估计[27]。我们预先计算对应于来自图像I的像素j的相机光线组{rij }H ×W ×3,其中j=1,每条光线以方向dij穿过3D位置oi,其中rij(t)=oi +tdij。
为了提高采样效率,NeRF同时优化两个MLP:一个粗略模型和一个精细模型,其中由粗略模型预测的密度确定精细模型的正交点采样。两个模型的参数都通过最小化以下损失来优化:
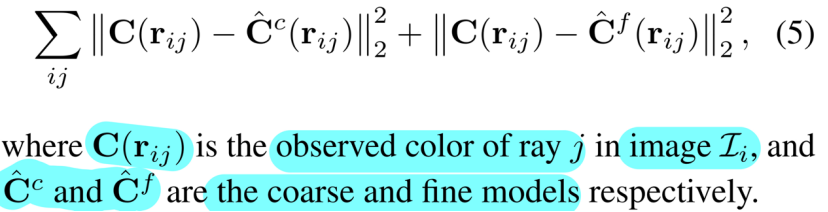
4. NeRF in the Wild
我们现在介绍NeRF-W,一个从野外照片集in-the-wild photo collections中重建3D场景的系统。我们在NeRF [24]的基础上,引入了两个专门为应对无约束图像unconstrained imagery挑战而设计的增强功能。

NeRF在其输入视图中假设一致性:在两幅不同的图像中从相同的位置和观察方向观察到的3D空间中的点具有相同的强度intensity。但是,由于两个不同的现象,互联网照片(如图2所示)违背了这一假设:1)光度变化Photometric variation:在室外摄影中,一天中的时间和大气条件直接影响场景中物体的照明(以及因此产生的辐射)。由于自动曝光设置、白平衡和照片色调映射auto-exposure settings, white balance, and tone-mapping 的变化可能导致额外的光度不一致additional photometric inconsistencies[4],摄影成像管道photographic imaging pipelines加剧了这一问题。2)瞬时物体Transient objects:现实世界的地标很少被孤立地捕捉,它们周围没有移动的物体或遮挡物。地标的旅游照片尤其具有挑战性,因为它们通常包含摆拍的人类主体和其他行人。
我们提出两个模型组件来解决这些问题。在第4.1节中,我们扩展了NeRF,以允许图像相关的外观和光照变化image- dependent appearance and illumination variations ,从而可以显式地模拟图像之间的光度差异。在第4.2节中,我们进一步扩展了这个模型,允许瞬时物体被联合估计并从3D世界的静态表示中分离出来allowing transient objects to be jointly estimated and disen- tangled from a static representation of the 3D world。图3显示了所提议的模型架构的概述。
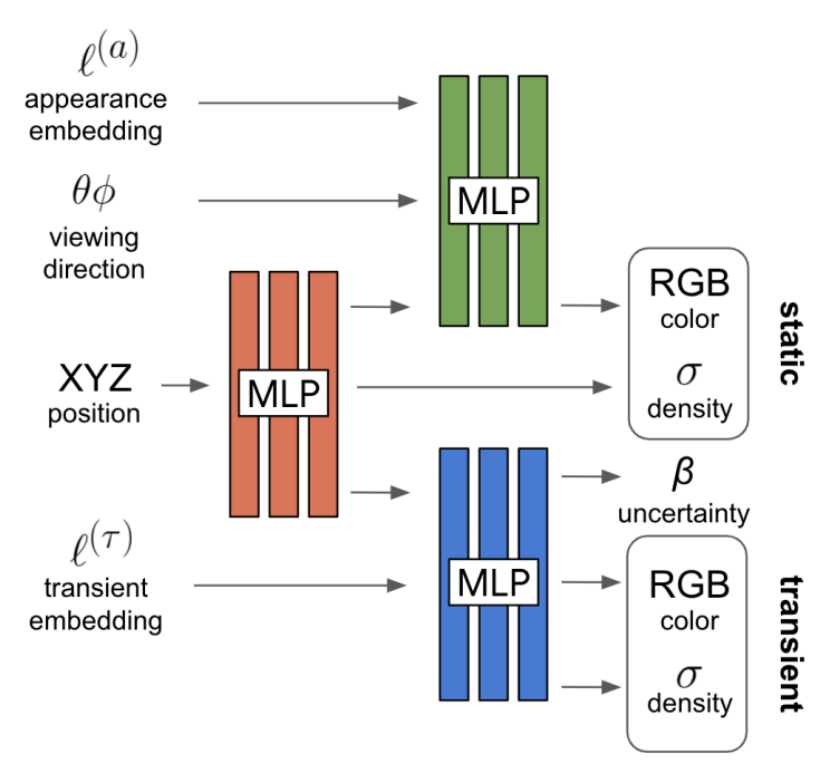
图3:NeRF-W模型架构。给定一个三维位置、观察方向、学习的外观和瞬态嵌入,NeRF-W产生静态和瞬态的颜色和密度以及不确定性的度量a measure of uncertainty。请注意,静态不透明度static opacity是基于外观嵌入,在模型之前生成的,确保静态几何static geometry在所有图像中共享。
4.1. Latent Appearance Modeling

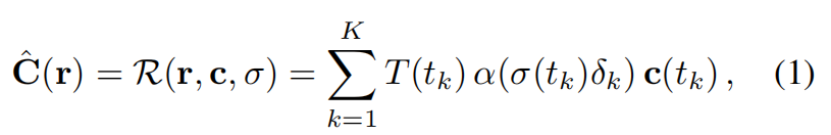
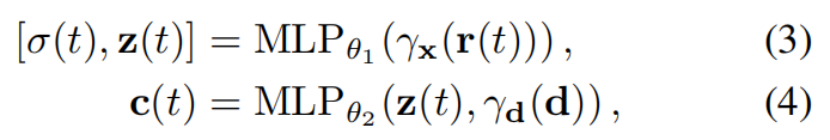
使用这些外观嵌入仅作为发射颜色的网络分支的输入,授予我们的模型在特定图像中改变场景的发射辐射的自由,同时仍然保证3D几何形状(先前由MLPθ1预测)是静态的并且在所有图像中共享。通过将n(a)设置为一个较小的值,我们鼓励优化以确定一个可以嵌入照明条件的连续空间,从而实现条件之间的平滑插值,如图8所示。

图8:两个训练图像(左,右)的外观嵌入`(a)之间的插值,这导致渲染(中间),其中颜色和照明被插值,但几何形状是固定的。请注意,训练图像包含不出现在渲染图中的人物(左)和灯光(右)。
4.2. Transient Objects
我们使用两种不同的设计决策来解决瞬态现象transient phenomena:首先,我们将NeRF中使用的颜色发射MLP color-emitting MLP(等式(4))
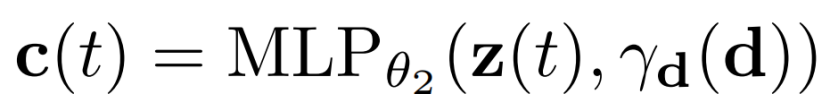 指定为我们模型的“静态”头部“static” head,并且我们添加额外的“瞬态”头部additional “transient” head,该头部发射其自身的颜色和密度,其中该密度允许在训练图像之间变化。这使得NeRF-W能够重建包含遮光器occluders的图像,而不会在静态场景表示中引入伪像artifacts。第二,不是假设所有观察到的像素颜色都同样可靠,而是允许我们的瞬态头部发射不确定场emit a field of uncertainty(很像我们现有的颜色和密度场),这允许我们的模型调整其重建损失adapt its reconstruction loss,以忽略不可靠的像素和可能包含遮光物的3D位置。我们将每个像素的颜色建模为各向同性的正态分布isotropic normal distribution,我们将最大化其可能性likelihood,并且我们使用与NeRF使用的相同的体绘制方法来“绘制”该分布的方差。这两个模型组件允许NeRF-W在没有明确监督的情况下理清disentangle静态和瞬态现象。
指定为我们模型的“静态”头部“static” head,并且我们添加额外的“瞬态”头部additional “transient” head,该头部发射其自身的颜色和密度,其中该密度允许在训练图像之间变化。这使得NeRF-W能够重建包含遮光器occluders的图像,而不会在静态场景表示中引入伪像artifacts。第二,不是假设所有观察到的像素颜色都同样可靠,而是允许我们的瞬态头部发射不确定场emit a field of uncertainty(很像我们现有的颜色和密度场),这允许我们的模型调整其重建损失adapt its reconstruction loss,以忽略不可靠的像素和可能包含遮光物的3D位置。我们将每个像素的颜色建模为各向同性的正态分布isotropic normal distribution,我们将最大化其可能性likelihood,并且我们使用与NeRF使用的相同的体绘制方法来“绘制”该分布的方差。这两个模型组件允许NeRF-W在没有明确监督的情况下理清disentangle静态和瞬态现象。
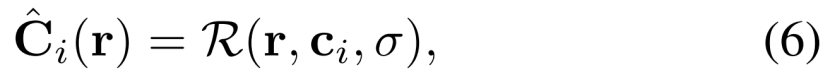
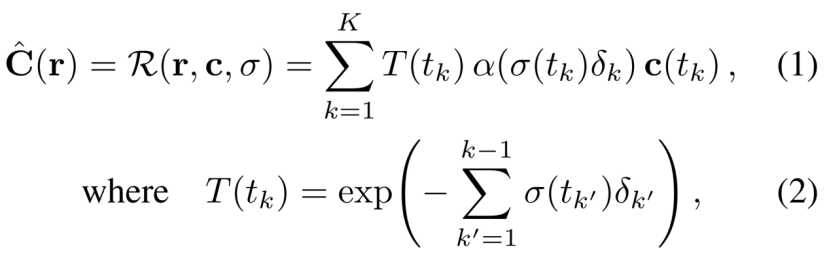

我们采用Kendall等人[15]的贝叶斯学习框架Bayesian learning framework来模拟观察到的颜色的不确定性。我们假设观察到的像素强度pixel intensities是固有的噪声(任意的)inherently noisy (aleatoric),并且进一步假设这种噪声是依赖于输入的(异质的)input-dependent (het- eroscedastic)。我们用各向同性正态分布isotropic normal distribution 对观察到的颜色Ci(r)建模,该正态分布具有依赖于图像和光线的方差βi(r)2和平均值cˇI(r)。
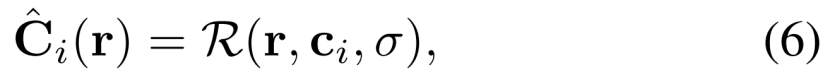
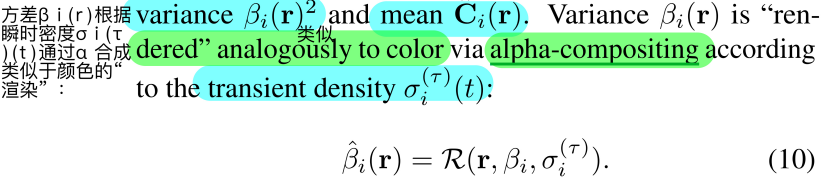



图4:NeRF-W分别呈现场景中的静态(a)和瞬态(b)元素,然后将它们合成为(c).训练使通过不确定性(e)加权的复合图像和真实图像(d)之间的差异最小化,同时进行优化以识别和去除异常图像区域discount anomalous image regions。
4.3. Optimization
像NeRF一样,我们同时优化Fθ的两个副本:使用上述模型和losses的精细模型,以及仅使用潜在外观建模组件latent appearance modeling component的粗糙模型。除了参数θ,我们还优化了每个图像的外观嵌入{l(a) }N和瞬态嵌入i i=1嵌入{l(τ)}N。然后,
 因为优化只为训练集中的图像产生外观嵌入
因为优化只为训练集中的图像产生外观嵌入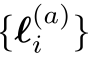 ,所以测试集图像的嵌入是未指定的。对于测试集可视化,我们选择
,所以测试集图像的嵌入是未指定的。对于测试集可视化,我们选择![]() 来最佳拟合目标图像(例如图8)或者将其设置为任意值。
来最佳拟合目标图像(例如图8)或者将其设置为任意值。
5. Experiments
在这里,我们提供了NeRF-W对文化地标的非约束(例如“野外”)互联网照片集合unconstrained (e.g. “in-the-wild”) internet photo collections of cultural landmarks的评估。我们从摄影旅游数据集Pho- totourism dataset中选择了六个地标。受之前作品的启发[22],我们重建了特莱维喷泉和圣心教堂Trevi Fountain and Sacre Coeur以及四个新的场景,勃兰登堡门、泰姬陵、布拉格老城广场和圣索菲亚大教堂Brandenburg Gate, Taj Mahal, Prague Old Town Square, and Hagia Sophia。这些场景的经验性能可在表1中找到,但我们强烈建议读者在附录中直观检查视频结果。

表1:NRW[22]、NeRF[24]和两种消融模型的 Phototourism dataset[13]的定量结果。highlighted.
显示最佳结果。NeRF-W在PSNR和MS-SSIM上的所有数据集上都优于以前的技术水平,并在LPIPS中取得了竞争性的结果。请注意,LPIPS通常倾向于训练具有对抗性或感知损失的NRW等方法,并且它对典型的GAN伪影不那么敏感,见图7和图14(补充)
Baselines:
我们评估了我们提出的方法 与Neural Rerendering in the Wild (NRW) [22]、NeRF [24]和NeRF-W的两次消融:NeRF-A(外观),其中消除了“瞬时”头部;和NeRF-U(不确定性),其中消除了嵌入l(a)的外观。NeRF-W是NeRF-A和NeRF-U的组合。虽然最近的其他工作,如[18]也用于类似的领域,但我们将基线限制在那些能够显著推断数据集所代表的视图之外的领域。
优化:
基于NeRF https://github.com/bmild/nerf,我们使用Keras实现了TensorFlow 2中的所有实验。对于每个场景,我们使用具有两个径向和两个切向变形参数two radial and two tangential dis- tortion parameters的COLMAP [27]来估计每个图像的相机参数。像在NeRF中一样,对于每个场景,我们训练一个初始化为随机权重的模型。我们使用Adam [7](超参数β1 = 0.9,β2 = 0.999,ε= 10-7),在8个GPU上优化300,000步的所有NeRF变量,批量大小为2048,耗时约2天。选择所有NeRF变量共享的超参数,以最大化Brandenburg Gate数据集上的PSNR,并在所有其他场景中固定为这些值。通过网格搜索选择NeRF-W变体的额外超参数,以最大化Brandenburg Gate场景的保留验证集上的PSNR,并将其固定为所有其他场景的值。有关超参数的更多详细信息,请参见附录。
略
6. Conclusion
我们提出了NeRF-W,一种基于NeRF的从非结构化的互联网照片集中重建复杂环境三维场景的新方法。我们学习每幅图像的潜在嵌入,捕捉经常出现在野外数据中的光度外观变化,并且我们将场景分解成依赖于图像的和共享的组件,以允许我们的模型从静态场景中分离出瞬态元素。对真实世界(和合成)数据的实验评估表明,与先前最先进的方法相比,在定性和定量方面都有显著的改进。

















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









