





OptimalFlow is an Omni-ensemble Automated Machine Learning toolkit, which is based on Pipeline Cluster Traversal Experiment approach, to help data scientists building optimal models in easy way, and automate Machine Learning workflow with simple codes.
最优流量 是基于管道集群遍历实验方法的全集成自动化机器学习工具包,可帮助数据科学家以简便的方式构建最佳模型,并使用简单的代码自动进行机器学习工作流程。
Comparing other popular “AutoML or Automated Machine Learning” APIs, OptimalFlow is designed as an Omni-ensemble ML workflow optimizer with higher-level API targeting to avoid manual repetitive train-along-evaluate experiments in general pipeline building.
比较其他流行的“ AutoML或自动机器学习” API, OptimalFlow 被设计为具有更高级别API定位的Omni-ensemble ML工作流优化器,从而避免了在常规管道构建中进行人工重复的训练和评估实验。
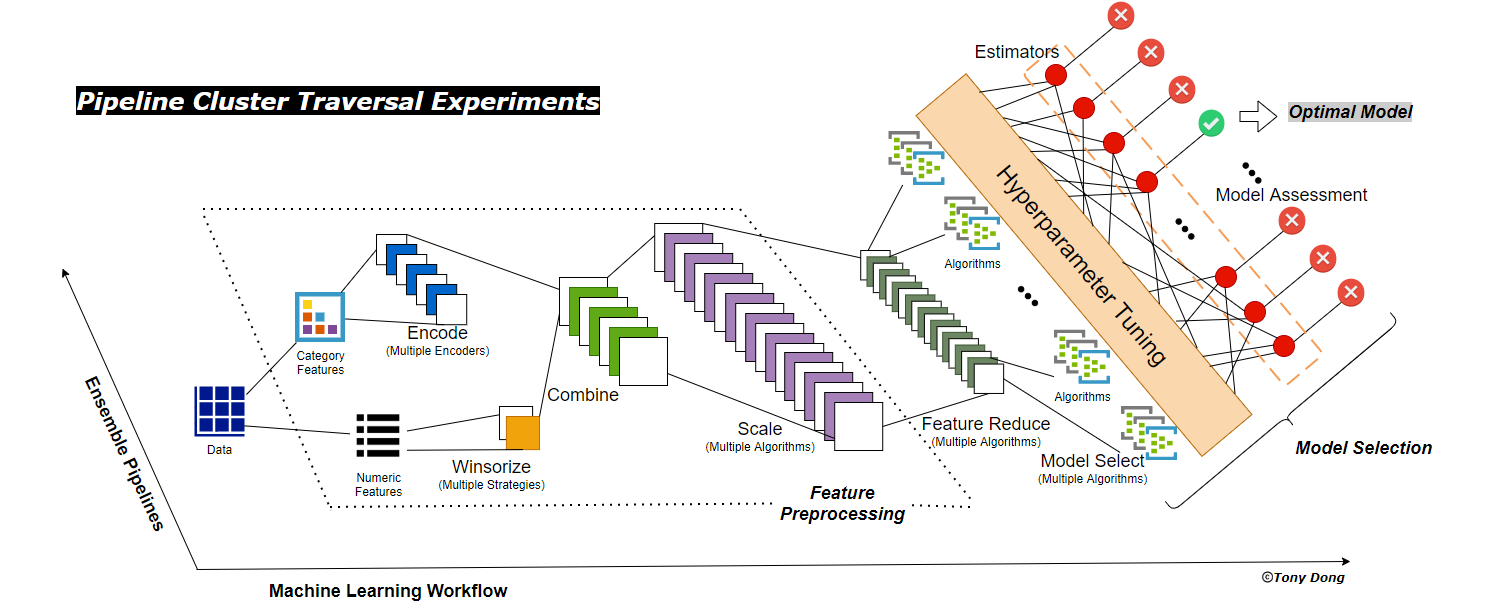
It rebuilt the automated machine learning framework by switching the focus from single pipeline components automation to a higher workflow level by creating an automated ensemble pipelines (Pipeline Cluster) traversal experiments and evaluation mechanisms. In another word, OptimalFlow jumps out of a single pipeline’s scope, while treats the whole pipeline as an entity, and automate produce all possible pipelines for assessment, until finding one of them leads to the optimal model. Thus, when we say a pipeline represents an automated workflow, OptimalFlow is designed to assemble all these workflows, and find the optimal one. That’s also the reason to name it as OptimalFlow.
它通过创建自动集成管道(管道集群)遍历实验和评估机制,将重点从单个管道组件自动化转移到更高的工作流程级别,从而重建了自动化机器学习框架。 换句话说, OptimalFlow跳出了单个管道的范围,而将整个管道视为一个实体,并自动生成所有可能的管道以进行评估,直到找到其中一个导致最佳模型为止。 因此,当我们说管道代表自动化的工作流程时, OptimalFlow旨在组装所有这些工作流程并找到最佳的工作流程。 这也是将其命名为OptimalFlow的原因。

To achieve that, OptimalFlow creates Pipeline Cluster Traversal Experiments to assemble all cross-matching pipelines covering major tasks of Machine Learning workflow, and apply traversal-experiment to search the optimal baseline model. Besides, by modularizing all key pipeline components in reusable packages, it allows all components to be custom updated along with high scalability.
为此, OptimalFlow 创建管道集群遍历实验以组装涵盖机器学习工作流程主要任务的所有交叉匹配管道,并应用遍历实验来搜索最佳基准模型。 此外,通过将所有关键管道组件模块化在可重复使用的程序包中,它允许对所有组件进行自定义更新,并具有很高的可扩展性。
The common machine learning workflow is automated by a “single pipeline” strategy, which is first introduced and well-supported by the scikit-learn library. In practical usage, data scientists need to implement repetitive experiments in each component within one pipeline, adjust algorithms & parameters, to get the optimal baseline model. I call this operation mechanism “Single Pipeline Repetitive Experiments”. No matter classic machine learning or current popular AutoML libraries, it’s hard to avoid this single pipeline focused experiment, which is the biggest pain point in the supervised modeling workflow.
常见的机器学习工作流程是通过“单一管道”策略实现自动化的,该策略首先由scikit-learn库引入并得到其良好的支持。 在实际使用中,数据科学家需要在一条管道中的每个组件中进行重复性实验,调整算法和参数,以获得最佳基准模型。 我将此操作机制称为“单管道重复实验”。 不管是经典的机器学习还是当前流行的AutoML库,都很难避免这种针对单一管道的实验,这是有监督的建模工作流程中最大的痛点。

The core concept/improvement in OptimalFlow is Pipeline Cluster Traversal Experiments, which is a theory of framework first proposed by Tony Dong in Genpact 2020 GVector Conference, to optimize and automate Machine Learning Workflow using ensemble pipelines algorithm.
OptimalFlow的核心概念/改进 是管道集群遍历实验 ,这是Tony Dong在Genpact 2020 GVector大会上首次提出的框架理论,旨在使用集成管道算法优化和自动化机器学习工作流程。
Comparing other automated or classic machine learning workflow’s repetitive experiments using a single pipeline, Pipeline Cluster Traversal Experiments is more powerful, since it expends the workflow from 1 dimension to 2 dimensions by ensemble all possible pipelines(Pipeline Cluster) and automated experiments. With larger coverage scope, to find the best model without manual intervention, and also more flexible with elasticity to cope with unseen data due to its ensemble designs in each component, the Pipeline Cluster Traversal Experiments provide data scientists an alternative more convenient and “Omni-automated” machine learning approach.
与使用单个管道的其他自动化或经典机器学习工作流的重复性实验相比,“ 管道集群遍历实验”功能更强大,因为它通过集成所有可能的管道(“ 管道集群” )和自动化实验将工作流从1维扩展到2维。 管道集群遍历实验具有覆盖范围广,无需人工干预即可找到最佳模型的优点,并且由于每个组件的整体设计而具有更大的灵活性,可以处理看不见的数据,因此, 管道集群遍历实验为数据科学家提供了一种更便捷和“全方位的解决方案”自动化”的机器学习方法。
OptimalFlow is consist of 6 modules below, you can find more details about each module in Documentation. Each module can be used to simplify and automate the specific component pipeline individually. Plus, you could find their examples in the Documentation.
OptimalFlow由以下6个模块组成,您可以在Documentation中找到有关每个模块的更多详细信息。 每个模块都可以被用于简化和自动化的特定成分管道 个别地。 另外,您可以在“ 文档”中找到它们的示例。
- autoPP for feature preprocessing 用于特征预处理的autoPP
- autoFS for classification/regression features selection 用于分类/回归特征选择的autoFS
- autoCV for classification/regression model selection and evaluation 用于分类/回归模型选择和评估的autoCV
autoPipe for Pipeline Cluster Traversal Experiments
用于管道集群遍历实验的 autoPipe
- autoViz for pipeline cluster visualization 用于管道集群可视化的autoViz
- autoFlow for logging & tracking. 用于记录和跟踪的autoFlow。

There are some live notebook (on binder)and demos in the Documentation.
Using OptimalFlow, data scientists, including experienced users or beginners, can build optimal models easily without tedious experiments and pay more attention to convert their industry domain knowledge to the deployment phase w/ practical implement.
使用OptimalFlow,包括经验丰富的用户或初学者在内的数据科学家都可以轻松构建最佳模型,而无需进行繁琐的实验,并且可以更加关注将其行业知识转换为带有实际实现的部署阶段。
Here’s an end-to-end OptimalFlow tutorial:
这是一个端到端的OptimalFlow教程:
In summary, OptimalFlow shares a few useful properties for data scientists:
总之, OptimalFlow 为数据科学家提供了一些有用的属性:
Easy & less code — High-level APIs to implement Pipeline Cluster Traversal Experiments, and each ML component is highly automated and modularized;
简单易用的代码 -实施管道集群遍历实验的高级API,并且每个ML组件都是高度自动化和模块化的;
Well-ensemble — Each key component is an ensemble of popular algorithms w/ hyperparameters tuning included;
良好的集合 -每个关键组件都是流行的算法集合,其中包括超参数调整;
Omni-coverage — Pipeline Cluster Traversal Experiments are designed to cross-experiment with all key ML components, like combined permuted input datasets, feature selection, and model selection;
全方位覆盖 - 管道集群遍历实验旨在与所有关键ML组件进行交叉实验,例如组合排列的输入数据集,特征选择和模型选择;
Scalable & Consistency — Each module could add new algorithms easily due to its ensemble & reusable design; no extra needs to modify existing codes;
可扩展性和一致性 —由于其整体和可重用的设计,每个模块都可以轻松添加新算法。 无需额外修改现有代码;
Adaptable — Pipeline Cluster Traversal Experiments makes it easier to adapt unseen datasets with the right pipeline;
适应性强 — 管道集群遍历实验使使用合适的管道更容易适应看不见的数据集;
Custom Modify Welcomed — Support custom settings to add/remove algorithms or modify hyperparameters for elastic requirements.
欢迎自定义修改 -支持自定义设置以添加/删除算法或修改超参数以满足弹性要求。
As an initial stable version to release, all supports are welcome! Please feel free to share your feedback, report issue, or join as a contributor at OptimalFlow GitHub here.
作为要发布的初始稳定版本,欢迎所有支持! 请随时分享您的反馈,报告问题,或作为OptimalFlow的贡献者加入 GitHub 在这里 。
关于我: (About me:)
I am a healthcare & pharmaceutical data scientist and big data Analytics & AI enthusiast. I developed OptimalFlow library to help data scientists building optimal models in an easy way, and automate Machine Learning workflow with simple codes.
我是医疗保健和制药数据科学家以及大数据分析和AI爱好者。 我开发了OptimalFlow库,以帮助数据科学家以简单的方式构建最佳模型,并使用简单的代码使机器学习工作流程自动化。
As a big data insights seeker, process optimizer, and AI professional with years of analytics experience, I use machine learning and problem-solving skills in data science to turn data into actionable insights while providing strategic and quantitative products as solutions for optimal outcomes.
作为具有多年分析经验的大数据洞察力寻求者,流程优化器和AI专业人士,我使用数据科学中的机器学习和问题解决技能将数据转化为可行的洞察力,同时提供战略性和定量产品作为最佳结果的解决方案。
翻译自: https://towardsdatascience.com/an-omni-ensemble-automated-machine-learning-optimalflow-369d6485e453















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









