





 本文介绍了如何利用BERT模型进行词汇简化,内容来源于中英文对照翻译。
本文介绍了如何利用BERT模型进行词汇简化,内容来源于中英文对照翻译。
使用bert
Lexical Simplification (LS) is replacing complex words with simpler alternatives, which can help various groups of people, like children, non-native speakers, etc, to better understandig a given text.
大号 exical简化(LS)与更简单的方法,它可以帮助各类人群,如儿童,非母语等取代复杂的单词,以understandig给定文本更好。
介绍 (Introduction)
In this article I’ll show how to make a lexical simplifier using NLTK, BERT and python, the main ideas are taken from this paper
在本文中,我将展示如何使用NLTK,BERT和python创建词法简化器,主要思想摘自本文。
This project will be address in 3 steps: 1. Identify complex words in a given sentence: Create a model that can detect or identify possible complex word, it is called complex word identification (CWI). 2. Generate candidates: Used BERT´s masked language model to get possible words candidates.3. Select the best candidates based on Zipf values: Compute the zipf values of each candidates to select the simplest one.
该项目将分3个步骤解决: 1.识别给定句子中的复杂单词:创建一个可以检测或识别可能的复杂单词的模型,称为复杂单词识别(CWI)。 2.生成候选词:使用BERT的屏蔽语言模型来获取可能的单词候选词。 3.根据Zipf值选择最佳候选者:计算每个候选者的zipf值以选择最简单的候选者。
The diagram of the work is as follows:
工作图如下:

1.识别复杂的单词 (1. Identify complex words)
The first goal is to be able to select the words in a given sentence which should be simplified, for that we need to train a model able to detect complex words in sentences.To train this model we are going to use the labeled dataset you can find on this page, and we are going to use a sequential architecture based in BiLSTM, which provides contextual information from both the left and right context of a target word.
第一个目标是能够选择给定句子中的单词 , 该单词 应该简化,因为我们需要训练一个能够检测句子中复杂单词的模型。要训练该模型,我们将使用标记的数据集可以在此页面上找到,我们将使用基于BiLSTM的顺序体系结构,该体系结构从目标单词的左右上下文中提供上下文信息。
After loaded the dataset you’ll end with the follow length:
加载数据集后,您将以以下长度结尾:
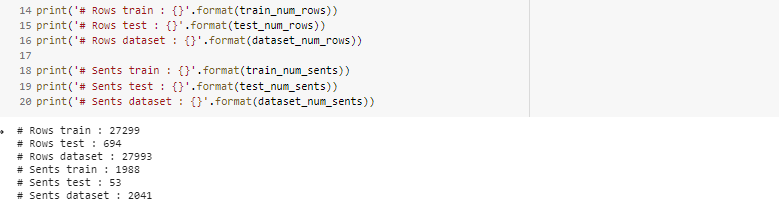
And the structure:
以及结构:

You can see that the dataset has sentences with binary labeled words (1 if word is considered complex), we will use this to train the CWI model.
您会看到数据集包含带有二进制标记单词的句子(如果单词被认为是复数,则为1),我们将使用它来训练CWI模型。
As usual in NLP, we need to apply some preprocessing to text in order to feed the data into a deep learning model:
像在NLP中一样,我们需要对文本进行一些预处理,以将数据输入到深度学习模型中:
- clean the text: delete not alphanumeric characters, lower case all words, etc. 清除文字:删除字母数字字符,小写所有单词等。
- create the vocabulary. 创建词汇表。
- Get the embeding vectors (for this article we are using glove). 获取嵌入向量(对于本文,我们使用手套)。
After preprocesing the dataset, we got the following:
在对数据集进行预处理之后,我们得到了以下内容:
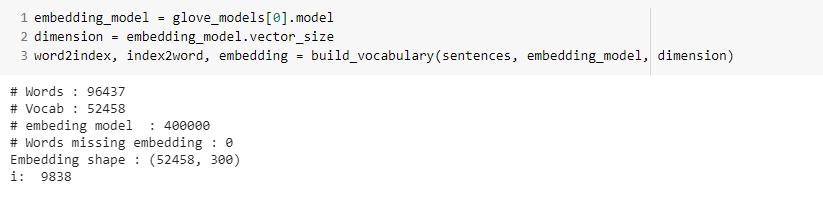
i.e. a vocabulary with 52K words, and an embedding matrix of shape 52K x 300
例如,词汇表包含52K个单词,并且嵌入矩阵的形状为52K x 300
创建CWI模型 (Create the model for CWI)
Next, we are creating the following model, using keras:
接下来,我们使用keras创建以下模型:
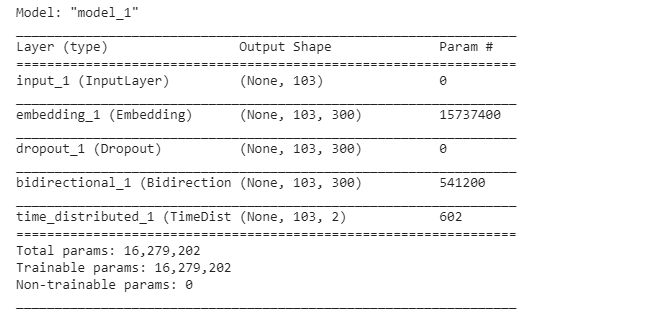
Is a simple BiLSTM model, we select this model for this post just for give you an idea how to approach for this problem. This model is going to be used only for indentify possible complex word in a given sentence.
这是一个简单的BiLSTM模型,在本文中选择此模型只是为了给您一个解决该问题的方法。 该模型将仅用于识别给定句子中可能的复杂单词 。
And then train it:
然后训练它:

After trained the CWI model, we will use BERT to generate candidates over the words which the CWI model identified as complex, the candidates are based not only in the synonym of the word but in context of them.
在训练了CWI模型之后,我们将使用BERT生成CWI模型标识为complex的单词的候选词,这些候选词不仅基于单词的同义词,而且还基于它们的上下文。
2.使用BERT生成候选人 (2. Generate candidates using BERT)
BERT is a powerful pretrained model from google, however this article is not about how BER works, if you need some basic knowledge about it please go to this blog.
BERT是来自Google的功能强大的预训练模型,但是本文与BER的工作方式无关,如果您需要BER的一些基础知识,请转到他的博客 。
We are using one of the BERT’s task masked language modeling (MLM), which is predicts missing tokens in a sequence given its left and right context.
我们正在使用BERT的一种任务掩盖语言建模 (MLM),该模型可以根据给定的左右上下文来预测序列中缺少的标记。
For example given the following sentence:
例如,给出以下语句:
* “the cat sat on the table”The sentence is modified (masked)before put into BERT:
在放入BERT之前,对句子进行修改(屏蔽):
* “[CLS] the cat [MASK] on the table [SEP]”As we said, one of the task BERT was trained for, is to be able to predict the [MASK] word, so if we input into a BERT model, it will output the most probably word given the context, for example:
就像我们说过的那样,BERT训练的任务之一就是能够预测[MASK]单词,因此,如果我们输入BERT模型,它将在给定上下文的情况下输出最可能的单词,例如:
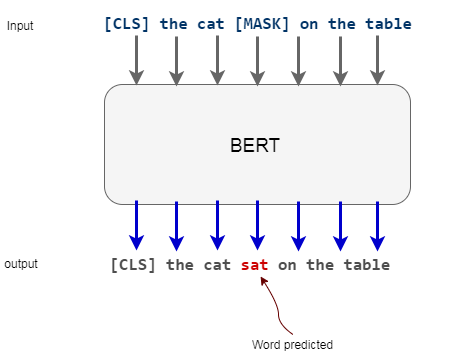
We are masking the complex words of each sentence and get the probability distribution of the vocabulary corresponding to the masked word.
我们对每个句子的复杂词进行掩蔽,并获得与掩蔽词相对应的词汇的概率分布。
As the paper suggest, We’ll concatenate the original sequence and the sequence where we replace the complex word with mask token as a sentence pair, and feed the sentence pair into the Bert to obtain the probability distribution of the vocabulary corresponding to the mask word.
正如论文所建议的 ,我们将连接原始序列和将复杂单词替换为掩码标记作为句子对的序列,并将句子对输入到Bert中,以获得与掩码词相对应的词汇的概率分布。
By using the sentence pair approach, we are not only consider the complex word itself, but also fit the context of the complex word:
通过使用句子对方法,我们不仅可以考虑复杂词本身,还可以适合复杂词的上下文:
Consider the sentence:
考虑以下句子:
* “an attempt to thwart them”The complex word in this sentence is “thwart”, to get the simplest replaces candidates we will feed it into BERT in this way:
这句话中的复杂词是“ thwar t”,要获得最简单的替换候选者,我们将以这种方式将其输入BERT:
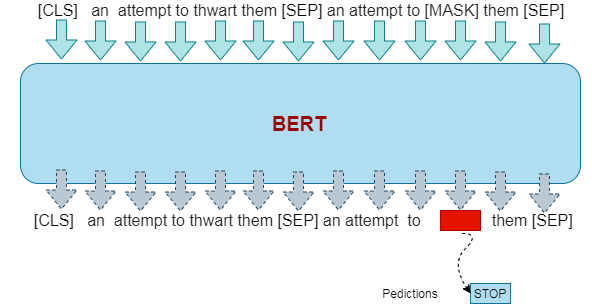
As we see, we feed the sentence pair into the Bert to obtain the mask word, in this case BERT give us: “Stop” which is a appropiate simplest replace.
如我们所见,我们将句子对输入到Bert中以获取掩码单词,在这种情况下,BERT给我们:“ Stop”(停止),这是一个最合适的最简单替换。
To do that, we’ll using pytorch and the function BertForMaskedLM from the very useful library hugginface, with that, using BERT’s masked language modeling is as simple as:
为了做到这一点,我们将使用pytorch从非常有用的库函数BertForMaskedLM hugginface ,与使用BERT的蒙面语言建模 很简单:
3.根据Zipf值选择最佳候选者。 (3. Select the best candidates based on Zipf values.)
We adopt the Zipf frequency of a word which is the base-10 logarithm of the number of times it appears per billion words to rank the replace word candidates. The greater the value the most common or familiar is the word for a person.
我们采用一个单词的Zipf频率 ,该频率是每十亿个单词出现的次数的10个对数,以对替换单词候选者进行排名。 一个人最常识或最熟悉的词的价值越大。
To get you and idea, let’s get the zipf values for simple word “stop”:
为了让您有一个想法,让我们获取简单单词“ stop ”的zipf值:

Now a more complex/uncommon word, “thwart”
现在,一个更复杂 /不常见的词“ 挫败 ”

Yo can see that the word “Stop” is most common than “thwart” so the chances that people are more familiar with the word “stop” are higher.
可以看到“停止”一词比“阻止”一词最常见,因此人们对“停止”一词的熟悉程度更高。
Now you get the idea, for each candidate generated from BERT we compute the zipf score using the python’s package wordfreq.
现在您就知道了,对于从BERT生成的每个候选者,我们都使用python的wordfreq软件包计算zipf得分。
In summary, for our lexical simplifier, we:
总而言之 ,对于我们的词汇简化器,我们:
- Get 10 context-aware candidates word from BERT. 从BERT获得10个上下文相关候选词。
- Compute their Zipf values. 计算其Zipf值。
- Sort each candidates based in the greater zipf value. 根据较高的zipf值对每个候选项进行排序。
- Replace each complex word with their simpler counterpart. 将每个复杂的单词替换为其较简单的单词。
The snippet code for this steps:
此步骤的代码段代码:
for input_text in list_texts:
new_text = input_text
input_padded, index_list, len_list = process_input(input_text)
pred_cwi = model_cwi.predict(input_padded)
pred_cwi_binary = np.argmax(pred_cwi, axis = 2)
complete_cwi_predictions = complete_missing_word(pred_cwi_binary, index_list, len_list)
bert_candidates = get_bert_candidates(input_text, complete_cwi_predictions)
for word_to_replace, l_candidates in bert_candidates:
tuples_word_zipf = []
for w in l_candidates:
if w.isalpha():
tuples_word_zipf.append((w, zipf_frequency(w, 'en')))
tuples_word_zipf = sorted(tuples_word_zipf, key = lambda x: x[1], reverse=True)
new_text = re.sub(word_to_replace, tuples_word_zipf[0][0], new_text)
print("Original text: ", input_text )
print("Simplified text:", new_text, "\n")And finally some results:
最后是一些结果 :
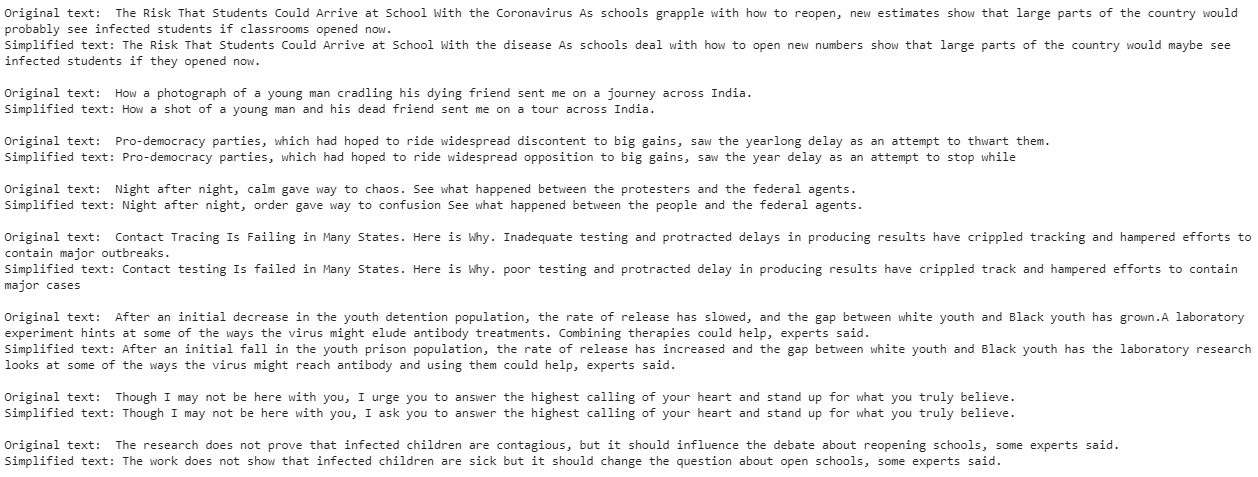
For example the first original sentence:
例如第一个原始句子:
“ The Risk That Students Could Arrive at School With the Coronavirus As schools grapple with how to reopen, new estimates show that large parts of the country would probably see infected students if classrooms opened now.
“学生可能会携带冠状病毒到达学校的风险随着学校努力重新开放,最新估计表明,如果现在开教室,该国大部分地区可能会感染受感染的学生。”
And the simplified one, where we mark in bold the words replaces:
简化的是用粗体标记的单词:
“The Risk That Students Could Arrive at School With the disease As schools deal with how to open, new numbers show that large parts of the country would maybe see infected students if they opened now.”
“那学生可以到学校随着病情学校应对如何打开的风险,新的数字显示,全国大部分地区将可能看到被感染的学生,如果他们现在开了。”
再来看看 (Let’s see one more)
The original:
原本的:
“The research does not prove that infected children are contagious, but it should influence the debate about reopening schools, some experts said.”
一些专家说:“这项研究并未证明受感染的儿童具有传染性,但它应该影响有关重新开学的辩论。”
The simplified:
简化的:
“The work does not show that infected children are sick, but it should change the question about open schools, some experts said.”
一些专家说:“这项工作并未表明受感染的孩子生病了,但应该改变有关开放学校的问题。”
最后的话 (Final Words)
The techniques for lexical simplification of sentences/documents, in this article, leverages on the masking language model of Bert. It focuses on the context of the complex word.
在本文中,用于简化句子/文档的词汇的技术利用了Bert的掩蔽语言模型。 它着重于复杂单词的上下文。
Experiment results have shown that this approach achieves pretty good canditates for replace into sentence and make it more simple.
实验结果表明,该方法可以很好地实现替换成句子的候选条件,并且使其变得更加简单。
If you want to improve, you can try another method or model for CWI, and use another score beyond zipf values for candidates raking.
如果要改进,可以尝试CWI的另一种方法或模型,并使用zipf值以外的其他分数进行候选者抽奖。
The complete code can be found on this Jupyter notebook, and you can browse for more projects on my Github.
完整的代码可以在Jupyter笔记本上找到,您可以在我的Github上浏览更多项目。
Also my linkedin
也是我的Linkedin
If you need some help with Data Science’s related projects: https://www.disruptio-analytics.com/
如果您需要有关Data Science相关项目的帮助,请访问: https : //www.disruptio-analytics.com/
翻译自: https://medium.com/@armandj.olivares/how-to-use-bert-for-lexical-simplification-6edbf5a4d15e
使用bert

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









