





This blog is the first in a series. We will cover some parts of Object Detection in each blog. For other parts click here:
该博客是系列文章中的第一篇。 我们将在每个博客中介绍对象检测的某些部分。 对于其他部分,请单击此处:
Wondering what’s all this hype about deep learning about? How can you as a practitioner use it to add value to your organization? These series of blog posts will help you understand what object detection is in general. What are the key performance metrics to keep an eye on? How you can leverage state of the art methods to get the job done succinctly in less time.
想知道有关深度学习的所有炒作是什么吗? 作为从业者,您如何使用它为您的组织增加价值? 这些系列博客文章将帮助您了解什么是对象检测。 有哪些关键性能指标需要关注? 如何利用最先进的方法在更少的时间内简洁地完成工作。
大纲: (Outline:)
1. Understanding the Problem2. Using Azure API for Object Detection3. Overview of Deep Learning Models
1.了解问题2。 使用Azure API进行对象检测3。 深度学习模型概述
先决条件: (Prerequisites:)
1. Knowledge of Machine Learning services2. Knowledge about Web APIs and their working3. Introductory knowledge about Performance Metrics
1. 机器学习服务知识2.关于Web API及其工作知识3。 有关绩效指标的入门知识
什么是物体检测? (What is Object Detection?)
Object Detection, in a nutshell, is about outputting bounding boxes along with class labels signifying objects enclosed within these bounding boxes. There can be multiple objects in a single image like a chair, handbag, desk, laptop, etc. Multiple objects could be of the same type say two bottles or different types. They may also overlap with each other.
简而言之,“对象检测”是关于输出边界框以及表示这些边界框内包含的对象的类标签。 单个图像中可以有多个对象,例如椅子,手提包,书桌,笔记本电脑等。多个对象可以是同一类型,例如两个瓶子或不同类型。 它们也可能彼此重叠。
对象检测与图像分割: (Object Detection vs Image Segmentation:)
Object Detection is different from the Image segmentation in the sense that, in Image Segmentation, we try to get or mark the exact pixels. Typically, we want to mark each pixel which signifies that it is part of the object say handbag. Hence, in Object Detection, we care more about bounding boxes and in Image Segmentation, we care more about pixels. Algorithms which work on pixel level like UNets are time-consuming in nature. Such algorithms try to build a pixel map such as to say that all these pixels belong to the laptop. And as we want object detection to be faster, we are working here with bounding boxes.
对象检测与图像分割的不同之处在于,在图像分割中,我们尝试获取或标记确切的像素。 通常,我们要标记每个像素,表示它是对象(例如手提包)的一部分。 因此,在“对象检测”中,我们更关注边界框,在“图像分割”中,我们更关注像素。 像UNets这样在像素级别上工作的算法本质上是耗时的。 这样的算法试图建立一个像素图,例如说所有这些像素都属于笔记本电脑。 并且由于我们希望对象检测更快,因此我们在这里使用边界框。
Now, we know what is the input and what is the output, right? Simply, image is the input and output is the bounding box. There are multiple ways of representing a Bounding Box: say using height and width. And for each Bounding Box, we wanna know what’s the object enclosed within it.
现在,我们知道什么是输入,什么是输出,对吗? 简单来说,图像是输入,输出是边界框。 表示边界框的方法有多种:使用高度和宽度表示。 对于每个边界框,我们想知道其中包含的对象是什么。
使用Azure API进行对象检测: (Using Azure API for Object Detection:)
We will work our way with the help of Azure API as it doesn’t charge you for one weekend while Google Compute does charge you with a credit card and a lot of readers might not have one. Keep in mind, here I am assuming that, you know the basics of Web-APIs and how they work. I am not going to explain how they work from the underlying details.
我们将在Azure API的帮助下进行工作,因为它不会在一个周末向您收费,而Google Compute会通过信用卡向您收费,而且很多读者可能没有信用卡。 请记住,这里我假设您了解Web-API的基础知识以及它们的工作方式。 我不会从底层细节来解释它们如何工作。
If you just do a google search saying “azure object detection python”. The very first search result you get is a code set on how to do it.
如果您只是在Google搜索中说“ azure object detection python”。 您获得的第一个搜索结果是有关如何执行此操作的代码集 。

Image URL: https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/images/windows-kitchen.jpg
图片网址: https : //docs.microsoft.com/zh-CN/azure/cognitive-services/computer-vision/images/windows-kitchen.jpg
If you will go through the documentation, you will see, that there is an image that works as input, and JSON is returned as output which is pretty much the same format used by each and every API these days.
如果您仔细阅读该文档,将会看到有一个图像可以用作输入,并且JSON作为输出返回,这与当今每个API使用的格式几乎相同。
<pre><code>{ “objects”:[ { “rectangle”:{ “x”:730, “y”:66, “w”:135, “h”:85 }, “object”:”kitchen appliance”, “confidence”:0.501 }, { “rectangle”:{ “x”:523, “y”:377, “w”:185, “h”:46 }, “object”:”computer keyboard”, “confidence”:0.51 }, { “rectangle”:{ “x”:471, “y”:218, “w”:289, “h”:226 }, “object”:”Laptop”, “confidence”:0.85, “parent”:{ “object”:”computer”, “confidence”:0.851 } }, { “rectangle”:{ “x”:654, “y”:0, “w”:584, “h”:473 }, “object”:”person”, “confidence”:0.855 } ], “requestId”:”a7fde8fd-cc18–4f5f-99d3–897dcd07b308", “metadata”:{ “width”:1260, “height”:473, “format”:”Jpeg” } }</code></pre>
<pre> <code> {“对象”:[{“矩形”:{“ x”:730,“ y”:66,“ w”:135,“ h”:85},“对象”:“厨房用具”,“信心”:0.501},{“矩形”:{“ x”:523,“ y”:377,“ w”:185,“ h”:46},“对象”:“计算机键盘”,“置信度:0.51},{“矩形”:{“ x”:471,“ y”:218,“ w”:289,“ h”:226},“对象”:“笔记本电脑”,“置信度”:0.85 ,“ parent”:{“ object”:“ computer”,“ confidence”:0.851}}},{“ rectangle”:{“ x”:654,“ y”:0,“ w”:584,“ h”: 473},“ object”:“ person”,“ confidence”:0.855}],“ requestId”:“ a7fde8fd-cc18–4f5f-99d3–897dcd07b308”,“ metadata”:{“ width”:1260,“ height”: 473,“格式”:“ Jpeg”}} </ code> </ pre>
Let’s try to make sense of the JSON output: we can see that the object returned is, in fact, an array comprising of several sub-objects within it. These parts signify what are the possible objects detected by the model from the input picture. We can see for bounding boxes (which are mostly rectangle in shape), we are returned central coordinates, height, and width. Also, for a prediction being made, it returns the confidence value which is a probability explaining how much confidence the model has in that prediction to be correct. The confidence value ranges from 0–1. You may even get to see, the hierarchy of objects such as a laptop being also predicted further being a computer which is true when considering the real world.
让我们尝试理解JSON输出:我们可以看到返回的对象实际上是一个数组,其中包含多个子对象。 这些部分表示模型从输入图片中检测到的可能对象是什么。 我们可以看到边界框(形状大多为矩形),返回的是中心坐标,高度和宽度。 同样,对于进行的预测,它返回置信度值,这是解释模型对该预测正确的置信度的概率。 置信度值的范围是0-1。 您甚至可能会看到,诸如笔记本电脑之类的对象的层次结构也被进一步预测为一台计算机,这在考虑现实世界时是正确的。
Azure API的局限性: (Limitations of the Azure API:)
If you’ll go through some of the limitations:
如果您会遇到一些限制:
1) It cannot detect objects which are less than 5% of the total area of the image.
1)它无法检测到小于图像总面积5%的物体。
2) Also, objects which are stacked together are a bit difficult to be identified.
2)而且,堆叠在一起的物体有点难以识别。
3) It can’t differentiate brand or product names.
3)不能区分品牌或产品名称。
For the final point, there is a different API altogether from Microsoft dynamics 365 consultants , let’s pay it a visit.
最后一点,与Microsoft Dynamics 365顾问完全不同的API,让我们参观一下。
计算机视觉API-2.0 (Computer Vision API-2.0)
Our Object Detection feature is part of Analyze Image API. Now, assuming that you know about Web-based APIs, and how localhost sends some requests to the server and it returns some output based on some request variables/parameters. If you ask only for an object, it will give you that only else when not specified, other valid feature types like adult content, brands, colors, faces, celebrities, landmarks, etc. will be returned as well. You can also specify the language you want the output to be in. Say, for example, English, Chinese, Japanese, Spanish, etc.
我们的对象检测功能是Analyze Image API的一部分。 现在,假设您了解基于Web的API,以及localhost如何将一些请求发送到服务器,并且localhost根据一些请求变量/参数返回一些输出。 如果只要求一个对象,则只有在未指定对象的情况下,其他内容才有效,例如成人内容,品牌,颜色,面部,名人,地标等。 您也可以指定输出要使用的语言。例如,说英语,中文,日语,西班牙语等。
You can also look at the JSON given below and can see similar to what we had seen above, this one is describing several types of objects present in the input image and making predictions for it with some confidence value. Also, we can see the bounding box for the object present in the input image at last.
您还可以查看下面给出的JSON,并且可以看到与我们上面看到的类似的内容,这是描述输入图像中存在的几种对象,并以一定的置信度对其进行预测。 此外,我们最终可以看到输入图像中存在的对象的边界框。
<pre><code>{ “categories”: [ { “name”: “abstract_”, “score”: 0.00390625 }, { “name”: “people_”, “score”: 0.83984375, “detail”: { “celebrities”: [ { “name”: “Satya Nadella”, “faceRectangle”: { “left”: 597, “top”: 162, “width”: 248, “height”: 248 }, “confidence”: 0.999028444 } ], “landmarks”:[ { “name”:”Forbidden City”, “confidence”: 0.9978346 } ] } } ], “adult”: { “isAdultContent”: false, “isRacyContent”: false, “adultScore”: 0.0934349000453949, “racyScore”: 0.068613491952419281 }, “tags”: [ { “name”: “person”, “confidence”: 0.98979085683822632 }, { “name”: “man”, “confidence”: 0.94493889808654785 }, { “name”: “outdoor”, “confidence”: 0.938492476940155 }, { “name”: “window”, “confidence”: 0.89513939619064331 } ], “description”: { “tags”: [ “person”, “man”, “outdoor”, “window”, “glasses” ], “captions”: [ { “text”: “Satya Nadella sitting on a bench”, “confidence”: 0.48293603002174407 } ] }, “requestId”: “0dbec5ad-a3d3–4f7e-96b4-dfd57efe967d”, “metadata”: { “width”: 1500, “height”: 1000, “format”: “Jpeg” }, “faces”: [ { “age”: 44, “gender”: “Male”, “faceRectangle”: { “left”: 593, “top”: 160, “width”: 250, “height”: 250 } } ], “color”: { “dominantColorForeground”: “Brown”, “dominantColorBackground”: “Brown”, “dominantColors”: [ “Brown”, “Black” ], “accentColor”: “873B59”, “isBWImg”: false }, “imageType”: { “clipArtType”: 0, “lineDrawingType”: 0 }, “objects”: [ { “rectangle”: { “x”: 25, “y”: 43, “w”: 172, “h”: 140 }, “object”: “person”, “confidence”: 0.931 } ] }</code></pre>
<pre> <code> {“类别”:[{“名称”:“抽象”,“得分”:0.00390625},{“名称”:“ people_”,“得分”:0.83984375,“详细信息”:{“名人”:[{“名称”:“ Satya Nadella”,“ faceRectangle”:{“左”:597,“顶部”:162,“宽度”:248,“高度”:248},“信心”:0.999028444}] ,“地标”:[{“名称”:“紫禁城”,“信心”:0.9978346}]}}]}}},“成人”:{“ isAdultContent”:false,“ isRacyContent”:false,“ adultScore”:0.0934349000453949, “ racyScore”:0.068613491952419281},“ tags”:[{“ name”:“ person”,“ confidence”:0.98979085683822632},{“ name”:“ man”,“ confidence”:0.94493889808654785},{“ name”:“室外”,“信心”:0.938492476940155},{“名称”:“窗口”,“信心”:0.89513939619064331}],“描述”:{“标签”:[“人”,“人”,“室外”,“窗口”,“眼镜”,“字幕”:[{“ text”:“ Satya Nadella坐在长凳上”,“ confidence”:0.48293603002174407}]},“ requestId”:“ 0dbec5ad-a3d3–4f7e-96b4-dfd57efe967d ”,“元数据”:{“宽度”:1500,“高度”:1000,“ 格式”:“ Jpeg”},“脸部”:[{“年龄”:44,“性别”:“男”,“ faceRectangle”:{“左”:593,“顶部”:160,“宽度”:250 ,“ height”:250}}]],“ color”:{“ dominantColorForeground”:“ Brown”,“ dominantColorBackground”:“ Brown”,“ dominantColors”:[[“ Brown”,“ Black”],“ accentColor”:“ 873B59”,“ isBWImg”:false},“ imageType”:{“ clipArtType”:0,“ lineDrawingType”:0},“ objects”:[{“ rectangle”:{“ x”:25,“ y”:43 ,“ w”:172,“ h”:140},“ object”:“ person”,“ confidence”:0.931}]} </ code> </ pre>
Big Giants like FAANG, provide code in their documentation. You can see, in the code section with Python Language, that we are providing Subscription Key as part of the request headers. You can also see several parameters that we discussed to be part of the request. You have to specify in the visual features part it to be either an object, face, or something else. Then comes another code snippet, saying that we first establish an HTTPS connection. You will be returned the byte stream data. If you wanna print it, you can use: print(json.dumps(response.json()))
像FAANG这样的大巨人在其文档中提供了代码。 您可以在Python语言的代码部分中看到,我们在请求标头中提供了Subscription Key。 您还可以看到一些我们讨论过的参数,它们是请求的一部分。 您必须在视觉特征部分中将其指定为对象,面部或其他东西。 然后是另一个代码段,说我们首先建立了HTTPS连接。 您将返回字节流数据。 如果要打印,可以使用: print(json.dumps(response.json()))
<pre><code>########### Python 2.7 ############# import httplib, urllib, base64 headers = { # Request headers ‘Content-Type’: ‘application/json’, ‘Ocp-Apim-Subscription-Key’: ‘{subscription key}’, } params = urllib.urlencode({ # Request parameters ‘visualFeatures’: ‘Objects’, ‘details’: ‘{string}’, ‘language’: ‘en’, }) try: conn = httplib.HTTPSConnection(‘westcentralus.api.cognitive.microsoft.com’) conn.request(“POST”, “/vision/v2.0/analyze?%s” % params, “{body}”, headers) response = conn.getresponse() data = response.read() print(data) conn.close() except Exception as e: print(“[Errno {0}] {1}”.format(e.errno, e.strerror)) #################################### ########### Python 3.2 ############# import http.client, urllib.request, urllib.parse, urllib.error, base64 headers = { # Request headers ‘Content-Type’: ‘application/json’, ‘Ocp-Apim-Subscription-Key’: ‘{subscription key}’, } params = urllib.parse.urlencode({ # Request parameters ‘visualFeatures’: ‘Categories’, ‘details’: ‘{string}’, ‘language’: ‘en’, }) try: conn = http.client.HTTPSConnection(‘westcentralus.api.cognitive.microsoft.com’) conn.request(“POST”, “/vision/v2.0/analyze?%s” % params, “{body}”, headers) response = conn.getresponse() data = response.read() print(data) conn.close() except Exception as e: print(“[Errno {0}] {1}”.format(e.errno, e.strerror)) ####################################</code></pre>
<pre> <code> ########### Python 2.7 ############ import httplib,urllib,base64标头= {#请求标头'Content-Type': 'application / json','Ocp-Apim-Subscription-Key':'{subscription key}',} params = urllib.urlencode({#请求参数'visualFeatures':'Objects','details':'{string} ','language':'en',})尝试:conn = httplib.HTTPSConnection('westcentralus.api.cognitive.microsoft.com')conn.request(“ POST”,“ /vision/v2.0/analyze? %s”%参数,“ {body}”,标题)response = conn.getresponse()data = response.read()print(data)conn.close()例外,例如e:print(“ [Errno {0} ] {1}”。format(e.errno,e.strerror))################################ ### ########### Python 3.2 ############ import http.client,urllib.request,urllib.parse,urllib.error,base64标头= { #请求标头'Content-Type':'application / json','Ocp-Apim-Subscription-Key':'{subscription key}',} params = urllib.parse.urlencode({#请求参数'visualFeatures':'类别”,“详细信息”:“ {strin g}','language':'en',})尝试:conn = http.client.HTTPSConnection('westcentralus.api.cognitive.microsoft.com')conn.request(“ POST”,“ / vision / v2。 0 / analyze?%s”%参数,“ {body}”,标题)response = conn.getresponse()data = response.read()print(data)conn.close()例外,例如e:print(“ [ Errno {0}] {1}”。format(e.errno,e.strerror))############################## ####### </ code> </ pre>
If you’re interested in looking at the complete code, visit this.
如果您有兴趣查看完整的代码,请访问this 。
性能指标: (Performance Metrics:)
How do we measure if an algorithm is good or not? There are a couple of terms you should be comfortable using:
我们如何衡量算法是否良好? 您应该习惯使用以下两个术语:
1) Ground Truth: It is absolute truth; generally labeled or given by a human. It will be a bounded box drawn by a human when asked to do so. In Machine Learning lingo, represented by…
1) 地面真理:这是绝对真理; 通常由人类标记或给出。 当要求这样做时,它将是人类绘制的有界框。 在机器学习术语中,以...表示
2) Predictions: It is the prediction made by machine/model. In Machine Learning lingo, represented by…
2) 预测:这是由机器/模型做出的预测。 在机器学习术语中,以...表示
You want to see how close is the machine prediction to the human annotation. What you will do? We will take both rectangles aka bounding boxes, and will compute something called Intersection over Union or IoU.
您想了解机器预测与人工标注的距离有多近。 你会做什么? 我们将两个矩形又称为边界框,并将计算称为“在Union或IoU上的交集”的东西。

Now, what should be the ideal case? When both bounding boxes are completely overlapping over each other, the value of will be 1. What is the worst case? When both bounding boxes don’t overlap at all i.e. intersection = 0. Resultingly, IoU will be 0. The common threshold which is used is that, if , then your prediction is referred to as positive (in case of a binary classification setup). It is also sometimes called as 50% . Now, this is a performance for one bounding box. When we have multiple objects in the same image, there will be many bounding boxes as well. So?
现在,理想的情况是什么? 当两个边界框完全重叠时,值将为1。最坏的情况是什么? 当两个边界框都不重叠时,即交集=0。因此,IoU将为0。使用的通用阈值是,如果,则您的预测被称为正(在二进制分类设置的情况下) 。 有时也称为50%。 现在,这是一个边界框的性能。 当我们在同一图像中有多个对象时,也将有许多边界框。 所以?
We were saying that whether the predicted rectangle overlaps 50% or more with ground truth rectangle or not. A rectangle overlap problem is converted to a binary classification problem. But for multiple objects, we have a multi-class classification problem. Now, for each class (chair, person,..), we will compute average precision from all the objects of the same class which can be calculated using the Area Under Precision Curve.
我们说的是,预测矩形是否与地面真实矩形重叠50%或更多。 矩形重叠问题转换为二进制分类问题 。 但是对于多个对象,我们有一个多类分类问题 。 现在,对于每个类别(椅子,人等),我们将从同一个类别的所有对象中计算平均精确度,这可以使用“精确度曲线下的面积”来计算。
Once you have computed average precision for each of the classes, take the mean/average of all of them, and you will get mean-average-precision (). Many research papers have notation signifying that we are calculating with. Don’t confuse it with MAP(maximum a-posteriori) which is there in statistics.
计算完每个类的平均精度后,对所有这些类取均值/平均值,即可得到均值平均精度()。 许多研究论文都有表示我们正在使用的符号。 不要将其与统计数据中存在的MAP (最大后验)混淆。
深度学习模型概述: (Overview of Deep Learning Models:)
As of now, we have covered how a non-deep learning person can make use of available APIs without worrying about algorithmic stuff to perform object detection. Now, we will move towards the algorithmic section. As you had seen, our input is image or video. We can break the video in a sequence of images and can give it to the model and it will be perfectly all right. Now, what is the output? We want bounding boxes and associated object class labels. We will make use of the COCO dataset for our understanding. It contains 80 class labels and a few thousands of images. Hence, a fairly large dataset and is well-curated for tasks such as Image Segmentation and Object Detection.
到目前为止,我们已经介绍了非深度学习者如何利用可用的API而不用担心算法问题来执行对象检测。 现在,我们将进入算法部分。 如您所见,我们的输入是图像或视频。 我们可以将视频分解为一系列图像,然后将其提供给模型,这样就可以了。 现在,输出是什么? 我们需要边界框和关联的对象类标签。 我们将利用COCO数据集进行理解。 它包含80个类别标签和数千个图像。 因此,一个相当大的数据集对于诸如图像分割和对象检测之类的任务来说是精心策划的。
Now, the main trade-off is Speed vs. Speed here basically means that given an image to the input algorithm, how fast it can give you the output. It can be measured in milliseconds or frames per second. So, if the speed of the algorithm to process an image comes out to be 50ms, it is roughly equal to 20 fps. As, 1sec = 1000ms, hence 20 images/sec. Humans see the world in 24 fps. For systems like self-driving cars where there is a little time to identify other vehicles and lane, real-time face detection systems where there is only a little time to identify the entrant, speed is very critical. There are other places where or average precision is very important. Say, medical diagnosis and Optical Character Recognition (OCR) where we cannot afford to make too many mistakes at the expense of faster results.
现在,主要的权衡是速度与速度的关系,这里基本上意味着给输入算法一个图像,它能为您提供输出的速度。 可以以毫秒或帧/秒为单位进行测量。 因此,如果算法处理图像的速度为50毫秒,则大约等于20 fps。 As 1sec = 1000ms,因此为20个图像/秒。 人类以24 fps的速度观看世界。 对于像自动驾驶汽车这样的系统,该系统几乎没有时间识别其他车辆和车道,而对于只有实时系统的实时面部检测系统来说,识别进入者的速度非常关键。 在其他地方,平均精度非常重要。 假设是医学诊断和光学字符识别 (OCR),我们不能承担太多错误而以更快的结果为代价。
For good we have, algorithms like R-CNN, Fast R-CNN and faster R-CNNs, Feature pyramid network-based FRCN. Faster versions of these algorithms are available to do tasks faster as fundamentally they are not designed for that. Then, we have algorithms like single-shot detection and RetinaNet. Also, algorithms like YOLO v1 (2015), YOLO v2/ YOLO 9000 (called so as it can recognize 9000 objects on Imagenet Dataset) and the recent one in the lineup is YOLO v3 (Apr 2018). There are other 30+ odd algorithms for the same purpose.
好的,我们有R-CNN,Fast R-CNN和Fast R-CNNs,基于特征金字塔网络的FRCN之类的算法。 这些算法的较快版本可更快地执行任务,因为从根本上说,它们不是为此目的而设计的。 然后,我们有了单次检测和RetinaNet之类的算法。 此外, YOLO v1(2015),YOLO v2 / YOLO 9000 (之所以这样称呼,是因为它可以识别Imagenet Dataset上的9000个对象),而最新的算法是YOLO v3(2018年4月)。 具有相同目的的其他30多种奇数算法。
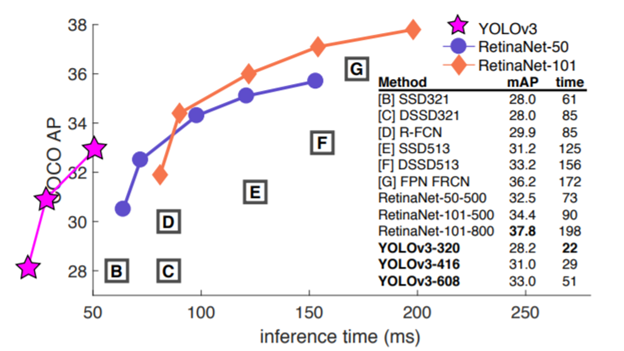
Now, looking at the benchmarks image, we can see that YOLO v3, has three variants as per the sizes of the image that it works with. YOLO-320 -basically says the sizes of the input images are 320x320. Our objective is to get higher and less time. We can see that, YOLO v3 is super fast and has very good. When the input image is smaller in size, it takes less time to process. While, when the input image is larger in size, it takes more time but there are more chances of correctly detecting smaller objects. So, the choice of the variants among those provided by the YOLO v3, depends on how small objects you wish to detect. YOLO v3 is a really great architecture that is aggregating good things from various other models.
现在,看一下基准图像,我们可以看到YOLO v3根据所使用图像的大小具有三个变体。 YOLO-320-基本上说输入图像的大小是320x320。 我们的目标是获得更多和更少的时间。 我们可以看到,YOLO v3超级快并且非常出色。 当输入图像尺寸较小时,处理时间会减少。 同时,当输入图像较大时,将花费更多时间,但是有更多机会正确检测较小的对象。 因此,在YOLO v3提供的变体中选择哪种取决于您希望检测的物体的数量。 YOLO v3是一个非常好的架构,它聚集了来自其他各种模型的优点。
In the next blog post, we will take a look at the architecture and tweaks which make YOLOv3 to be one of the best models in object detection space. Until then, happy learning!
在下一篇博客文章中,我们将介绍使YOLOv3成为对象检测领域最佳模型之一的体系结构和调整。 在那之前, 学习愉快 !
Gain Access to Expert View — Subscribe to DDI Intel
获得访问专家视图的权限- 订阅DDI Intel
翻译自: https://medium.com/datadriveninvestor/how-do-i-use-azure-api-in-object-detection-ac8b6d34c7d8















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









