





python 缓存
介绍 (Introduction)
Most of us may have experienced the scenarios that we need to implement some computationally expensive logic such as recursive functions or need to read from I/O or network multiple times, these functions typically requires more resources and longer CPU time, and eventually can cause performance issue if handle without care. For such case, you shall always pay special attention to it once you have completed all the functional requirements, as the additional runtime costs on the resources and time may eventually lead to the user experience issue. In this article, I will be sharing how we can make use of the cache mechanism (aka memoization) to improve the code performance.
我们大多数人可能都经历过以下场景:我们需要实现一些计算上昂贵的逻辑,例如递归函数,或者需要多次读取I / O或网络,这些函数通常需要更多的资源和更长的CPU时间,最终可能导致性能下降问题,如果不小心处理。 对于这种情况,一旦完成所有功能要求,您就应该始终特别注意它,因为资源和时间上的额外运行时成本最终可能会导致用户体验问题。 在本文中,我将分享我们如何利用缓存机制(又称为备忘录)来提高代码性能。
Prerequisites:
先决条件:
To follow the examples in below, you will need to have requests package installed in your working environment, you may use the below pip command to install:
要遵循以下示例,您需要在工作环境中安装请求包,可以使用以下pip命令进行安装:
pip install requestsWith this ready, let’s dive into the problem we are going to solve today.
做好准备之后,让我们深入探讨我们今天要解决的问题。
As I mentioned before, the computationally expensive logic such as recursive functions or reading from I/O or network usually have the significant impacts to the runtime, and are always the targets for optimization. So let me illustrate with a specific example, for instance, assume we need to call some external API to get the rates:
如前所述,递归函数或从I / O或网络读取等计算量大的逻辑通常会对运行时产生重大影响,并且始终是优化的目标。 因此,让我用一个特定的示例进行说明,例如,假设我们需要调用一些外部API来获取费率:
import requests
import json def inquire_rate_online(dimension):
result = requests.get(f"https://postman-echo.com/get?dim={dimension}")
if result.status_code == requests.codes.OK:
data = result.json()
return data["args"]["dim"]
return ''This function needs to make a call through the network and return the result (for demo purpose, this API call just echo back the input as result). If you want to provide this as a service to everybody, there is a high chance that different people inquire the rate with same dimension value. And for this case, you may wish to have the result stored at somewhere after the first person inquired, so that later you can just return this result for the subsequent inquiry rather than making an API call again. With this sort of caching mechanism, it should improve your code performance.
此函数需要通过网络进行调用并返回结果(出于演示目的,此API调用只是将输入作为结果回显)。 如果您想将此服务提供给所有人,那么不同的人很有可能会询问具有相同尺寸值的比率。 对于这种情况,您可能希望将结果存储在第一个查询的人之后的某个地方,以便以后您可以只返回此结果以进行后续查询,而不必再次进行API调用。 通过这种缓存机制,它应该可以提高代码性能。
用全局字典实现缓存 (Implement cache with global dictionary)
For the above example, the most straightforward way to implement a cache is to store the arguments and results in a dictionary, and every time we check this dictionary to see if the key exists before calling the external API. We can implement this logic in a separate function as per below:
对于上面的示例,实现缓存的最直接的方法是将参数和结果存储在字典中,并且每次我们在调用外部API之前检查该字典以查看键是否存在时。 我们可以按照以下单独的函数来实现此逻辑:
cached_rate = {} def cached_inquire(dim):
if dim in cached_rate:
print(f"cached value: {cached_rate[dim]}")
return cached_rate[dim]
cached_rate[dim]= inquire_rate_online(dim)
print(f"result from online : {cached_rate[dim]}")
return cached_rate[dim]With this code, you can cache the previous key and result in the dictionary, so that the subsequent calls will be directly returned from the dictionary lookup rather than an external API call. This should dramatically speed up your code since reading from dictionary is much faster than making an API through the network.
使用此代码,您可以将先前的键缓存并存储在字典中,以便后续的调用将直接从字典查找中返回,而不是从外部API调用中返回。 这应该大大加快您的代码速度,因为从字典中读取内容比通过网络制作API快得多。
You can quickly test it from Jupyter Notebook with the %time magic:
您可以使用%time魔术从Jupyter Notebook快速对其进行测试:
%time cached_inquire(1)For the first time you call it, you would see the time taken is over 1 seconds (depends on the network condition):
第一次调用它,您会看到花费的时间超过1秒(取决于网络状况):
result from online : 1
Wall time: 1.22 sWhen calling it again with the same argument, we should expect our cached result start working:
当使用相同的参数再次调用它时,我们应该期望我们的缓存结果开始起作用:
%time cached_inquire(1)You can see the total time taken dropped to 997 microseconds for this call, which is over 1200 times faster than previously:
您可以看到此调用花费的总时间降至997微秒,比以前快了1200倍:
cached value: 1
Wall time: 997 µsWith this additional global dictionary, we can see so much improvement on the performance. But some people may have concern about the additional memory used to hold these values in a dictionary, especially if the result is a huge object such as image file or array. Python has a separate module called weakref which solves this problem.
有了这个额外的全局字典,我们可以看到性能有了很大的提高。 但是有些人可能会担心用于在字典中保存这些值的额外内存,特别是如果结果是一个庞大的对象(例如图像文件或数组)时,尤其如此。 Python有一个名为weakref的单独模块,可以解决此问题。
用weakref实现缓存 (Implement cache with weakref)
Python introduced weakref to allow creating weak reference to the object and then garbage collection is free to destroy the objects whenever needed in order to reuse its memory.
Python引入了weakref以允许创建对对象的弱引用,然后在需要时可以随意进行垃圾回收以销毁对象以重用其内存。
For demonstration purpose, let’s modify our earlier code to return a Rate class instance as the inquiry result:
出于演示目的,让我们修改之前的代码以返回Rate类实例作为查询结果:
class Rate(): def __init__(self, dim, amount):
self.dim = dim
self.amount = amount def __str__(self):
return f"{self.dim} , {self.amount}" def inquire_rate_online(dimension):
result = requests.get(f"https://postman-echo.com/get?dim={dimension}")
if result.status_code == requests.codes.OK:
data = result.json()
return Rate(float(data["args"]["dim"]), float(data["args"]["dim"])) return Rate(0.0,0.0)And instead of a normal Python dictionary, we will be using WeakValueDictionary to hold a weak reference of the returned objects, below is the updated code:
而且,我们将使用WeakValueDictionary来代替返回的对象的弱引用,而不是普通的Python字典,下面是更新的代码:
import weakref wkrf_cached_rate = weakref.WeakValueDictionary() def wkrf_cached_inquire(dim):
if dim in wkrf_cached_rate:
print(f"cached value: {wkrf_cached_rate[dim]}")
return wkrf_cached_rate[dim] result = inquire_rate_online(dim)
print(f"result from online : {result}")
wkrf_cached_rate[dim] = result return wkrf_cached_rate[dim]With the above changes, if you run the wkrf_cached_inquire two times, you shall see the significant improvement on the performance:
通过上述更改,如果您运行两次wkrf_cached_inquire,您将看到性能上的重大改进:
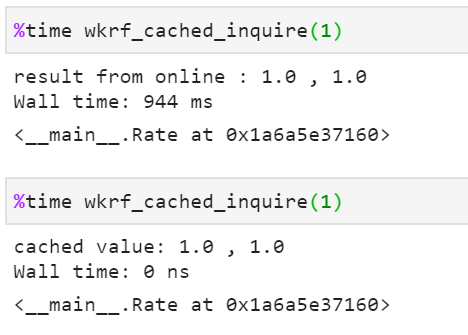
And the dictionary does not hold the instance of the Rate, rather a weak reference of it, so you do not have to worry about the extra memory used, because the garbage collection will reclaim it when it’s needed and meanwhile your dictionary will be automatically updated with the particular entry being removed. So subsequently the program can continue to call the external API like the first time.
而且字典没有保存Rate的实例,而是它的弱引用,因此您不必担心所使用的额外内存,因为垃圾收集会在需要时回收它,同时您的字典将自动更新删除特定条目。 因此,随后程序可以像第一次一样继续调用外部API。
If you stop your reading here, you will miss the most important part of this article, because what we have gone through above are good but just not perfect due to the below issues:
如果您在这里停止阅读,您将错过本文的最重要部分,因为由于以下问题,我们上面介绍的内容是不错的,但并不完美:
In the example, we only have 1 argument for the inquire_rate_online function, things are getting tedious if you have more arguments, all these arguments have to be stored as the key for the dictionary. In that case, re-implement the caching as a decorator function probably would be easier
在该示例中,inquire_rate_online函数只有1个参数,如果您有更多的参数,事情将变得很乏味,所有这些参数都必须存储为字典的键。 在这种情况下,将缓存重新实现为装饰器功能可能会更容易
- Sometimes you do not really want to let garbage collection to determine which values to be cached longer than others, rather you want your cache to follow certain logic, for instance, based on the time from the most recent calls to the least recent calls, aka least recent used, to store the cache 有时,您实际上并不是真正希望让垃圾回收来确定哪些值比其他值缓存的时间更长,而是希望您的缓存遵循某些逻辑,例如,根据从最近调用到最近调用的时间,最近最少使用,用于存储缓存
If the least recent used cache mechanism makes sense to your use case, you shall consider to make use of the lru_cache decorator from functools module which will save you a lot of effort to reinvent the wheels.
如果最不常用的缓存机制对您的用例有意义,则应考虑使用functools模块中的lru_cache装饰器,这将节省您大量的精力来重新设计轮子。
使用lru_cache进行缓存 (Cache with lru_cache)
The lru_cache accepts two arguments :
lru_cache接受两个参数:
- maxsize — to limit the size of the cache, when it is None, the cache can grow without bound maxsize —限制缓存的大小,当它为None时,缓存可以无限增长
typed — when set it as True, the arguments of different types will be cached separately, e.g. wkrf_cached_inquire(1) and wkrf_cached_inquire(1.0) will be cached as different entries
typed —设置为True时,不同类型的参数将分别缓存,例如wkrf_cached_inquire(1)和wkrf_cached_inquire(1.0)将作为不同的条目缓存
With the understanding of the lru_cache, let’s decorate our inquire_rate_online function to have the cache capability:
了解了lru_cache之后,让我们装饰一下inquire_rate_online函数以使其具有缓存功能:
from functools import lru_cache
@lru_cache(maxsize=None)
def inquire_rate_online(dimension):
result = requests.get(f"https://postman-echo.com/get?dim={dimension}")
if result.status_code == requests.codes.OK:
data = result.json()
return Rate(float(data["args"]["dim"]), float(data["args"]["dim"]))
return Rate(0.0,0.0)If we re-run our inquire_rate_online twice, you can see the same effect as previously in terms of the performance improvement:
如果我们重新运行inquire_rate_online两次,那么在性能改进方面您会看到与以前相同的效果:

And with this decorator function, you can also see the how the cache is used. The hits shows no. of calls have been returned from the cached results:
通过此装饰器功能,您还可以查看缓存的使用方式。 点击数不显示。 的呼叫已从缓存的结果返回:
inquire_rate_online.cache_info()
#CacheInfo(hits=1, misses=1, maxsize=None, currsize=1)Or you can manually clear all the cache to reset the hits and misses to 0:
或者,您可以手动清除所有缓存以将命中和未命中重置为0:
inquire_rate_online.cache_clear()局限性: (Limitations:)
Let’s also talk about the limitations of the solutions we discussed above:
让我们还讨论上面讨论的解决方案的局限性:
def random_x(x):
return x*random.randint(1,1000)- For keyword arguments, if you swap the position of the keywords, the two calls will be cached as separate entries 对于关键字参数,如果交换关键字的位置,则两个调用将被缓存为单独的条目
- It only works for the arguments that are immutable data type. 它仅适用于不可变数据类型的参数。
结论 (Conclusion)
In this article, we have discussed about the different ways of creating cache to improve the code performance whenever you have computational expensive operations or heavy I/O or network reads. Although lru_cache decorator provide a easy and clean solution for creating cache but it would be still better that you understand the underline implementation of cache before we just take and use.
在本文中,我们讨论了每当您进行计算量大的操作或繁重的I / O或网络读取操作时,创建高速缓存以提高代码性能的不同方法。 尽管lru_cache装饰器提供了一种简单而干净的创建缓存的解决方案,但是最好还是在使用和使用之前了解一下缓存的下划线实现。
We also discussed about the limitations for these solutions that you may need to take note before implementing. Nevertheless, it would still help you in a lot of scenarios where you can make use of these methods to improve your code performance.
我们还讨论了这些解决方案的局限性,在实施之前您可能需要注意这些局限性。 但是,它仍然可以在许多情况下为您提供帮助,在这些情况下,您可以使用这些方法来提高代码性能。
Originally published at https://www.codeforests.com on September 11, 2020.
最初于 2020年9月11日 发布在 https://www.codeforests.com 。
翻译自: https://medium.com/swlh/python-cache-the-must-read-tips-for-code-performance-f6ccd12e11b2
python 缓存















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









