





汤和油谁的沸点高
What is Web Scraping?
什么是网页抓取?
Web Scraping is a technique employed to extract large amounts of data from websites whereby the data is extracted and saved to a local file in your computer or to a database in table (spreadsheet) format.
Web爬网是一种用于从网站提取大量数据的技术,据此,数据将被提取并以表(电子表格)格式保存到计算机的本地文件或数据库中。
Why Web Scraping is important?
为什么网络爬虫很重要?
Web Scraping helps you to get the data that you want from the Web. These data are extracted from millions of URLs based on your requirement. These data play a vital role in key decision making in their business. These data will be used based on their needs. The data can be used to determine dynamic pricing. Reviews will help to understand the seller’s quality.
Web Scraping帮助您从Web获得所需的数据。 这些数据是根据您的要求从数百万个URL中提取的。 这些数据在其业务的关键决策中起着至关重要的作用。 这些数据将根据其需求使用。 该数据可用于确定动态定价。 评论将有助于了解卖方的质量。
Now that you know why web scraping is important, let us move on to the libraries and modules we will using to scarp websites.
既然您知道了网络抓取为什么很重要,那么让我们继续研究将用于简化网站的库和模块。
We will be using two of the most famous libraries and modules out there that are Beautiful Soup and requests.
我们将使用其中两个最著名的库和模块“ Beautiful Soup”和“ Requests”。
Beautiful Soup is a python package for parsing HTML and XML documents (including having malformed markup, i.e. non-closed tags, so named after tag soup). It creates a parse tree for parsed pages that can be used to extract data from HTML, which is useful for web scraping.
Beautiful Soup是一个用于解析HTML和XML文档的python包(包括标记格式错误,即非封闭标签,因此以标签汤命名)。 它为已解析的页面创建了一个解析树,可用于从HTML提取数据,这对于Web抓取非常有用。
The requests module allows you to send HTTP requests using Python.
请求模块允许您使用Python发送HTTP请求。
I’ll be scraping https://www.trustpilot.com/ for reviews and then perform some sentiment analysis on it. This site is very good for starters as it is regularly updated with new reviews.
我将抓取https://www.trustpilot.com/进行评论,然后对其进行一些情绪分析。 该网站非常适合初学者,因为它会定期更新以提供新的评论。
Before starting you need to have this installation in place:
在开始之前,您需要进行以下安装:
- Python (latest version) Python(最新版本)
- Beautiful Soup 美丽的汤
pip install beautifulsoup4- requests 要求
pip install requestsLet us see the content of the website we are gonna scrap.
让我们看看我们将要废弃的网站的内容。

让我们编码! (Let’s Code!)
Step 1: Create a python file (say reviews.py)
第1步:创建python文件(例如reviews.py)
Step 2: Import the libraries and modules
步骤2:导入库和模块
from bs4 import BeautifulSoup
import requestsStep3: Send the HTTP request and store it in variable
步骤3:发送HTTP请求并将其存储在变量中
url="https://www.trustpilot.com/"
req=requests.get(url).textThe get() method sends a GET request to the specified URL.
get()方法将GET请求发送到指定的URL。
.text converts the response into simple text.
.text将响应转换为简单文本。
Step 4: Parse the HTML data (req)
步骤4:解析HTML数据(req)
soup=BeautifulSoup(req, 'html.parser')The html.parser is a structured markup processing tool. It defines a class called HTMLParser, which is used to parse HTML files. It comes in handy for web crawling.
html.parser是结构化的标记处理工具。 它定义了一个名为HTMLParser的类,该类用于解析HTML文件。 它非常适用于网络爬网。
We create a BeautifulSoup object by passing two arguments:
我们通过传递两个参数来创建BeautifulSoup对象:
req: It is the raw HTML content.req:这是原始HTML内容。html.parser: Specifying the HTML parser we want to use.html.parser:指定我们要使用HTML解析器。
Step 5: Searching and navigating through the parse tree (HTML data)
步骤5:在分析树中搜索和浏览(HTML数据)
Now, we would like to extract some useful data from the HTML content. The soup object contains all the data in the nested structure which could be programmatically extracted. In our example, we are scraping a webpage consisting of some reviews. So, we would like to create a program to save those reviews (and all relevant information about them).
现在,我们想从HTML内容中提取一些有用的数据。 汤对象包含嵌套结构中的所有数据,这些数据可以通过编程方式提取。 在我们的示例中,我们正在抓取包含一些评论的网页。 因此,我们想创建一个程序来保存这些评论(以及有关它们的所有相关信息)。
For that, we first need to inspect the website and see which class or div contains all the reviews.
为此,我们首先需要检查网站,看看哪个班级或div包含所有评论。
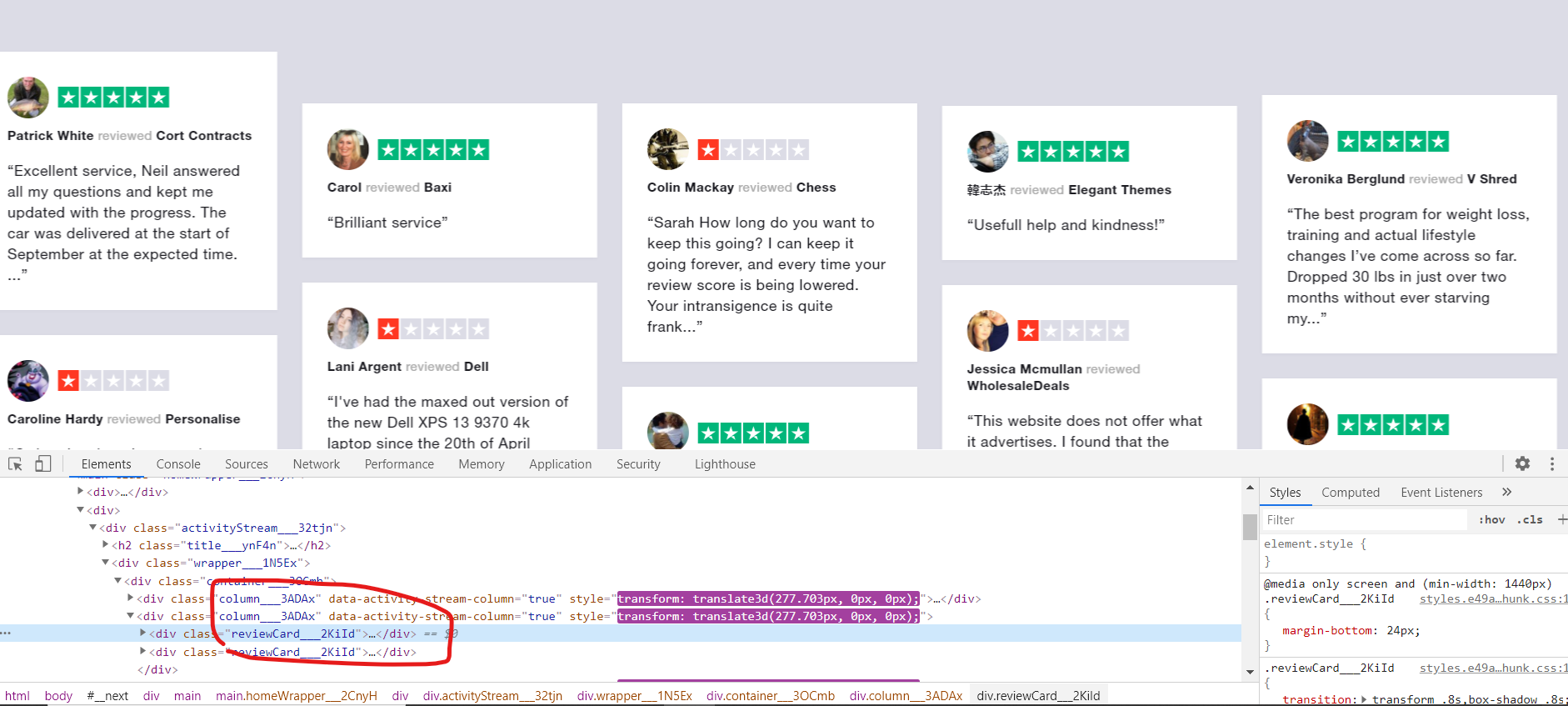
Now that we know which div class we need to target (‘reviewCard___2KiId’), let’s write the code.
现在我们知道我们需要定位哪个div类(“ reviewCard___2KiId ”),让我们编写代码。
reviews=soup.find_all("div", class_="reviewCard___2KiId").find_all() method is one of the most common methods in BeautifulSoup. It looks through a tag’s descendants and retrieves all descendants that match your filters.
.find_all()方法是BeautifulSoup中最常用的方法之一。 它会查看标签的后代,并检索与您的过滤器匹配的所有后代。
Now, we have stored all the reviews of the page into a variable called reviews . We can loop through it to get all the reviews and print them one by one.
现在,我们将页面的所有评论存储到一个名为reviews的变量中。 我们可以遍历它以获取所有评论并一一打印。
Step 6: Looping through the extracted data to get relevant information
步骤6:循环浏览提取的数据以获得相关信息
for review in reviews:
author=review.find("div", class_="author___3-7MA").a.text.strip()
rev=review.find("div", class_="reviewCardBody___2o5Ws").text
print(author)
print(rev)
print()Since the div with the class name “reviewCard___2KiId” has a lot of data in it, we need to parse down further to get the author’s name and the review itself.
由于类名称为“ reviewCard___2KiId ”的div中包含大量数据,因此我们需要进一步剖析以获得作者的姓名和评论本身。
Therefore we use .find() to find the “author___3–7MA” class div and then further navigate to the anchor tag and extract the text from it. .strip() is used to remove the extra spaces present.
因此,我们使用.find()查找“ author ___ 3-7MA ”类div,然后进一步导航至定位标记并从中提取文本。 .strip()用于删除存在的多余空格。
For the review, we need to navigate to the “reviewCardBody___2o5Ws” class div and extract the text from it.
对于审阅,我们需要导航到“ reviewCardBody___2o5Ws ”类div并从中提取文本。
Then simply display the results.
然后只需显示结果即可。
If you want to store it in a .csv file then visit the link.
如果要将其存储在.csv文件中,请访问链接。
Here you go, you just scrapped a website. Hurray !!
在这里,您只是报废了一个网站。 万岁!
完整代码 (Full Code)
from bs4 import BeautifulSoup
import requests
url="https://www.trustpilot.com/"
req=requests.get(url).text
soup=BeautifulSoup(req, 'html.parser')
reviews=soup.find_all("div", class_="reviewCard___2KiId")
for review in reviews:
author=review.find("div", class_="author___3-7MA").a.text.strip()
rev=review.find("div", class_="reviewCardBody___2o5Ws").text
print(author)
print(rev)
print()Quick Note: If you want to perform sentiment analysis on each review then visit the link(do give a star if you like it).
快速说明:如果您想对每条评论进行情感分析,请访问链接(如果喜欢,请加星号) 。
Check out my other article on Twitter Sentiment Analysis if you are more into sentiment analysis.
如果您更喜欢情绪分析,请查看我在Twitter情绪分析上的其他文章。
Quick Note: Web Scraping is considered illegal in many cases. It may also cause your IP to be blocked permanently by a website.
快速说明:在许多情况下,Web爬网被视为非法。 这也可能导致您的IP被网站永久阻止。
结论 (Conclusion)
In this article, I have shown you a simple example of how to create a web scraper in Python. From here, you can try to scrap any other website of your choice. In case of any queries, post them below in the comments section.
在本文中,我向您展示了一个简单的示例,该示例说明了如何使用Python创建网络抓取工具。 在这里,您可以尝试抓取您选择的任何其他网站。 如有任何疑问,请在下面的评论部分中发布。
If you require more examples then visit the link(do give a star if you like it).
如果您需要更多示例,请访问链接(如果喜欢,请加星号)。
Thanks for reading this article. I hope it’s helpful to you all!
感谢您阅读本文。 希望对您有帮助!
Happy Coding !!
快乐编码!
翻译自: https://medium.com/swlh/web-scraping-using-beautiful-soup-and-requests-in-python-ca44ff11e476
汤和油谁的沸点高

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









