





cnn网络架构演进
深度学习 (DEEP LEARNING)
- ILSVRC’10 ILSVRC'10
- ILSVRC’11 ILSVRC'11
- ILSVRC’12 (AlexNet) ILSVRC'12(AlexNet)
- ILSVRC’13 (ZFNet) ILSVRC'13(ZFNet)
- ILSVRC’14 (VGGNet) ILSVRC'14(VGGNet)
- ILSVRC’14 (GoogleNet) ILSVRC'14(GoogleNet)
- ILSVRC’15 (ResNet) ILSVRC'15(ResNet)
ILSVRC stands for Imagenet Large Scale Visual Recognition Challenge or the Imagenet Challenge .
ILSVRC代表Imagenet大规模视觉识别挑战赛或Imagenet挑战赛。
ILSVRC is a challenge which is held annually to allow contenders to classify the images correctly and generate the best possible predictions .
ILSVRC是一项每年都会举行的挑战,目的是让竞争者正确地对图像进行分类并生成最佳的预测。
亚历克斯网 (AlexNet)
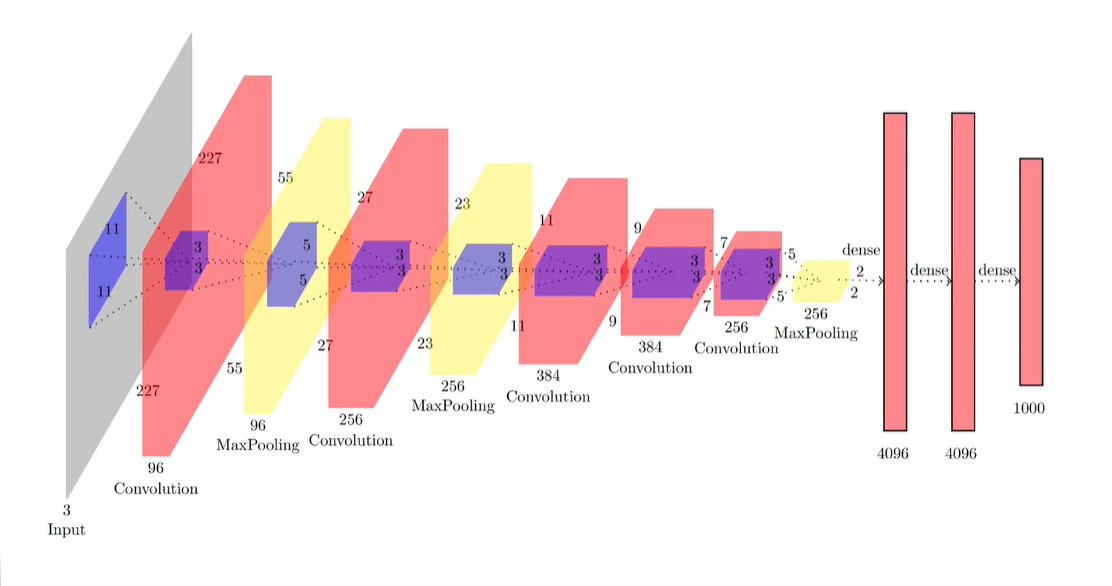
- AlexNet CNN architecture won the 2012 ImageNet ILSVRC challenge by a large margin : it achieve a top-five error rate of 17% while the second best achieved only 26% AlexNet CNN架构大获全胜,赢得了2012年ImageNet ILSVRC挑战:它的前五位错误率达到17%,而次优错误率仅达到26%
- It was developed by Alex Krizhevsky , Ilya Sutskever and Geoffrey Hinton . 它是由Alex Krizhevsky,Ilya Sutskever和Geoffrey Hinton开发的。
- It is quite similar to LeNet-5, only much larger and deeper, and it was the first to stack convolutional layers directly on top of each other, instead of stacking a pooling layer on top of each convolutional layer. 它与LeNet-5非常相似,只是更大和更深,它是第一个将卷积层直接堆叠在彼此之上的方法,而不是在每个卷积层之上堆叠池化层的方法。
- It consist of 8 convolutiona land fully connected layers and 3 max pooling layers . 它由8个卷积陆地完全连接层和3个最大池化层组成。

To reduce overfitting, the authors used two regularization techniques: first they applied dropout with a 50% dropout rate during training to the outputs of layers F8 and F9. Second, they performed data augmentation by randomly shifting the training images by various offsets, flipping them horizontally, and changing the lighting conditions.
为了减少过度拟合,作者使用了两种正则化技术:首先,他们在训练过程中对F8层和F9层的输出应用了50%的丢失率。 其次,他们通过将训练图像随机偏移各种偏移量,水平翻转它们并更改照明条件来执行数据增强。
ZFNet (ZFNet)
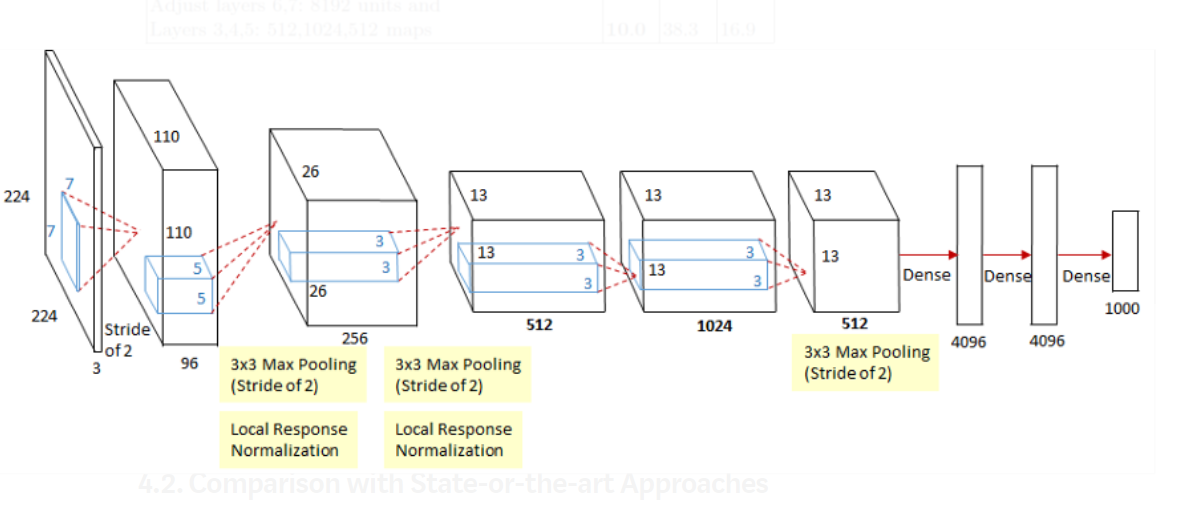
- ZFNet is another 8-layer CNN architecture . ZFNet是另一种8层CNN架构。
- ZFNet is largely similar to AlexNet, with the exception of a few of the layers . ZFNet在很大程度上类似于AlexNet,除了其中一些层。
- ZFNet CNN architecture won the 2013 ImageNet ILSVRC challenge. ZFNet CNN架构赢得了2013年ImageNet ILSVRC挑战。
- One major difference in the approaches was that ZF Net used 7x7 sized filters whereas AlexNet used 11x11 filters. 这些方法的主要区别在于ZF Net使用7x7大小的过滤器,而AlexNet使用11x11过滤器。
- The intuition behind this is that by using bigger filters we were losing a lot of pixel information, which we can retain by having smaller filter sizes in the earlier convolution layers. 这背后的直觉是,通过使用较大的滤镜,我们损失了很多像素信息,而在较早的卷积层中使用较小的滤镜尺寸可以保留这些像素信息。
- The number of filters increase as we go deeper. This network also used ReLUs for their activation and trained using batch stochastic gradient descent. 过滤器的数量随着我们的深入而增加。 该网络还使用ReLU激活它们,并使用批量随机梯度下降法对其进行了训练。
虚拟网 (VGGNet)

- The runner up in the ILSVRC 2014 challenge was VGGNet . VGGNet是2014年ILSVRC挑战赛的亚军。
- It was developed by K. Simon‐yan and A. Zisserman. 它由K.Simon-yan和A.Zisserman开发。
- During the design of the VGGNet, it was found that alternating convolution & pooling layers were not required. So VGGnet uses multiple of Convolutional layers in sequence with pooling layers in between. 在VGGNet的设计过程中,发现不需要交替的卷积和池化层。 因此,VGGnet依次使用多个卷积层,并在其间合并池层。
- It had a very simple and classical architecture, with 2 or 3 convolutional layers, a pooling layer, then again 2 or 3 convolutional layers, a pooling layer, and so on (with a total of just 16 convolutional layers), plus a final dense net‐work with 2 hidden layers and the output layer. It used only 3 × 3 filters, but many filters. 它具有非常简单和经典的架构,具有2或3个卷积层,一个池化层,然后又是2或3个卷积层,一个池化层,依此类推(总共只有16个卷积层),最后还有一个密集的具有2个隐藏层和输出层的网络。 它仅使用3×3滤镜,但使用了许多滤镜。
GoogLeNet (GoogLeNet)

- The GoogLeNet architecture was developed by Christian Szegedy et al. from Google Research,12 and it won the ILSVRC 2014 challenge by pushing the top-5 error rate below 7%. GoogLeNet体系结构是由Christian Szegedy等人开发的。 由Google Research提供,12并通过将前5位错误率降低到7%以下而赢得了2014年ILSVRC挑战。
- This great performance came in large part from the fact that the network was much deeper than previous CNNs 如此出色的性能很大程度上是因为该网络比以前的CNN更深
- This was made possible by sub-networks called inception modules, which allow GoogLeNet to use parameters much more efficiently than previous architectures: GoogLeNet actually has 10 times fewer parameters than AlexNet (roughly 6 million instead of 60 million). 这是通过称为“初始模块”的子网实现的,该子网使GoogLeNet可以比以前的体系结构更有效地使用参数:GoogLeNet的参数实际上比AlexNet少10倍(大约是600万,而不是6000万)。

GoogLeNet uses 9 inception module and it eliminates all fully connected layers using average pooling to go from 7x7x1024 to 1x1x1024. This saves a lot of parameters .
GoogLeNet使用9个初始模块,它使用平均池从7x7x1024到1x1x1024消除了所有完全连接的层。 这样可以节省很多参数。
Several variants of the GoogLeNet architecture were later proposed by Google researchers, including Inception-v3 and Inception-v4, using slightly different inception modules, and reaching even better performance.
Google研究人员后来提出了GoogLeNet架构的几种变体,包括Inception-v3和Inception-v4,它们使用了稍有不同的inception模块,并获得了更好的性能。
ResNet (ResNet)

- The ILSVRC 2015 challenge was won using a Residual Network (or ResNet) 使用残差网络(或ResNet)赢得了ILSVRC 2015挑战赛
- It was Developed by Kaiming He et al . 它是由Kaiming He等人开发的。
- It delivered an astounding top-5 error rate under 3.6%, using an extremely deep CNN composed of 152 layers. It confirmed the general trend: models are getting deeper and deeper, with fewer and fewer parameters. The key to being able to train such a deep network is to use skip connections (also called shortcut connections): the signal feeding into a layer is also added to the output of a layer located a bit higher up the stack. Let’s see why this is useful. 使用由152层组成的超深CNN,它的前5位错误率达到了惊人的3.6%。 它证实了总体趋势:模型越来越多,参数越来越少。 能够训练如此深的网络的关键是使用跳过连接(也称为快捷连接):馈入层的信号也将添加到位于堆栈中较高一点的层的输出中。 让我们看看为什么这很有用。

When training a neural network, the goal is to make it model a target function h(x). If you add the input x to the output of the network (i.e., you add a skip connection),then the network will be forced to model f(x) = h(x)-x rather than h(x). This is called residual learning .
在训练神经网络时,目标是使其成为目标函数h(x)的模型。 如果将输入x添加到网络的输出(即,添加跳过连接),则网络将被强制建模为f(x)= h(x)-x而不是h(x)。 这称为残差学习。
References :
参考文献:
https://www.guvi.in/ (Online Learning Platform)
https://www.guvi.in/ (在线学习平台)
Handson Machine Learning with Scikit (Reference Book , PDF -https://drive.google.com/file/d/16DdwF4KIGi47ky7Q_B-4aApvMYW2evJZ/view?usp=sharing) .
使用Scikit进行的Handson机器学习(参考书,PDF- https: //drive.google.com/file/d/16DdwF4KIGi47ky7Q_B-4aApvMYW2evJZ/view?usp=sharing)。
翻译自: https://medium.com/analytics-vidhya/7-cnn-architectures-evolved-from-2010-2015-fd5869bd744e
cnn网络架构演进















 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









