





python web应用
Living in today’s world, we are surrounded by different data all around us. The ability to collect and use this data in our projects is a must-have skill for every data scientist.
生活在当今世界中,我们周围遍布着不同的数据。 在我们的项目中收集和使用这些数据的能力是每位数据科学家必不可少的技能。
There are so many tutorials online about how to use specific Python libraries to harvest online data. However, you can rarely find tutorials on choosing the best library for your particular application.
在线上有太多关于如何使用特定的Python库来收集在线数据的教程。 但是,您很少会找到有关为特定应用程序选择最佳库的教程。
Python offers a variety of libraries that one can use to scrape the web, libraires such as Scrapy, Beautiful Soup, Requests, Urllib, and Selenium. I am quite sure that more libraries exist, and more will be released soon considering how popular Python is.
Python提供了多种可用于抓取网络的库,例如Scrapy,Beautiful Soup,Requests,Urllib和Selenium等库。 我很确定存在更多的库,并且考虑到Python的流行程度,很快就会发布更多的库。
In this article, I will cover the 5 libraries I just mentioned, will give an overview of each of them, for example, code and what are the best applications and cases for each of them.
在本文中,我将介绍我刚刚提到的5个库,并对它们进行概述,例如,代码以及对它们而言最佳的应用程序和案例。
For the rest of this article, I will use this sandbox website containing books to explain specific aspects of each library.
对于本文的其余部分,我将使用这个沙箱网站包含的书来解释每个库的具体方面。
1.崎cra (1. Scrapy)
Scrapy is one of the most popular Python web scrapping libraries right now. It is an open-source framework. This means it is not even a library; it is rather a complete tool that you can use to scrape and crawl around the web systematically.
Scrapy是目前最流行的Python Web抓取库之一。 这是一个开源框架。 这意味着它甚至不是图书馆。 它是一个完整的工具,可用于系统地在网络上抓取和爬网。
Scrapy was initially designed to build web spiders that can crawl the web on their own. It can be used in monitoring and mining data, as well as automated and systematic testing.
Scrapy最初旨在构建可自动爬网的网络蜘蛛。 它可以用于监视和挖掘数据以及自动和系统的测试。
It is also very CPU and memory effecient compared to other Python approaches to scrape the web. The downside to using Scrapy is that installing it and getting to work correctly on your device can be a bit of a hassle.
与其他刮取Web的Python方法相比,它在CPU和内存方面也非常有效。 使用Scrapy的缺点是安装它并在您的设备上正常工作可能有点麻烦。
概述和安装 (Overview and installation)
To get started with Scrapy, you need to make sure that you’re running Python 3 or higher. To install Scrapy, you can simply write the following command in the terminal.
要开始使用Scrapy,您需要确保运行的是Python 3或更高版本。 要安装Scrapy,您只需在终端中编写以下命令即可。
pip install scrapyOnce Scrapy is successfully installed, you can run the Scrapy shell, by typing:
成功安装Scrapy之后,您可以通过键入以下命令运行Scrapy Shell:
scrapy shellWhen you run this command, you will see something like this:
运行此命令时,您将看到以下内容:
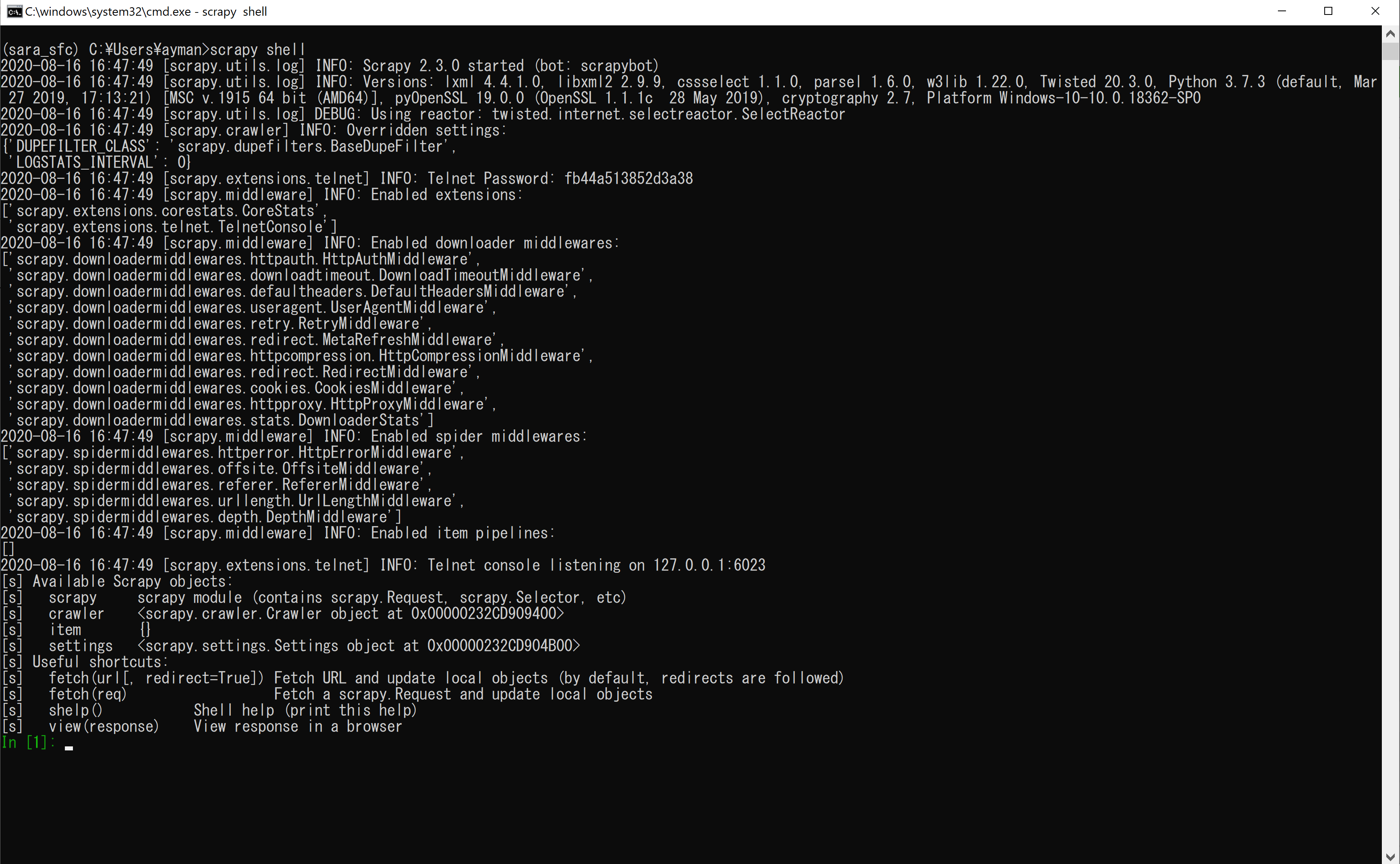
You can use the Scrapy shell to run simple commands, for example, you can fetch the HTML content of a website using the fetch function. So, let's say I want to fetch this book website; I can simply do that it in the shell.
您可以使用Scrapy shell来运行一些简单的命令,例如,您可以获取使用网站HTML内容fetch功能。 所以,让我们说,我想取这本书的网站; 我可以在外壳中简单地做到这一点。

fetch("http://books.toscrape.com/")Now, you can then use the view function to open up this HTML file in your default browser. Or you can just print out the HTML source code of the page.
现在,您可以使用view功能在默认浏览器中打开此HTML文件。 或者,您可以只打印页面HTML源代码。
view(response)
print(response.text)Of course, you won’t be scaring a website just to open it in your browser. You probably want some specific information from the HTML text. This is done using CSS Selectors.
当然,您不会只是在浏览器中打开网站而感到害怕。 您可能需要HTML文本中的一些特定信息。 这是使用CSS选择器完成的。
You will need to inspect the structure of the webpage you want to fetch before you start so you can use the correct CSS selector.
在开始之前,您需要检查要获取的网页的结构,以便可以使用正确CSS选择器。
什么时候使用Scarpy? (When to use Scarpy?)
The best case to use Scrapy is when you want to do a big-scale web scraping or automate multiple tests. Scrapy is very well-structured, which allows for better flexibility and adaptability to specific applications. Moreover, the way Scrapy projects are organized makes it easier o maintain and extend.
最好使用Scrapy的情况是要进行大规模的Web抓取或自动化多个测试时。 Scrapy的结构非常好,可以为特定应用程序提供更好的灵活性和适应性。 此外,Scrapy项目的组织方式使维护和扩展变得更容易。
I would suggest that you avoid using Scrapy if you have a small project or you want to scrape one or just a few webpages. In this case, Scarpy will overcomplicate things and won’t add and benefits.
如果您的项目很小,或者只想抓取一个或几个网页,我建议您避免使用Scrapy。 在这种情况下,Scarpy将使事情变得复杂,并且不会增加收益。
2.要求 (2. Requests)
Requests is the most straightforward HTTP library you can use. Requests allow the user to sent requests to the HTTP server and GET response back in the form of HTML or JSON response. It also allows the user to send POST requests to the server to modify or add some content.
请求是您可以使用的最直接的HTTP库。 请求允许用户将请求发送到HTTP服务器,并以HTML或JSON响应的形式返回GET响应。 它还允许用户向服务器发送POST请求,以修改或添加一些内容。
Requests show the real power that can be obtained with a well designed high-level abstract API.
请求显示了使用精心设计的高级抽象API可以获得的真正功能。
概述和安装 (Overview and installation)
Requests is often included in Python’s built-in libraries. However, if for some reason you can’t import it right away, you can install it easily using pip.
请求通常包含在Python的内置库中。 但是,如果由于某种原因无法立即导入,则可以使用pip轻松安装。
pip install requestsYou can use Requests to fetch and clean well-organized API responses. For example, let’s say I want to look up a movie in the OMDB database. Requests allow me to send a movie name to the API, clean up the response, and print it in less than 10 lines of code — if we omit the comments 😄.
您可以使用请求来获取和清理组织良好的API响应。 例如,假设我要在OMDB数据库中查找电影。 请求允许我将影片名称发送到API,清理响应,并在少于10行的代码中将其打印-如果我们省略注释😄。
何时使用请求? (When to use Requests?)
Requests is the ideal choice when you’re starting with web scraping, and you have an API tp contact with. It’s simple and doesn’t need much practice to master using. Requests also doesn’t require you to add query strings to your URLs manually. Finally, it has a very well written documentation and supports the entire restful API with all its methods (PUT, GET, DELETE, and POST).
当您开始抓取网页并且与API tp联系时, 请求是理想的选择。 它很简单,不需要太多练习就可以掌握。 请求也不需要您手动将查询字符串添加到您的URL。 最后,它有一个写得很好的文档,并以其所有方法(PUT,GET,DELETE和POST)支持整个Restful API。
Avoid using Requests if the webpage you’re trying or desiring has JavaScrip content. Then the responses may not parse the correct information.
如果您尝试或想要的网页包含JavaScrip内容,请避免使用请求。 然后,响应可能无法解析正确的信息。
3. Urllib (3. Urllib)
Urllib is a Python library that allows the developer to open and parse information from HTTP or FTP protocols. Urllib offers some functionality to deal with and open URLs, namely:
Urllib是一个Python库,允许开发人员打开和解析来自HTTP或FTP协议的信息。 Urllib提供了一些处理和打开URL的功能,即:
urllib.request: opens and reads URLs.
urllib.request:打开并读取URL。
urllib.error: catches the exceptions raised by urllib.request.
urllib.error:捕获urllib.request引发的异常。
urllib.parse: parses URLs.
urllib.parse:解析URL。
urllib.robotparser: parses robots.txt files.
urllib.robotparser:解析robots.txt文件。
概述和安装 (Overview and installation)
The good news is, you don’t need to install Urllib since it is a part of the built-in Python library. However, in some rare cases, you may not find Urllib in your Python package. If that’s the case, simply install it using pip.
好消息是,您不需要安装Urllib,因为它是内置Python库的一部分。 但是,在极少数情况下,您可能在Python包中找不到Urllib。 如果是这种情况,只需使用pip安装即可。
pip install urllibYou can use Urllib to explore and parse websites; however, it won’t offer you much functionality.
您可以使用Urllib浏览和解析网站。 但是,它不会为您提供太多功能。
何时使用Urllib? (When to use Urllib?)
Urllib is a little more complicated than Requests; however, if you want to have better control over your requests, then Urllib is the way to go.
Urllib比Requests要复杂一些; 但是 ,如果您想更好地控制自己的请求,则可以使用Urllib。
4.美丽的汤 (4. Beautiful Soup)
Beautiful Soup is a Python library that is used to extract information from XML and HTML files. Beautiful Soup is considered a parser library. Parsers help the programmer obtain data from an HTML file. If parsers didn’t exist, we would probably use Regex to match and get patterns from the text, which is not an effecient or maintainable approach.
Beautiful Soup是一个Python库,用于从XML和HTML文件中提取信息。 Beautiful Soup被视为解析器库。 解析器帮助程序员从HTML文件获取数据。 如果不存在解析器,我们可能会使用Regex匹配并从文本中获取模式,这不是一种有效或可维护的方法。
Luckily, we don’t need to do that, because we have parsers!
幸运的是,我们不需要这样做,因为我们有解析器!
One of Beautiful Soup’s strengths is its ability to detect page encoding, and hence get more accurate information from the HTML text. Another advantage of Beautiful Soup is its simplicity and ease.
Beautiful Soup的优势之一是它能够检测页面编码,从而从HTML文本中获取更准确的信息。 美丽汤的另一个优点是简单易用。
概述和安装 (Overview and installation)
Installing Beautiful Soup is quite simple and straight forward. All you have to do is type the following in the terminal.
安装Beautiful Soup非常简单直接。 您所要做的就是在终端中键入以下内容。
pip install beautifulsoup4That’s it! You can get right to scraping.
而已! 您可以直接进行抓取。
Now, Beautiful Soup is a parser that we just mentioned, which means we’ll need to get the HTML first and then use Beautiful Soup to extract the information we need from it. We can use Urllib or Requests to get the HTML text from a webpage and then use Beautiful Soup to cleaning it up.
现在,Beautiful Soup是我们刚刚提到的解析器,这意味着我们需要首先获取HTML,然后使用Beautiful Soup从中提取所需的信息。 我们可以使用Urllib或Requests从网页中获取HTML文本,然后使用Beautiful Soup对其进行清理。
Going back to the webpage from before, we can use Requests to fetch the webpage’s HTML source and then use Beautiful Soup to get all links inside the <a> in the page. And we can do that with a few lines of code.
回到以前的网页,我们可以使用请求来获取网页HTML源,然后使用Beautiful Soup来获取页面<a>中的所有链接。 我们可以用几行代码来做到这一点。
何时使用美丽汤? (When to use Beautiful Soup?)
If you’re just starting with webs scarping or with Python, Beautiful Soup is the best choice to go. Moreover, if the documents you’ll be scraping are not structured, Beautiful Soup will be the perfect choice to use.
如果您只是从网上清理或Python开始,那么Beautiful Soup是最好的选择。 此外,如果您要抓取的文档没有结构化,那么Beautiful Soup将是使用的理想选择。
If you’re building a big project, Beautiful Soup will not be the wise option to take. Beautiful Soup projects are not flexible and are difficult to maintain as the project size increases.
如果您要建设一个大型项目,则“美丽汤”将不是明智的选择。 Beautiful Soup项目不灵活,并且随着项目规模的增加而难以维护。
5.Selenium (5. Selenium)
Selenium is an open-source web-based tool. Selenium is a web-driver, which means you can use it to open a webpage, click on a button, and get results. It is a potent tool that was mainly written in Java to automate tests.
Selenium是基于Web的开源工具。 Selenium是一个网络驱动程序,这意味着您可以使用它来打开网页,单击按钮并获得结果。 这是一个强大的工具,主要是用Java编写的用于自动化测试的工具。
Despite its strength, Selenium is a beginner-friendly tool that doesn’t require a steep learning curve. It also allows the code to mimic human behavior, which is a must in automated testing.
尽管具有优势,Selenium还是一种适合初学者的工具,不需要陡峭的学习曲线。 它还允许代码模仿人类行为,这在自动化测试中是必须的。
概述和安装 (Overview and installation)
To install Selenium, you can simply use the pip command in the terminal.
要安装Selenium,您只需在终端中使用pip命令。
pip install seleniumIf you want to harvest the full power of Selenium — which you probably will — you will need to install a Selenium WebDriver to drive the browser natively, as a real user, either locally or on remote devices.
如果您想充分利用Selenium的全部功能(可能会),则需要安装Selenium WebDriver以本地用户或本地设备在本地或远程设备上以本机驱动浏览器。
You can use Selenium to automate logging in to Twitter — or Facebook or any site, really.
实际上,您可以使用Selenium来自动登录Twitter或Facebook或任何站点。
何时使用Selenium? (When to use Selenium?)
If you’re new to the web scraping game, yet you need a powerful tool that is extendable and flexible, Selenium is the best choice. Also, it is an excellent choice if you want to scrape a few pages, yet the information you need is within JavaScript.
如果您不熟悉网络抓取游戏,但是您需要一个可扩展且灵活的强大工具,那么Selenium是最佳选择。 另外,如果要刮几页,这也是一个极好的选择,但是所需的信息在JavaScript中。
Using the correct library for your project can save you a lot of time and effort, which could be critical for the success of the project.
为您的项目使用正确的库可以节省大量时间和精力,这对于项目的成功至关重要。
As a data scientist, you will probably come across all these libraries and maybe more during your journey, which is, in my opinion, the only way to know the pros and cons of each of them. Doing so, you will develop a sixth sense to lead you through choosing and using the best library in future projects.
作为数据科学家,您可能会遇到所有这些库,并且在您的旅途中可能会遇到更多的库,我认为这是了解每个库的优缺点的唯一方法。 这样做,您将形成第六感,引导您选择和使用未来项目中的最佳库。
python web应用















 2989
2989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









