





陆涛喜欢夏琳吗
技术系列中的女性 (WOMEN IN TECHNOLOGY SERIES)
Interest in data science has been exponentially increasing over the past decade, and more and more people are working towards making a career switch into the field. In 2020, articles and YouTube videos about transitioning into a career in data science abound. Yet, for a lot of people, many key questions about this switch still remain: How do you break into data science from a social science background? And what are some of the most important skills in fields like psychology that can be applied to data science?
在过去的十年中,人们对数据科学的兴趣呈指数增长,并且越来越多的人致力于将职业转变为该领域。 2020年,有关如何过渡到数据科学职业的文章和YouTube视频不胜枚举。 但是,对于许多人来说,有关此切换的许多关键问题仍然存在:如何从社会科学背景闯入数据科学? 在心理学等领域可以应用于数据科学的最重要的技能是什么?
Charlene Chambliss has an inspiring and non-traditional career path. Currently, she leverages state-of-the-art natural language processing to “build smarter tools for analyzing massive amounts of information.¹” In the past two years, she has written about NLP topics including BERT for named entity recognition, and word2vec for news headline analysis to name a few. However, before her current role as a machine learning engineer, she held roles in marketing, psychology, research, and interned as a data scientist in the skincare industry.
夏琳·香布利斯(Charlene Chambliss)具有非传统的职业道路。 目前,她利用最先进的自然语言处理能力来“构建用于分析大量信息的更智能工具。¹”。在过去两年中,她撰写了有关NLP主题的文章,包括用于命名实体识别的BERT和用于命名实体识别的word2vec。新闻标题分析等。 但是,在担任机器学习工程师之前,她曾在市场营销,心理学,研究领域任职,并在皮肤护理行业担任数据科学家的工作。
Amber: Could you tell us a bit about your background?Charlene: Sure! I’ve had kind of an unusual path into data science, so I’ll start from the beginning and go into some detail to help illuminate what it took for me.
琥珀色:您能谈谈您的背景吗? 夏琳:当然! 我在数据科学领域走过一条不寻常的道路,因此,我将从头开始,并进行一些详细介绍,以帮助阐明对我而言所需要的。
I grew up in a smallish agricultural town (Modesto, CA), where my dad worked at Safeway (still does!) and my mom was a stay-at-home mom. They really impressed upon me the importance of taking my education seriously, which was fine with me because I loved learning and I enjoyed making them proud of me.
我在一个很小的农业小镇(加利福尼亚州莫德斯托)长大,我父亲曾在Safeway工作(现在还在!),妈妈是一个全职妈妈。 他们的确给我留下了认真对待我的教育的重要性,这对我来说很好,因为我热爱学习,并且喜欢让他们为我感到骄傲。
Ever since I was little, I wanted to be a scientist. I loved tinkering and learning how things worked. My mom indulged my curiosity by taking me to the library (I would come home with a stack of like 12 books), having me help her in the kitchen (cooking = chemistry!), and getting me the occasional toy science kit.
从小我就想成为一名科学家。 我喜欢修补和学习事物的工作原理。 妈妈通过带我去图书馆(我会带着一堆12本书回家),让我在厨房里帮助她(烹饪=化学!)和偶尔给我的玩具科学工具包来满足我的好奇心。
That interest carried on through high school and into freshman year of college, where I had decided I wanted to study chemical engineering and become a flavor scientist, because chemistry was my favorite subject. I (adorably) thought that I would simply invent new flavors to make healthy food taste better, so people would have an easier time eating salads and vegetables, and thus be healthier overall. I hated eating salads and vegetables, so 17-year-old-me thought I was brilliant and that this was an amazing solution.
这种兴趣一直持续到高中,然后进入大学一年级,在那里我决定要学习化学工程并成为一名风味科学家,因为化学是我最喜欢的学科。 我(一直)认为,我只是发明新的口味以使健康食品的味道更好,所以人们可以更轻松地食用沙拉和蔬菜,从而总体上更健康。 我讨厌吃沙拉和蔬菜,所以我17岁的我认为我很聪明,这是一个了不起的解决方案。
“Studying a social science is, in general, a great way to get used to dealing with muddy, hard-to-define questions, a skill that’s key to delivering data science work that decision-makers will actually feel comfortable using.”
“一般来说,学习社会科学是一种很好的方式来习惯处理泥泞的,难以定义的问题,这是交付决策者实际上会感到满意的数据科学工作的关键技能。”
I kept up my education focus and work ethic throughout high school, and made it into Stanford for undergrad. Frankly, that was pretty unexpected for me — I thought I would be going to UC Davis and maaaybe Berkeley if I was really lucky. Around half of folks who graduate from my high school don’t end up going to college at all, so even these felt like pretty high ambitions. Of my graduating class of 500 that year, I think only around 5 of us made it into “top schools” (Berkeley, Stanford, Harvard).
在整个高中期间,我一直保持着教育重点和职业道德,并进入斯坦福大学攻读本科。 坦白说,这对我来说是非常出乎意料的-如果我真的很幸运,我想我会去加州大学戴维斯分校和maaaybe Berkeley。 大约有一半从我的高中毕业的人根本没有去上大学,因此即使是这些人也感觉到很高的野心。 那一年我的500届毕业班中,我认为只有大约5人进入了“顶尖学校”(伯克利,斯坦福,哈佛)。
What I was really not expecting when I went to Stanford was the culture shock I was in for. The vast majority of students at Stanford come from upper-income backgrounds, with a median family income of $167,500. They are, by and large, the kinds of kids who have college-educated, professional parents, go to the best, most well-funded high school in town, and have paid tutors to help them out in any area they’re struggling with. Meanwhile, I grew up with a HH income around a quarter of that, and the level of preparation I received in some areas relative to my peers was reflective of that difference. (My parents and teachers were wonderful and had done their best, but there’s only so much one can do with limited resources.)
我真正去斯坦福大学时没想到的是,我对文化的震惊。 斯坦福大学的绝大多数学生来自高收入家庭,家庭收入中位数为167,500美元 。 总的来说,他们是那种具有受过大学教育的专业父母,去城里最好,资金最充裕的高中,并付钱给家教的孩子,他们可以在他们所苦苦挣扎的任何地方帮助他们。 同时,我的家庭生活收入约为家庭收入的四分之一,在某些方面相对于同龄人,我的准备水平反映了这种差异。 (我的父母和老师都很出色,已经尽了最大的努力,但是只有有限的资源可以做很多事情。)
Suddenly, I found myself feeling very insecure about my abilities (particularly my aptitude for math and computer science) and was really questioning whether I measured up to the other students. I didn’t realize that our backgrounds had been so different, since no one goes around talking about that sort of thing, so I attributed differences in performance to my own lack of ability. I was also the only one from my high school who went to Stanford that year, so I didn’t know anyone when I got there and had no one to talk to about what I was experiencing. The feeling of being an impostor never really went away during my time at Stanford, but I did at least get better at faking-it-’til-I-made-it.
突然,我发现自己对自己的能力(尤其是我对数学和计算机科学的天赋)感到很不安全,并且真的在质疑我是否对其他学生进行了评估。 我没有意识到我们的背景如此不同,因为没有人谈论这种事情,所以我将性能差异归因于自己缺乏能力。 我也是那年高中唯一去过斯坦福大学的人,所以我到那儿时不认识任何人,也没有人谈论我的经历。 在斯坦福大学期间,作为冒名顶替者的感觉从未真正消失过,但我至少在伪造“直到我造出来的”方面做得更好。
I did make it through Stanford, although I ended up not pursuing chemical engineering and also needed to take a year off after junior year to help with my parents’ divorce (my mom is disabled and needed help selling our family home and moving out). I graduated with a B.A. in Psychology in 2017 — first in my immediate family to get a 4-year degree — but I felt like I had made a lot of mistakes along the way due to a lack of guidance and role models. Even just searching for my first job proved difficult, because I could really only turn to the career center for advice on how to navigate the job market for “educated professionals.” The pamphlets and 30-minute consultations they could offer couldn’t really fill in all the gaps, but after a lot of research and attending career fairs, I was able to land a job doing social media marketing for a small agency.
我确实通过斯坦福大学取得了成功,尽管我最终没有追求化学工程,并且还需要在大三后休假一年以帮助父母离婚(我的母亲残疾,需要帮助我们卖掉家并搬出去)。 我于2017年获得心理学学士学位-我是直系亲属中第一个获得4年学位的人-但由于缺乏指导和榜样,我觉得自己一路上犯了很多错误。 即使只是寻找我的第一份工作也证明是困难的,因为我真的只能向职业中心寻求关于如何为“受过教育的专业人员”打入职场的建议。 他们所能提供的小册子和30分钟的咨询服务并不能真正填补所有空白,但是经过大量研究和参加职业博览会之后,我得以找到了一家小型代理商从事社交媒体营销的工作。

Without going into too much detail about one’s financial and overall career prospects as a psychology major with only a Bachelor’s, it became clear to me over the course of my time in that job that I wasn’t going to get where I wanted to go career-wise unless I made a big change. So near the end of 2017, I decided I wanted to go into data science, specifically focusing on machine learning, and threw myself into GRE studies so I could get my applications in in time for Fall 2018 admissions. (I’ll go into more detail about why I chose data science, and NLP in particular, in the next section.)
没有过多地了解只有心理学士学位的心理学专业的财务和整体职业前景,在我从事该工作的过程中,我很清楚自己不会去自己想去的职业-除非我做了很大的改变。 因此,在2017年底左右,我决定想进入数据科学领域,特别专注于机器学习,然后投入GRE学习,以便在2018年秋季入学之前及时获得申请。 (在下一节中,我将详细介绍为什么选择数据科学,尤其是NLP。)
I enrolled in my M.S. as planned, doing my coursework and studying as much as I could outside class, focusing especially on stats, linear algebra, Python, and machine learning. The degree coursework was all in R, so I learned Python entirely on my own using a combination of online classes and a massive 1500+ page textbook (Learning Python). Toward the end of my first year (spring 2019), I landed a data science internship at Curology and worked there through fall. Then, at the beginning of my second year, I partnered up with an amazing mentor, Nina Lopatina, through SharpestMinds, because I had decided I wanted to focus specifically on getting a role doing NLP. At the end of the 10-week mentorship, I started looking for jobs, and got an offer to join Primer full-time in December of 2019.
我按计划报名参加了MS课程,完成了课业并在课外学习了很多东西,尤其是专注于统计,线性代数,Python和机器学习。 学位课程全部用R编写,所以我结合了在线课程和庞大的1500多页教科书( Learning Python ),完全靠自己学Python 。 在第一年末(2019年Spring),我在Curology进行了数据科学实习,并一直到秋天工作。 然后,在第二年开始的时候,我通过SharpestMinds与一位了不起的导师Nina Lopatina合作,因为我决定我想专门专注于扮演NLP的角色。 在为期10周的指导期结束后,我开始寻找工作,并于2019年12月获得了全职加入Primer的邀请。
I would need to defer the last semester of my MS program to start full-time, which was a tough call, but the experience was more important to me, so I did. It turns out that that decision was frighteningly well-timed, because the COVID-19 pandemic decimated the recent grad job market only a few months later. I have classmates who are still struggling to find jobs, and I easily could have ended up in the same situation. I realize that I am very privileged that my roll of the dice worked out so well.
我需要推迟我的MS程序的最后一个学期才能开始全日制学习,这是一个艰难的决定,但是经验对我来说更重要,所以我做到了。 事实证明,这一决定的时机非常糟糕,因为COVID-19大流行仅在几个月后就摧毁了最近的毕业生就业市场。 我有一些仍在努力寻找工作的同学,而我很可能最终会遇到同样的情况。 我意识到我很荣幸自己的骰子制作得如此出色。
All in all, it took about 2 years to transition from marketing into a full-time machine learning engineer role, from a background of relatively little math and programming experience. (Prior to 2017, I had only taken single-variable calculus, basic/intro statistics, and one Java programming class.)
总的来说,从相对较少的数学和编程经验的背景下,从市场营销过渡到专职机器学习工程师角色大约花费了2年时间。 (在2017年之前,我只参加了单变量演算,基本/入门统计和一个Java编程课程。)
A: Before working in the data science industry, you studied psychology at Stanford. Could you tell us how your experience there influenced your career path into data science?C: Studying a social science is, in general, a great way to get used to dealing with muddy, hard-to-define questions, a skill that’s key to delivering data science work that decision-makers will actually feel comfortable using. It’s sort of a Murphy’s Law mindset, as applied to experiment results: I’ve become extremely attentive to anything that could be “confounding” or otherwise influencing the results of my analysis, and I can call attention to potential caveats whenever appropriate. That way, the stakeholder can leverage their domain knowledge to decide whether they think those things do or don’t matter for our conclusions, and we can adjust the experiment/analysis accordingly.
答:在从事数据科学行业之前,您曾在斯坦福大学学习过心理学。 您能否告诉我们您的经验如何影响您进入数据科学的职业道路? C:一般而言,学习社会科学是一种很好的方式来习惯于处理泥泞,难以定义的问题,这是交付决策者实际上会感到满意的数据科学工作的关键技能。 这有点像墨菲定律的心态,用于实验结果:我已经非常注意可能会“混淆”或影响分析结果的任何事情,并且在适当的时候我可以引起注意。 这样,利益相关者可以利用他们的领域知识来决定他们认为这些事情对我们的结论是否重要,并且我们可以相应地调整实验/分析。
In addition to that, I’ve probably spent a collective year and a half working in psychology labs to implement experiments. While there is a lot of “grunt work” involved in these sorts of positions, like data entry, you also get a front-row seat to how scientific studies actually happen, from data collection to the final statistical analyses, and you get to participate in some of the decisions that are made along the way. This prepared me quite well for data science workflows, as well as giving me some practical skills (like working with spreadsheets) and a can-do attitude that would be helpful later.
除此之外,我可能已经花了一年半的时间在心理学实验室工作以实施实验。 尽管这类职位涉及很多“艰巨的工作”,例如数据输入,但您也可以从数据收集到最终的统计分析,在科学研究的实际过程中占有一席之地,并参与其中在此过程中做出的一些决定中。 这使我为数据科学工作流程做好了充分的准备,同时还为我提供了一些实践技能(例如,使用电子表格)和可以做的态度,这些将对以后的工作有所帮助。
A: Previously, you interned at Curology as a data science intern. Could you discuss how data science looks like in the skincare industry? What types of questions did you and your team seek to answer? And what are some of the most interesting projects you worked on in your time at Curology?C: I think my experience at Curology was a good example of how data science looks in a D2C (direct-to-consumer) business in general, especially in a startup context. It is often the case that the first thing consumer-focused businesses need data-wise (after data engineers, of course) is really just a lot of descriptive statistics, often known as “consumer insights.”
答:以前,您曾在Curology实习过,是一名数据科学实习生。 您能否讨论一下数据科学在护肤行业中的样子? 您和您的团队寻求回答什么类型的问题? 您在Curology期间从事哪些最有趣的项目? C:我认为我在Curology上的经验很好地说明了数据科学在D2C(直接面向消费者)业务中的表现,尤其是在启动环境中。 通常,以消费者为中心的企业首先需要数据方面的东西(当然,在数据工程师之后)实际上只是大量描述性统计信息,通常被称为“消费者洞察力”。
Since I was embedded in the user acquisition department, I was especially focused on answering questions that would help us make better marketing decisions across the many different acquisition channels. 80% of the time, I was writing SQL against our data warehouse to better understand the behavior of different customer segments and track how that behavior trended over time, and turning those findings into interpretable dashboards for use by the rest of the team. The other 20% of the time, I used Python to analyze and visualize customers’ survey responses to better understand what they liked and needed from Curology.
自从我进入用户获取部门以来,我特别专注于回答可以帮助我们在许多不同的获取渠道中做出更好的营销决策的问题。 80%的时间里,我正在针对我们的数据仓库编写SQL,以更好地了解不同客户群的行为,并跟踪该行为随时间的变化趋势,并将这些发现转化为可解释的仪表板,以供团队其他成员使用。 另外20%的时间,我使用Python分析和可视化了客户的调查反馈,以更好地了解他们对Curology的需求。
So a few of the questions I got to ask and answer were:
所以我要问和回答的几个问题是:
- How do customers’ skincare goals vary based on their demographics (gender, age, etc.)? What is most important to each segment of customers, and how can we make sure we serve each of their needs well? 客户的护肤目标如何根据其受众特征(性别,年龄等)而变化? 对于每个客户群而言,最重要的是什么?我们如何确保我们很好地满足他们的每一个需求?
- Which of our channels have had the “stickiest” customers, i.e. customers who have tended to stay with us the longest? Do any other behaviors or preferences correlate with subscription length? 我们哪个渠道拥有“最粘性”客户,即那些与我们在一起时间最长的客户? 是否有其他行为或喜好与订阅时间有关?
- Can we build a model that will leverage the historical data we have on customer behavior to predict customer lifetime value (LTV) at time of signup? (This is actually very hard when your customer base is growing quickly, due to sampling considerations!) 我们可以建立一个模型来利用我们在客户行为方面的历史数据来预测注册时的客户生命周期价值(LTV)吗? (出于抽样考虑,当您的客户群快速增长时,这实际上非常困难!)
I learned a ton. Doing data analysis with SQL doesn’t just help you learn SQL; it actually helps you think analytically, as cliche as that sounds. You first have to learn to translate someone’s natural-language question about customers into the appropriate metrics (where those metrics will often have different filter conditions and assumptions, depending on the intended use-case!), then ALSO learn how to actually execute that in a mathematically and technically correct way using SQL code. Sometimes you will even have to make sure that you are using the correct tables/data, because tables get deprecated, not all data makes it into the table due to bugs in the pipeline, or X metric only started being tracked 6 months ago, etc. There are many practical considerations you need to keep in the back of your mind when doing this kind of work. Doing rock-solid data analysis is just as challenging as machine learning IMO, albeit sometimes for different reasons.
我学到了很多。 使用SQL进行数据分析不仅可以帮助您学习SQL,还可以帮助您更好地学习SQL。 它实际上可以帮助您进行分析思考,听起来像陈词滥调。 您首先必须学习将某人关于客户的自然语言问题转换为适当的度量标准(其中,这些度量标准通常具有不同的过滤条件和假设,具体取决于预期的用例!),然后还学习如何在其中实际执行该度量标准。使用SQL代码在数学和技术上正确的方法。 有时,您甚至必须确保使用正确的表/数据,因为表已被弃用,由于管线中的错误,或者不是6个月前才开始跟踪X指标,所以并非所有数据都将其放入表中。在进行此类工作时,您需要牢记许多实际的考虑因素。 进行坚如磐石的数据分析与IMO机器学习一样具有挑战性,尽管有时是出于不同的原因。

A: Did you always know that working in data science was what you wanted to do? What inspired you to pursue a career in natural language processing? And, could you tell us a bit about your work on the Primer.Ai applied research team looks like?C: Not at all! I don’t think many of us who work in data science today could have anticipated the rise of this field. I didn’t even really know about the widespread use of applied statistics in the private sector until my senior year of undergrad.
答:您一直都知道从事数据科学工作是您想要做的吗? 是什么激发了您从事自然语言处理的职业? 而且,您能否介绍一下您在 Primer.Ai 应用研究团队的 工作情况 ? C:一点也不! 我认为今天在数据科学领域工作的许多人都没有预料到这一领域的兴起。 直到我大四的时候,我才真正知道私有领域应用统计的广泛使用。
When I graduated with my B.A. and started my first job in marketing, I figured out that that wasn’t the right fit for me relatively quickly. I started researching my alternatives to see if there might be a career I could transition into that would be better-suited to my personality and values (and frankly, better-paying, as the entry-level marketing salary was only enough to live paycheck-to-paycheck in the Bay Area).
当我获得文学学士学位并开始从事市场营销的第一份工作时,我发现相对不合适我是不合适的。 我开始研究自己的替代方案,以查看是否有可以转变为职业的职业更适合我的个性和价值观(坦率地说,薪水更高,因为入门级营销人员的薪水仅足以应付薪水,在海湾地区进行支付)。
After a few months of digging, I landed on data science. It was intellectually challenging work, poised to make an enormous impact both economically and in society at large. Not only that, but I noticed that people in data science careers often cared more deeply about ethics than I had seen elsewhere. To see that people in the field genuinely cared about how their work would impact people really spoke to me, and is what ultimately helped me decide on making the transition.
经过几个月的挖掘,我学习了数据科学。 这是一项具有智力挑战性的工作,有望对经济和整个社会产生巨大影响。 不仅如此,而且我注意到,数据科学职业中的人们通常比我在其他地方看到的更加关注道德。 看到这个领域的人们真正关心他们的工作会对人们产生怎样的影响,这真的对我说话,这最终帮助我决定进行过渡。
That said, I was still unsure, because I had had negative experiences with math and computer science in undergrad, and I wasn’t sure that I could hack it (haha). In my first quarter at Stanford, I got the worst grades I had ever received in my life in a calculus course and a CS course, which caused me to seriously question whether I was cut out for those kinds of subjects. When I started this journey, I had to convince myself that I could succeed by using objective measurements instead of my own feelings: “well I scored X on the SAT, and the average score for CS majors on the SAT was Y (where X > Y), so I should be able to learn the math and other material just as well as other folks in this field…”
就是说,我仍然不确定,因为我曾经在本科生中拥有过数学和计算机科学方面的负面经验,而且我不确定是否可以破解它(哈哈)。 在斯坦福大学的第一学期,我在微积分课程和CS课程中获得了我一生中最差的成绩,这使我严重质疑我是否适合这些学科。 当我开始这一旅程时,我不得不说服自己,使用客观的测量方法代替我自己的感觉可以成功:“好吧,我在SAT上得分为X,而在SAT上CS专业的平均得分为Y(其中X>是的,所以我应该能够像该领域的其他人一样学习数学和其他材料……”
“I love NLP because I can contribute directly to helping people cut through the noise and get down to what they need to know in order to live their lives and do their work more effectively.”
“我喜欢NLP,因为我可以直接帮助人们减少噪音,并深入了解他们需要知道的东西,以便生活和更有效地工作。”
I later made the connection during my M.S. in stats that the primary reasons for my underperformance as an undergrad were a lack of good study habits and a lack of interest in math as a subject. In high school I could get away with waiting until the night before to study for the test, and never reading the textbook outside of class, but that was no longer the case at Stanford. I improved my study habits over time, and by the time I took 2 statistics courses in senior year, I was able to ace them both. Similarly, once I started learning about some of the fascinating and unexpected ways that math and stats are being applied to the real world via data science, my mind really awoke to the benefits of math, and suddenly the motivation to master it was there. I got straight A’s in my M.S. coursework for all 3 semesters that I was enrolled.
后来,我在MS期间的统计数据中得出了这样的联系:造成我本科成绩不佳的主要原因是缺乏良好的学习习惯和对数学作为学科的兴趣。 在高中时,我可以等到晚上学习考试,再也不用在课外阅读教科书了,但斯坦福大学不再是这种情况了。 随着时间的流逝,我的学习习惯得到了改善,当我在大四时选修了2门统计学课程时,我就可以将两者都放在首位。 同样,一旦我开始学习通过数据科学将数学和统计信息应用于现实世界的一些有趣且出乎意料的方式,我的脑子就真正意识到了数学的好处,突然间就有了掌握它的动力。 在我注册的所有三个学期中,我的MS课程都获得了A。
It is still a little crazy to think that just a few years ago I truly disliked both math and programming, yet here I am now, using them both every day and genuinely enjoying it. I really want to emphasize how important it is not to put yourself into a “math person”/”not a math person” box, and the same goes for programming. Both skillsets are simply tools, and these tools have incredible power to make you more effective at any other area or interest you care about making a difference in, whether that’s art, law, a social science, or a more traditional synergy like engineering. If you can push through those early feelings of resistance and intimidation, there are wonderful feelings of competence and accomplishment waiting for you once you’re able to start using these tools for the things you care about.
想到几年前我真的不喜欢数学和编程,仍然有些疯狂,但是现在我在这里,每天都在使用它们并真正享受它。 我真的想强调不要让自己陷入“数学人” /“不是数学人”的框有多么重要,编程也是如此。 这两个技能集都是简单的工具,这些工具具有令人难以置信的功能,可以使您在任何其他领域或在您关心的领域产生兴趣的领域变得更有效,无论是艺术,法律,社会科学还是更传统的协同作用(例如工程学)。 如果您能够克服那些早期的抵制和恐吓感觉,那么一旦您能够开始使用这些工具来处理自己关心的事情,就会有美好的能力和成就感等待着您。
As for why I chose natural language processing (NLP) in particular, there are a few reasons. On a career level, I saw the NLP community as more welcoming to people from unconventional backgrounds, relative to an area like computer vision where I was really only seeing people from CS, math, physics, and electrical engineering backgrounds. On a more personal and interests-based level, I see NLP as the field best suited to helping solve the problem of information overload. There is an endless amount of information to consume, which is contributing to a heightened level of stress for everyone, as well as impairing the productivity of people in knowledge work careers. I love NLP because I can contribute directly to helping people cut through the noise and get down to what they need to know in order to live their lives, make informed decisions, and do their work more effectively.
至于为什么我特别选择自然语言处理(NLP),有几个原因。 在职业层面上,我看到NLP社区更欢迎来自非常规背景的人们,而相对于计算机视觉等领域,我实际上只看到来自CS,数学,物理学和电气工程背景的人们。 从个人和基于兴趣的角度来看,我认为NLP是最适合解决信息超载问题的领域。 信息的消耗量无穷无尽,这加剧了每个人的压力,并削弱了知识型职业中人们的生产力。 我喜欢NLP,因为我可以直接帮助人们降低噪音,掌握他们的知识,以便生活,做出明智的决定并更有效地开展工作。
My work at Primer is directly relevant to the problem of information overload. At Primer, we’re leveraging powerful, cutting-edge NLP models to extract structured information from noisy, unstructured text data. This helps our customers get at the information they need much faster than having individual humans poring over the data themselves. Some analysts are working 12 hour days simply because they have no way of quickly reading and digesting the deluge of information they’re responsible for staying up-to-date with, and we want to change that.
我在Primer的工作与信息超载问题直接相关。 在Primer,我们利用功能强大的尖端NLP模型从嘈杂的非结构化文本数据中提取结构化信息。 这使我们的客户获得所需信息的速度比让个人亲自检查数据快得多。 一些分析师每天工作12小时,只是因为他们无法快速阅读和消化他们负责保持最新状态的大量信息,我们希望对此进行更改。
My team, Applied Research, is tasked with training, testing, and making deep learning models available for Primer’s products, then integrating those models into our data pipeline or exposing them for use via an API. We also create reusable scripts and resources that allow people to train their own models on their own data. The work involves not just model experiments and engineering, but also plenty of collaboration with other teams that work more directly on our products and infrastructure.
我的团队Applied Research负责培训,测试和为Primer产品提供深度学习模型,然后将这些模型集成到我们的数据管道中,或通过API公开以供使用。 我们还创建可重用的脚本和资源,使人们可以根据自己的数据训练自己的模型。 这项工作不仅涉及模型实验和工程设计,还涉及与其他团队的大量协作,这些团队可以更直接地在我们的产品和基础架构上工作。
In terms of the week-to-week, I’d say half the time goes to writing code for model training/evaluation, data preprocessing, and other typical machine learning tasks, and the other half goes toward communicating about the work: discussing plans, specifications, and progress with product managers, working with our data labeling team to create datasets for new and existing tasks, as well as presenting to the company at large about new developments and improvements of our models.
就每周而言,我会说一半时间用于编写用于模型训练/评估,数据预处理和其他典型机器学习任务的代码,而另一半则用于交流工作:讨论计划,规格和产品经理的进度,与我们的数据标签团队合作为新任务和现有任务创建数据集,并向公司全面介绍我们模型的新发展和改进。
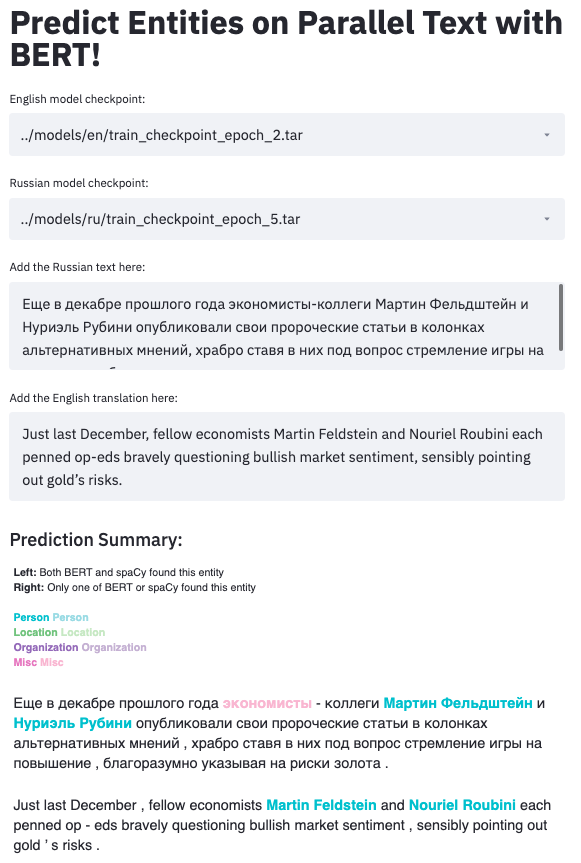
A: During your fellowship at SharpestMinds, you developed a toolkit for training “BERT-based named entity recognition models” for an error analysis frontend in Russian to English machine translation. Could you describe your project more detail and share what your three most important takeaways are? C: The TL;DR of the project is that my mentor needed a way to train BERT models to do named-entity recognition in Russian and English, and my task was to learn how to do NER with BERT in PyTorch, then build out the entire pipeline in the form of a git repo that could be cloned and run locally.
答:在SharpestMinds进修期间,您开发了一个工具包,用于培训“基于BERT的命名实体识别模型”,用于俄语到英语机器翻译的错误分析前端。 您能否更详细地描述您的项目,并分享三个最重要的要点? C:该项目的TL; DR是我的导师需要一种训练BERT模型以俄语和英语进行命名实体识别的方法,而我的任务是学习如何在PyTorch中使用BERT进行NER,然后建立可以复制并在本地运行的git repo形式的整个管道。
The resulting trained models could then be used to highlight entities, such as people, places, and organizations, in a user interface, where translators would identify whether a separate model (a Russian-to-English translation model) had made mistakes when translating names from Russian to English. I thought this — using the models to create more powerful, human-friendly software — was super cool, and this project really served to develop my intrigue for building ML-powered tools and interfaces.
然后,可以将生成的经过训练的模型用于在用户界面中突出显示诸如人,地点和组织之类的实体,翻译人员可以在其中识别出一个单独的模型(俄语到英语翻译模型)在翻译名字时是否犯了错误从俄语到英语。 我认为使用模型创建功能更强大,更人性化的软件非常棒,这个项目确实有助于培养我开发ML驱动的工具和界面的兴趣。
At the time that I did this, there was exactly one blog post about using BERT to do NER, and the code didn’t work out-of-the-box for me, so needless to say: there was a lot to figure out along the way! (Regardless, props to the author, Tobias Sterbak, for a very useful post; without it, it would have taken me a lot longer to get started.)
在我这样做时, 恰好有一篇关于使用BERT进行NER的博客文章 ,并且代码对我来说不是开箱即用的,所以不用多说:有很多事情要做一路上! (无论如何,对于作者Tobias Sterbak的一篇非常有用的文章的支持;没有它,花了我很长的时间才能上手。)
For anyone who would like more details, I wrote a 2-part series for In-Q-Tel Labs’ blog about the project as I was wrapping it up. Here are Part 1 and Part 2 of the series, and the repo can be found here.
对于想要了解更多详细信息的人,我在包裹之前为In-Q-Tel Labs博客撰写了有关该项目的两部分系列文章。 这是该系列的第1部分和第2部分 ,可以在此处找到回购。
C: What advice would you have for other women who are looking to enter the field?C: If you’re still in school (especially undergrad), you have 3 good options: study computer science and get a broad CS education, study a quantitative subject like applied statistics, economics, or engineering and combine with CS coursework, or study a qualitative subject while teaching yourself how to apply DS/ML to your field. Get research experience, especially if you want to pursue a MS or Ph.D., and if you think you prefer industry, get industry experience (have an internship every summer, maybe even work part-time during the school year). Whichever path you take, be aware that some conceptual understanding of the math behind DS/ML (statistical estimation and probability, linear algebra, and calculus) and good programming skills are still required to be successful in most roles.
C:您对其他想进入该领域的女性有什么建议? C:如果您还在上学(尤其是本科生),则有3个不错的选择:学习计算机科学并获得广泛的CS教育,学习诸如应用统计,经济学或工程学的定量学科,并结合CS课程工作或学习教您如何将DS / ML应用于您的领域的定性主题。 获得研究经验,特别是如果您想攻读MS或博士学位,并且如果您认为自己更喜欢行业,请获得行业经验(每年夏天都有实习机会,甚至在学年期间可以兼职工作)。 无论采用哪种方法,请注意,对于大多数角色而言,仍然需要对DS / ML背后的数学(统计估计和概率,线性代数和微积分)和良好的编程技巧有一定的概念性理解。
If you are a career-changer already out of school, study the career paths of people who are already in the industry. Try to pay the most attention to people whose backgrounds are similar to yours: for example, if you’re coming from a “non-technical” field that doesn’t involve much math or programming, take note of how other people transitioned in from non-technical fields. Figure out what they needed to do in order to prove that they had sufficient technical skills. Reach out to those people, see if you can get 30 minutes of their time for a phone call, and ask them specific, focused questions on what you would need to do to become hirable for the kinds of roles you’re interested in.
如果您已经是辍学的职业改变者,请研究该行业人士的职业发展道路。 尽量关注与您的背景相似的人:例如,如果您来自一个涉及数学或编程工作不多的“非技术”领域,请注意其他人如何从非技术领域。 弄清楚他们需要做些什么,以证明他们具有足够的技术技能。 与这些人联系,看看您是否可以在30分钟的时间内打通电话,并向他们询问一些具体的,有针对性的问题,以了解要想聘用感兴趣的职位需要做什么。
Career changers should also strongly consider going through a mentorship program such as SharpestMinds, if you’re transitioning from an unrelated background and need help designing and scoping an impressive, professional-quality data science project and preparing for interviews. If you are coming from a lower-paid field as I was, the income-share agreement is a lifesaver since you don’t have to pay anything until you actually get hired in a data science role.
如果您正从不相关的背景过渡并且需要帮助设计和确定令人印象深刻的专业质量的数据科学项目并准备面试,则职业更换者还应强烈考虑通过诸如SharpestMinds之类的指导计划。 如果您像我一样来自低薪领域,那么收入分成协议将是一项救命稻草,因为您无需支付任何费用,直到您真正被聘用为数据科学职位为止。
Also, Vicki Boykis’ article Data Science Is Different Now (written last year) is required reading for any aspiring data scientist. I don’t agree that everyone who takes a Coursera course or even a bootcamp is necessarily qualified for entry-level data science, but it absolutely is the case that competition for these roles is fierce, and you will need to do something to differentiate yourself from the many aspirants. As Vicki suggests, taking an adjacent role in general software engineering or data analysis first can be extremely useful for building skills and getting your foot in the door.
此外,任何有抱负的数据科学家都必须阅读Vicki Boykis的文章“ Data Science Is Now Now” (去年撰写)。 我不同意参加Coursera课程甚至是训练营的每个人都必须具备入门级数据科学的资格,但是对于这些角色的竞争绝对是一种极端情况,您将需要做一些事情来使自己与众不同来自许多有抱负的人。 正如Vicki所建议的那样,首先在通用软件工程或数据分析中扮演相邻角色对于提高技能和踏进大门非常有用。
A: How can our readers connect with you and get involved with your projects?C: You can follow me on Twitter, connect with me on LinkedIn, or just send me an email. I’m pretty heads-down on my work at Primer right now, but if I start any side projects in the future, I’ll be sure to share!
答:我们的读者如何与您联系并参与您的项目? C:您可以在Twitter上关注我,在LinkedIn上与我联系,或者给我发送电子邮件。 我现在在Primer上的工作非常头脑清醒,但是如果将来我开始任何附带项目,我一定会分享的!
In addition to innovating in the NLP space as a machine learning engineer, Charlene has also been an active member in the SharpestMinds community. Her career path and multi-disciplinary experience focused on social science and technology continues to empower women technologists to innovate in data science. Today, Charlene is solving the toughest problems in NLG and NLU, thus giving people the power to cut through the noise and understand the world at scale. As well as being a role model for data scientists who have non-traditional career paths, Charlene inspires women from diverse backgrounds to democratize the field of NLP.
除了作为机器学习工程师在NLP领域进行创新之外,Charlene还是SharpestMinds社区的活跃成员。 她的职业道路和专注于社会科学和技术的多学科经验继续使女性技术专家有能力在数据科学方面进行创新。 如今,Charlene正在解决NLG和NLU中最棘手的问题,从而使人们有能力消除噪音并大规模地了解世界。 作为具有非传统职业道路的数据科学家的榜样,Charlene激发了来自不同背景的女性,使NLP领域民主化。
Special thanks to Charlene Chambliss for allowing me to interview her for this series, and a huge shout out to the TDS Editorial Team for supporting this project.
特别感谢Charlene Chambliss允许我采访本系列的她,并向TDS编辑团队大呼支持该项目。
Do you know an inspiring woman in tech who you would like featured in this series? Are you working on any cool data science and tech projects that you’d like me to write about? Feel free to email me at angelamarieteng@gmail.com for comments and suggestions. Thanks for reading!
您是否知道本系列中有一位鼓舞人心的高科技女性? 您是否正在从事任何我想写的很酷的数据科学和技术项目? 请随时通过angelamarieteng@gmail.com给我发送电子邮件,以提出评论和建议。 谢谢阅读!
[1] Additional information obtained from LinkedIn, available upon request from the author.
[1]从LinkedIn获得的其他信息,可应作者要求提供。
陆涛喜欢夏琳吗














 1753
1753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









