





面向对象编程 python
It is known that the strength of Python is its flexibility. For example, Python is one of the easiest programming languages for Object-Oriented Programming. However, it is also sometimes criticised because it is “too flexible”.
众所周知,Python的优势在于它的灵活性。 例如,Python是面向对象编程的最简单的编程语言之一。 但是,有时也会因为它“太灵活”而受到批评。
In this article, I’m going to introduce the most elegant way that I believe to program object-orient using Python.
在本文中,我将介绍我认为使用Python编程面向对象的最优雅的方法。
The key to the way is a library called marshmallow.
方式的关键是一个名为marshmallow的库。
You can easily install the library by pip install marshmallow.
您可以通过pip install marshmallow轻松安装该库。

类的定义 (Definition of Class)
Let’s start it by declaring a User class and keep it simple for demonstrating purposes.
让我们从声明User类开始,并使其简单以进行演示。
class User(object):
def __init__(self, name, age):
self.name = name
self.age = agedef __repr__(self):
return f'I am {self.name} and my age is {self.age}'OK. Our User class only has two attributes: name and age. Please be noticed that I have also implemented the __repr__ method, so that we can easily output the instance to verify it.
好。 我们的User类只有两个属性: name和age 。 请注意,我还实现了__repr__方法,以便我们可以轻松地输出实例进行验证。
Then, we need to import some modules and methods from the librarymarshmallow.
然后,我们需要从库marshmallow导入一些模块和方法。
from marshmallow import Schema, fields, post_load
from pprint import pprintHere I imported pprint because we’re going to print many dictionaries and lists. Just want to make it better looking.
在这里,我导入了pprint因为我们将要打印许多字典和列表。 只想使其外观更好。
Now, how we should use marshmallow? Simply define a “Schema” for our User class.
现在,我们应该如何使用marshmallow ? 只需为我们的User类定义一个“架构”。
class UserSchema(Schema):
name = fields.String()
age = fields.Integer()@post_load
def make(self, data, **kwargs):
return User(**data)It is quite straightforward. For each attribute, we need to declare it is fields and then followed by the type.
这很简单。 对于每个属性,我们需要声明它是fields ,然后声明类型。
The annotation @post_load is optional, which is needed if we want to load the schema as an instance of any classes. Therefore, we need it in our case because we want to generate User instances. The make method will simply make use of all the arguments to instantiate the instance.
注释@post_load是可选的,如果我们要将模式作为任何类的实例加载,则需要使用该注释。 因此,由于我们要生成User实例,因此我们需要它。 make方法将简单地利用所有参数实例化实例。
JSON到实例 (JSON to Instance)
If we have a dictionary (JSON object) and we want an instance, here is the code.
如果我们有一个字典(JSON对象)并且想要一个实例,那么这里是代码。
data = {
'name': 'Chris',
'age': 32
}schema = UserSchema()
user = schema.load(data)
How easy it is! Just call the load() method of the schema and we deserialised the JSON object to the class instance.
多么简单! 只需调用架构的load()方法,我们就将JSON对象反序列化为类实例。
JSON数组到多个实例 (JSON Array to Multiple Instances)
What if we have a JSON array containing multiple objects to be deserialised? We don’t need to write a for-loop, simply specify many=True as follows.
如果我们有一个包含要反序列化的多个对象的JSON数组怎么办? 我们不需要编写for循环,只需按如下所示指定many=True 。
data = [{
'name': 'Alice',
'age': 20
}, {
'name': 'Bob',
'age': 25
}, {
'name': 'Chris',
'age': 32
}]schema = UserSchema()
users = schema.load(data, many=True)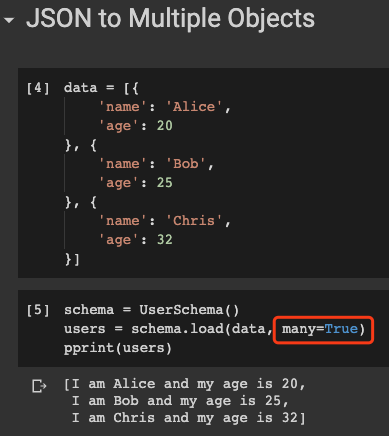
将实例序列化为JSON对象(字典) (Serialising Instances to JSON Object (Dictionary))
OK. We’ve known that we can use the load() method to convert a dictionary to instances. How about the other way around? We can use dump() method as follows.
好。 我们知道可以使用load()方法将字典转换为实例。 反过来呢? 我们可以如下使用dump()方法。
dict = schema.dump(users, many=True)
In this example, I simply used the users which is a list of user instances generated from the previous example. It can be seen that the list of user instances are converted into a JSON array in a single line of code!
在此示例中,我仅使用了users ,这是从上一个示例生成的用户实例的列表。 可以看出,用户实例列表在一行代码中被转换为JSON数组!
现场验证 (Field Validation)
Do you think marshmallow can only serialise/deserialise instances? If so, I probably won’t share this as a story here. The most powerful feature of this library is validation.
您认为marshmallow只能序列化/反序列化实例吗? 如果是这样,我可能不会在这里作为故事分享。 该库最强大的功能是验证。
Let’s start from a simple example here. To begin with, we need to import the ValidationError which is an exception from the library.
让我们从一个简单的例子开始。 首先,我们需要导入ValidationError ,这是库中的异常。
from marshmallow import ValidationErrorRemember we declared our UserSchema above with the field age as Integer? What if we pass an invalid value in?
还记得我们在上面将UserSchema age为Integer UserSchema吗? 如果传入无效值怎么办?
data = [{
'name': 'Alice',
'age': 20
}, {
'name': 'Bob',
'age': 25
}, {
'name': 'Chris',
'age': 'thirty two'
}]Please note that in the above JSON array, the third object “Chris” has an invalid age format, which cannot be converted into an integer. Let’s now use load() method to deserialise the array.
请注意,在上述JSON数组中,第三个对象“ Chris”的年龄格式无效,无法将其转换为整数。 现在让我们使用load()方法反序列化数组。
try:
schema = UserSchema()
users = schema.load(data, many=True)
except ValidationError as e:
print(f'Error Msg: {e.messages}')
print(f'Valid Data: {e.valid_data}')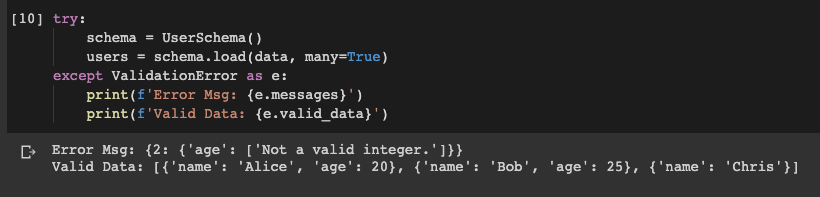
The exception is caught and it tells us “Not a valid integer”. Imagine that we are developing a web application, it is even not necessary to be bothered by writing the error messages!
捕获到异常,它告诉我们“不是有效整数”。 想象一下我们正在开发一个Web应用程序,甚至不必通过编写错误消息来打扰!
Also, in this example, only the third object has a validation issue. The error message actually told us that it happened at the index 2. Also, the objects that are valid can still be output.
同样,在此示例中,只有第三个对象存在验证问题。 错误消息实际上告诉我们它发生在索引2 。 同样,仍然可以输出有效的对象。
高级验证 (Advanced Validation)
Of course, it is not enough to validate only against the data types. The library supports much more validation methods.
当然,仅对数据类型进行验证是不够的。 该库支持更多的验证方法。
Let’s add one more attribute gender to the User class.
让我们向User类添加另一种属性gender 。
class User(object):
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = genderdef __repr__(self):
return f'I am {self.name}, my age is {self.age} and my gender is {self.gender}'Then, let’s define the schema with validations. We also need to import the validate feature from the library.
然后,让我们定义带有验证的架构。 我们还需要从库中导入validate功能。
from marshmallow import validateclass UserSchema(Schema):
name = fields.String(validate=validate.Length(min=1))
age = fields.Integer(validate=validate.Range(min=18, max=None))
gender = fields.String(validate=validate.OneOf(['F', 'M', 'Other']))Here, we added validations to all these three fields.
在这里,我们向所有这三个字段添加了验证。
For the field
name, the length has to be at least 1. In other words, it can’t be empty.对于字段
name,长度必须至少为1。换句话说,它不能为空。For the field
age, it has to be greater than or equal to 18.对于田间
age,它必须大于或等于18。For the field
gender, it has to be one of the three values.对于字段“
gender,它必须是三个值之一。
Let’s define a JSON object with all invalid values as follows.
让我们定义一个具有所有无效值的JSON对象,如下所示。
data = {
'name': '',
'age': 16,
'gender': 'X'
}Then, let’s try to load it.
然后,让我们尝试加载它。
try:
UserSchema().load(data)
except ValidationError as e:
pprint(e.messages)
It is not surprising that the exceptions are caught, but when I first time tried this, I was really surprised that the error messages are out-of-box. It saves a lot of time for us to write the validating error messages.
捕获异常并不奇怪,但是当我第一次尝试这样做时,我真的很惊讶错误消息是开箱即用的。 这为我们节省了很多时间来编写验证错误消息。
定制验证功能 (Customised Validate Functions)
You might ask that it is still kind of limited to use the built-in validating methods such as range, length and “one of” from the above example. What if we want to customise the validating method? Of course, you can.
您可能会问,使用上例中的内置验证方法(例如范围,长度和“其中之一”)仍然受到限制。 如果我们要自定义验证方法怎么办? 当然可以。
def validate_age(age):
if age < 18:
raise ValidationError('You must be an adult to buy our products!')class UserSchema(Schema):
name = fields.String(validate=validate.Length(min=1))
age = fields.Integer(validate=validate_age)
gender = fields.String(validate=validate.OneOf(['F', 'M', 'Other']))Here we defined our validation method validate_age with customised logic as well as the message. Let’s define a JSON object to test it. In the following object, the age is less than 18.
在这里,我们使用定制的逻辑和消息定义了验证方法validate_age 。 让我们定义一个JSON对象进行测试。 在以下对象中,年龄小于18。
data = {
'name': 'Chris',
'age': 17,
'gender': 'M'
}try:
user = UserSchema().load(data)
except ValidationError as e:
pprint(e.messages)
Now, it is using your customised logic and error message.
现在,它正在使用您的自定义逻辑和错误消息。
There is another way to implement this, which I think is more elegant.
还有另一种方法可以实现这一点,我认为这更优雅。
class UserSchema(Schema):
name = fields.String()
age = fields.Integer()
gender = fields.String()@validates('age')
def validate_age(self, age):
if age < 18:
raise ValidationError('You must be an adult to buy our products!')So, in this example, we use annotation to define the validation method inside the class.
因此,在此示例中,我们使用注释在类内部定义验证方法。
必填项 (Required Fields)
You can also define some fields are required.
您还可以定义一些必填字段。
class UserSchema(Schema):
name = fields.String(required=True, error_messages={'required': 'Please enter your name.'})
age = fields.Integer(required=True, error_messages={'required': 'Age is required.'})
email = fields.Email()In this example, we defined name and age are required fields. Now, let’s test it using an object without email.
在此示例中,我们定义name和age为必填字段。 现在,让我们使用没有电子邮件的对象对其进行测试。
data_no_email = {
'name': 'Chris',
'age': 32
}try:
user = UserSchema().load(data_no_email)
except ValidationError as e:
pprint(e.messages)
OK. No problem at all. What if we have an object without name and age?
好。 没问题 如果我们有一个没有名称和年龄的物体怎么办?
data_no_name_age = {
'email': 'abc@email.com'
}try:
user = UserSchema().load(data_no_name_age)
except ValidationError as e:
print(f'Error Msg: {e.messages}')
print(f'Valid Data: {e.valid_data}')
It complains and provides the error messages we define for the required fields.
它抱怨并提供我们为必填字段定义的错误消息。
默认值 (Default Values)
Sometimes, we may want to define some fields with default values. So, the users might not need to input it and the default values will be utilised.
有时,我们可能想定义一些具有默认值的字段。 因此,用户可能不需要输入它,并且将使用默认值。
class UserSchema(Schema):
name = fields.String(missing='Unknown', default='Unknown')print(UserSchema().load({})) # Take the "missing" value
print(UserSchema().dump({})) # Take the "default" value
In marshmallow, there are two ways to define a “default” values:
在marshmallow ,有两种方法可以定义“默认”值:
missingkeyword defines the default value that will be used when deserialising an instance usingload()missing关键字定义了使用load()反序列化实例时将使用的默认值defaultkeyword defines the default value that will be used when serialising an instance usingdump()default关键字定义使用dump()序列化实例时将使用的默认值
In the above example, we used both the two keywords and experimented both load() and dump() methods with an empty object. It can be seen that both of them were added the name field with default values.
在上面的示例中,我们同时使用了两个关键字,并使用空对象对load()和dump()方法进行了实验。 可以看出,它们都被添加了具有默认值的name字段。
属性别名 (Attribute Alias)
Keep going, not finished yet :)
继续前进,尚未完成:)
Sometimes, we may have some discrepancy implementation between our classes and the actually JSON data in terms of the keys/attribute names.
有时,就键/属性名称而言,我们的类与实际的JSON数据之间可能会有一些差异。
For example, in our class, we defined name attribute. However, in the JSON object, we have username which means the same field but named differently. In this case, we don’t have to re-implement our classes nor convert the keys in the JSON object.
例如,在我们的课程中,我们定义了name属性。 但是,在JSON对象中,我们具有username ,该username表示相同的字段,但名称不同。 在这种情况下,我们不必重新实现我们的类,也不必转换JSON对象中的键。
class User(object):
def __init__(self, name, age):
self.name = name
self.age = agedef __repr__(self):
return f'I am {self.name} and my age is {self.age}'class UserSchema(Schema):
username = fields.String(attribute='name')
age = fields.Integer()@post_load
def make(self, data, **kwargs):
return User(**data)Please be noticed that we have name in the User class, whereas in UserSchema we have username, but for the field username, we defined its attribute should be called name.
请注意,我们在User类中具有name ,而在UserSchema我们具有username ,但是对于字段username ,我们定义其attribute应称为name.
Let’s try to dump a user instance.
让我们尝试转储用户实例。
user = User('Chris', 32)
UserSchema().dump(user)
It correctly serialised the instance with the field name username.
它使用字段名username正确地序列化了实例。
Vice versa:
反之亦然:
data = {
'username': 'Chris',
'age': 32
}
UserSchema().load(data)
Even though we passed the JSON object with the key username, it can still deserialise it to the User instance without any problems.
即使我们使用密钥username传递了JSON对象,它仍然可以将其反序列化为User实例,而不会出现任何问题。
嵌套属性 (Nested Attributes)
Last but not least, marshmallow supports nested attributes without any problems.
最后但并非最不重要的一点, marshmallow支持嵌套属性,没有任何问题。
class Address(object):
def __init__(self, street, suburb, postcode):
self.street = street
self.suburb = suburb
self.postcode = postcodedef __repr__(self):
return f'{self.street}, {self.suburb} {self.postcode}'class User(object):
def __init__(self, name, address):
self.name = name
self.address = address
def __repr__(self):
return f'My name is {self.name} and I live at {self.address}'We defined two classes Address and User. The classUser has an attribute address, which is of type Address. Let’s test the classes by instantiating a user object.
我们定义了两个类Address和User 。 User类具有一个属性address ,该Address的类型为Address 。 让我们通过实例化用户对象来测试类。
address = Address('1, This St', 'That Suburb', '1234')
user = User('Chris', address)
print(user)
Now, we are going to define the schema as follows.
现在,我们将如下定义架构。
class AddressSchema(Schema):
street = fields.String()
suburb = fields.String()
postcode = fields.String()@post_load
def make(self, data, **kwargs):
return Address(**data)class UserSchema(Schema):
name = fields.String()
address = fields.Nested(AddressSchema())@post_load
def make(self, data, **kwargs):
return User(**data)The trick here is to use fields.Nested() to define a field using another schema. We have already got a user instance above. Let’s dump it to a JSON object.
这里的技巧是使用fields.Nested()来使用另一个模式定义一个字段。 我们上面已经有一个用户实例。 让我们将其转储到JSON对象。
pprint(UserSchema().dump(user))
As shown, the user instance has been serialised into a nested JSON object!
如图所示,用户实例已被序列化为嵌套的JSON对象!
Of course, the other way around will work, too.
当然,另一种方法也可以。
data = {
'name': 'Chris',
'address': {
'postcode': '1234',
'street': '1, This St',
'suburb': 'That Suburb'
}
}
pprint(UserSchema().load(data))
摘要 (Summary)

In this article, I have introduced how to use the library marshmallow to extremely simplify Object-Oriented Programming in Python in practice. It is the most elegant way that I believe to make use of OO <-> JSON in Python.
在本文中,我介绍了如何使用marshmallow库在实践中极大地简化Python中的面向对象编程。 我相信这是在Python中使用OO <-> JSON的最优雅的方式。
All the code is available in my Google Colab:
我的Google Colab中提供了所有代码:
Life is short, use Python!
寿命短,请使用Python!
翻译自: https://towardsdatascience.com/the-most-elegant-python-object-oriented-programming-b38d75f4ae7b
面向对象编程 python















 2697
2697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









