





 本文介绍了一个结合数据科学和应用程序开发的项目,详细描述了如何使用Keras实现卷积神经网络(CNN),并将其部署到iOS设备上,以识别图片中的犬种。
本文介绍了一个结合数据科学和应用程序开发的项目,详细描述了如何使用Keras实现卷积神经网络(CNN),并将其部署到iOS设备上,以识别图片中的犬种。
cnn keras 实现
I first thought about image classification in an app through watching the TV show Silicon Valley. For any non-Silicon Valley enthusiasts, the show is a comedy with the characters in a tech incubator. One member of the incubator unveils an app in which the only functionality tells you if the picture you are seeing is a ‘hotdog’ or ‘not hotdog.’¹ It was likely that a convolutional neural network (CNN) would be best suited to accomplish this task and while I had taken courses on them in the past, I was interested in how a machine learning algorithm could be implemented and deployed on a mobile device.
我首先通过看电视节目《 硅谷》来考虑应用程序中的图像分类。 对于任何非硅谷发烧友来说,该节目都是一部喜剧,里面有技术孵化器中的角色。 保育箱的一位成员推出了一款应用,其中唯一的功能会告诉您所看到的图片是“热狗”还是“非热狗”。¹ 卷积神经网络(CNN)可能最适合完成此任务,尽管我过去曾就其进行过课程,但是我对如何在移动设备上实现和部署机器学习算法感兴趣。
My first action was to decide on a topic matter for an image classification app, and I decided upon dogs. Who doesn’t love taking a picture of their dog anyways? In order to do so though I would need a relatively large and wide dataset necessary to train CNN’s. Luckily, Stanford has an open source database that has a 120 different dog breeds with at least 150 images per breed.²
我的第一个动作是为图像分类应用程序确定主题,然后决定了狗。 谁不喜欢为他们的狗拍照? 为了这样做,尽管我需要训练CNN所需的相对较大和较宽的数据集。 幸运的是,斯坦福大学拥有一个开放源数据库,其中包含120个不同的犬种,每个犬种至少有150张图片。²

My next thought was that while an app that classifies dogs would be fun, it might be relatively mundane. So, what if instead the model took a human photo as input and output what dog breed the person most closely resembled? The classifier would only be trained on dogs but given any image, including one of a human, it would provide a probabilistic outcome of the various breeds, so it would output the most likely breed as a prediction.
我的下一个想法是,虽然将狗分类的应用很有趣,但可能相对平凡。 那么,如果该模型将人类照片作为输入并输出与该人最相似的是哪种狗呢? 分类器将仅在狗上训练,但是给定任何图像(包括一个人),它将提供各种品种的概率结果,因此它将输出最可能的品种作为预测。
Apple iOS uses a tool called Core ML in order to perform all of their machine learning tasks such as image recognition. At first I thought it was likely I was going to have to build and train a model in Swift, which was a language I was relatively unfamiliar with. However, after a few Google searches I found that Apple provides a Core ML converter that can take a Keras model and transforms it into a Core ML model that can be deployed in an iOS app.³
Apple iOS使用一个名为Core ML的工具来执行其所有机器学习任务,例如图像识别。 起初我以为我可能必须在Swift中建立和训练一个模型,这是我相对不熟悉的一种语言。 但是,经过几次Google搜索后,我发现Apple提供了一个Core ML转换器,该转换器可以采用Keras模型并将其转换为可以在iOS应用中部署的Core ML模型。³
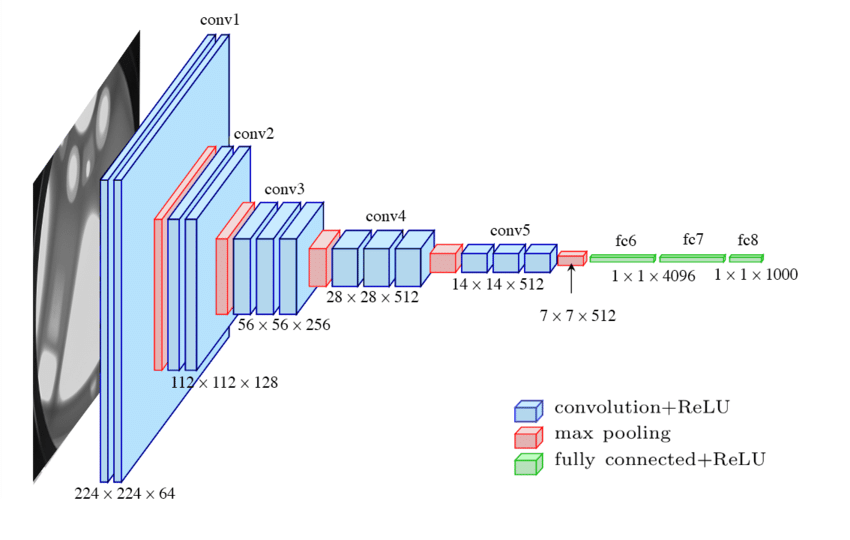
Next I had to build the CNN and train it on the roughly 20,000 images. In order to get sufficient depth in the model without an extremely large amount of training iterations, transfer learning was likely the best path to take. I decided to use the popular VGG16 network that has won the ImageNet competition in the past. An overview of the network is seen below.
接下来,我必须构建CNN并在大约20,000张图像上对其进行训练。 为了在模型中获得足够的深度而无需进行大量的训练迭代,转移学习可能是最好的选择。 我决定使用在过去赢得ImageNet竞赛的流行VGG16网络。 下面是网络的概述。
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D, Activation, Reshape
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.vgg16 import VGG16I set the layers to be untrainable in order to keep the original VGG weights and added 2 fully connected layers on the end while utilizing dropout in order to control for overfitting. I also ‘popped’ the last layer of the VGG and added two more fully connected layers in order to make it conform to the proper number of outputs.
为了保持原始VGG权重,我将图层设置为不可训练,并在最后使用压差为控制过度拟合而在末端添加了2个完全连接的图层。 我还“弹出”了VGG的最后一层,并添加了另外两个完全连接的层,以使其符合适当数量的输出。
model = Sequential()
model.add(VGG16(include_top = False, input_shape = (270,201,3)))
model.layers.pop()
model.layers.pop()for layer in model.layers:
layer.trainable = False
model.add(Flatten())
model.add(Dense(3000, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(118, activation = 'softmax'))
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])Before commencing training however, I needed to preprocess the images. Using Keras’ ImageDataGenerator was quite helpful as it shaped images to a given input size as well as allowing for a training and validation split.
但是,在开始培训之前,我需要对图像进行预处理。 使用Keras的ImageDataGenerator很有帮助,因为它可以将图像成形为给定的输入大小,并且可以进行训练和验证拆分。
data = ImageDataGenerator(rescale=1./255, horizontal_flip=True, validation_split=.2)train_gen = data.flow_from_directory('/Users/Derek/Desktop/ImageTrain', subset = 'training', class_mode = 'categorical', target_size = (270,201))#201 for ease in coremltest_gen = data.flow_from_directory('/Users/Derek/Desktop/ImageTrain', subset = 'validation', class_mode = 'categorical', target_size = (270,201))I trained the model until the validation error started to increase and saved it in a Keras checkpoint .h5 format. Then I converted my model into the .mlmodel format that could be used on iOS devices.
我对模型进行了训练,直到验证错误开始增加并将其保存为Keras检查点.h5格式。 然后,我将模型转换为可以在iOS设备上使用的.mlmodel格式。
import coremltools
model.save('your_model.h5')
coreml_model = coremltools.converters.keras.convert('your_model.h5', image_scale = 1./255., class_labels=class_list, input_names='Image', image_input_names = "Image")
spec = coreml_model.get_spec()
coremltools.utils.convert_double_to_float_multiarray_type(spec)
coreml_model = coremltools.models.MLModel(spec)coreml_model.save('my_model.mlmodel')Before I started app development I had to learn some basics of Swift and to be quite honest I had to learn about app development as well! I found a great YouTube tutorial called Coding with Chris that went through all of the basics of Swift and app development in Xcode.⁴ With the tutorial under my belt, I was able to put together a single view app that accepted as input either an image from the users camera roll or taken through the app and output the most likely classification of a dog breed, along with the dogs picture. While most aspects of the process were quite easy as Apple utilizes a lot of drag and drop features in Xcode, I had to manually preprocess the user image size in order to make sure it fit the input dimensions in the CNN.
在开始应用程序开发之前,我必须学习一些Swift的基础知识,老实说,我还必须学习应用程序开发! 我找到了一个很棒的YouTube教程,叫做Chris,它介绍了Xcode中所有Swift和应用程序开发的基础知识。⁴有了这个教程,我可以将一个单视图应用程序组合在一起,该应用程序既可以接受输入也可以输入图像从用户的相机胶卷或通过应用程序拍摄,并输出最可能的犬种分类以及犬的照片。 尽管该过程的大多数方面都非常容易,因为Apple在Xcode中利用了很多拖放功能,但是我必须手动预处理用户图像大小,以确保它适合CNN中的输入尺寸。
func full_preprocess(uiim: UIImageView, cgim: CGImage) -> CVPixelBuffer {var im = self.imageWithImage(image: uiim.image!, scaledToSize:CGSize(width: 67, height: 90))//This has to be half of the model input size because of the bufferlet ratio:Double = 270.0/Double(im.cgImage!.height)if ratio != 1 {im = self.imageWithImage(image: uiim.image!, scaledToSize:CGSize(width: 67.0 * ratio, height: 90 * ratio))}let new_im:CVPixelBuffer = self.pixelBufferFromCGImage(image: im.cgImage!, image2: im)return new_im}And there you have it, a project that utilizes both data science and app development, and one that can hopefully even make you laugh along the way!
有了这个项目,它既利用了数据科学又开发了应用程序开发,并且有希望甚至使您一路开怀!

Viet Ahn Le, Jian Yang: hotdog identifying app, 2017, https://www.youtube.com/watch?v=vIci3C4JkL0
Viet Ahn Le, Jian Yang:热狗识别应用程序 ,2017年, https://www.youtube.com/watch?v = vIci3C4JkL0
Stanford University, Stanford Dogs Dataset, http://vision.stanford.edu/aditya86/ImageNetDogs/
斯坦福大学, 斯坦福狗数据集 , http://vision.stanford.edu/aditya86/ImageNetDogs/
Apple, Core ML, https://developer.apple.com/documentation/coreml
Apple, Core ML, https://developer.apple.com/documentation/coreml
CodeWithChris, Code With Chris, https://www.youtube.com/channel/UC2D6eRvCeMtcF5OGHf1-trw
CodeWithChris, Chris的代码, https://www.youtube.com/channel/UC2D6eRvCeMtcF5OGHf1-trw
翻译自: https://towardsdatascience.com/using-a-keras-cnn-in-ios-9e82836b0ee3
cnn keras 实现

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









