





swift 依赖请求
介绍 (Introduction)
Implementing an architecture within an application can be challenging. There are rules we can follow (SOLID, Clean Architecture) and patterns to guide us (MVVM, MVP, MVI, Redux, …) but sometimes, things we thought were well established deserve a step back.
在应用程序中实现体系结构可能是一个挑战。 我们可以遵循一些规则(SOLID,Clean Architecture)和模式来指导我们(MVVM,MVP,MVI,Redux等),但是有时候,我们认为已经确立的东西值得退后一步。
Lately, I’ve been in this situation while developing an application that relied on the use of higher order free functions.
最近,在开发依赖于使用高阶自由函数的应用程序时,我一直处于这种情况。
In this article, I’ll try to guide you from the sparkle that lit this desire for higher order free functions to its implementation regarding dependency injection.
在本文中,我将引导您从点燃对高级自由函数的渴望的火花到有关依赖注入的实现。
依赖注入 (Dependency Injection)
Dependency injection is a technique at the crossroads of well known software engineering best practices: abstraction and decoupling, single responsibility, dependency inversion. It provides flexible and testable implementations.
依赖注入是在众所周知的软件工程最佳实践的十字路口上的一种技术:抽象和解耦,单一职责,依赖倒置。 它提供了灵活且可测试的实现。
This article assumes that the merits of dependency injection are accepted. We will see how dependency injection and higher order functions fit very well together.
本文假定接受了依赖项注入的优点。 我们将看到依赖注入和高阶函数如何很好地结合在一起。
以传统方式实施 (Implementation in a traditional way)
In the rest of this article we will focus on a UsersRepository object that fetches users from a Rest API and filters them out before returning them. For the sake of the demonstration all the endpoints of this API return users but with different flavours depending on the fetched route.
在本文的其余部分中,我们将重点介绍一个UsersRepository对象,该对象从Rest API获取用户并在返回用户之前将其过滤掉。 为了演示起见,此API的所有端点都是返回用户,但根据提取的路线,它们具有不同的风格。
To do so the UsersRepository will be injected with an ApiService protocol whose purpose is to provide a way to fetch users from the Rest endpoints:
为此,将使用ApiService协议注入UsersRepository,该协议的目的是提供一种从Rest端点获取用户的方式:

This is a pretty common implementation. Of course, in real life implementation, we would try to make the ApiService more versatile and safe by using generic types and constraints.
这是一个很常见的实现。 当然,在现实生活中,我们将尝试通过使用通用类型和约束使ApiService更加通用和安全。
As I said in the introduction, let’s give it a second thought … why an ApiService ?
正如我在简介中所说的,让我们再想一想...为什么选择ApiService?
In fact, we just want to retrieve users, the repository doesn’t care about where they come from, it is an implementation detail. A Rest API is one way among many.
实际上,我们只想检索用户,存储库不在乎用户来自何处,它是一个实现细节。 Rest API是众多方法中的一种。
A trivial approach would be to refactor the ApiService into a more versatile DataProvider protocol.
一种简单的方法是将ApiService重构为更通用的DataProvider协议。
But what about its definition?
但是它的定义呢?
- the “fetch” function doesn’t really make sense anymore “获取”功能不再有意义
- the “route” parameter becomes irrelevant outside an API context API上下文之外的“ route”参数变得无关紧要
- the “ApiError” type is too specific “ ApiError”类型过于具体
Of course, we could find a way to pick more « any purpose » names and data structures but I invite you to look for another way.
当然,我们可以找到一种选择更多“任何目的”名称和数据结构的方法,但我邀请您寻找另一种方法。
注射功能 (Injecting functions)
After all, the UsersRepository only relies on an AnyPublisher<[User], ApiError> to perform its work, right ?
毕竟,UsersRepository仅依靠AnyPublisher <[User],ApiError>来执行其工作,对吗?
The temptation is strong to directly inject this publisher as a dependency, but we should not. Injecting it directly would mean to build this publisher pretty early in the injection process and this is something that might lead to unwanted side effects: perhaps it takes time to be built or it needs other dependencies to be resolved ? The UsersRepository doesn’t know that and can make no assumption on that. The publisher should only be built if and when needed.
强烈希望直接将此发布者作为依赖项注入,但我们不应该这样做。 直接注入将意味着在注入过程中相当早地构建此发布者,这可能会导致不良的副作用:可能需要花费一些时间构建,或者需要解决其他依赖关系? UsersRepository不知道,因此无法做任何假设。 仅在需要时以及在需要时才构建发布者。
If we can’t inject the publisher, we can inject a function that builds it 👍, and execute it at our convenience.
如果我们不能注入发布者,我们可以注入一个构建它的函数,然后在我们方便的时候执行它。
Let’s give it a try then.
然后让我们尝试一下。

What have we done here:
我们在这里做了什么:
- To ease the reading, we’ve declared a typealias describing the function signature 为了便于阅读,我们声明了一个描述函数签名的类型别名。
- We’ve injected the function 我们已经注入了功能
- We’ve used the function as a replacement of the ApiService 我们已经使用该函数替代了ApiService
- The publisher signature has changed a bit, from AnyPublisher<[User], ApiError> to AnyPublisher<[User], Error>. We do not want to leak implementation details here because of the error type. 发布者签名已从AnyPublisher <[User],ApiError>更改为AnyPublisher <[User],Error>。 由于错误类型,我们不想在这里泄漏实现细节。
So far so good … but what about the Route we used to pass to the fetch function ? In fact we don’t need it anymore as it was specific to the ApiService; nevertheless, we will cover this precise point later in this article.
到目前为止一切顺利……但是,我们过去传递给fetch函数的Route呢? 实际上,我们不再需要它了,因为它特定于ApiService。 但是,我们将在本文后面介绍这一确切点。
As a bonus we can also inject the filtering function so we can change its behaviour depending on the context (the filter might differ between dev, QA or prod environment for instance).
另外,我们还可以注入过滤功能,以便我们可以根据上下文更改其行为(例如,在开发人员,QA或生产环境之间,过滤器可能有所不同)。

Once again we take advantage of typealiases to pass the functions around. This becomes almost mandatory when using functions as dependencies.
我们再次利用类型别名来传递函数。 使用函数作为依赖项时,这几乎变得必须。
While we are at it, perhaps we can push our reflexion a bit further and take a final step towards the systematic use of functions.
在此过程中,也许我们可以进一步反思,并朝着系统地使用功能迈出最后一步。
Why do we need a repository ? Usually, the repository pattern is used to group all the CRUD operations about an entity. We can assume that a UsersRepository will have several load, update, and delete functions. Once implemented, those functions will require a certain number of dependencies. We will end up with an initializer taking all the needed functions as parameters, whereas we might only need some of them depending on the feature we want to accomplish. This is not optimal.
为什么需要存储库? 通常,存储库模式用于对有关实体的所有CRUD操作进行分组。 我们可以假设UsersRepository将具有多个加载,更新和删除功能。 一旦实现,这些功能将需要一定数量的依赖关系。 我们将最终得到一个将所有需要的功能作为参数的初始化程序,而根据我们要完成的功能,我们可能只需要其中的一些即可。 这不是最佳的。
Getting rid of the repository implies that every function (load, update, delete …) is self-supporting and is being injected only with the needed dependencies.
摆脱存储库意味着每个功能(加载,更新,删除...)都是自支持的,并且仅以所需的依赖项进行注入。

Here we go, we have a 100% autonomous function. For the sake of clarity we can wrap the whole thing inside a namespace to shorten some names:
在这里,我们有100%的自治功能。 为了清楚起见,我们可以将整个内容包装在名称空间中以缩短一些名称:

对单元测试的积极影响 (The positive impact on the unit tests)
Let’s get back to the original UsersRepository implementation. In order to unit test the loadUsers function, we would have had to create a mocked ApiService to fulfill the initializer requirements. The mocked ApiService should be able to succeed or fail in order to test the output of the loadUsers function.
让我们回到原始的UsersRepository实现。 为了对loadUsers函数进行单元测试,我们必须创建一个模拟的ApiService来满足初始化程序的要求。 模拟的ApiService应该能够成功或失败,以便测试loadUsers函数的输出。
In the unfortunate case where the ApiService also needs a dependency on its own, then we would have been forced to implement another mocked dependency as well. If we apply that strategy to the whole application, we might end up with a complex hierarchy of mock objects.
在不幸的情况下,如果ApiService也需要自己依赖,那么我们也将不得不实现另一个模拟依赖。 如果我们将该策略应用于整个应用程序,则最终可能会得到复杂的模拟对象层次结构。
When using functions as dependencies, we still need mocks of course, but they are in general very small, simple and defined right next to the unit test:
当使用函数作为依赖项时,我们当然仍然需要模拟,但是它们通常非常小,简单并且在单元测试旁边已定义:


Unit tests are super easy to imagine, to write, and to read. Personally, I find this technique a very good tool to reach a high (and meaningful) code coverage. I think it can help a lot when using a TDD approach.
单元测试非常容易想象,编写和阅读。 就个人而言,我发现此技术是达到很高(且有意义的)代码覆盖率的非常好的工具。 我认为在使用TDD方法时,它会有所帮助。
函数式编程的窍门 (A trick from functional programming)
Do you remember the original implementation of the UsersRepository: it used an ApiService to fetch an endpoint defined by a route. Even though this has been erased by the abstraction brought by the injection of functions, at the end we still need to provide a function that can retrieve users for real. It is up to the dependency injection mechanism to provide a compatible concrete implementation.
您还记得UsersRepository的原始实现吗:它使用ApiService来获取路由定义的端点。 即使通过注入函数带来的抽象消除了这种情况,最后,我们仍然需要提供一个可以真正检索用户的函数。 依赖注入机制可以提供兼容的具体实现。
We have an ApiService at our disposal but the fetch definition does not match the signature we need:
我们可以使用ApiService,但是获取定义与我们需要的签名不匹配:

We need to perform two changes here:
我们需要在此处执行两项更改:
- Erase the Route parameter 删除路由参数
- Change the error type 更改错误类型
To erase the Route parameter we can borrow some techniques from the functional programming like partial functions or currying.
要删除Route参数,我们可以从函数编程中借鉴一些技术,例如部分函数或currying。
We will go with partial functions here, even though currying could be a reasonable choice as well.
我们将在这里使用部分函数,即使currying也可能是一个合理的选择。
Partializing a function is like saying to the compiler « Hey, I know some parameters of this function, I can set them right now, but the rest of the parameters are still undefined, please give me back a function that will only take those parameters so I can call it later!»
函数的局部化就像对编译器说的“嘿,我知道这个函数的一些参数,我现在可以设置它们,但是其余的参数仍未定义,请给我一个只接受那些参数的函数,以便我可以稍后再打电话!»
Let’s take a look at an example 😏.
让我们看一个示例😏。
dumbFunction is a function that takes two parameters and returns a Bool.
dumbFunction是一个带有两个参数并返回Bool的函数。

We can partialize that function to be able to « freeze » the first parameter and get back in return a function that only takes the second one.
我们可以对该函数进行局部化处理,使其能够“冻结”第一个参数,然后返回仅返回第二个参数的函数。

Now, instead of using the function ‘dumbFunction’ with 2 parameters, we can use its partialized counterpart with only one parameter
现在,代替使用带有两个参数的函数“ dumbFunction”,我们可以仅使用一个参数来使用其部分化的对应项。

It is a little bit like if we had performed dependency injection of the first parameter, the partialization has « captured » it.
有点像如果我们对第一个参数执行了依赖注入,那么部分化已经“捕获”了它。
Of course, we cannot write a partialized version of every function in our code base. There is a way to make it generic with any numbers of parameters.
当然,我们不能在代码库中编写每个函数的部分版本。 有一种方法可以使它与任意数量的参数通用。
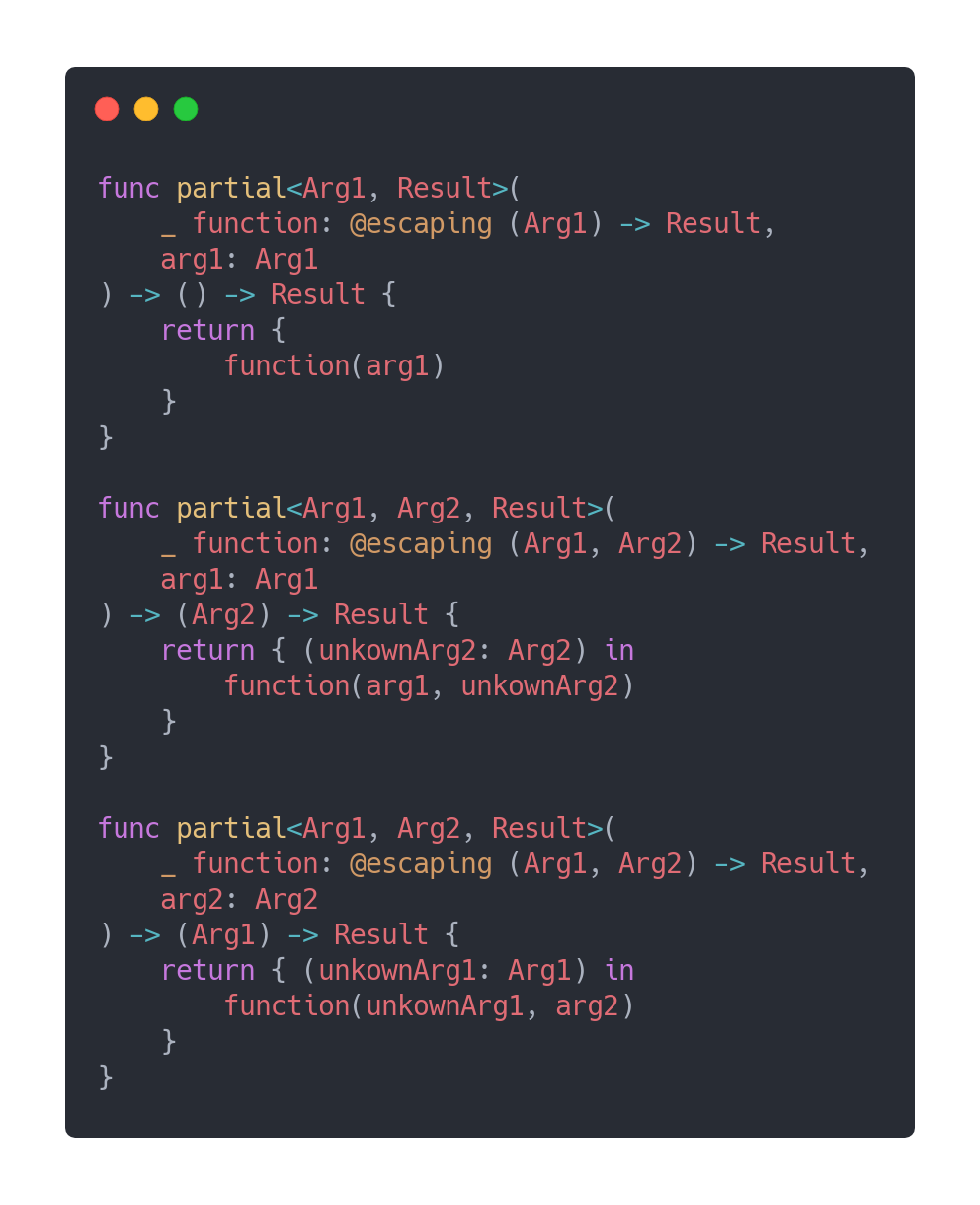
And we can write as much versions of partial functions as needed.
而且我们可以根据需要编写尽可能多的部分函数版本。
Do you see where I’m going here ? We went from a function with two parameters to a function with only one. Then, we can go from a function with one parameter to a function with none !
你知道我要去哪里吗? 我们从具有两个参数的函数变为只有一个参数的函数。 然后,我们可以从具有一个参数的函数变为没有参数的函数!
Let’s get back to the ApiService.fetch function and apply a partialization on it:
让我们回到ApiService.fetch函数并对其进行部分化:

We now have a partialized function with the signature:
现在,我们有了带有签名的部分函数:
() -> AnyPublisher<[User], ApiError>, the route parameter has been captured by the partialization and will be used when executing partializedFetchFunction.
()-> AnyPublisher <[User],ApiError> ,路由参数已被部分化捕获,将在执行partializedFetchFunction时使用。
We’re almost there, all we need to do is hide the ApiError, fortunately Combine can help use with that:
我们快到了,我们所要做的就是隐藏ApiError,幸运的是Combine可以帮助您使用:

Aaaaaand we have our dependency ! the retrieveUsersFunction has that signature:
aa,我们有依赖性! resolveUsersFunction具有该签名:
() -> AnyPublisher<[User], Swift.Error>
()-> AnyPublisher <[User],Swift.Error>
We can inject it in the Users.load function 👌.
我们可以将其注入到Users.load函数中。
总结 (Sum up)
1:使用函数作为依赖项: (1: use function as dependencies:)
2:使用局部化来建立依赖关系: (2: use partialization to build the dependencies:)
3:注入依赖 (3: inject the dependency)

The most delicate part is the second one as it asks some plumbing and boilerplate, but it should be segregated in specific areas of your code dedicated to dependency injection, like Swinject Assemblies for instance.
最微妙的部分是第二部分,因为它要求一些管道和样板,但应将其隔离在代码中用于依赖项注入的特定区域中,例如Swinject汇编。
结论 (Conclusion)
Although injecting traditional data structures is perfectly fine and is in line with best practices, injecting functions offers two major benefits:
尽管注入传统的数据结构非常好并且符合最佳实践,但是注入功能具有两个主要优点:
This puts under a new light how easy it is to leak the implementation details and how we can avoid it. The less we know about our dependencies, the better. I guess this illustrates perfectly the Law of Demeter
这使人们更加容易泄漏实现细节,以及如何避免这种细节。 我们对依赖性的了解越少,那就越好。 我想这很好地说明了得墨meter耳定律
- This makes unit tests easier to write, to read, and to reason about 这使得单元测试更易于编写,阅读和推理。
Using functions « everywhere » can have some unpleasant aspects like making signatures hard to read for instance. But this is something we can easily work around by using typealiases.
使用“无处不在”功能会带来一些不愉快的方面,例如使签名难以阅读。 但这是我们可以通过使用类型别名轻松解决的问题。
Using functions « everywhere » also opens the door to functional programming. We had a taste of it with partialization but it is a whole new world that you should gently explore.
使用“无处不在”功能也为功能编程打开了大门。 我们对它进行了局部化,但您应该轻轻地探索它,这是一个全新的世界。
Thanks for reading. Of course, feel free to comment and stay tuned.
谢谢阅读。 当然,请随时发表评论并继续关注。
奖励:Swinject和功能注入 (Bonus: Swinject and the injection of functions)
Swinject is a well established dependency injection framework in the Swift community. It is used to register and resolve the « recipes » to build your dependencies. But what about registering and resolving functions ?
Swinject是Swift社区中一个完善的依赖注入框架。 它用于注册和解析《配方》以建立依赖关系。 但是注册和解析函数呢?
There is nothing more like a (String) -> String function than another (String) -> String function, right !
没有什么比(String)-> String函数更像另一个(String)-> String函数了,对!
What happens if we need to resolve a function that has been registered several time with the same signature ?
如果我们需要解析已经使用相同签名多次注册的功能,会发生什么情况?
Swinject provides a way to discriminate registered services by using a unique name. If we want to use that in our (String) -> String case, we will end up with something like this:
Swinject提供了一种使用唯一名称来区分注册服务的方法。 如果要在(String)-> String情况下使用它,我们将得到如下所示的结果:

When it comes to resolve things:
解决问题时:

While there is nothing wrong about that, this is kind of ugly to read. We can improve this a bit with a protocol that groups the function signature and its name:
尽管这没有什么错,但阅读起来有点丑陋。 我们可以通过对功能签名及其名称进行分组的协议来对此进行一些改进:
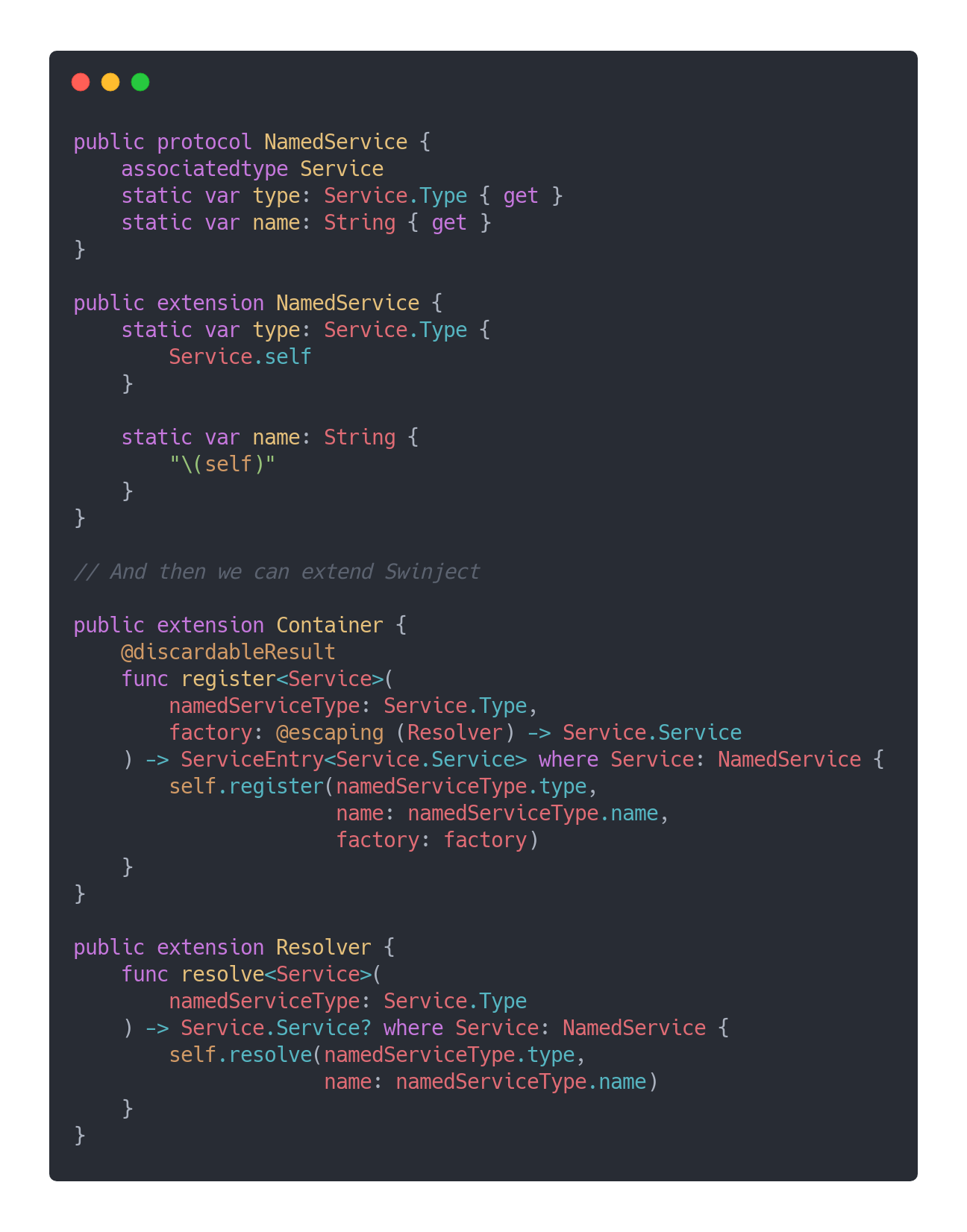
With that in place, the Swinject assembly now becomes:
将其安装到位后,Swinject装配现在变为:

When it comes to resolve things:
解决问题时:
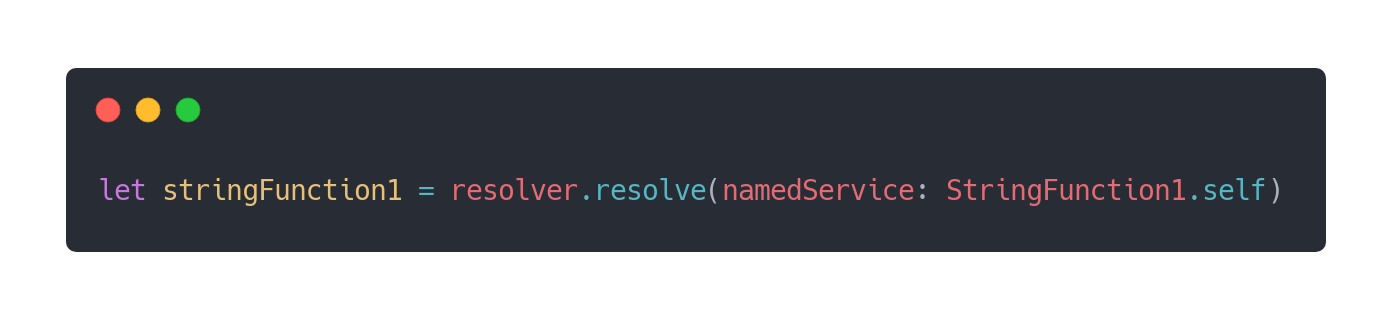
Even if we do not win that much in doing this, we make the function registration/resolving look like any traditional data structure usage. It removes a pain point in injecting functions that could have prevented you from trying this technique 😏.
即使这样做并没有赢得太多,我们也会使函数注册/解析看起来像任何传统的数据结构用法。 它消除了可能阻止您尝试使用此技术的注入功能的痛苦点。
翻译自: https://itnext.io/functions-as-dependencies-in-swift-2bc382f9475d
swift 依赖请求















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









